











LLMs
Implementieren und verwalten Sie Open-Source-LLMs oder proprietäre LLMs mit GPU-Beschleunigung und Zuverlässigkeit auf Produktionsniveau.
Agenten
Führen Sie KI-Agenten mit langer Laufzeit mit Speicher, Werkzeugausführung und nahtloser Integration mit AI Gateway- und MCP-Servern aus
MCP-Server
Stellen Sie MCP-Server bereit, um Tools, APIs und Unternehmenssysteme sicher für KI-Agenten bereitzustellen.
Arbeitsabläufe
Orchestrieren Sie mehrstufige KI-Workflows für Modelle, Agenten und Dienste von einer einzigen Steuerungsebene aus.
Jobs
Führen Sie Batch-Jobs, Trainingsworkloads und geplante KI-Aufgaben bei Bedarf aus.
Klassische ML-Modelle
Stellen Sie traditionelle Modelle für maschinelles Lernen zusammen mit LLMs auf derselben Plattform bereit und bieten Sie sie an.
.webp)
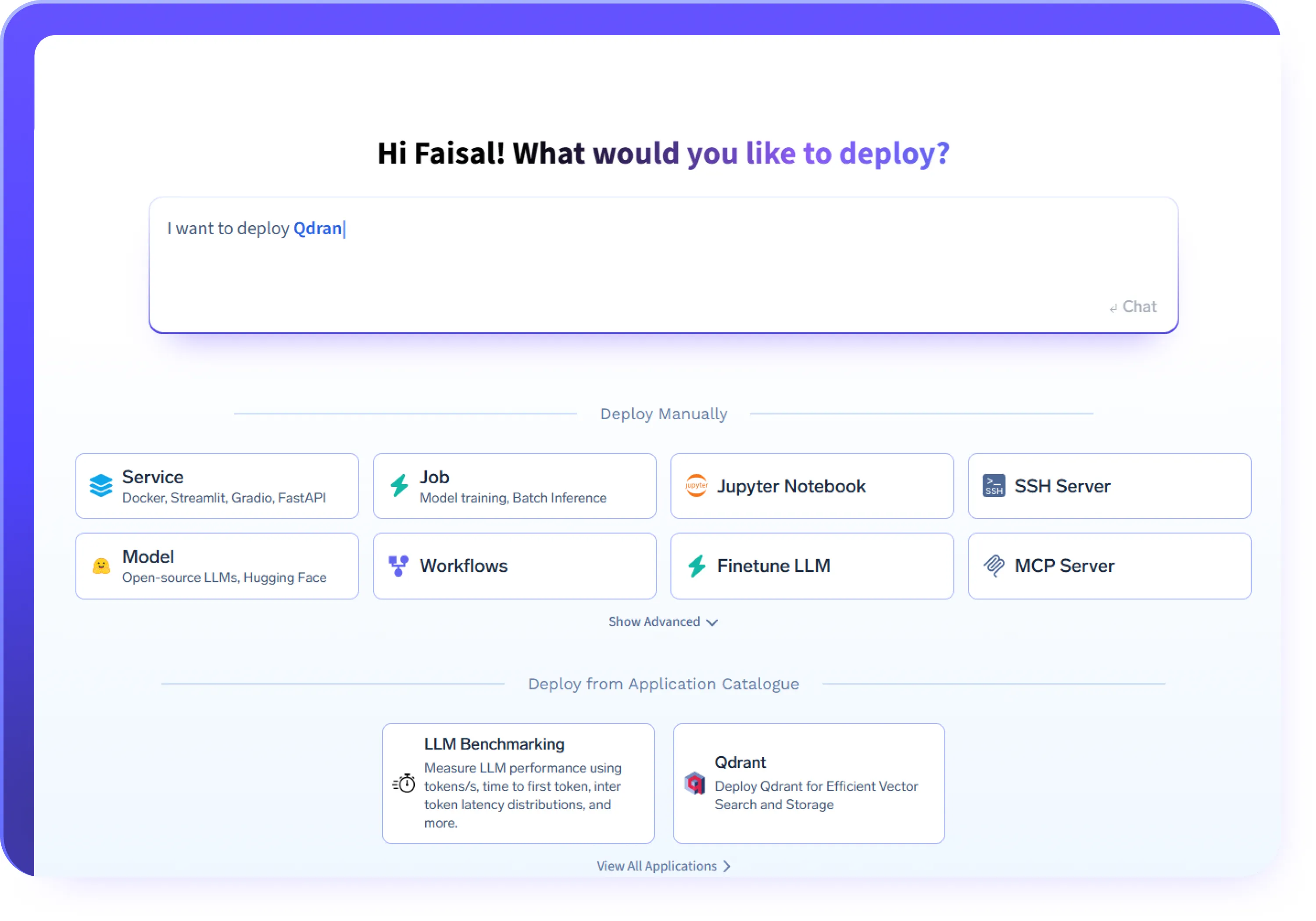
Stellen Sie beliebige KI-Workloads bereit
- Stellen Sie LLMs und GPU-basierte Inferenz-Workloads mithilfe von Frameworks wie vLLM, Triton, kServe oder benutzerdefinierten Containern bereit
- Stellen Sie KI-Agenten und Agentendienste mit konsistenter Laufzeit und Netzwerk bereit
- Stellen Sie MCP-Server bereit, um Tools und interne Systeme sicher verfügbar zu machen
- Führen Sie Batch-Jobs, APIs und KI-Dienste mit langer Laufzeit auf derselben Plattform aus
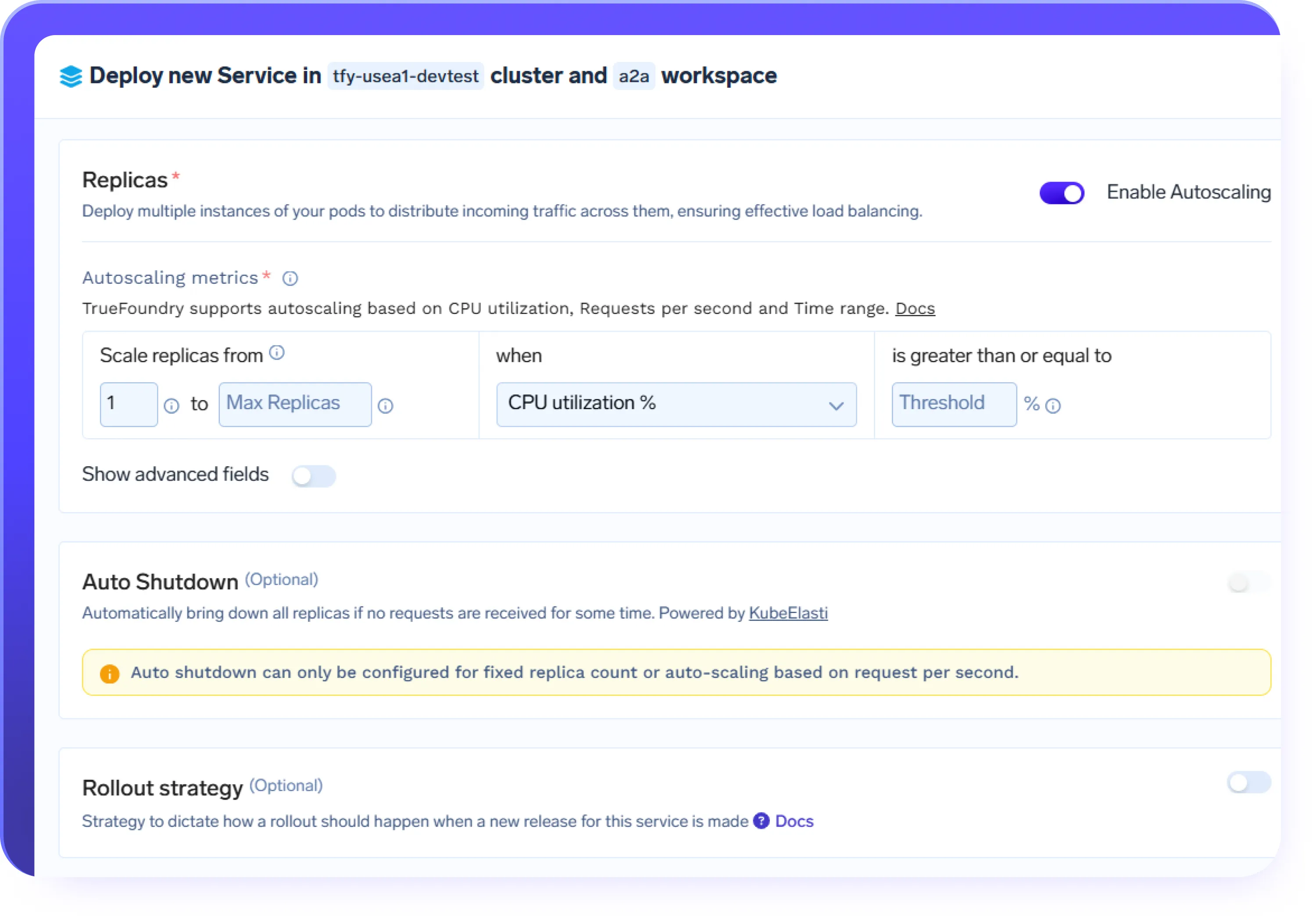
Autoscaling für KI-Workloads
Nachfrage.
- Automatische Skalierung von Inferenzendpunkten und Agentendiensten auf der Grundlage des Anforderungsvolumens
- Skalieren Sie die GPU-Workloads bei Spitzennachfrage hoch und reduzieren Sie sie, wenn der Traffic sinkt
- Unterstützt intensive Workloads wie Chat, RAG und agentengesteuerte Workflows
- Sorgen Sie bei Verkehrsspitzen für eine vorhersehbare Leistung
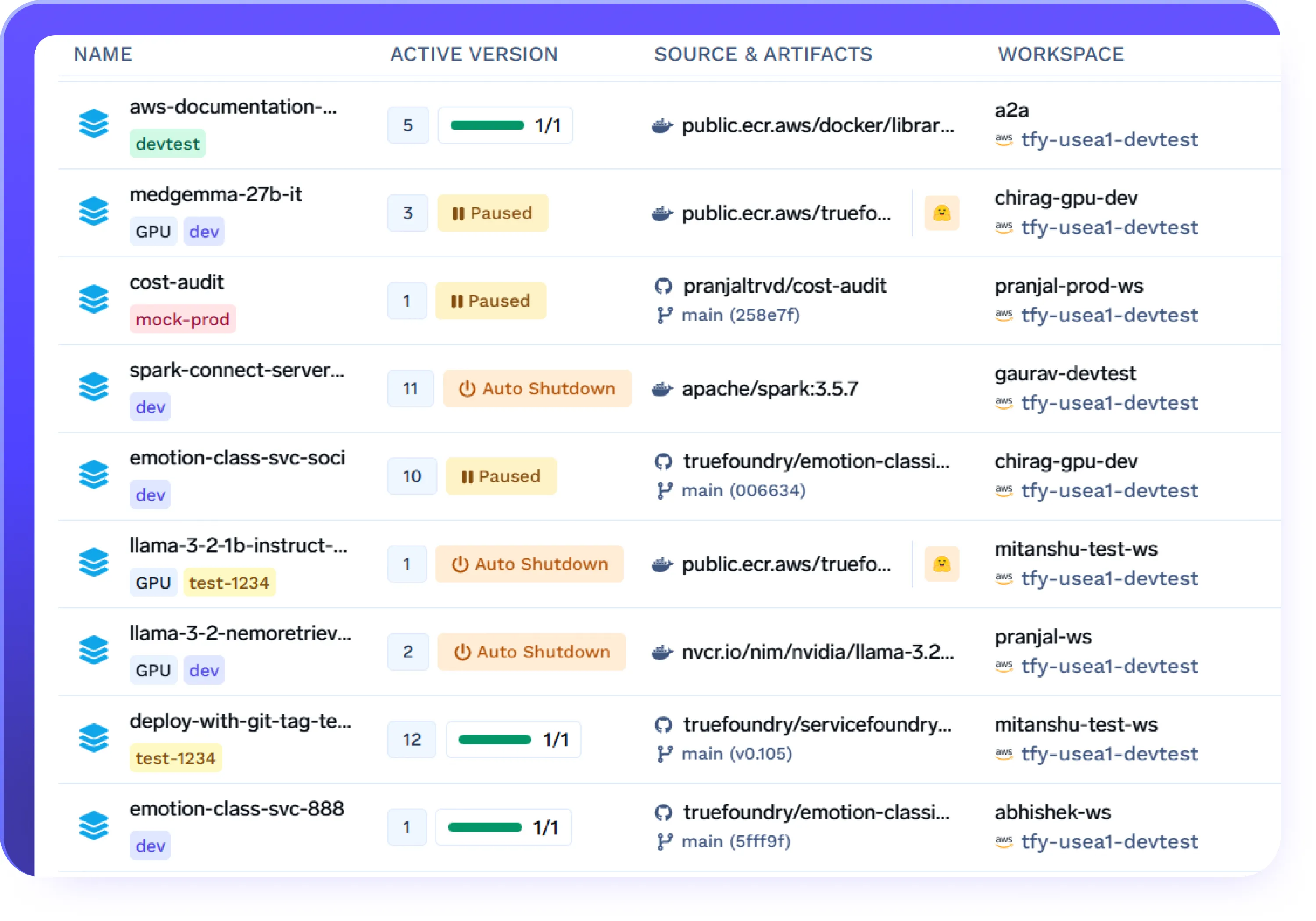
Automatische Abschaltung zur Kostenkontrolle
- Automatisches Herunterfahren von Endpunkten, Agenten oder Diensten nach konfigurierbaren Ruhezeiten
- Reduzieren Sie den GPU-Verbrauch außerhalb der Spitzenzeiten oder bei Experimenten
- Starten Sie Workloads bei Bedarf ohne manuelles Eingreifen neu
- Kostendisziplin teamübergreifend durchsetzen und
Umgebungen
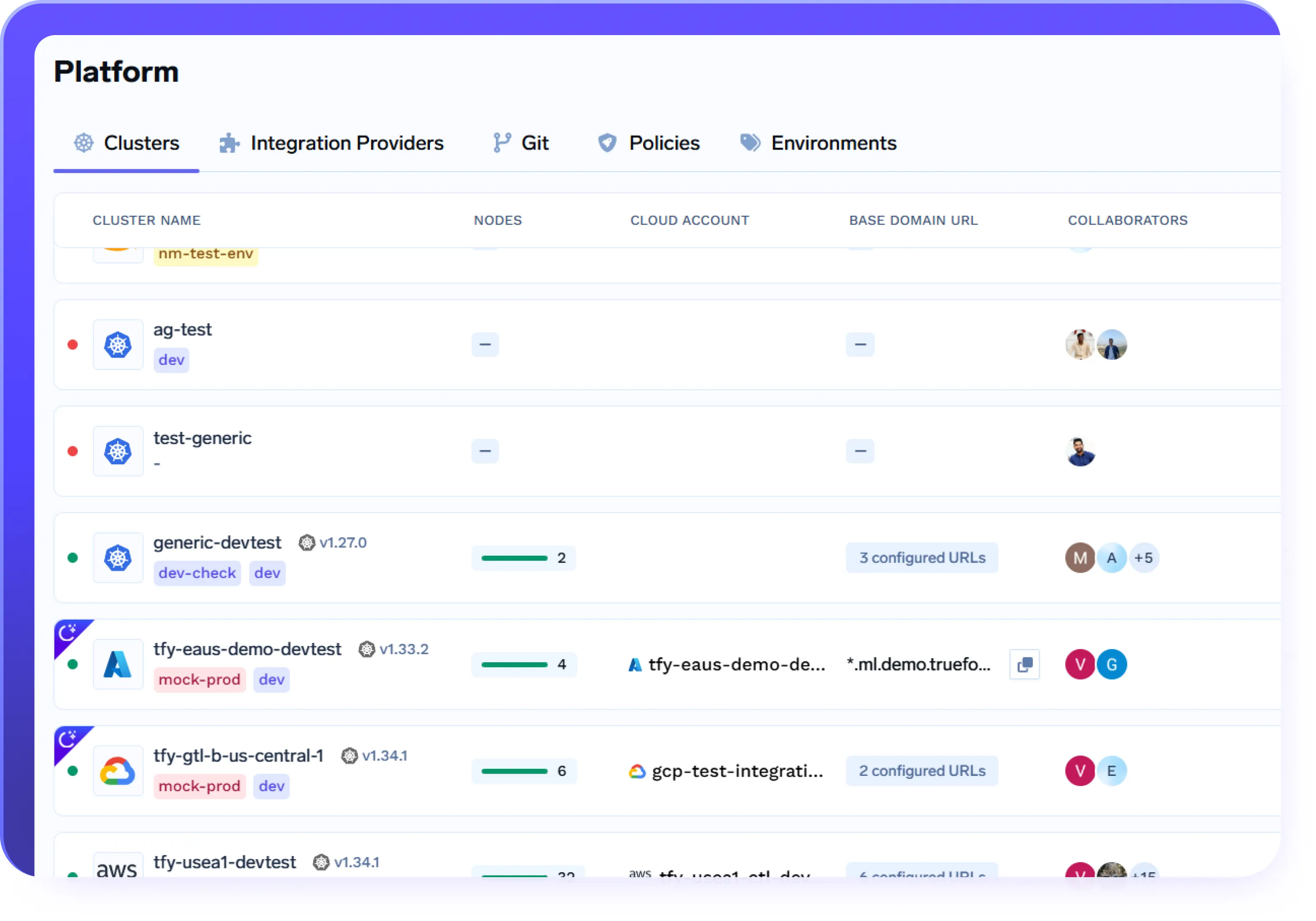
Einheitliches Bereitstellungserlebnis in der Cloud/On-Prem
- Verbinden und verwalten Sie AWS-, Azure-, GCP- und lokale Cluster von einer einzigen Steuerungsebene aus
- Stellen Sie denselben Workload mithilfe identischer Workflows und APIs in verschiedenen Umgebungen bereit
- Abstrahieren Sie cloudspezifische Komplexität und behalten Sie gleichzeitig die volle Kontrolle und Isolierung
- Nutzen Sie die gleiche Bereitstellungserfahrung für Entwicklung, Staging und Produktion, unabhängig von der Infrastruktur
Konzipiert für ein erstklassiges Entwicklererlebnis
- Integrierte Protokolle, Metriken und Ereignisse für jede Bereitstellung
- Systemeigene Überwachung und Warnmeldungen zur schnellen Erkennung und Behebung von Problemen
- Produktionsbereite Bereitstellungsfunktionen wie Integritätsprüfungen und Rollout-Strategien
- Sichere Geheimverwaltung und nahtlose CI/CD-Integrationen
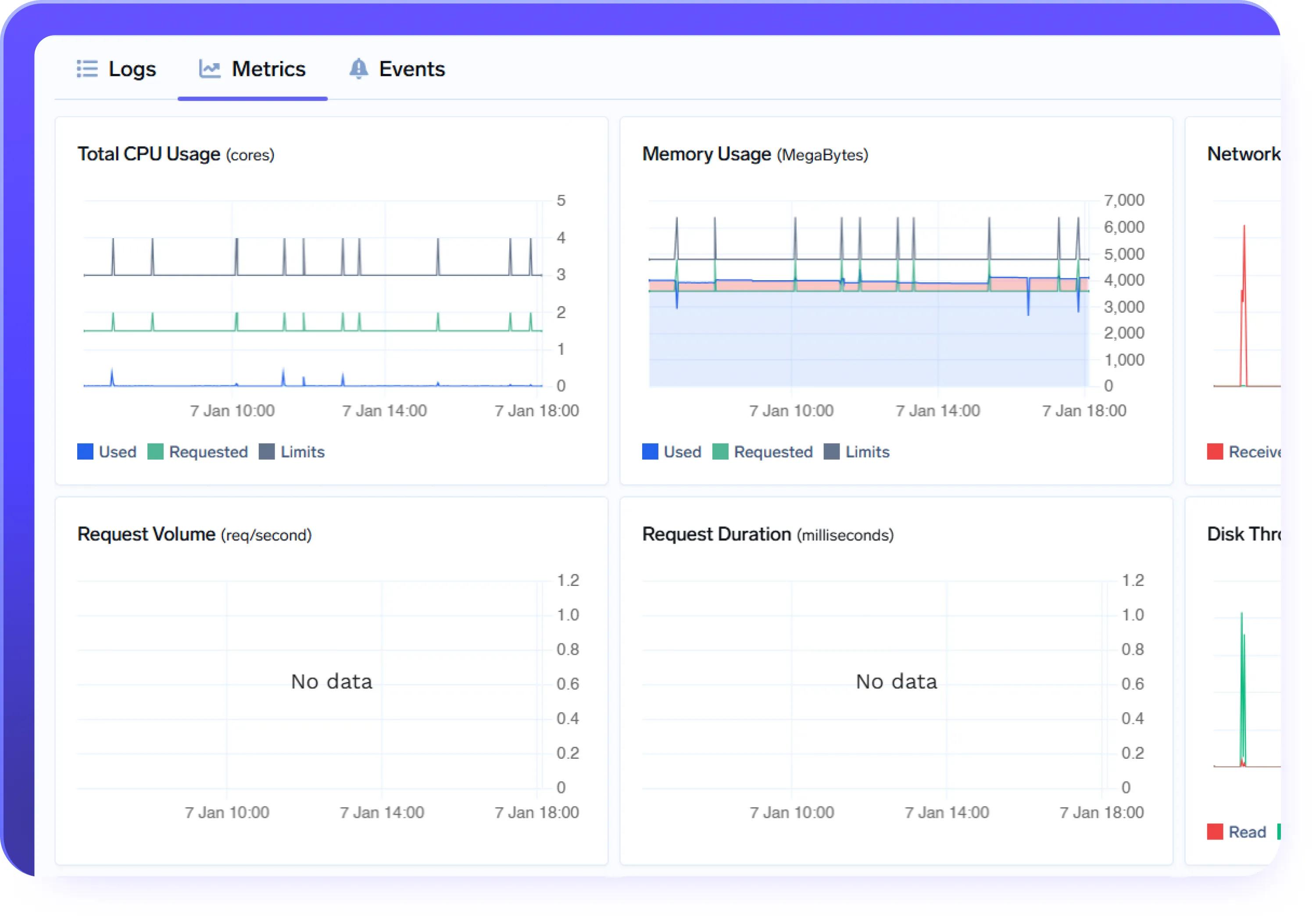
Funktioniert nahtlos mit AI Gateway und Agent Gateway
darüber.
- AI Gateway regelt Modellzugriff, Routing und Kostenkontrolle
- MCP Gateway regelt den Zugriff und die Ausführung von Tools
- Agent Gateway orchestriert und steuert Agenten-Workflows
- Einheitliche KI-Bereitstellungen sorgen für die eigentliche Ausführung und Infrastruktur
Maßstabsgetreu für künstliche Intelligenz in der realen Welt gemacht
Bereit für Unternehmen
Stellen Sie ein sicheres KI-Gateway bereit, das Ihre Daten und Modelle innerhalb Ihrer Cloud-/On-Premise-Infrastruktur hält.


Einhaltung von Vorschriften und Sicherheit
SOC 2-, HIPAA- und DSGVO-Standards um einen robusten Datenschutz zu gewährleistenVerwaltung und Zugriffskontrolle
SSO + Rollenbasierte Zugriffskontrolle (RBAC) und AuditprotokollierungSupport und Zuverlässigkeit für Unternehmen
Support rund um die Uhr mit SLA-Unterstützung Antwort-SLAs
VPC, vor Ort, Airgapped oder über mehrere Clouds hinweg.
Keine Daten verlassen Ihre Domain. Genießen Sie vollständige Souveränität, Isolierung und Compliance auf Unternehmensebene, wo auch immer TrueFoundry ausgeführt wird

Echte Ergebnisse bei TrueFoundry
Warum sich Unternehmen für TrueFoundry entscheiden






3 x
schnellere Amortisierungszeit mit autonomen LLM-Agenten
80%
höhere GPU-Cluster-Auslastung nach automatisierter Agentenoptimierung

Aaron Erickson
Gründer von Applied AI Lab
TrueFoundry hat unsere GPU-Flotte in eine autonome, sich selbst optimierende Engine verwandelt, die 80% mehr Auslastung ermöglicht und uns Millionen an ungenutzter Rechenleistung erspart.
5x
schnellere Produktionszeit der internen KI/ML-Plattform
50%
geringere Cloud-Ausgaben nach der Migration von Workloads zu TrueFoundry

Pratik Agrawal
Leitender Direktor, Datenwissenschaft und KI-Innovation
TrueFoundry hat uns geholfen, in Rekordzeit vom Experimentieren zur Produktion überzugehen. Was über ein Jahr gedauert hätte, war in Monaten erledigt — bei besserer Akzeptanz durch Entwickler.
80%
Verkürzung der Produktionszeit von Modellen
35%
Cloud-Kosteneinsparungen im Vergleich zum vorherigen SageMaker-Setup
.webp)
Vibhas Geji
Mitarbeiter ML Engineer
Wir haben die DevOps-Belastung reduziert und die produktiven Rollouts teamübergreifend vereinfacht. TrueFoundry beschleunigte die ML-Bereitstellung mit einer Infrastruktur, die von Experimenten bis hin zu robusten Services skaliert werden kann.
50%
schnellere RAG-/Agent-Stack-Bereitstellung
60%
Reduzierung des Wartungsaufwands für RAG-/Agent-Pipelines
.webp)
Indronel G.
Intelligenter Prozessführer
TrueFoundry half uns dabei, einen vollständigen RAG-Stack — einschließlich Pipelines, Vektor-DBs, APIs und UI — doppelt so schnell bereitzustellen und dabei die volle Kontrolle über die selbst gehostete Infrastruktur zu haben.
60%
schnellere KI-Bereitstellungen
~ 40-50%
Effektive Kostenreduzierung in allen Entwicklungsumgebungen
.webp)
Nilav Ghosh
Leitender Direktor, KI
Mit TrueFoundry haben wir die Bereitstellungszeiten um mehr als die Hälfte reduziert und den Infrastrukturaufwand durch eine einheitliche MLOps-Schnittstelle gesenkt — was die Wertschöpfung beschleunigt hat.
<2
Wochen, um alle Produktionsmodelle zu migrieren
75%
Verkürzung des Zeitaufwands für die Koordination von Datenwissenschaften, Beschleunigung von Modellaktualisierungen und Feature-Rollouts
.webp)
Rajat Bansal
CTO
Wir haben viel an Infrastrukturkosten gespart und die DS-Koordinationszeit um 75% reduziert. TrueFoundry hat die Geschwindigkeit unserer Modellbereitstellung in allen Teams erhöht.
Häufig gestellte Fragen
Welche Arten von KI-Workloads kann ich mit Unified AI Deployments bereitstellen?
Unterstützt Unified AI Deployments Autoscaling?
Wie funktioniert das automatische Herunterfahren für KI-Workloads?
Kann ich KI-Workloads in meiner eigenen Umgebung bereitstellen?
Wie lässt sich Unified AI Deployments in AI Gateway integrieren?

GenAI infra- einfach, schneller, günstiger
Mehr als 30 Unternehmen und Fortune-500-Unternehmen vertrauen darauf








