












LLMops für Model Serving und Inferenz
.webp)
- Stellen Sie beliebige bereit Open-Source-LLM innerhalb Ihrer LLMOPS-Pipeline mithilfe vorkonfigurierter, leistungsoptimierter Setups
- Nahtlose Integration mit Hugging Face, private Registeroder ein beliebiger Model-Hub — vollständig in Ihrer LLMOPS-Plattform verwaltet
- Nutzen Sie branchenführende Modellserver wie vLLM und SG lang für Inferenz mit niedriger Latenz und hohem Durchsatz
- Aktiviere GPU-Autoskalierung, automatisches Herunterfahren und intelligente Ressourcenbereitstellung in Ihrer gesamten LLMOPS-Infrastruktur.
.webp)
Servieren Sie jeden LLM mit Hochleistungs-Modellserver wie vLLM und sGLang, unterstützt durch GPU-Auto-Scaling und kosteneffiziente LLMOPS-Infrastruktur.
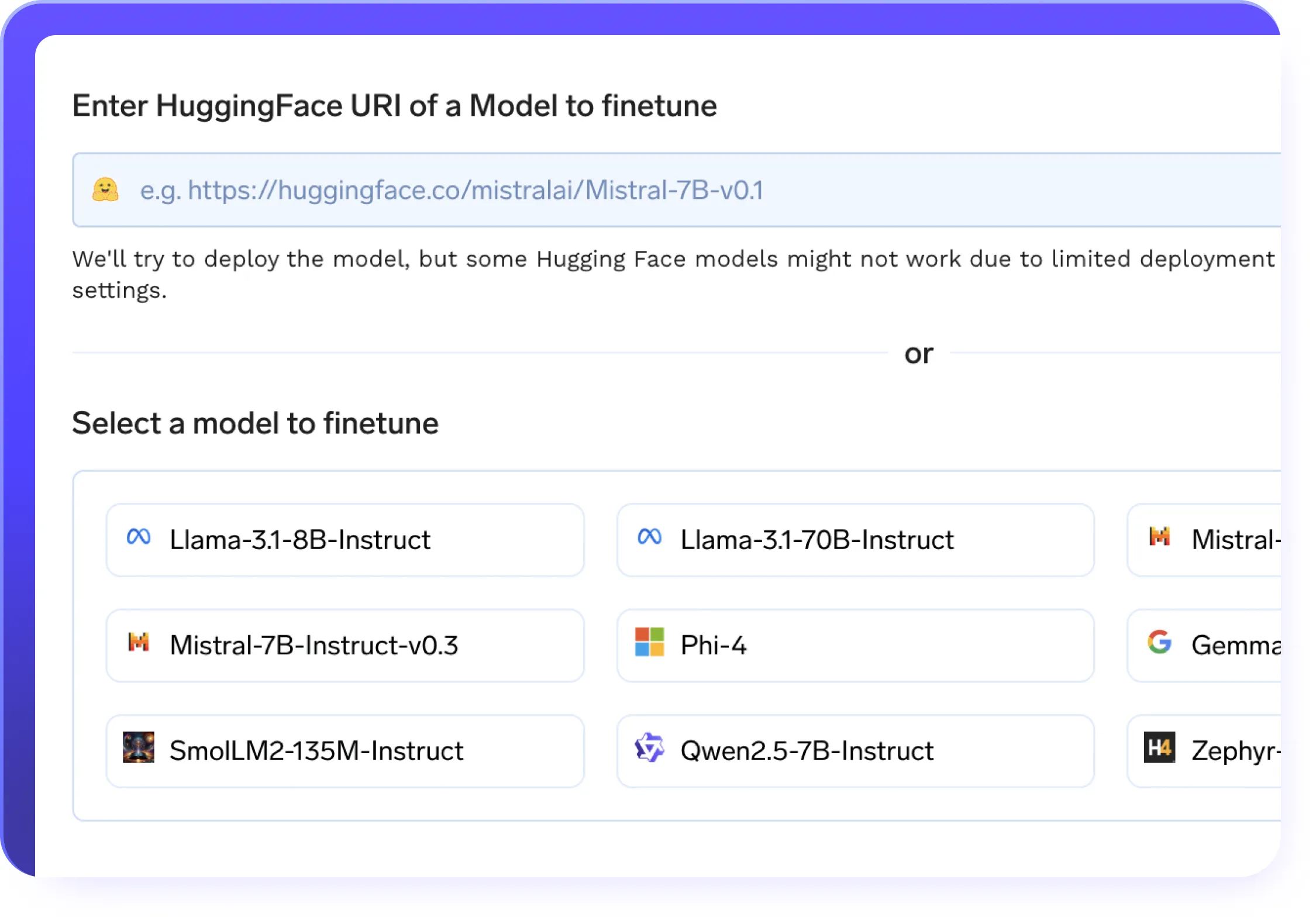
Effizientes Feintuning
- Unterstützung für die Feinabstimmung ohne Code und mit vollem Code für benutzerdefinierte Datensätze
- LoRa und QLora für effiziente Low-Rank-Anpassung
- Setzen Sie das Training nahtlos fort mit Checkpointing Unterstützung für Ihre LLMOPS-Pipelines
- Ein Klick Einsatz fein abgestimmter Modelle mit erstklassigen Modellservern
- Automatisierte Trainingspipelines mit integriertem Verfolgen von Experimenten in Ihre LLMops-Workflows integriert
- Verteilte Trainingsunterstützung für schnellere Modelloptimierung in großem Maßstab
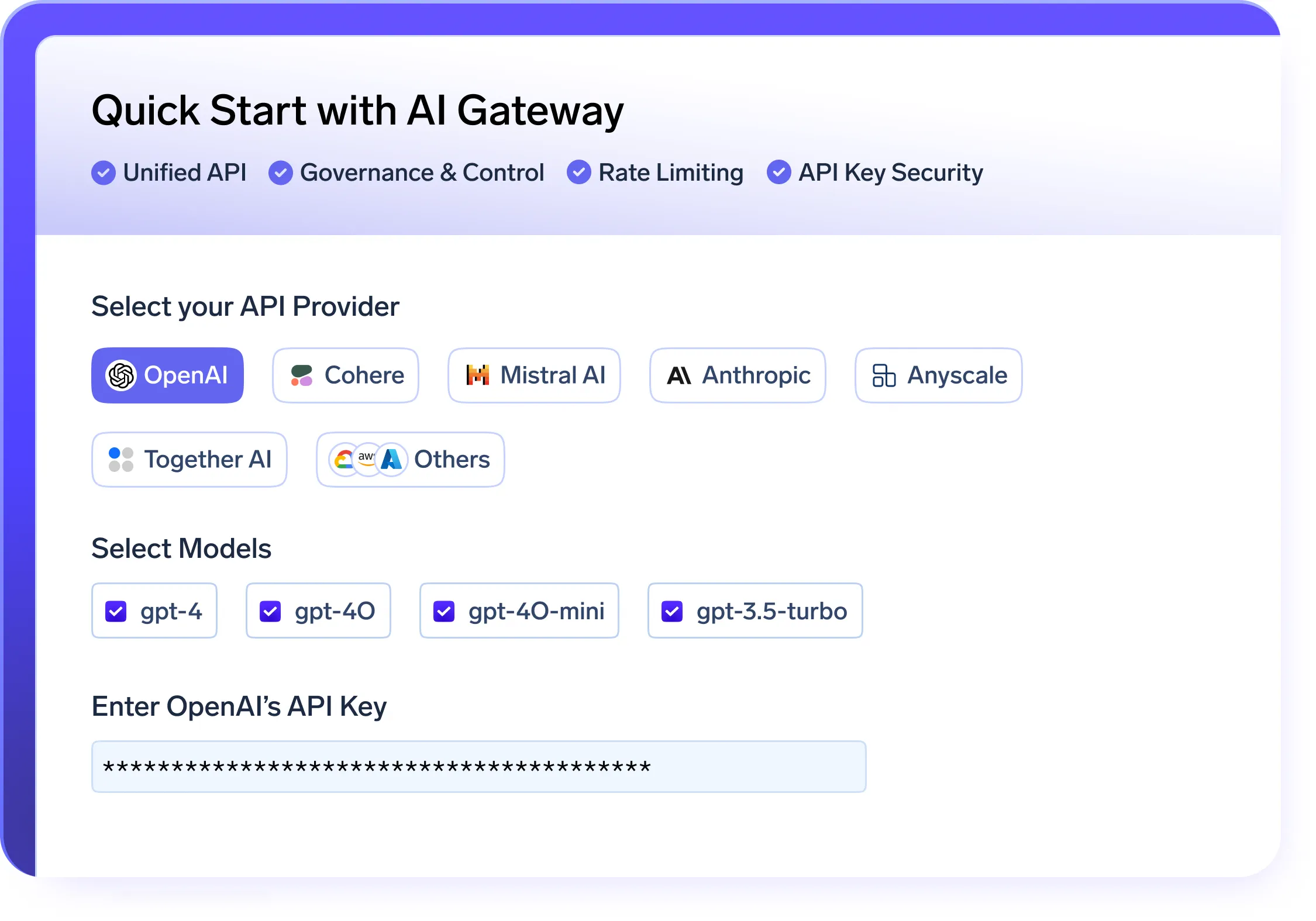
Steuern Sie die KI-Nutzung mit einem AI-Gateway, das vereinheitlicht den Modellzugriff, setzt Kontingente durch und gewährleistet Beobachtbarkeit und Sicherheit.
Sicheres und skalierbares KI-Gateway
- EIN vereinheitlichte API Ebene zur Bereitstellung und Verwaltung von Modellen auf OpenAI, LLama, Gemini und anderen Anbietern
- Eingebaut Verwaltung der Kontingente und Zugriffskontrolle zur Durchsetzung einer sicheren, kontrollierten Modellnutzung innerhalb Ihrer LLMops-Plattform
- Metriken in Echtzeit für Nutzung, Kosten und Leistung zur Verbesserung der LLMOPs-Beobachtbarkeit
- Intelligent Fallback und automatische Wiederholungsversuche um die Zuverlässigkeit Ihrer LLMOPS-Pipelines zu gewährleisten
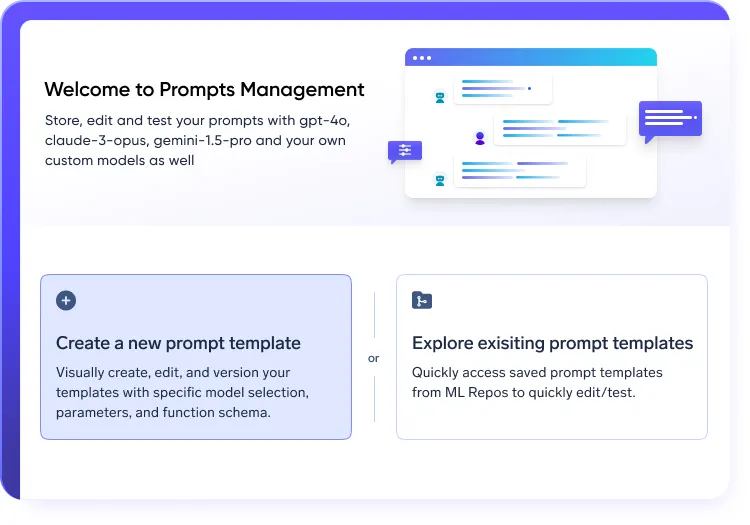
Strukturierte Prompt-Workflows im LLMOPS-Stack
- Experimentieren und iterieren Sie mit versionskontrollierte Eingabeaufforderung Ingenieurwesen
- Lauf A/B-Tests modellübergreifend zur Leistungsoptimierung
- Sorgen Sie für die vollständige Rückverfolgbarkeit schneller Änderungen innerhalb Ihrer LLMops-Plattform
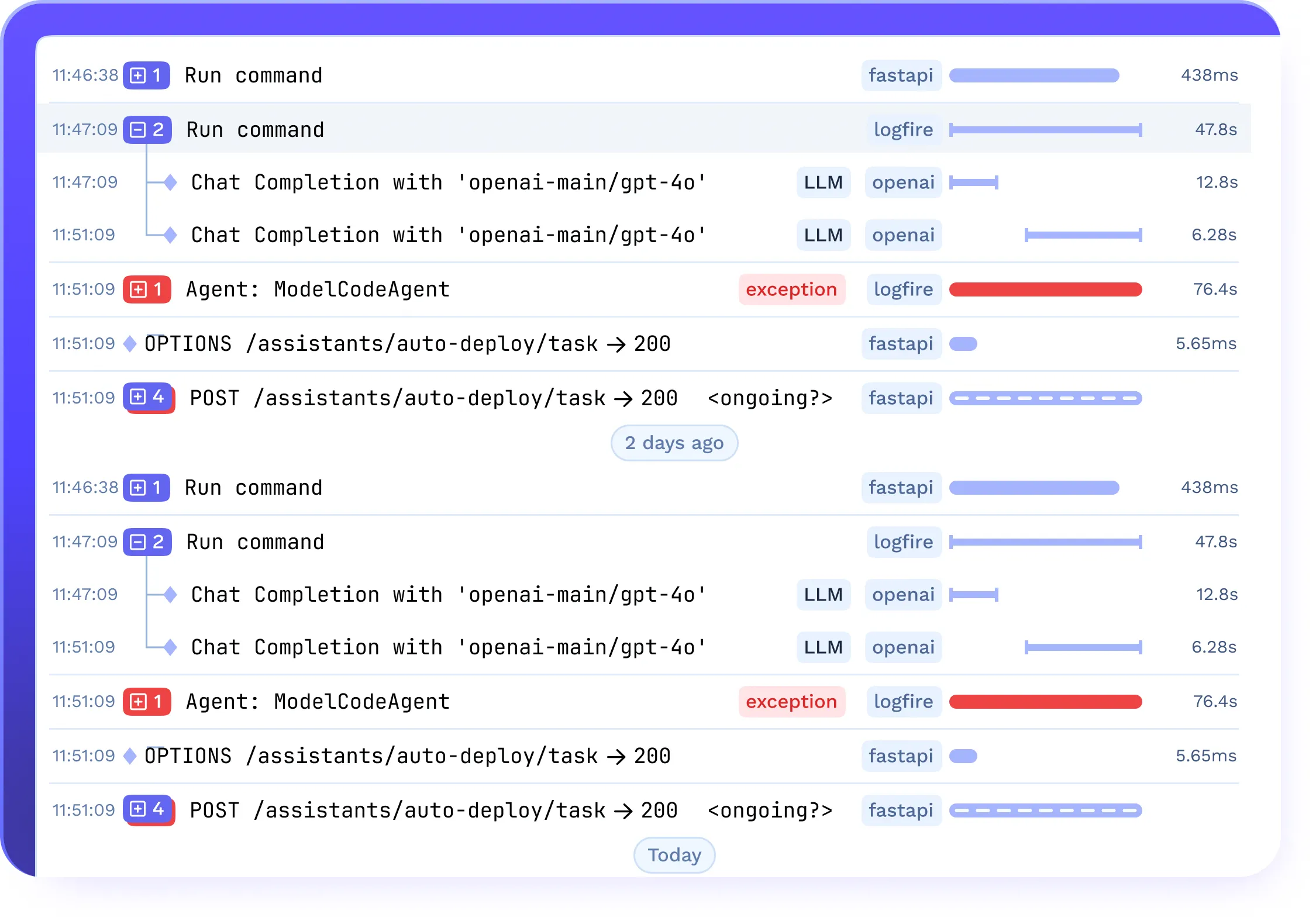
Tracing und Guardrails für LLMOps-Workflows
- Erfassen volle Spuren von Eingabeaufforderungen, Antworten, Token-Nutzung und Latenz
- Überwachen Sie die Leistung, Abschlussraten und Auffälligkeiten
- Integrieren mit Leitplanken für PII-Erkennung und Inhaltsmoderation in LLMOPS-Pipelines
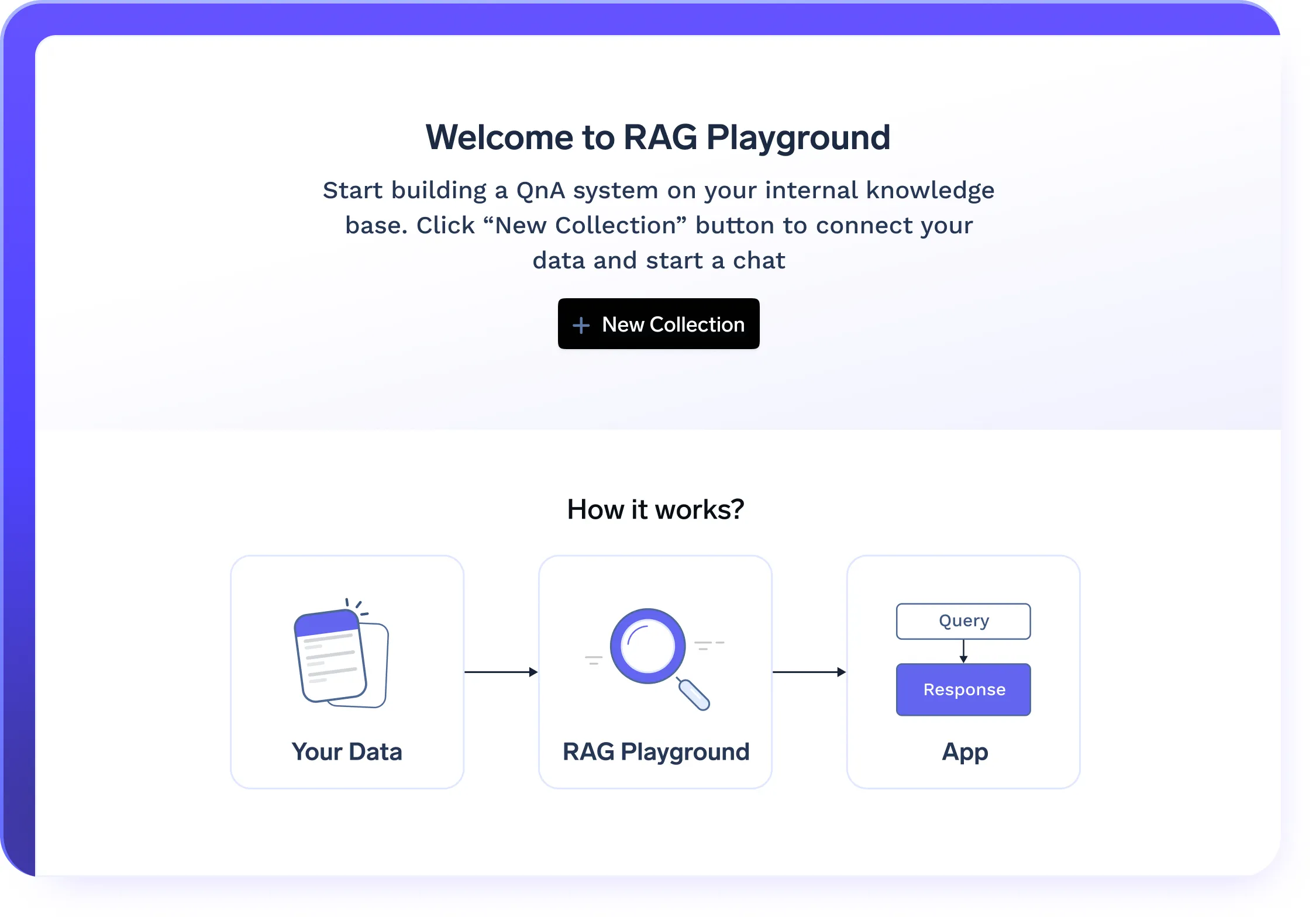
RAG-Bereitstellung mit einem Klick
- Stellt alle RAG-Komponenten mit einem einzigen Klick bereit, einschließlich VectorDB, Einbettungsmodelle, Frontend und Backend
- Konfigurierbare Infrastruktur zur Optimierung der Speicherung, des Abrufs und der Abfrageverarbeitung
- Bewältigen Sie wachsende Dokumentenbasen mit Cloud-nativer LLMOps-Skalierbarkeit
Agenten-Lebenszyklen verwalten — von der Bereitstellung bis zur Beobachtbarkeit — in jedem Framework, unterstützt von Ihrer LLMops-Plattform.
LLMOPs für das Lebenszyklusmanagement von KI-Agenten
- Führen und skalieren Sie Agenten in jedem Framework mithilfe Ihrer LLMOps-Infrastruktur
- Unterstützung für LangChain, AutoGen, CrewAI und benutzerdefinierte Agenten
- Framework-unabhängige Agenten-Orchestrierung mit integrierter LLMOPS-Überwachung
- Unterstützung für die Orchestrierung mehrerer Agenten, sodass Agenten interagieren, Kontext gemeinsam nutzen und Aufgaben autonom ausführen können
.webp)
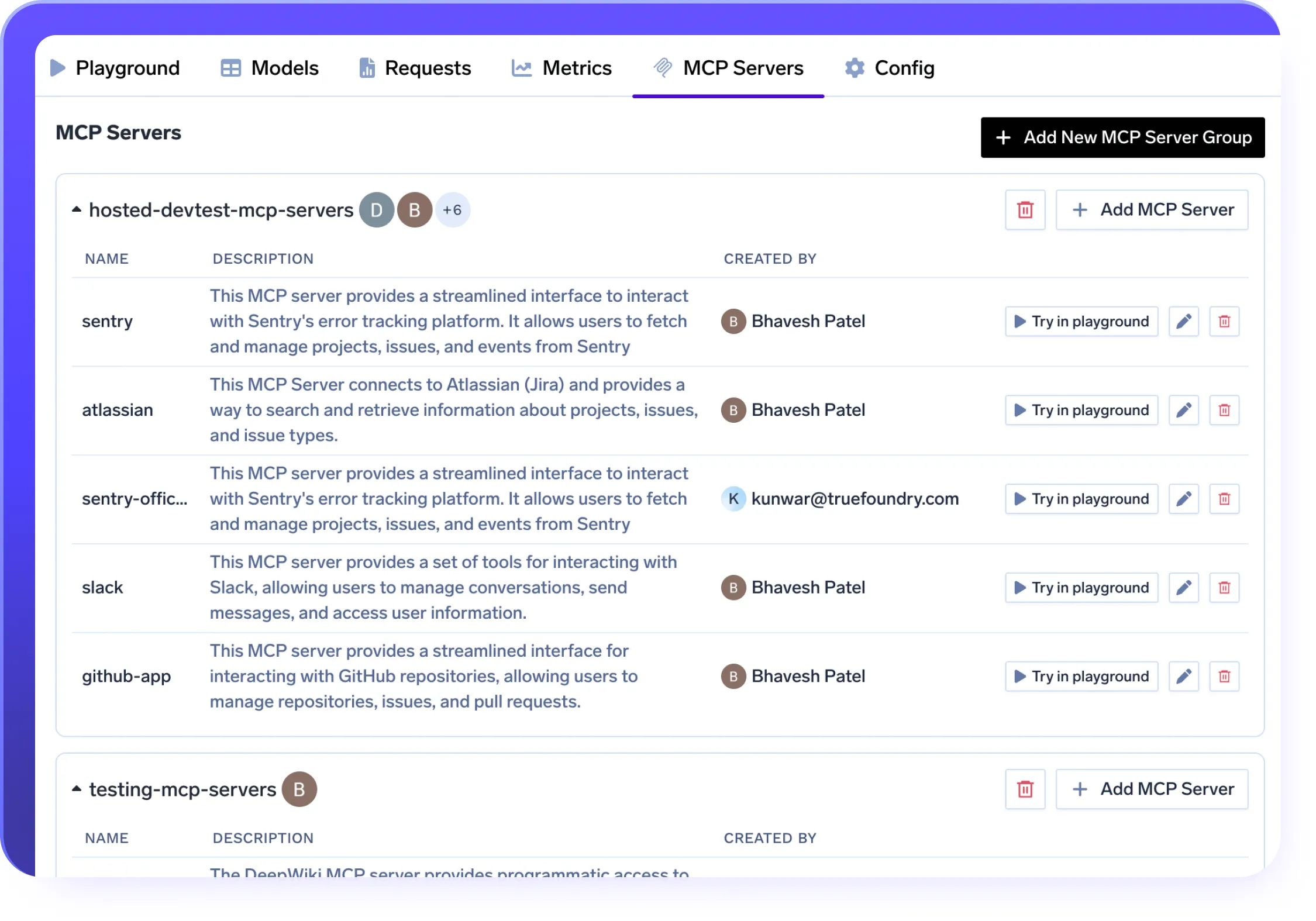
MCP-Serverintegration in Ihren LLMOPS-Stack
- Verbinden Sie LLMs mithilfe des MCP-Protokolls sicher mit Tools wie Slack, GitHub und Confluence
- Stellen Sie MCP-Server in VPC-, lokalen oder Air-Gap-Setups mit voller Datenkontrolle bereit
- Ermöglichen Sie die schnelle Nutzung nativer Tools ohne Wrapper — vollständig in Ihren LLMOPS-Stack integriert
- Steuern Sie den Zugriff mit RBAC, OAuth2 und verfolgen Sie jeden Anruf mit integrierter Observability
Bereit für Unternehmen
Stellen Sie ein sicheres KI-Gateway bereit, das Ihre Daten und Modelle innerhalb Ihrer Cloud-/On-Premise-Infrastruktur hält.


Einhaltung von Vorschriften und Sicherheit
SOC 2-, HIPAA- und DSGVO-Standards um einen robusten Datenschutz zu gewährleistenVerwaltung und Zugriffskontrolle
SSO + Rollenbasierte Zugriffskontrolle (RBAC) und AuditprotokollierungSupport und Zuverlässigkeit für Unternehmen
Support rund um die Uhr mit SLA-Unterstützung Antwort-SLAs
Stellen Sie TrueFoundry in jeder Umgebung bereit
VPC, vor Ort, Airgapped oder über mehrere Clouds hinweg.
Keine Daten verlassen Ihre Domain. Genieße die volle Souveränität, Isolierung und unternehmensweite Compliance, wo auch immer TrueFoundry läuft
Häufig gestellte Fragen
Was ist LLMops und warum ist es wichtig?
LLMops (Large Language Model Operations) bezieht sich auf die Praxis der Verwaltung des gesamten
Lebenszyklus großer Sprachmodelle — von der Schulung und Feinabstimmung bis hin zur Bereitstellung, Inferenz,
Überwachung und Steuerung. LLMops hilft Unternehmen dabei, GenAI-Anwendungen zu integrieren
Produktion zuverlässig und in großem Maßstab. TrueFoundry bietet eine LLMOPS-Plattform für die Produktion
das vereinfacht und beschleunigt den gesamten Prozess.
Lebenszyklus großer Sprachmodelle — von der Schulung und Feinabstimmung bis hin zur Bereitstellung, Inferenz,
Überwachung und Steuerung. LLMops hilft Unternehmen dabei, GenAI-Anwendungen zu integrieren
Produktion zuverlässig und in großem Maßstab. TrueFoundry bietet eine LLMOPS-Plattform für die Produktion
das vereinfacht und beschleunigt den gesamten Prozess.
Wie unterscheidet sich LLMops von herkömmlichen MLOPs?
Während MLops eine Vielzahl von ML-Modellen unterstützt, wurde LLMops speziell für GenAI entwickelt und
große Sprachmodelle. Es umfasst Funktionen wie Modellserver-Orchestrierung, Prompt
Verwaltung, Beobachtbarkeit auf Token-Ebene, Agenten-Frameworks und sicherer API-Zugriff.
Die LLMOPS-Plattform von TrueFoundry verarbeitet diese GENAI-spezifischen Workflows nativ — im Gegensatz
generische MLOps-Tools.
große Sprachmodelle. Es umfasst Funktionen wie Modellserver-Orchestrierung, Prompt
Verwaltung, Beobachtbarkeit auf Token-Ebene, Agenten-Frameworks und sicherer API-Zugriff.
Die LLMOPS-Plattform von TrueFoundry verarbeitet diese GENAI-spezifischen Workflows nativ — im Gegensatz
generische MLOps-Tools.
Warum sollte ich in eine dedizierte LLMOPS-Plattform wie TrueFoundry investieren?
Eine dedizierte LLMOPS-Plattform macht das Zusammenfügen von Infrastruktur-, Überwachungs- und Evaluierungstools überflüssig. TrueFoundry ermöglicht eine sichere Bereitstellung, schnelle Experimente, Beobachtbarkeit und Kostenoptimierung auf einer Plattform. Auf diese Weise können Teams schneller vom Prototyp zur Produktion übergehen und gleichzeitig die Unternehmensführung und Zuverlässigkeit aufrechterhalten.
Was sind die Kernfunktionen der LLMOPS-Plattform von TrueFoundry?
Die LLMOPS-Plattform von TrueFoundry integriert Versionskontrolle, B-Tests und zeitnahes Tuning für jedes Foundation-Modell. Zu den wichtigsten Komponenten von LLMops gehören automatisiertes Hyperparameter-Tuning und die Überwachung der Datenqualität. Diese Funktionen unterstützen komplexe KI-Anwendungen, indem sie die Rechenressourcen optimieren und eine konsistente LLM-Leistung über alle Datensätze hinweg sicherstellen.
Kann ich die LLMOPS-Plattform von TrueFoundry auf meiner Infrastruktur bereitstellen?
Ja. TrueFoundry unterstützt die Bereitstellung in Ihrer VPC-, Private Cloud- oder On-Premise-Umgebung. Dies gewährleistet die volle Kontrolle über sensible Daten, die Einhaltung interner Sicherheitsrichtlinien und eine nahtlose Integration in die bestehende Infrastruktur bei gleichzeitiger Aufrechterhaltung der Skalierbarkeit und Leistung auf Unternehmensebene.
Wie verbessert LLMops die Beobachtbarkeit und das Debugging?
Diese LLMOps-Plattform verbessert die Modellleistung durch Leistungsmetriken und Datenanalysen in Echtzeit. Ingenieure verwenden die Gisting-Bewertung und die zweisprachigen Bewertungsmetriken für das Unterstudium, um ML-Modelle zu debuggen. Indem Sie menschliches Feedback und Modelloperationen verfolgen, erhalten Sie einen umfassenden Einblick in das Verhalten künstlicher Intelligenz in Live-Produktionsumgebungen.
Ist die LLMOPS-Plattform von TrueFoundry sicher und konform?
Unsere LLMOps-Plattform für Unternehmen priorisiert die KI-Sicherheit von Unternehmen durch RBAC- und SOC 2-Compliance. Wir stellen die Datenqualität sicher und schützen sensible Daten mithilfe der Isolierung mehrerer Mandanten. Durch die Integration kontinuierlicher Integration und strenger Datenaufbereitungsprotokolle bietet die Plattform eine sichere Umgebung für den Einsatz umfangreicher Sprachmodelle.
Welche Modelle und Frameworks werden in der LLMOPS-Plattform von TrueFoundry unterstützt?
Die LLMOPS-Plattform von TrueFoundry unterstützt neben traditionellen ML-Modellen auch Sprachmodelle wie Mistral und LLama. Sie ist Framework-unabhängig und lässt sich in Transformatoren und Data-Science-Tools integrieren. Ganz gleich, ob Sie ein Basismodell oder benutzerdefinierte KI-Systeme verwenden, unsere Plattform ermöglicht die nahtlose Bereitstellung und Skalierung von Modellen.
Kann ich die LLMOPS-Plattform von TrueFoundry verwenden, um mehrere Teams und Projekte zu verwalten?
Ja, die Enterprise-LLMops-Plattform von TrueFoundry ist für Mehrmandantenfähigkeit konzipiert und ermöglicht es Datenentwicklungsteams, verschiedene Projekte zu verwalten. Sie können die Rechenressourcen überwachen, die Kosten verfolgen und die Datenerfassung für bestimmte Aufgaben organisieren. Diese Struktur verbessert die Benutzererfahrung für große Unternehmen, die ihre Initiativen im Bereich der generativen KI und der Datenwissenschaft skalieren.
Wie schnell kann ich anfangen, TrueFoundry für LLMOPs zu verwenden?
Mithilfe vorgefertigter Vorlagen für Eingabeaufforderungen und KI-Entwicklungsworkflows können Sie unsere LLMops-Plattform in wenigen Minuten starten. Die Plattform beschleunigt die Datenaufbereitung und die Automatisierung des Kundensupports. Mit automatisierten Modelloperationen kann Ihr Team schnell und mit minimalem Aufwand von der anfänglichen Datenerfassung zu leistungsstarken Produktionsumgebungen übergehen.

GenAI infra- einfach, schneller, günstiger
Mehr als 30 Unternehmen und Fortune-500-Unternehmen vertrauen darauf








