

June 25, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 23, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Teil 1 stellte die Diagnose: Tokenmaxxing ist kein Problem der KI-Nutzung; es ist ein Problem der Steuerungsebene. Wenn Roh-Tokens zu einem Ziel werden, werden Menschen für Roh-Tokens optimieren. Wenn die gesteuerte KI-Nutzung zum Betriebsmodell wird, kann die Plattform die Akzeptanz fördern und gleichzeitig Kosten, Risiken und operativen Aufwand begrenzen. Dieser Teil konkretisiert diese Architektur.
Die These ist einfach. Jede KI-Anfrage, die eine Unternehmensanwendung verlässt, ist, ob man sie so behandelt oder nicht, ein Laufzeitereignis mit Kosten-, Sicherheits- und Audit-Konsequenzen. Der Ort mit dem größten Hebel, um Kontrollen an diese Ereignisse anzubringen, ist das Gateway – die Schicht, die zwischen jeder Anwendung und jedem Modell- und Tool-Backend sitzt. Ein nachgelagertes Dashboard kann beschreiben, was passiert ist. Nur das Gateway kann entscheiden, was als Nächstes geschieht.
Ein Dashboard meldet ein Problem. Ein Gateway verhindert das nächste. Die untenstehende Architektur macht diese Unterscheidung operativ.
Eine gesteuerte KI-Anfrage benötigt vier Hüllen, die sie umgeben, bevor sie die Anwendung verlässt. Stellen Sie sich dies als das OSI-Modell für Unternehmens-KI vor – jede Schicht hat eine spezifische Verantwortung und einen spezifischen Fehlerfall, wenn sie fehlt.
Diese Hüllen müssen sich auf dem Anfragepfad befinden, nicht in einem Bericht, den jemand am Freitag liest. Ein nachträglich erstelltes Dashboard kann ein Problem beschreiben; nur eine Hülle bei der Live-Anfrage kann den nächsten Aufruf gestalten. Dies ist das architektonische Prinzip, das eine gesteuerte KI-Plattform von einem Analyse-Add-on unterscheidet.
Der erste Implementierungsstandard ist ein strenger Metadatenvertrag. Verwenden Sie zeichenkettenbasierte Schlüssel, senden Sie diese bei jeder Anfrage mit und machen Sie sie in Ihren SDK-Wrappern, internen Client-Bibliotheken, Bot-Frameworks und Agenten-Vorlagen obligatorisch. Die Kosten eines fehlenden Feldes zeigen sich später als fehlende Rechnungszeile, eine nicht zuordenbare Spitze oder ein Guardrail-Ereignis, das niemandem zugeordnet werden kann.
// JSON — minimum metadata contract
// Treat as a strict schema, not a suggestion.
{
"team": "payments-platform", // maps to FinOps cost center
"project_id": "proj-agentic-refactor", // rate/budget scoping key
"workflow": "repo-understanding", // routing and policy selector
"surface": "ide-agent", // hourly rate-limit selector
"environment": "production", // budget tier selector
"cost_center": "eng-core", // accounting integration
"ticket_id": "ENG-18472", // outcome join key — THE most important field
"policy_version": "ai-leverage-v1" // audit trail
}
// Python SDK — never skip the metadata header:
// extra_headers={"X-TFY-METADATA": json.dumps(metadata)}Tagging ist die kostengünstigste Ingenieurarbeit in dieser gesamten Architektur und das Erste, was kaputtgeht, wenn Teams es überspringen.
Im TrueFoundry Gateway wird dies als X-TFY-METADATA-Header übertragen. Derselbe Schlüssel-Namensraum versorgt dann alles nachgelagerte: Budgets gelten pro Projekt, Ratenbegrenzungen pro Workflow, Dashboards gruppieren nach Team, Traces werden mit Tickets verknüpft und die Finanzabteilung weist Ausgaben nach Kostenstelle zu. Es gibt keine zweite Quelle der Wahrheit.

Das architektonische Ziel ist nicht, zusätzliche Stellschrauben einzuführen. Es geht darum, eine enge Zuordnung zwischen jedem realistischen Fehlerfall und der spezifischen Kontrolle, die ihn verhindert, aufrechtzuerhalten. Hier ist die vollständige Taxonomie:
Wenn Anwendungscode ein spezifisches Anbietermodell benennt, verlieren Sie die Möglichkeit, ohne Codeänderungen zu migrieren, zu testen, A/B-Tests durchzuführen oder ein Failover zu initiieren. Das richtige Muster ist, logische Funktionen offenzulegen – Namen wie prod/engineering-assistant oder prod/frontier-reasoning – und das Gateway diese basierend auf Metadaten, Priorität, Gewicht oder gemessener Latenz in physische Ziele auflösen zu lassen.
Bei TrueFoundry dienen dazu virtuelle Modelle und die Routing-Konfiguration. Dieselben Regeln decken Canary-Rollouts, regionale Präferenzen, On-Premise-Lösungen mit Cloud-Fallback und anbieterspezifische Prompt-Overrides ab. Dies ist die am meisten unterschätzte Funktion im Governance-Stack – sie macht Compliance, Kostenoptimierung und Modellmigration für Anwendungsentwickler unsichtbar.
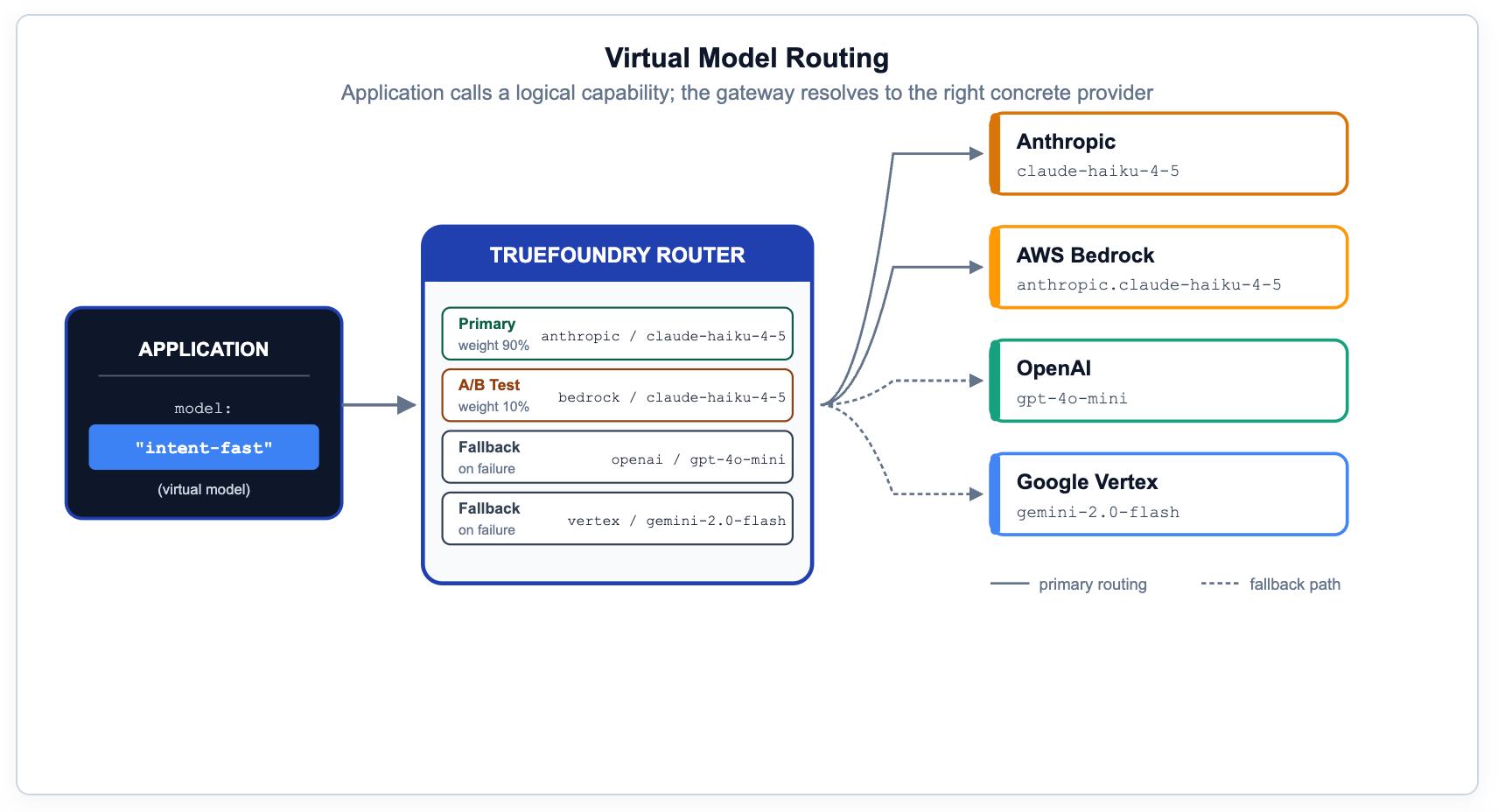
# YAML — gateway-load-balancing-config
# Evaluated top-to-bottom; first match wins.
name: engineering-agent-routing
type: gateway-load-balancing-config
rules:
# Simple repo questions: cheap-first with frontier fallback.
- id: 'simple-repo-questions'
type: priority-based-routing
when:
models: ['prod/engineering-assistant']
metadata:
workflow: 'repo-understanding'
load_balance_targets:
- target: openai-main/gpt-4o-mini
priority: 0
retry_config: {attempts: 2, delay: 100, on_status_codes: ['429','500']}
fallback_status_codes: ['429', '500', '502', '503']
- target: anthropic-main/claude-sonnet
priority: 1
# Security-critical: strongest reasoner first.
- id: 'security-critical-review'
type: priority-based-routing
when:
metadata:
workflow: 'security-review'
load_balance_targets:
- target: anthropic-main/claude-opus
priority: 0
- target: openai-main/gpt-4.1
priority: 1
# Cost-sensitive batch: on-prem first, cloud as overflow.
- id: 'batch-processing-jobs'
type: priority-based-routing
when:
metadata:
surface: 'batch-pipeline'
load_balance_targets:
- target: on-prem/llama-3.1-70b
priority: 0
- target: openai-main/gpt-4o-mini
priority: 1
Routing-Dokumentation: truefoundry.com/docs/ai-gateway/load-balancing-overview
Sobald KI-Anwendungen in Produktion gehen, verarbeiten sie echte Benutzerdaten und führen in agentenbasierten Setups über Tools reale Aktionen aus. Der Sicherheitsperimeter ist nicht eine einzige Sache. Er besteht aus vier Hooks, die an den vier Momenten ansetzen, an denen das Gateway eingreifen kann, bevor eine Anfrage Schaden anrichtet.
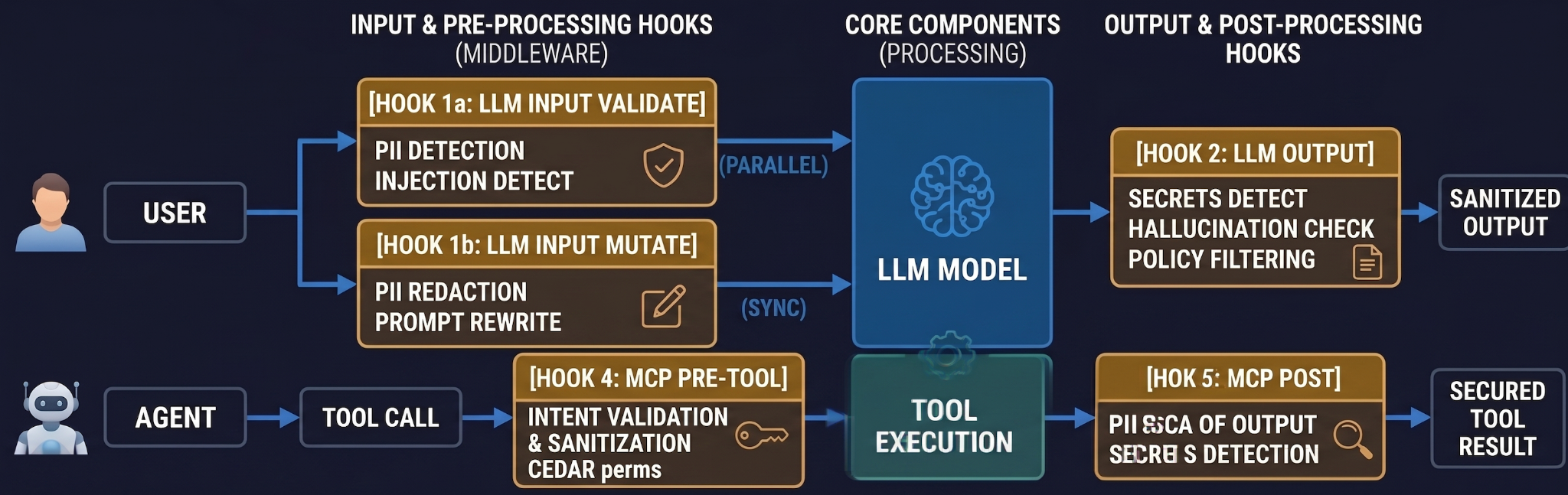
# Per-request guardrails — passed via X-TFY-GUARDRAILS header.
# For org-wide enforcement: AI Gateway → Controls → Guardrails.
X-TFY-GUARDRAILS: {
"llm_input_guardrails": [
"global/pii-redaction",
"global/prompt-injection-detection"
],
"llm_output_guardrails": [
"global/secrets-detection",
"global/hallucination-check"
],
"mcp_tool_pre_invoke_guardrails": [
"global/sql-sanitizer",
"global/cedar-permissions"
],
"mcp_tool_post_invoke_guardrails": [
"global/secrets-detection",
"global/pii-redaction"
]
}
# Rollout strategy — never go straight to blocking in production:
# Phase 1: mode=audit (log violations, let requests through)
# Phase 2: mode=enforce (block on fail, fail-open on provider errors)
# Phase 3: mode=strict (block on fail AND on provider errors)
Führen Sie Guardrails in drei Schritten ein: Audit → Erzwingen-aber-Fehler-ignorieren → Strikt. Die mittlere Einstellung ist diejenige, die Sie an dem Tag rettet, an dem ein Drittanbieter für Sicherheit einen Ausfall hat.
Guardrails-Übersicht: truefoundry.com/docs/ai-gateway/guardrails-overview
PII/PHI-Erkennung: truefoundry.com/docs/ai-gateway/tfy-pii
Erkennung von Geheimnissen: truefoundry.com/docs/ai-gateway/secrets-detection
Zwei Fragen dominieren den Betrieb, sobald die gesteuerte KI-Nutzung in Produktion ist: 'Warum hat diese Anfrage sich so verhalten?' und 'Entsprechen die Kosten, die wir zahlen, der Leistung, die wir erhalten?' Keine davon lässt sich anhand eines Token-Zählungsdiagramms beantworten.
Die minimale Oberfläche, die zur Beantwortung dieser Fragen erforderlich ist — und die Oberfläche, die TrueFoundrys Gateway sofort bietet:
Analysedokumentation: truefoundry.com/docs/ai-gateway/analytics
OpenTelemetry-Export: truefoundry.com/docs/ai-gateway/export-opentelemetry-data
Die vier oben genannten Hüllen wurden unter der Annahme von Chat-Anfragen konzipiert: Eine Anwendung sendet einen Prompt, das Modell gibt Text zurück. Moderne KI-Workloads sind über diese Annahme hinausgewachsen. Agenten rufen Tools auf. Tools rufen andere Tools auf. Eine einzelne Benutzeranfrage kann eine 50-schrittige Agenten-Trajektorie auslösen, die ein halbes Dutzend MCP-Server berührt. Die Kostenfläche, die Sicherheitsfläche und die Audit-Fläche sind alle vom Prompt zum Tool-Aufruf gewandert.
Deshalb spricht das TrueFoundry-Gateway sowohl die LLM-API als auch das Model Context Protocol (MCP) nativ. Dieselbe Identitätshülle, dieselben Circuit Breaker, dieselben Observability-Hooks gelten für einen Tool-Aufruf wie für eine Chat-Vervollständigung. Die OAuth 2.0-Identität wird in MCP-Tool-Aufrufe injiziert, sodass ein Agent als spezifischer Benutzer und nicht als Dienstkonto agiert, wenn er eine Datenbank abfragt oder ein Jira-Ticket erstellt. Virtuelle MCP-Server ermöglichen es Ihnen, einen logischen „Finance-Agent-Server“ aus Tools zusammenzustellen, die über drei reale MCP-Server verteilt sind, wobei Zugriffssteuerung und Ratenbegrenzungen auf die Komposition angewendet werden.
Das Model Context Protocol ist wichtig für die Kosten, nicht nur für die Architektur. TrueFoundry berichtet von bis zu 99 % Einsparungen bei Inferenz-Tokens, wenn Agenten aktives Tool-Retrieval verwenden, anstatt Kontext in Prompts zu stopfen – und einem Tool-Aufruf-Overhead von etwa 10 ms.
→ MCP-Gateway-Übersicht
→ Virtuelle MCP-Server
Es ist verlockend, diese Kontrollen in den Anwendungscode zu verlagern: ein Wrapper hier, ein Python-Decorator dort, eine Helferklasse im Agenten-Framework. Das funktioniert, bis Sie drei Anwendungsteams, zwei Modell-Anbieter, eine Akquisition, ein PCI-Audit und einen Ratenbegrenzungs-Vorfall an einem Dienstag haben.
An diesem Punkt stellen Sie fest, dass Sie vier leicht unterschiedliche Steuerungsebenen aufgebaut haben, die sich widersprechen, und dass keine davon eine Anfrage von einem Team stoppen kann, das den Wrapper nicht importiert hat. Das Gateway existiert aus demselben Grund, aus dem API-Gateways vor einem Jahrzehnt existierten: Es ist der einzige Ort, an dem jede Anfrage, von jeder Anwendung, in jeder Umgebung, einheitlich beobachtet und geformt werden kann.
Der Einwand gegen ein Gateway ist immer „ein weiterer Hop im Anfragepfad“. Das TrueFoundry AI Gateway fügt etwa 5 ms p50 Overhead hinzu und verarbeitet über 350 Anfragen pro Sekunde auf einer einzelnen vCPU. Der Einwand hält den Zahlen nicht stand.
Das Gateway ist auch der einzige Ort, der die gesamte Oberfläche der modernen KI-Infrastruktur abdecken kann: über 1000 LLMs von mehr als 19 Anbietern, plus die MCP-Server, die Ihre Agenten aufrufen, plus die selbst gehosteten Modelle hinter Ihrer VPC. TrueFoundry wurde im Gartner-Bericht „10 Best Practices zur Optimierung der Kosten für generative und agentische KI 2026“ genannt – weil Unternehmen in diesem Bereich nur dann wirklich optimieren können, wenn sie jede Anfrage durch eine einzige, gesteuerte Schicht leiten.
Tokenmaxxing ist ein Symptom einer unkontrollierten KI-Einführung. Die oben beschriebene Architektur ist die Lösung. Identität definiert, wer anfragt. Richtlinien definieren, was erlaubt ist. Sicherheit definiert, was akzeptabel ist. Observability definiert, was tatsächlich geschehen ist. Zusammen wandeln sie rohe Token-Aktivität in einen gesteuerten Anfragelife-Cycle um – rechenschaftspflichtig, nützlich, sicher, anpassbar.
Das Ziel ist nicht, den Einsatz von KI zu reduzieren. Das Ziel ist es, jede Zeile davon erklärbar zu machen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.



.webp)
.webp)










.webp)
.webp)