













Mehr als 1000 globale Marken vertrauen uns
Bedienen Sie jedes Modell, jedes Framework
Generative KI
Bieten Sie jedes Hugging Face-Modell in Text, Bild, multimodal und Audio an, mit voller Unterstützung für OpenAI-kompatible Endgeräte
Traditionelles ML
Stellen Sie mit XGBoost, Scikit-Learn und LightGBM erstellte Modelle mühelos bereit und skalieren Sie sie für zuverlässige, leistungsstarke Vorhersagen.
Tiefes Lernen
Führen Sie produktionsfertige Modelle aus, die mit PyTorch, TensorFlow oder Keras entwickelt wurden und für Geschwindigkeit, Skalierbarkeit und Stabilität optimiert sind.
Benutzerdefinierte Behälter
Stellen Sie vollständig angepasste Inferenz-Pipelines mit Ihren eigenen Docker-Containern bereit, um die vollständige Kontrolle über Laufzeit und Abhängigkeiten zu haben.
LAPPEN
Stellen Sie Einbettungsmodelle, Reranker und Vektordatenbanken bereit, um genaue, kontextsensitive KI-Anwendungen zu erstellen.
Vision-Modelle
Stellen Sie jedes Computer-Vision-Modell mühelos bereit und skalieren Sie es — von der Bildklassifizierung bis hin zum erweiterten visuellen Verständnis.

Überall ausführen: Cloud, On-Prem oder Edge
- Vollständig cloudnative Kubernetes-basierte Bereitstellungen
- Bereitstellen am AWS, GCP, Azure, lokal, oder bei der Kante
Müheloses Auto-Scaling auf CPUs/GPUs
- Unterstützt sowohl CPU- als auch GPU-intensive Modelle
- Auf Null skalieren oder bei Bedarf automatisch skalieren
.webp)

Sicherer und kontrollierter Zugriff
- Feingranulare rollenbasierte Zugriffskontrolle
- Token-basierte Authentifizierung und API-Sicherheit
Batch- und Streaming-Inferenz
- Stellen Sie Prognosen in Echtzeit über REST oder gRPC bereit
- Batch-Inferenz planen oder auslösen
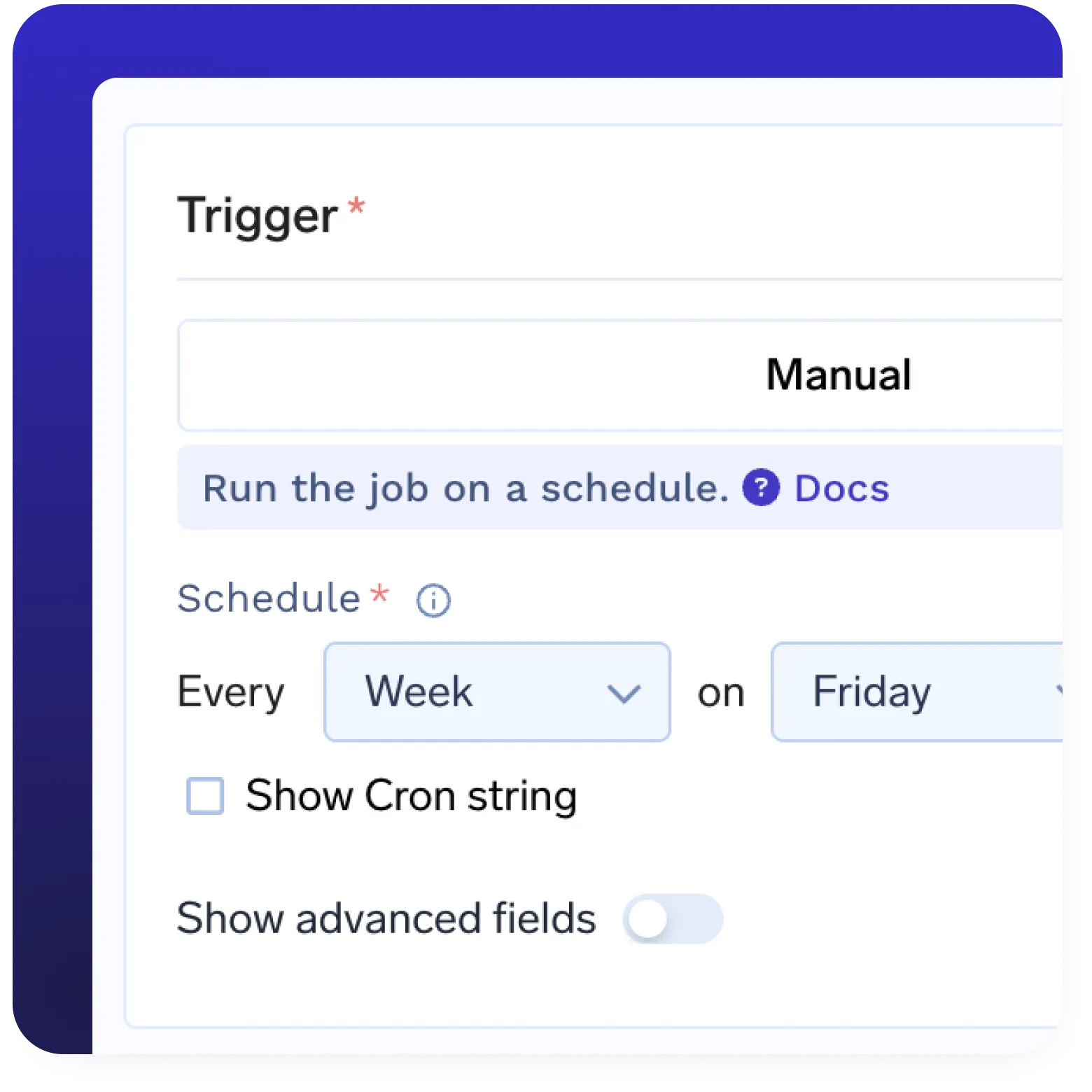

Eingebaute Modellregistrierung
- Eingebaute umfassende Modellregistrierung
- Modelle automatisch aus der Registrierung bereitstellen
- Versionen und Metadaten verwalten
Vollständige Beobachtbarkeit und Überwachung
- Native Unterstützung für Prometheus, Grafana und OpenTelemetry
- Protokolle, Traces und Metriken in Echtzeit
- Überblick über Bereitstellung, Nutzung und Systemzustand
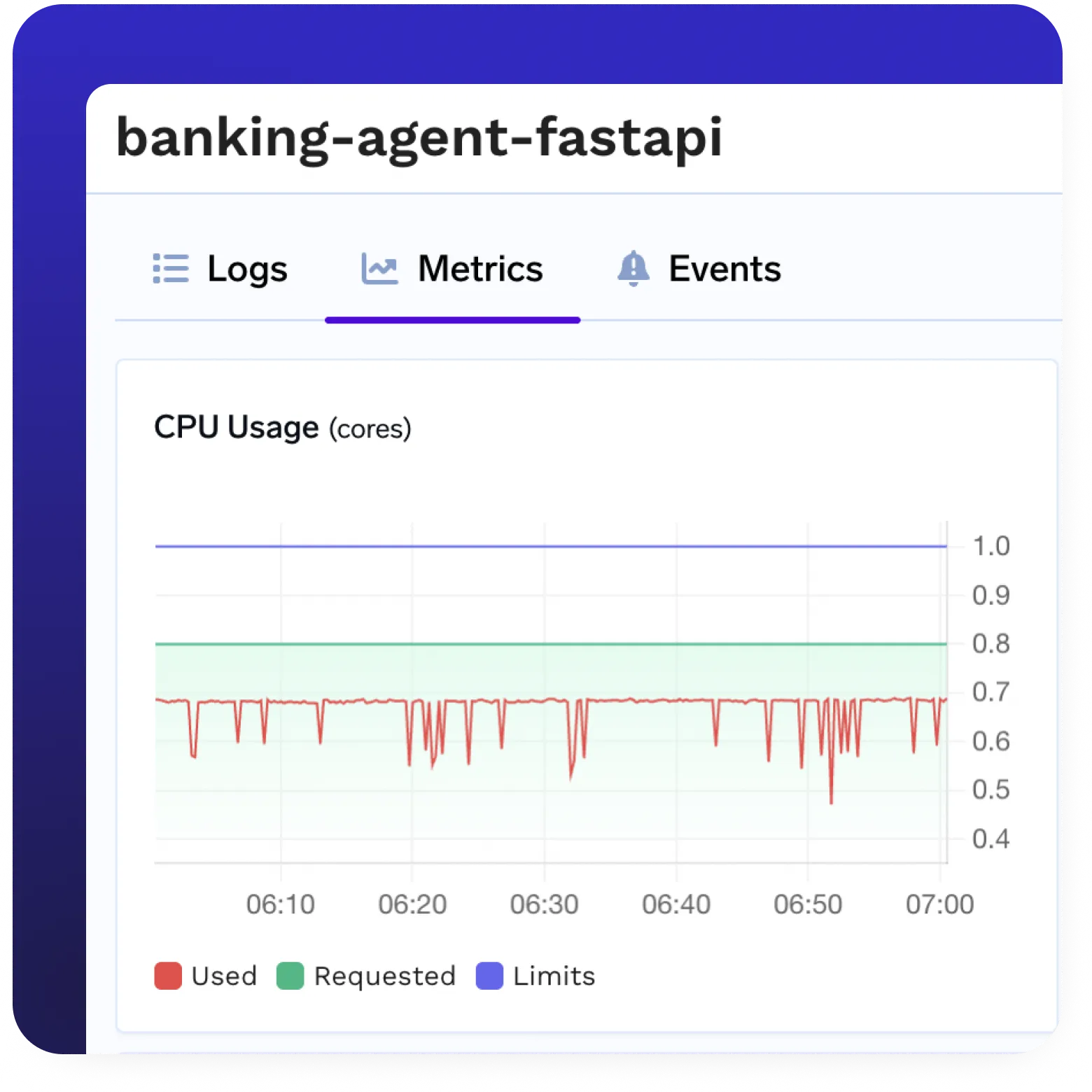

Herrliches Entwicklererlebnis
- Intuitive Benutzeroberfläche, SDK und CLI zum Verwalten, Testen und Überwachen Ihrer Modelle.
- Von der lokalen Entwicklung bis zur Produktion steht der Entwickler an erster Stelle.
Kostengünstig
- Intelligente Infrastrukturoptimierung
- Effiziente GPU-Auslastung und Spot-Instance-Unterstützung
- Keine Anbieterbindung

Bereit für Unternehmen
Ihre Daten und Modelle sind sicher in Ihrer Cloud-/On-Prem-Infrastruktur untergebracht.

Vollständig modulare Systeme
Integriert und ergänzt Ihren bestehenden StackEchte Konformität
SOC 2-, HIPAA- und DSGVO-Standards zur Gewährleistung eines robusten DatenschutzesVon vornweg sicher
Flexible rollenbasierte Zugriffskontrolle und Audit-TrailsAuthentifizierung nach Industriestandard
SSO-Integration über OIDC oder SAML

GenAI infra- einfach, schneller, günstiger
Mehr als 30 Unternehmen und Fortune-500-Unternehmen vertrauen darauf
Testimonials TrueFoundry macht Ihr ML-Team 10x schneller
.webp)
Deepanshi S
Leitender Datenwissenschaftler



Matthieu Perrinel
Leiter ML


Soma Dhavala
Direktor für maschinelles Lernen


Rajesh Chaganti
CTO


Summit Rao
AVP für Datenwissenschaft


Vivek Suyambu
Leitender Softwareingenieur










