














August 27, 2025
|
5 min read

Published: April 11, 2026

Blazingly fast way to build, track and deploy your models!
Overall Vision: A developer platform that eases creation and management of services following all best practices and gives complete overall picture of infrastructure including monitoring of systems, data, cost and impact with initial focus on Machine Learning!
Vision for TrueFoundry (5–10 years)
TrueFoundry at its core aims to make developer experience seamless for running and managing MicroServices — where with the right level of abstractions, developers can just focus on writing the business logic at very high iteration speeds.
Imagine a flow where after writing the code — I can call a genie and tell about my requirements like kind of service (Serverless, CronJob, Database, an API service), resource requirements like CPU, memory, etc and the genie creates the service with the best practices like Gitops, Infrastructure as Code (IAC) and then shows a dashboard with all the metrics created.
We want to be able to achieve the following things with servicefoundry:
Centralized Infrastructure Provisioning using IAC
ServiceFoundry will provision and host the most commonly used open source infrastructure components on the user’s cloud. A few examples of this can be:

Create Service
Similar to the above, we also want to do the same for ML Models, Databases.

ServiceFoundry will aim to streamline the deployment and monitoring of the standard types of services:
Service Catalog and Graph
All services created using ServiceFoundry can be viewed at one place along with their complete metdata. This catalog will also show all the environments for each application like dev, staging and prod. This leads to a developer platform portal where developers and business leaders can view the services running in the organization. A few of the key metadata asscociated with each service is:


The initial focus of TrueFoundry will be to provide a seamless MlOps platform that focuses on post-model building pipeline and makes it really easy for datascientists to deploy, monitor and retrain their models.
A machine learning pipeline comprises of the following centralized infrastructure:

A brief explanation of the different steps involved are:
Because of so many moving parts and different technologies involved, usually multiple people are involved in a ML project like DataEngineer, Datascientist, ML engineer, Devops and Product Manager. A successful project requires the coordination among all these different personas which leads to a lot of delays and hampers the speed of a data scientist.
A typical workflow in companies for a machine learning pipeline looks something like:

We want to automate the parts in the ML pipeline that can be automated and empower the datascientist to be able to test their models in production and iterate fast with as minimum dependencies on other teams as possible. We draw our motivation from the products created by Platform teams in top tech companies that allow all teams to move much faster and deploy and iterate on their own.
We don’t handle any of the data related problems now — that section will be introduced later.
A key ML Platform comprises of the following services (apart from the central infrastructure)
If we can easily deploy these services, maintain versioning across different stages and generate monitoring for each of them, the ML Ops problem will be a much more simpler problem.
This blog was first published on Medium at https://abhishekch09.medium.com/d8e159743a4b
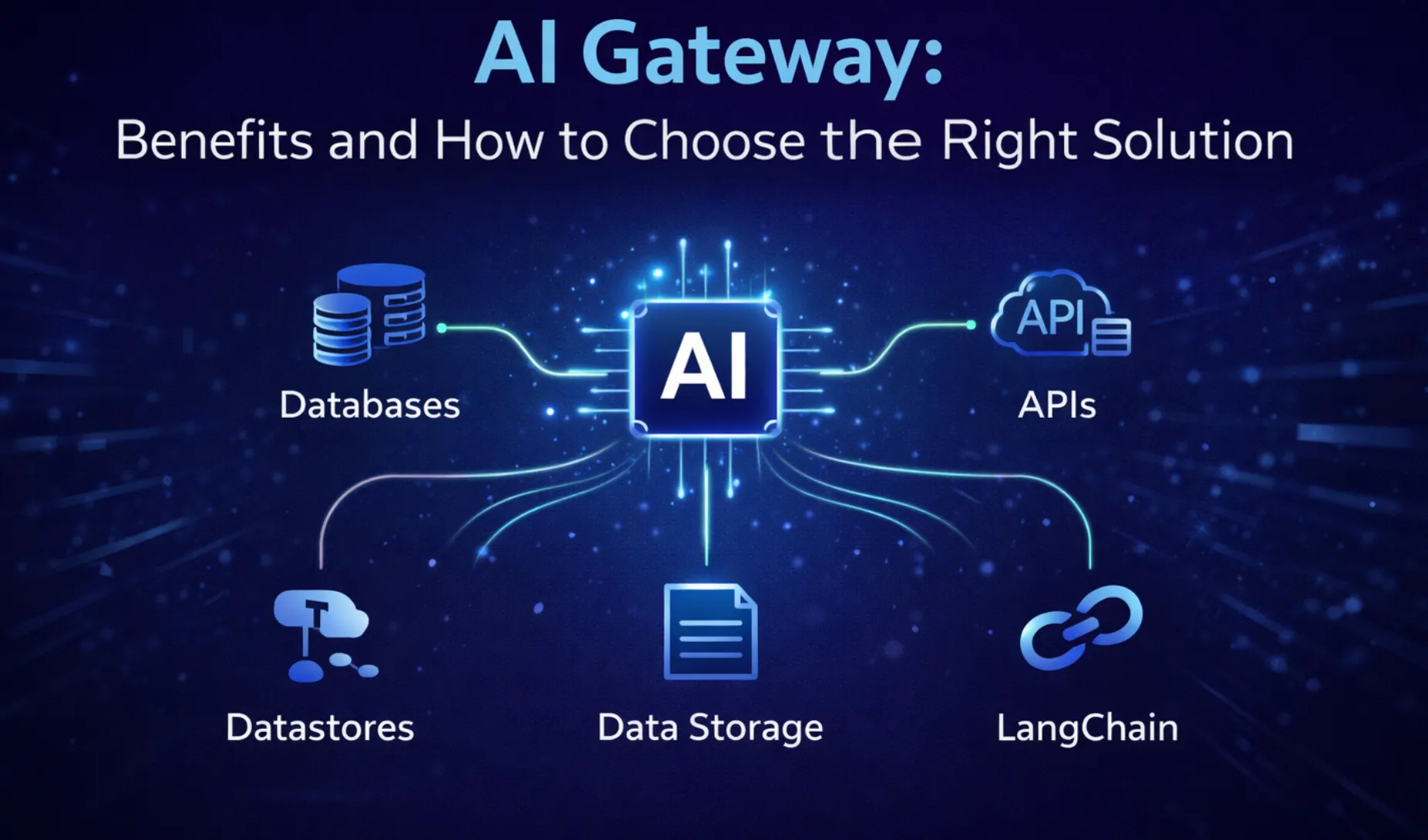
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox


.webp)
.png)
.webp)




.webp)


.webp)
.png)
.webp)
.webp)
.webp)




