
.webp)
June 25, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 4, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wir kündigen die Integration von Resemble AI mit dem TrueFoundry AI Gateway an, die Stimmenklonung sowie synchrone Text-zu-Sprache- und Streaming-TTS-Funktionen in denselben Gateway-Pfad bringt, den Teams bereits für LLMs, Embeddings und Agenten-Traffic nutzen.
Teams, die KI-Traffic über das AI Gateway von TrueFoundry leiten, können Resemble AI nun als erstklassigen Text-zu-Sprache-Anbieter über das native SDK-Pass-Through des Gateways anbinden. Anfragen an Resembles /synthesize-Endpunkt und /stream-Endpunkt laufen über den Gateway-Pfad mit zentralisierter Authentifizierung, teambasierter Zugriffssteuerung, vereinheitlichter Kostenverfolgung und vollständigem Request-Tracing. Es sind keine Änderungen am Client-Code erforderlich, außer die Resemble-Basis-URL auf das Gateway zu richten und sich mit einem TrueFoundry-Token zu authentifizieren.
Dieser Beitrag beschreibt die Architektur der Integration. Er erklärt, wie das TrueFoundry AI Gateway TTS-Anbieter bereitstellt, wie Resembles native API-Oberfläche über die Pass-Through-Schicht erhalten bleibt und wie Failover über mehrere TTS-Anbieter hinweg mittels Virtual Models funktioniert.
TrueFoundry stellt die Steuerungsebene für KI-Produktionssysteme bereit. Über das AI Gateway zentralisieren Teams Modell-Routing, Schlüsselverwaltung, Zugriffssteuerung, Observability und Kostenverfolgung über LLMs, Embeddings sowie Bild- und Audioanbieter hinweg. Jede Anfrage fließt durch eine einzige Proxy-Schicht, wo die Identität überprüft, Ratenbegrenzungen durchgesetzt und Traces erfasst werden.
TTS-Traffic in der Produktion ähnelt LLM-Traffic in dreierlei Hinsicht. Mehrere Anbieter sind in der Regel im Einsatz, da kein einzelner TTS-Anbieter in jeder Dimension überlegen ist. Latenz ist wichtig, da Sprachagenten Audio in Echtzeit an Benutzer streamen. Kosten summieren sich schnell auf Zeichen- oder Sekundenebene und profitieren von denselben Chargeback- und Budgetkontrollen, die Teams bereits auf Chat-Completions anwenden. Die Argumente für das Schalten eines Gateways vor LLM-Anbieter übertragen sich direkt.
Resemble AI ist eine Plattform für Stimmengenerierung und Audio-Intelligenz. Ihr Kern-Synthese-Engine ist das Chatterbox-Modell mit einer Chatterbox Turbo-Variante für geringere Latenz und paralinguistische Tag-Unterstützung. Die Plattform unterstützt Stimmenklonung, SSML, HD-Synthese und Streaming-Ausgabe. Resemble bietet auch angrenzende Produkte an, darunter Resemble Detect zur Erkennung von Audio-Deepfakes, Audio Edit, Voice Design und Watermark, die neben dem TTS-Workflow integriert werden können.
Zusammen bieten die beiden Plattformen Teams einen zentralen Ort, um die Stimmengenerierung neben dem Rest ihres KI-Stacks zu steuern und zu verfolgen. TrueFoundry übernimmt Bereitstellung, Routing und operative Steuerung. Resemble übernimmt die eigentliche Synthese. Die Integration nutzt TrueFoundrys natives SDK-Pass-Through, das Resembles vollständige API-Oberfläche bewahrt, ohne sie in ein OpenAI-kompatibles Format zu zwingen.

Resembles synchroner Text-zu-Sprache-Endpunkt akzeptiert eine kleine Menge von Feldern und gibt Audio zusammen mit Timing-Metadaten zurück. Der Synthese-Endpunkt akzeptiert eine `voice_uuid` zur Auswahl der zu verwendenden trainierten oder vorgefertigten Stimme und ein Datenfeld, das Text oder SSML mit bis zu 3000 Zeichen enthält. Optionale Felder steuern die Modellauswahl über `model` (z.B. `chatterbox-turbo`), die Audio-Präzision über `precision` (eines von `MULAW` oder `PCM_16` oder `PCM_24` oder `PCM_32`), das Ausgabeformat über `output_format` (`wav` oder `mp3`), die Abtastrate, den HD-Modus über `use_hd` und die Handhabung benutzerdefinierter Aussprachen über `apply_custom_pronunciations`.
Die Antwort-Payload gibt `success` und ein base64-kodiertes `audio_content`-Feld zurück, das die synthetisierten Audio-Bytes enthält. Timing-Metadaten werden in `audio_timestamps` mit Graphem-Zeichen und Graphem-Zeiten sowie Phonem-Zeichen und Phonem-Zeiten für nachgelagerte Ausrichtungsanwendungsfälle wie Lippensynchronisation und Untertitelung geliefert. Die Antwort meldet außerdem `duration` (die Audiolänge in Sekunden), `synth_duration` (die reine Synthesezeit), `output_format`, `sample_rate` und alle Probleme, die der Synthesizer während der Generierung gemeldet hat.
Ein zweiter Endpunkt unter `/stream` unterstützt Streaming-Synthese über HTTP für Sprachagenten-Anwendungsfälle, bei denen die Zeit bis zum ersten Audio-Chunk entscheidend ist. Die Anfragenstruktur ist dieselbe. Die Antwort ist ein Stream von Audio-Frames anstelle einer einzelnen base64-Payload. Die Authentifizierung für beide Endpunkte erfolgt über einen Bearer-Token, der von der Resemble-Account-Konsole ausgestellt wird.
Das TrueFoundry AI Gateway läuft auf dem Hono-Framework, und ein einzelner Gateway-Pod verarbeitet über 250 Anfragen pro Sekunde auf 1 vCPU und 1 GB RAM mit einer zusätzlichen Latenz von etwa 3 ms. Gateway-Pods sind zustandslos und CPU-gebunden und skalieren horizontal auf Zehntausende von RPS durch zusätzliche Pods. Die Control Plane und die Gateway Plane sind getrennt. Die Anbieterkonfiguration, einschließlich Anmeldeinformationen, Routing-Regeln und Ratenbegrenzungen, befindet sich in der Control Plane und wird über NATS mit den Gateway-Pods synchronisiert. Der eigentliche Anfragepfad verbleibt im Speicher, ohne externe Aufrufe über den Anbieteraufruf selbst hinaus.
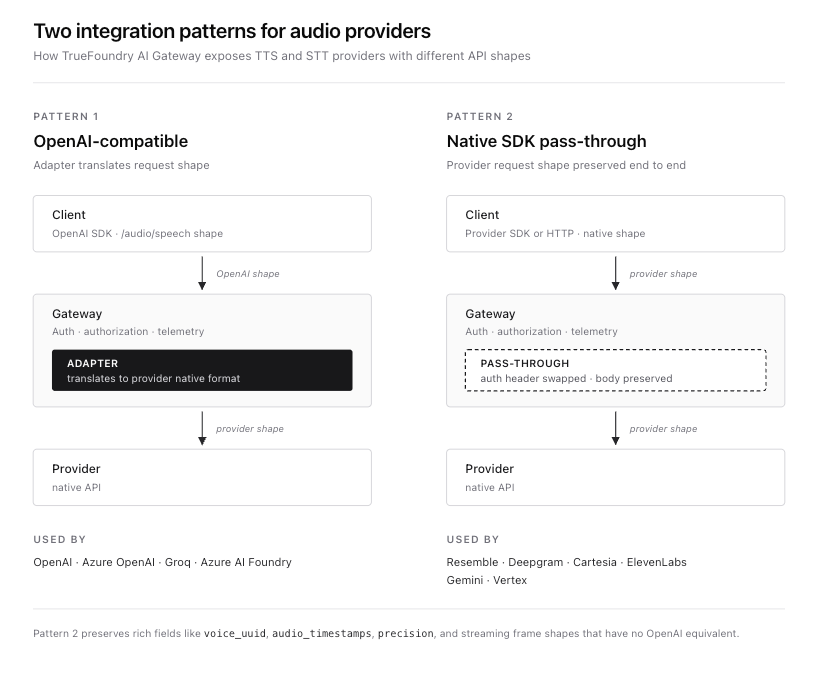
Für TTS bietet das Gateway zwei Integrationsmuster.
Das erste ist das OpenAI-kompatible API Muster unter der Gateway-Basis-URL. Anbieter, die das OpenAI `/audio/speech`-Format unterstützen (OpenAI, Azure OpenAI, Azure AI Foundry und Groq), werden hier angeschlossen. Clients verwenden das Standard-OpenAI-SDK, und das Gateway übersetzt die Anfrage über eine Adapterschicht in das native Format des Anbieters.
Der zweite ist der native SDK-Durchleitung Muster unter {GATEWAY_BASE_URL}/tts/{providerAccountName}. Anbieter mit umfangreichen nativen APIs, die sich nicht sauber auf das OpenAI-Format abbilden lassen (Deepgram und Cartesia und ElevenLabs und Gemini und Vertex), finden hier Anschluss. Die vollständige Struktur der Anbieteranfrage und -antwort bleibt erhalten. Das Gateway übernimmt Authentifizierung, Zugriffskontrolle, Tracing und Routing, schreibt die Nutzlast jedoch nicht um. Dies ist das Muster, das Resemble verwendet, da der Resemble-Anfragekörper mit voice_uuid und audio_timestamps und Präzisionsstufen und dem chatterbox-turbo Modellselektor kein Äquivalent im OpenAI TTS-Vertrag hat.
Wenn eine Anfrage einen Gateway-Pod erreicht, sieht der Pfad wie folgt aus. Der TrueFoundry-Token im Authorization-Header wird anhand von gecachten IdP-Public-Keys validiert. Die Team-Identität wird anhand einer In-Memory-Map aufgelöst und die Autorisierung für das Resemble-Anbieterkonto überprüft. Der Anfragekörper wird an den Resemble Synthesize- oder Stream-Endpunkt weitergeleitet, wobei der Resemble-Bearer-Token serverseitig angehängt wird. Die Antwort wird an den Client zurückgestreamt. Die gesamte Interaktion wird in einem Trace-Span erfasst, zusammen mit dem Modellnamen, dem Anbieterkonto, der Anzahl der Eingabezeichen, der Antwortdauer, der Synthesedauer und der Latenz. Es gibt keine zusätzlichen Roundtrips über den eigentlichen Anbieteraufruf hinaus.
Resemble wird in der TrueFoundry-Steuerungsebene als Anbieterkonto registriert, wobei der Resemble-Bearer-Token als Geheimnis gespeichert wird. Sobald das Konto hinzugefügt wurde, stellt das Gateway zwei TTS-Routen dafür bereit. Die native SDK-Route unter {GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize leitet Anfragen an den synchronen Endpunkt weiter. Die Streaming-Route unter {GATEWAY_BASE_URL}/tts/{providerAccountName}/stream leitet Anfragen an den Streaming-Endpunkt weiter. Beide Routen bewahren die Resemble-Anfrage- und -Antwortstruktur exakt.
Ein minimaler Client-Aufruf sieht aus wie das untenstehende Snippet. Beachten Sie, dass die einzige Änderung gegenüber einem direkten Resemble-Aufruf die Basis-URL und der Authentifizierungs-Header sind.
curl -X POST {GATEWAY_BASE_URL}/tts/resemble-prod/synthesize \
-H "Authorization: Bearer ${TFY_API_KEY}" \
-H "Content-Type: application/json" \
-d '{ "voice_uuid": "55592656",
"data": "Hello from the gateway.",
"model": "chatterbox-turbo",
"output_format": "mp3",
"use_hd": false }'Bestehender Anwendungscode, der direkt auf Resemble abzielt, migriert durch den Austausch der Basis-URL und des Bearer-Tokens. Voice-UUIDs, SSML-Payloads, Präzisionseinstellungen und der HD-Modus werden alle ohne Änderungen übernommen. Die offiziellen Client-Bibliotheken von Resemble können auf die gleiche Weise konfiguriert werden, indem ihre Basis-URL überschrieben wird.
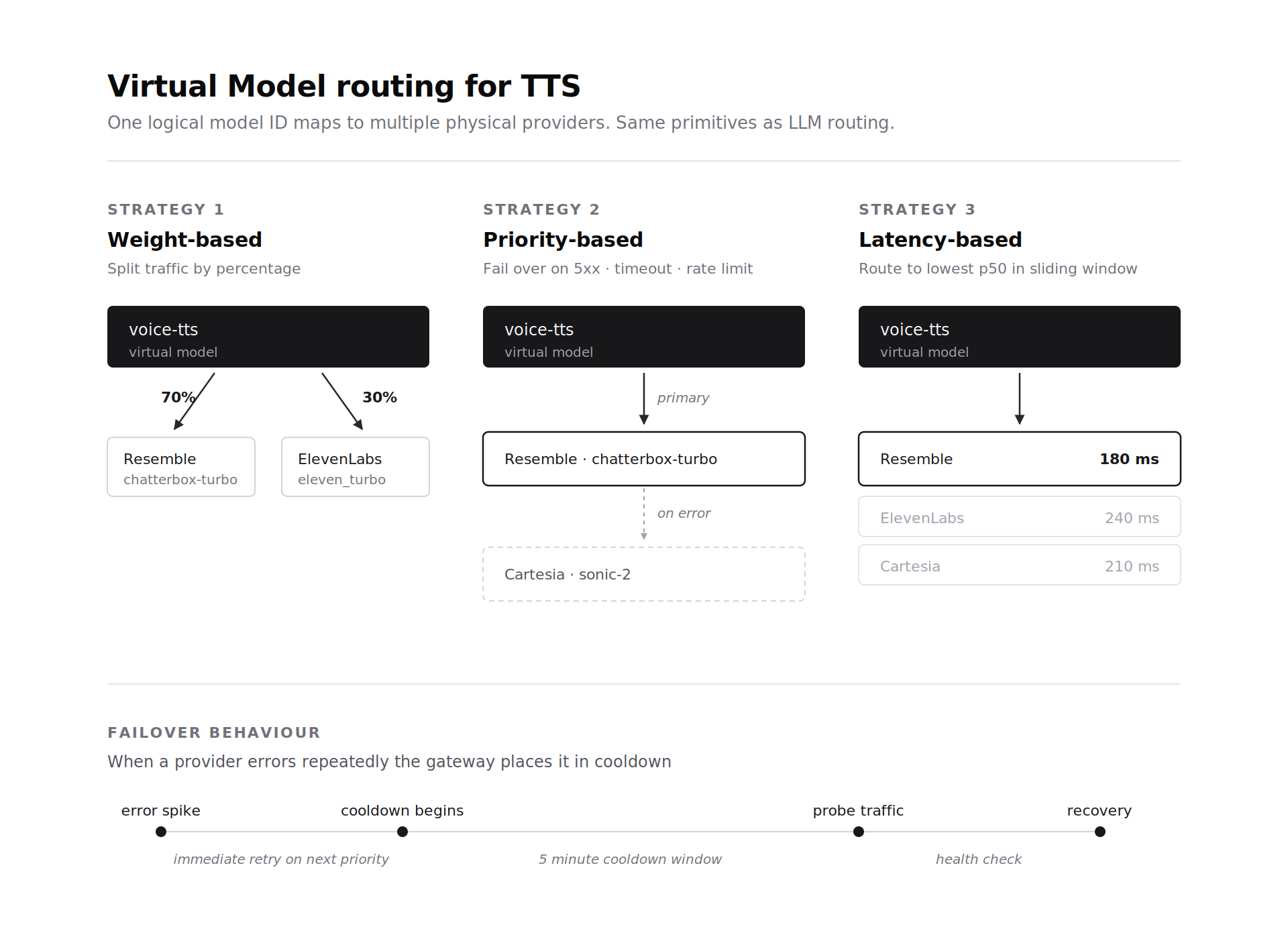
Voice-Agent-Stacks verwenden in der Produktion oft mehr als einen TTS-Anbieter aus Kosten- und Latenzgründen. Die Virtual-Model-Abstraktion des Gateways erstreckt sich auf TTS-Anbieter auf die gleiche Weise wie auf LLM-Anbieter. Ein virtueller Modell-Identifikator wird einem oder mehreren physischen TTS-Bereitstellungen mit Routing-Regeln zugeordnet. Gewichtsbasiertes Routing verteilt den Traffic prozentual auf die Anbieter. Prioritätsbasiertes Routing versucht es mit dem ersten Anbieter und wechselt bei einem 5xx-Fehler, einem Timeout oder einer Ratenbegrenzung auf einen anderen. Latenzbasiertes Routing leitet den Traffic an den Anbieter weiter, der die niedrigste p50-Latenz im gleitenden Fenster aufweist.
Das Failover für TTS funktioniert mit denselben Primitiven wie das LLM-Failover. Nicht wiederholbare Fehler lösen einen sofortigen Wiederholungsversuch beim nächsten Prioritätsanbieter aus. Fehlerspitzen versetzen einen Anbieter in eine 5-minütige Abklingzeit, und Sondierungs-Traffic prüft auf Wiederherstellung. Ein Team, das Resemble Chatterbox Turbo als primären Pfad mit geringer Latenz betreibt, kann ohne Änderung des Client-Codes auf Cartesia oder ElevenLabs ausweichen. Das Virtual Model übernimmt die Auswahl.
Die Kostenverfolgung erfasst die TTS-Nutzung mit der gleichen Granularität wie die LLM-Nutzung. Das Gateway erfasst für jede Anfrage die Anzahl der Eingabezeichen, die Synthesedauer, das Modell, das Team und den Benutzer. Der Aggregator-Dienst berechnet die Ausgaben pro Team und pro Benutzer und speist dieselben Dashboards und Budgetdurchsetzungs-Primitive, die bereits Chat-Completions und Embeddings abdecken. Ratenbegrenzungen werden durch den Sliding Window Token Bucket Algorithmus angewendet, mit Minutenfenstern, die auf Benutzer, Team oder Modell bezogen sind. Für TTS ist die Einheit Zeichen oder Anfragen statt Tokens, aber der Algorithmus bleibt unverändert.
Jede TTS-Anfrage erzeugt einen Trace-Span. Die Span-Attribute umfassen das Anbieterkonto und den Modell-Identifikator (zum Beispiel resemble-prod/chatterbox-turbo) sowie die Anzahl der Eingabezeichen, die Antwortdauer in Sekunden, die Roh-Synthesezeit, das Ausgabeformat, die Abtastrate und die Gateway-seitige Latenz. Traces werden asynchron über NATS ausgegeben und via OTEL an jedes vom Team konfigurierte Observability-Backend (Arize oder Langfuse oder LangSmith oder jedes der unterstützten Ziele) exportiert. Die Option „Anfragedaten ausschließen“ (Exclude Request Data) funktioniert auf die gleiche Weise wie bei Chat-Completions, um den Eingabetext aus exportierten Traces herauszuhalten, wenn der Datenschutz dies erfordert.
Das bedeutet, dass TTS-Aufrufe in derselben Trace-Timeline erscheinen wie der vorgelagerte LLM-Aufruf, der den Text erzeugt hat, und die nachgelagerte Agentenaktion, die das Audio verbraucht hat. Für das Debugging von Sprachagenten ist diese Konsolidierung wichtig. Eine fehlgeschlagene Interaktion kann von der LLM-Vervollständigung, die die Antwort ausgewählt hat, über die TTS-Synthese, die sie gerendert hat, bis hin zur nächsten Aktion des Agenten zurückverfolgt werden.
Der End-to-End-Anfragefluss sieht wie folgt aus. Ein Client sendet eine TTS-Anfrage an das Gateway unter {GATEWAY_BASE_URL}/tts/{providerAccountName}/synthesize oder an dessen Streaming-Pendant mit einem TrueFoundry Bearer-Token. Das Gateway authentifiziert den Aufrufer anhand zwischengespeicherter IdP-Schlüssel, löst das Anbieterkonto auf und überprüft die Team- und Benutzerautorisierung im Speicher. Wenn ein virtuelles Modell verwendet wird, wählt die Routing-Logik einen physischen Anbieter basierend auf Gewichtung, Priorität oder Latenz aus. Der Anfragetext wird an Resemble weitergeleitet, wobei das serverseitige Resemble Bearer-Token angehängt wird. Die Antwort wird an den Client zurückgestreamt, wobei die vollständige Resemble-Payload-Struktur einschließlich Audioinhalt, Zeitstempeln und Dauer-Metadaten erhalten bleibt. Jeder Schritt wird in einem Trace-Span erfasst, der asynchron an NATS gesendet und über OTEL exportiert wird.
An der Anwendung muss nichts weiter geändert werden. Es ist keine Neuentwicklung des SDK erforderlich, keine anbieterspezifische Authentifizierung auf Clientseite und keine separate Observability-Pipeline für Sprachverkehr. Das Gateway befindet sich bereits im Anforderungspfad für den Rest des KI-Stacks, und Resemble bindet sich über natives Pass-Through in diesen Pfad ein. Bestehender Resemble-Client-Code funktioniert weiterhin mit einem Austausch der Basis-URL.
Erfahren Sie mehr über das TrueFoundry AI Gateway und die Resemble AI-Plattform. Fügen Sie Resemble als Anbieterkonto in der Gateway-Steuerungsebene hinzu und rufen Sie den Synthese- oder Stream-Endpunkt unter der Route /tts/{providerAccountName} aus dem bestehenden Anwendungscode auf.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.



.webp)











.webp)
.webp)