
August 3, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 5, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Exact-match caching has been the right default for thirty years. It is the wrong default for LLMs, because text is the surface of intent, not intent itself. The work of a semantic cache is to cache the thing underneath.
Traditional API caching is a hash table. The request is hashed, the response is keyed against the hash, and the next byte-identical request returns the cached value. The model is correct for deterministic APIs because the hash captures everything that matters about a request. There is no information in the call that is not in its bytes.
LLM workloads break this assumption at the surface. Three users in a customer-support flow ask the same thing in three different shapes:
user traffic · 60-second window
-- User A: "How do I reset my password?"
-- User B: "I forgot my password — what should I do?"
-- User C: "Where is the password reset page?"
To a SHA-256 cache, those are three keys, three misses, and three full provider calls. To the model, the intent is identical and the response should be identical. The cache that hashes raw text is not a wrong cache; it is a cache for the wrong layer of meaning. Text is a lossy carrier of intent — the same intent has many surfaces — and exact-match caching keys the surface instead of the substance.
The gap is large enough to be worth caring about. A cache that hits only on byte-equal requests catches a small fraction of the calls a cache that hits on intent would catch. Closing that gap is what semantic caching is for.
A production-grade semantic cache cannot just embed-and-look-up. It has to enforce policy boundaries (different system prompts must not collide), respect tenant isolation, and refuse to confuse “my left arm hurts” with “my right arm hurts.” The TrueFoundry gateway runs a four-stage pipeline that pulls all four concerns into a single hot path.
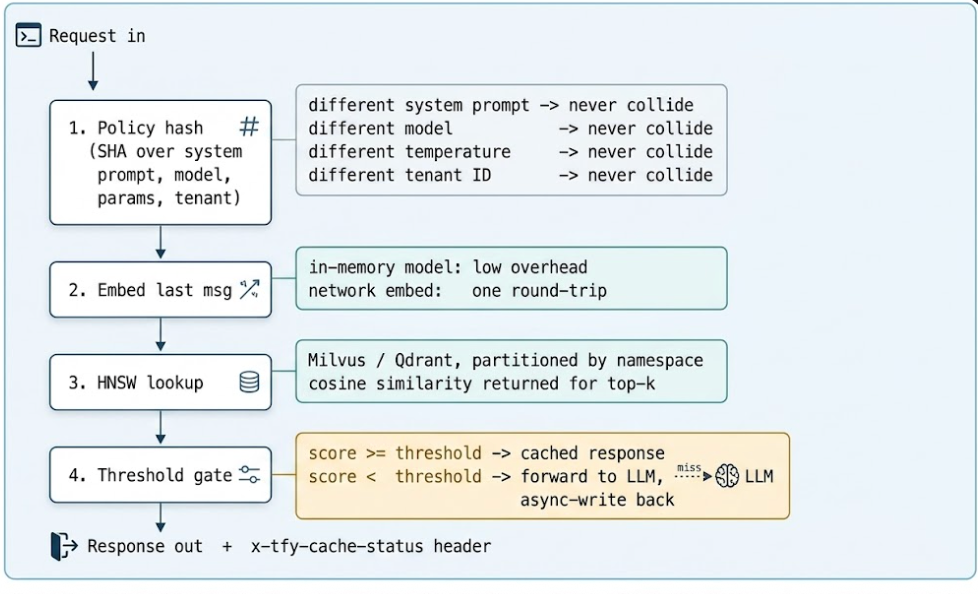
A subtle detail: only the last message is compared semantically. Everything else — model name, temperature, prior messages, system prompt, tenant ID — is hashed exactly. If any of those don't match, the cache treats the requests as different even if the user's most recent line is word-for-word identical. That is the correct default. A pre-loaded conversation context changes meaning more than most engineers expect, and you want the cache to err toward not collapsing those.
Embedding vectors live in high-dimensional space — 384 dimensions for MiniLM, 768 for BGE-base, 1536 for text-embedding-3-small. In that geometry, Euclidean distance is dominated by vector magnitude, which is mostly noise; what carries semantic meaning is direction. Cosine similarity normalizes magnitude out by computing the cosine of the angle between two vectors — it is invariant to scale, so two vectors pointing the same way score 1.0 regardless of length.
Every modern semantic cache uses cosine. The only time you would reach for Euclidean is if your embedding model produced unit-normalized vectors anyway, in which case the two metrics are equivalent up to a constant and cosine is still simpler to reason about. There is no practical workload where Euclidean is the right answer.
Naïve nearest-neighbor search is O(N) — every query compares against every cached vector. At a million entries, the comparison budget is unworkable. HNSW (Hierarchical Navigable Small World) builds a layered graph where each node connects to a small number of close neighbors, with sparser links at higher layers. A query starts at the top layer, walks greedily toward the nearest match, descends a layer, and repeats. The search visits O(log N) nodes — approximate, but typically 95–99% recall against an exact search, and orders of magnitude cheaper. Milvus and Qdrant both ship with HNSW; TrueFoundry uses whichever the deployment is configured against.
Semantic caching trades compute for latency and provider cost, so the embedding model is the most consequential decision in the system. There are two real options.
Managed models — OpenAI's text-embedding-3-small, Cohere, Voyage — provide strong cross-domain semantic grasp out of the box. The cost is a network round-trip on every request, which eats directly into the latency wins from caching. On TrueFoundry SaaS, text-embedding-3-small (1536 dimensions) is the default and is not user-configurable; this is a deliberate choice for the managed tier — a known-good baseline that is cheap enough to amortize on every call.
In-memory alternatives like BGE-micro (384 dim) or all-MiniLM-L6-v2 (384 dim) run inside the gateway process, drop the network dependency entirely, and remove the embedding round-trip from the request path. On the on-premise tier, the embedding model is configurable through the dashboard (Controls → Settings → Semantic Cache); the choice applies gateway-wide. For internal-facing workloads — coding assistants, technical documentation, customer-support flows — fine-tuning a small local model on domain vocabulary is usually the highest-ROI move on the entire stack. “k8s” and “Kubernetes” should embed to nearly the same vector. A general-purpose model treats them as cousins; a fine-tuned one treats them as synonyms. Hit rate moves accordingly.
There is a practical observation about dimensions. Higher-dimensional embeddings (1536) carry more semantic information but cost more to index and search; HNSW with 1536 dim takes roughly 4× the memory and 2× the search time of 384 dim. For most cache workloads, the marginal recall gain of 1536 over a fine-tuned 384-dim model is small enough that the operational savings dominate. Start at 384 and only move up if measured precision and recall on real traffic justifies it.
Table 1 — The embedding model is the dial that decides whether semantic caching is a latency win or a latency wash. In production, the in-memory path is the path that pays for itself.
The similarity threshold is the slider between savings and risk. Lower it, hit rate goes up, cost goes down — and so does the chance of a false hit, returning a stale or contextually wrong answer. The dial sits inside the request via x-tfy-cache-config:
HTTP · request header
x-tfy-cache-config: {
"type": "semantic",
"similarity_threshold": 0.94,
"ttl": 600,
"namespace": "tenant-123"
}TrueFoundry's recommended starting point is 0.9, with a band that depends on the tolerance for incorrect cache hits.
Table 2 — Threshold band. There is no global “correct” value; the right threshold is the one that matches the cost of a false hit in your domain.
The medical-triage thought experiment makes the danger concrete. “My left arm hurts” and “My right arm hurts” can score 0.91 in a general-purpose embedding space. At threshold 0.90, the cache cheerfully returns identical advice for two physically opposite conditions. For a general FAQ bot 0.88 may be perfectly safe. For triage it is malpractice. The threshold is not a global hyper-parameter; it is a per-workload encoding of how expensive a wrong answer is.
Choosing a threshold is choosing a point on a precision/recall curve specific to your traffic. Below is what that curve typically looks like for a customer-support workload — yours will be shifted left or right, but the shape is the same:
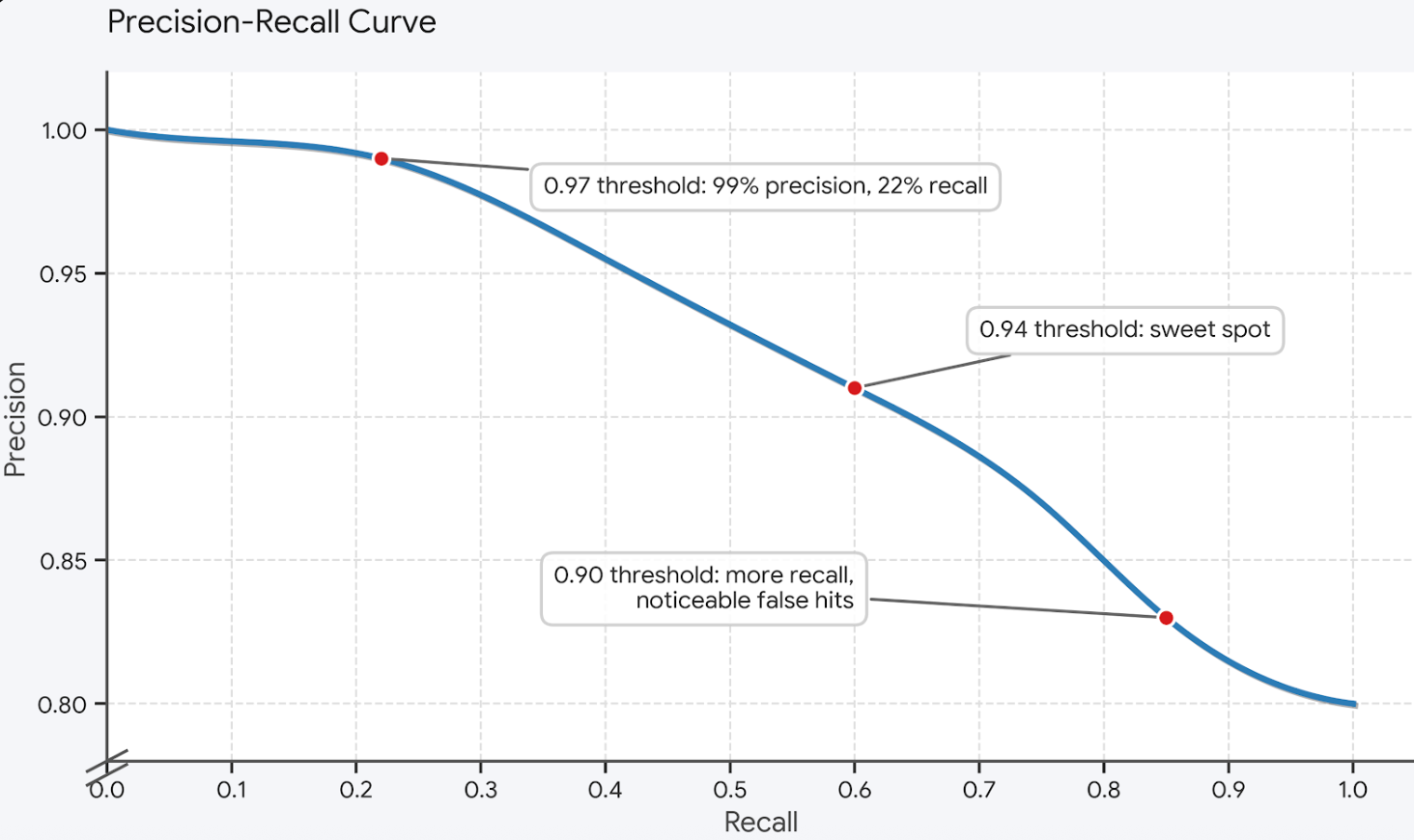
The right discipline for picking a point is shadow mode. For a configurable window — typically a week — the cache computes similarities and logs what would have matched at every threshold without actually serving cached responses. Engineers review the log, plot their version of the curve above against real traffic, and pick a threshold that drives false hits to a level the workload can tolerate. The threshold is not a global constant; it is a per-workload tuning knob, and the tuning data has to come from production traffic, not synthetic queries.
On every response the gateway returns three headers that make this loop debuggable: x-tfy-cache-status (hit / miss / error), x-tfy-cache-similarity-score (the cosine score on hits), and x-tfy-cached-trace-id (the trace ID of the original request that populated the entry). The third one is the one you'll keep coming back to — it lets you trace any cached answer back to the conversation that produced it, which is the only way to debug a misfire.
Semantic similarity becomes dangerous when the underlying truth has shifted. “What is the current interest rate?” yesterday and today are semantically identical and factually different. The cache will happily serve last month's number with a similarity score of 1.0.
Workloads need workload-specific TTLs. Static documentation assistants run a comfortable multi-day TTL because the underlying truth is the docs, and the docs change at the speed of releases. RAG applications use document-hash invalidation: when the source document changes, every cache entry derived from it is flushed automatically. Time-sensitive facts (rates, prices, schedules) get short, hard TTLs and never coalesce across day boundaries. For these, semantic caching is often the wrong tool, and you should fall back to exact-match or no caching at all.
It is worth being honest about what semantic caching is bad at. Anything that should change as the world changes is bad cache material at any threshold. The right rule of thumb: if a human would notice the answer is stale, the cache is too.
There is one operational hazard worth designing around explicitly: the cache stampede. If a popular query expires and a thousand identical requests arrive in the same second, a naïve cache will let all thousand pass through to the LLM, then have all thousand try to write the result back. The TrueFoundry gateway uses single-flight semantics — the first request to miss acquires a per-key lock; subsequent identical requests during the LLM call wait for that single response and reuse it. The write-back is async (the response is returned to the client immediately, the vector is committed to Milvus/Qdrant in the background), so cache writes never appear in the request-path latency.
In any B2B SaaS deployment, tenant A receiving a cached response generated for tenant B is not a bug. It is a breach. The cache architecture has to be hostile to that outcome by design, not by post-hoc filtering.
TrueFoundry isolates cache entries at two levels and the user does not have to think about the first one.
Level 1 is enough for most teams. Level 2 is the lever you reach for when one virtual account fans out to many downstream end-users — a SaaS that proxies LLM requests on behalf of its own customers, for example — and a per-customer cache is what your data-residency commitments require. Either way, there is no global vector pool to leak from. This is the implementation that satisfies SOC 2 and HIPAA reviewers.
Anthropic and OpenAI have both shipped prompt-side caching: the provider hashes a prefix of the system prompt and reuses internal state on cache hits, charging less for cached input tokens. This is a different layer than what we have been discussing, and the two compose.
Provider prompt caching reduces time-to-first-token and lowers the cost of cached input tokens, but the model still generates a fresh completion. Gateway semantic caching eliminates the model call entirely. Most teams that benefit from one benefit from both, and the gateway-side cache is the larger lever — order-of-magnitude latency improvement on hits, full cost elimination, and a layer the org can debug, audit, and tune without provider involvement. The provider cache is opaque; the gateway cache is yours.
There is an old observation in distributed systems: caches are correctness-preserving only at the layer of meaning they were designed to capture. A page cache works because pages are the unit of correctness. A query cache works because identical queries produce identical results. An LLM cache that hashes text is caching at the wrong layer of meaning, and the wrongness shows up in the form of misses where hits should be.
Semantic caching is the work of moving the cache key from text to intent. It needs more infrastructure (an embedding model, a vector index, a threshold) because intent is a more abstract object than a string. But it is the right abstraction for the workload, and once the cache layer matches the meaning layer the savings stop feeling like an optimization and start feeling like the right architecture all along.
No. Semantic caching is a strict superset — exact match is just cosine similarity 1.0. On TrueFoundry, setting the cache type to semantic also returns exact-match hits. Running both layers separately is duplicated infrastructure that complicates invalidation, and the gateway treats them as a single layer.
Only if you use a network-hosted embedding model on a workload where most calls miss the cache. The whole point of running a small in-memory model on the gateway nodes is to keep the embedding cost well below the threshold where it would erase the win on hits. On the SaaS tier, the default embedding model is text-embedding-3-small, which adds roughly one network round-trip; that is the cost of operating zero embedding infrastructure yourself.
Run shadow mode for at least a week. Don't ship a threshold without seeing what it would have served against your real traffic. The same question scored slightly differently on synthetic data and on production data is the surprise that ends careers — and it is fully avoidable with one log and one Jupyter notebook.
The cache is decided up front, before the model call begins. On a hit, the response is returned immediately with no streaming gap. On a miss, the streaming response is captured asynchronously and committed back to the cache after the call completes — there is no streaming-vs-cache tradeoff to manage.
The gateway falls back to forwarding every request to the LLM provider. Cache misses cost what they would have cost without the cache; nothing breaks. The only operational signal is the x-tfy-cache-status: error header on responses, which a dashboard alert should be wired to. Reliability of the request path beats availability of the cache layer.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet








.webp)




.webp)



