











Feinabstimmung für jedes Modell
Optimieren Sie LLMs und klassische ML-Modelle mithilfe von Hugging Face-Integrationen und produktionsreifen Vorlagen
Feinabstimmung ohne Code oder mit vollem Code
Beginnen Sie schnell mit einer Benutzeroberfläche ohne Code oder bringen Sie Ihre eigenen Trainingsskripte mit, um volle Kontrolle und Flexibilität zu erhalten.
PEFT und vollständige Feinabstimmung
Unterstützt LoRa, QLora und vollständige Feinabstimmung, um Kosten, Speicherverbrauch und Modellleistung in Einklang zu bringen.
Checkpointing und Versionierung
Automatische Checkpoint-Läufe, Wiederaufnahme des Trainings und Versionierung von Modellen und Datensätzen zur Reproduzierbarkeit.
Integrierte Versuchsverfolgung
Verfolgen Sie Hyperparameter, Metriken, Datensätze und Ausgaben in allen Feinabstimmungsläufen.
Adapterverwaltung
Trainieren, wiederverwenden, zusammenführen und wechseln Sie LoRa-Adapter, um die Feinabstimmung zu beschleunigen und die Kosten zu senken.
.webp)
Feinabstimmung für jedes sich umarmende Gesichtsmodell//Klassisches ML-Modell
- Unterstützt die Feinabstimmung von LLMs wie LLama, Mistral, BERT, Falcon und GPT-J
- Mit dem integrierten Hugging Face Model Hub können Sie in wenigen Minuten mit der Feinabstimmung von LLMs beginnen
- Vorkonfigurierte Vorlagen vereinfachen die Feinabstimmung großer Sprachmodelle
- Die skalierbare Infrastruktur bewältigt alles, von kleinen Experimenten bis hin zur serienreifen LLM-Feinabstimmung
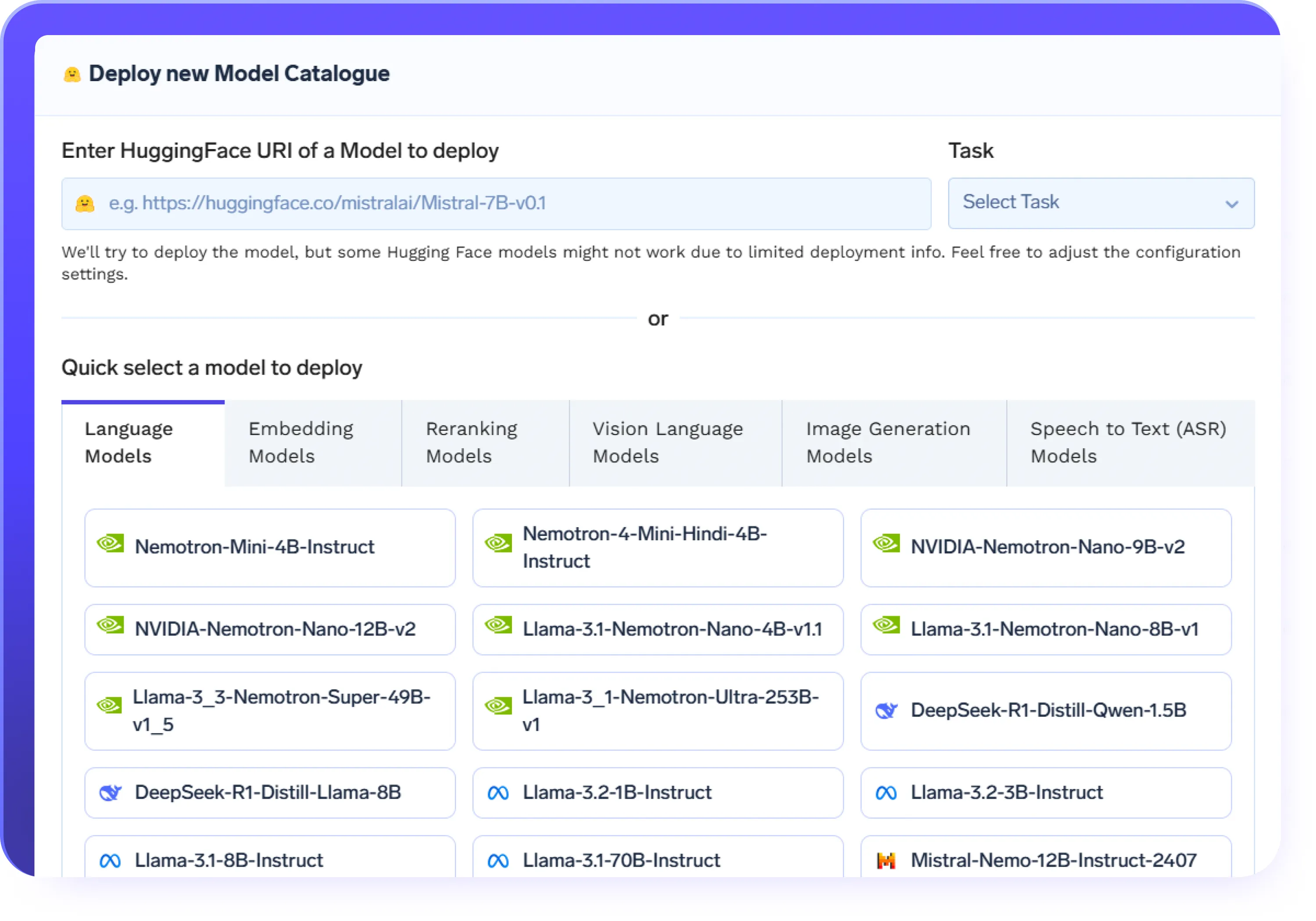
Kein Code oder Vollcode — Sie haben die Wahl
- Optimieren Sie LLMs mithilfe einer Benutzeroberfläche ohne Code für eine schnelle Einrichtung und schnelle Iteration
- Bringen Sie Ihre eigenen Trainingsskripte mit voller Kontrolle im Code-Modus
- Automatisches Management der Infrastruktur- und Ressourcenskalierung
- Mit integrierten Protokollen, Metriken und Versionskontrolle erhalten Sie volle Transparenz bei jedem Feinabstimmungslauf.
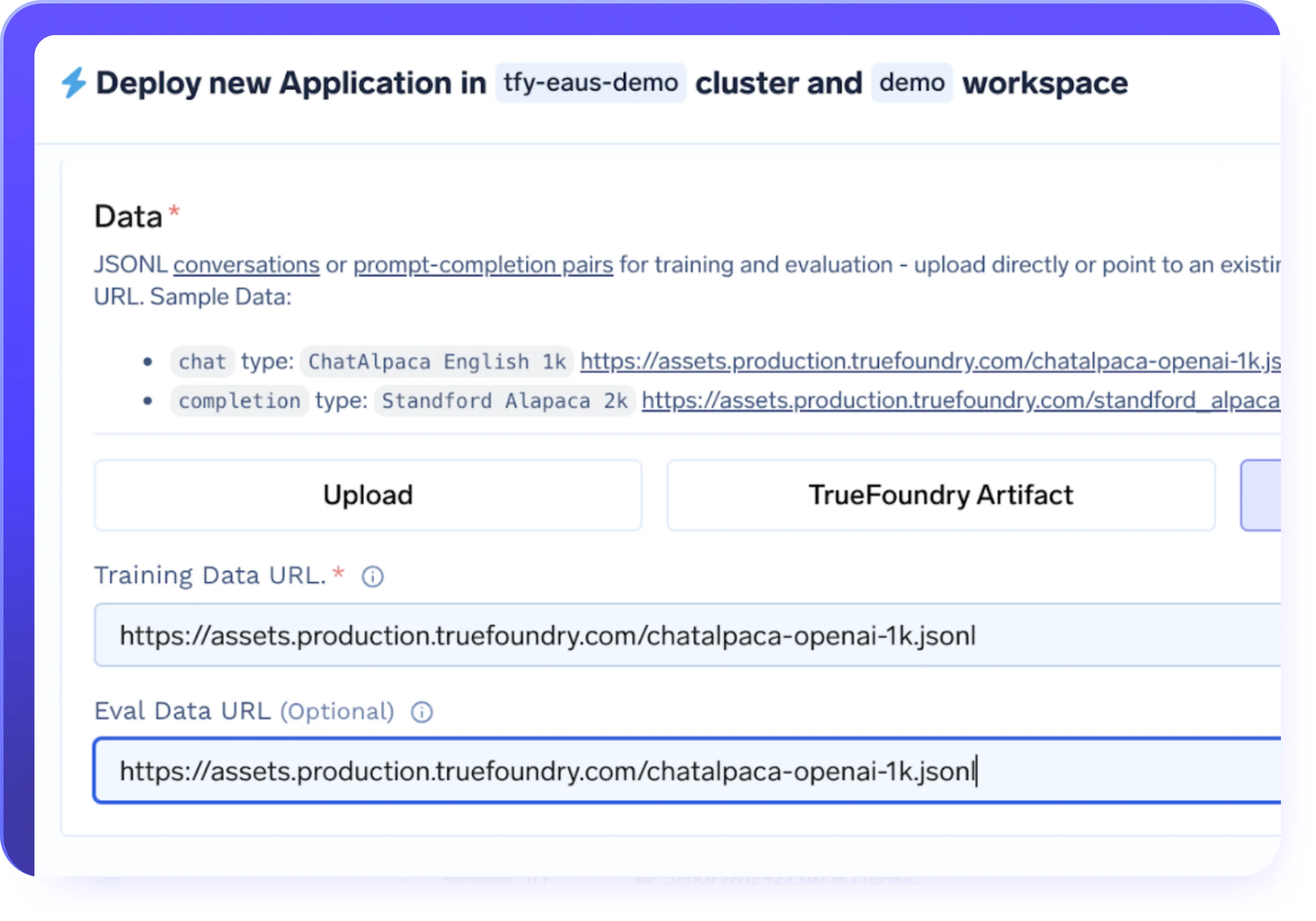
PEFT (LoRa/QLora) und vollständige Feinabstimmungsunterstützung
- Unterstützt parametereffiziente Feinabstimmung (LoRa, QLora) sowie die Feinabstimmung des gesamten Modells
- Wählen Sie LoRa oder QLora für eine schnellere und kostengünstigere Feinabstimmung großer LLMs
- Reduzieren Sie die GPU-Speicherauslastung bei gleichbleibender Modellqualität und Leistung
- Wählen Sie den richtigen Feinabstimmungsansatz auf der Grundlage von Modellgröße, Kosten und Workload-Anforderungen
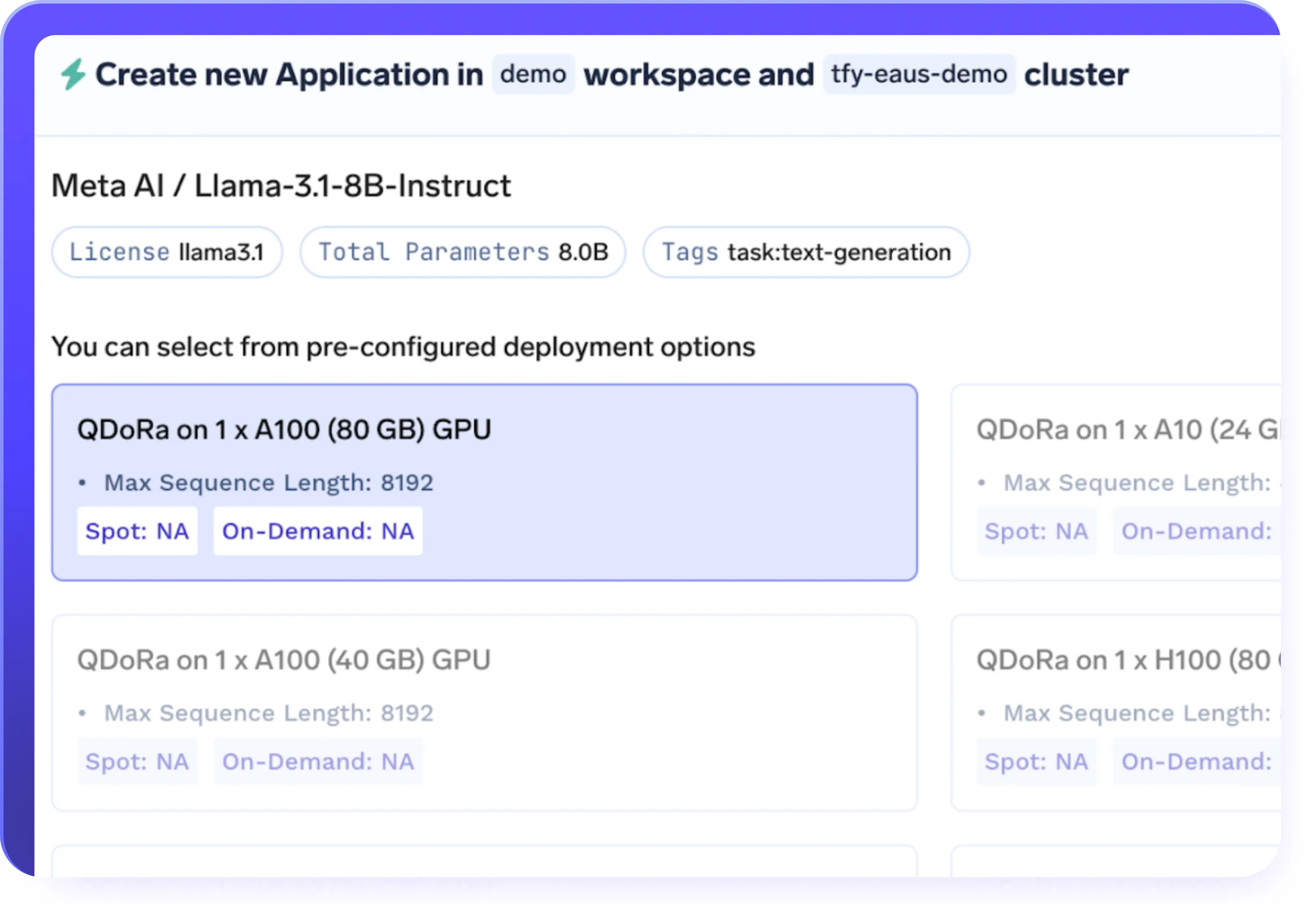
Checkpointing und Versionierung
- Speichere Checkpoints automatisch bei der Feinabstimmung, um den Verlust des Trainingsfortschritts zu verhindern
- Unterbrochene oder angehaltene Feinabstimmungsjobs von jedem Checkpoint aus fortsetzen
- Versionsmodelle, Datensätze und Trainingsläufe für vollständige Reproduzierbarkeit
- Kehren Sie zu früheren Checkpoints zurück und vergleichen Sie die Leistung verschiedener Versionen
Integrierte Versuchsverfolgung
- Automatische Protokollierung aller Trainingsmetadaten: Hyperparameter, Metriken, Datensätze und Ausgaben
- Vergleichen Sie mehrere Läufe, um LLMs effektiver zu optimieren
- Integrieren Sie in Ihren LLMOPS-Stack oder verwenden Sie unsere native visuelle Oberfläche
- Die integrierte Versionskontrolle gewährleistet Reproduzierbarkeit und Überprüfbarkeit
Adaptermanagement für effizientes LLM-Finetuning
- Nutzen Sie LoRa-Adapter zur Feinabstimmung von Modellen, indem Sie nur einen kleinen Satz von Parametern aktualisieren.
- Verwenden Sie vortrainierte Adapter projekt- und domänenübergreifend wieder
- Kombinieren oder wechseln Sie Adapter für verschiedene Aufgaben, um schnelles Experimentieren und modulares Modelldesign zu ermöglichen
- Beschleunigen Sie das Training und senken Sie die Kosten, indem Sie kompakte Adaptermodule anstelle von vollen LLM-Gewichten trainieren
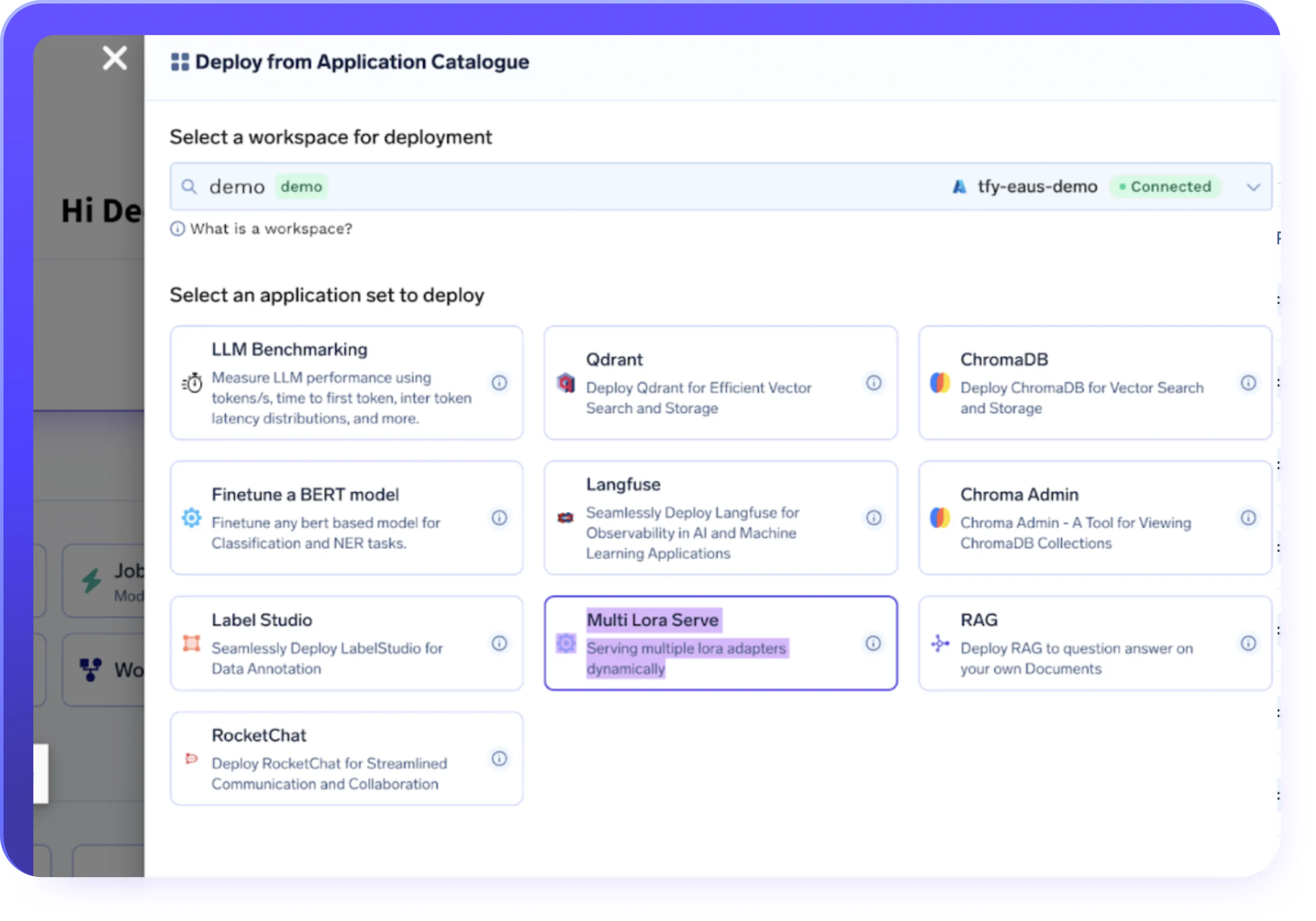
Daten- und Infrastrukturintegrationen
- Datensätze aus S3-, GCS-, Azure Blob- oder Hugging Face-Datensätzen importieren
- Führen Sie Feinabstimmungsjobs auf einer vollständig verwalteten Infrastruktur oder Ihren eigenen Clustern aus
- Stellen Sie Workloads in Cloud-, Hybrid- oder lokalen Umgebungen bereit
- Verwenden Sie standardmäßig GPU-Autoscaling, Time-Slicing und kostenbewusste Bereitstellung
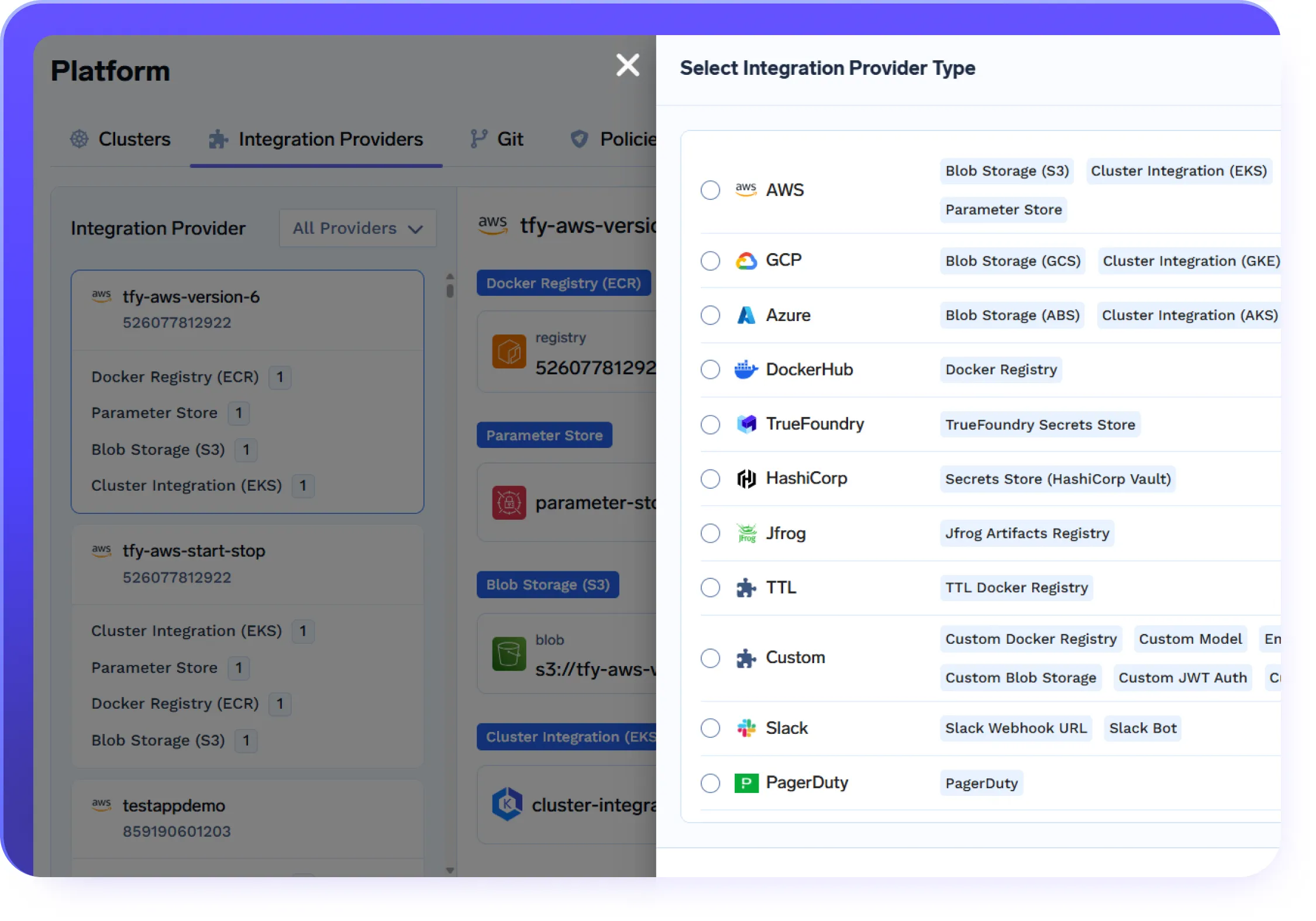
Maßstabsgetreu für künstliche Intelligenz in der realen Welt gemacht
Bereit für Unternehmen
Stellen Sie ein sicheres KI-Gateway bereit, das Ihre Daten und Modelle innerhalb Ihrer Cloud-/On-Premise-Infrastruktur hält.


Einhaltung von Vorschriften und Sicherheit
SOC 2-, HIPAA- und DSGVO-Standards um einen robusten Datenschutz zu gewährleistenVerwaltung und Zugriffskontrolle
SSO + Rollenbasierte Zugriffskontrolle (RBAC) und AuditprotokollierungSupport und Zuverlässigkeit für Unternehmen
Support rund um die Uhr mit SLA-Unterstützung Antwort-SLAs
VPC, vor Ort, Airgapped oder über mehrere Clouds hinweg.
Keine Daten verlassen Ihre Domain. Genießen Sie vollständige Souveränität, Isolierung und Compliance auf Unternehmensebene, wo auch immer TrueFoundry ausgeführt wird

Echte Ergebnisse bei TrueFoundry
Warum sich Unternehmen für TrueFoundry entscheiden






3 x
schnellere Amortisierungszeit mit autonomen LLM-Agenten
80%
höhere GPU-Cluster-Auslastung nach automatisierter Agentenoptimierung

Aaron Erickson
Gründer von Applied AI Lab
TrueFoundry hat unsere GPU-Flotte in eine autonome, sich selbst optimierende Engine verwandelt, die 80% mehr Auslastung ermöglicht und uns Millionen an ungenutzter Rechenleistung erspart.
5x
schnellere Produktionszeit der internen KI/ML-Plattform
50%
geringere Cloud-Ausgaben nach der Migration von Workloads zu TrueFoundry

Pratik Agrawal
Leitender Direktor, Datenwissenschaft und KI-Innovation
TrueFoundry hat uns geholfen, in Rekordzeit vom Experimentieren zur Produktion überzugehen. Was über ein Jahr gedauert hätte, war in Monaten erledigt — bei besserer Akzeptanz durch Entwickler.
80%
Verkürzung der Produktionszeit von Modellen
35%
Cloud-Kosteneinsparungen im Vergleich zum vorherigen SageMaker-Setup
.webp)
Vibhas Geji
Mitarbeiter ML Engineer
Wir haben die DevOps-Belastung reduziert und die produktiven Rollouts teamübergreifend vereinfacht. TrueFoundry beschleunigte die ML-Bereitstellung mit einer Infrastruktur, die von Experimenten bis hin zu robusten Services skaliert werden kann.
50%
schnellere RAG-/Agent-Stack-Bereitstellung
60%
Reduzierung des Wartungsaufwands für RAG-/Agent-Pipelines
.webp)
Indronel G.
Intelligenter Prozessführer
TrueFoundry half uns dabei, einen vollständigen RAG-Stack — einschließlich Pipelines, Vektor-DBs, APIs und UI — doppelt so schnell bereitzustellen und dabei die volle Kontrolle über die selbst gehostete Infrastruktur zu haben.
60%
schnellere KI-Bereitstellungen
~ 40-50%
Effektive Kostenreduzierung in allen Entwicklungsumgebungen
.webp)
Nilav Ghosh
Leitender Direktor, KI
Mit TrueFoundry haben wir die Bereitstellungszeiten um mehr als die Hälfte reduziert und den Infrastrukturaufwand durch eine einheitliche MLOps-Schnittstelle gesenkt — was die Wertschöpfung beschleunigt hat.
<2
Wochen, um alle Produktionsmodelle zu migrieren
75%
Verkürzung des Zeitaufwands für die Koordination von Datenwissenschaften, Beschleunigung von Modellaktualisierungen und Feature-Rollouts
.webp)
Rajat Bansal
CTO
Wir haben viel an Infrastrukturkosten gespart und die DS-Koordinationszeit um 75% reduziert. TrueFoundry hat die Geschwindigkeit unserer Modellbereitstellung in allen Teams erhöht.
Häufig gestellte Fragen
Was ist LLM-Finetuning und warum ist es wichtig?
Wie vereinfacht TrueFoundry das LLM-Finetuning?
- Workflows ohne Code und mit vollem Code: Verwenden Sie eine intuitive Benutzeroberfläche oder benutzerdefinierte Trainingsskripte
- Integrierte Versuchsverfolgung: Automatische Protokollierung von Hyperparametern, Metriken und Modellversionen
- Infrastruktur-Orchestrierung: Führen Sie Jobs auf einer von TrueFoundry verwalteten Infrastruktur oder Ihrer eigenen Cloud/VPC aus
- Unterstützung für PEFT-Methoden: Native Unterstützung für LoRa und QLora-basiertes Finetuning
- Checkpointing und Versionierung: Nahtlose Wiederaufnahme der Schulung und Aufrechterhaltung der Reproduzierbarkeit
- Adaptermanagement: Adapter für mehrere Aufgaben/Modelle wiederverwenden, zusammenführen oder bereitstellen
Welche Arten von Modellen kann ich auf TrueFoundry optimieren?
- Decoder-basierte LLMs (z. B. LLama, GPT-J, Falcon, Mistral)
- Encoder-Modelle (z. B. BERT, RobertA, DistilBert)
- Encoder-Decoder-Modelle (z. B. T5, FLAN-T5)
Kann ich meinen eigenen Datensatz und Trainingscode mitbringen?
- Bringen Sie Ihre eigenen Datensätze aus S3, GCS, Azure, Hugging Face Hub oder lokalen Dateien mit
- Bringen Sie Ihren eigenen Code über benutzerdefinierte Trainingsskripte (PyTorch, Transformers, PEFT usw.) mit.
- Oder verwenden Sie vorgefertigte Vorlagen für gängige Feinabstimmungsabläufe
Wie unterstützt TrueFoundry das LoRa- und QLora-Finetuning?
- Verwenden Sie unsere Benutzeroberfläche, um LoRa-Ebenen und Hyperparameter zu konfigurieren
- Speichern und implementieren Sie LoRa-Adapter unabhängig von den Basismodellen
- Kombinieren Sie Adapter mit Basismodellen für die Bereitstellung oder Offline-Inferenz
- Reduzieren Sie die GPU-Speicherauslastung drastisch — ideal für Unternehmen, die ihre Infrastrukturausgaben optimieren
Kann ich fein abgestimmte Modelle von TrueFoundry in der Produktion einsetzen?
- Stellen Sie Modelle mit vLLM, sGLang oder anderen Inferenzservern bereit
- Stellen Sie Ihr Modell als API mit integrierter Ratenbegrenzung und RBAC zur Verfügung
- Überwachen Sie Latenz, Token-Nutzung und Leistung in Echtzeit
- Verwenden Sie Adapter für eine schnelle Bereitstellung oder führen Sie sie mit dem Basismodell für eigenständige Inferenz zusammen

GenAI infra- einfach, schneller, günstiger
Mehr als 30 Unternehmen und Fortune-500-Unternehmen vertrauen darauf








