




July 4, 2026
|
5 min read


احصل على وصول فوري إلى بيئة TrueFoundry مباشرة. انشر النماذج، ووجّه حركة مرور LLM، واستكشف المنصة بالكامل — بيئة الاختبار الخاصة بك جاهزة في ثوانٍ، ولا يلزم وجود بطاقة ائتمان.









Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
AI in 2026 means running multiple models across multiple providers, each with different pricing, latency profiles, rate limits, and failure modes. The teams moving fastest aren't connecting to models directly anymore, they're running everything through an LLM gateway. One layer that unifies providers, enforces compliance, controls costs, and gives you the observability you need to actually understand what your AI stack is doing.
The gateway you choose will determine how fast you ship, how reliable your systems are, and how much you end up paying. This guide cuts through the noise.
Building with AI is no longer about picking the best single model. Different providers excel in different areas, pricing shifts constantly, and no one LLM dominates every use case. What works for chat today may fall short for code generation or reasoning tomorrow.
An LLM gateway acts as a smart middle layer between your applications and the rapidly changing world of model providers. Instead of wiring your system directly to each API, dealing with custom integrations and vendor lock-in, you connect to one gateway and gain:
As AI adoption accelerates, the real winners will not only be those who use LLMs but those who manage them wisely. The gateway is where that wisdom lives.
Not all gateways are equal. The right one depends on your team's scale, workflow, and compliance requirements. Here's the evaluation framework that matters:
Performance: A good gateway should route requests intelligently, balancing speed, reliability, and cost. Look for sub-10ms p95 overhead on time-to-first-token. Higher latency compounds across multi-step agentic workflows.
Flexibility: Your gateway should support multiple providers, open APIs, and easy switching. Lock-in defeats the purpose.
Observability: Clear cost and usage insights, dashboards, and anomaly detection. Without them, you're flying blind.
Security: Whether it's SOC2, GDPR, or enterprise-grade encryption, the gateway should enforce consistent policies. Especially important for LLM deployments in regulated industries.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

The market for LLM gateways is heating up fast. New players are entering, established ones are evolving, and each promises to be the smartest layer between you and the world of models. But not all of them deliver the same value. Some focus on speed, others on cost control, and a few lean heavily into enterprise compliance.
The right gateway for you depends on your use case, whether you are scaling a startup product, running enterprise workloads, or experimenting with cutting-edge models. Below are six of the most notable gateways in 2026, each bringing a different flavor of performance, flexibility, and control.
TrueFoundry stands out as the leading LLM gateway for enterprises that need production-ready AI without the usual complexity. It combines orchestration, governance, and scalability into a single platform - making it easier to deploy, manage, and optimize LLM workflows at scale.
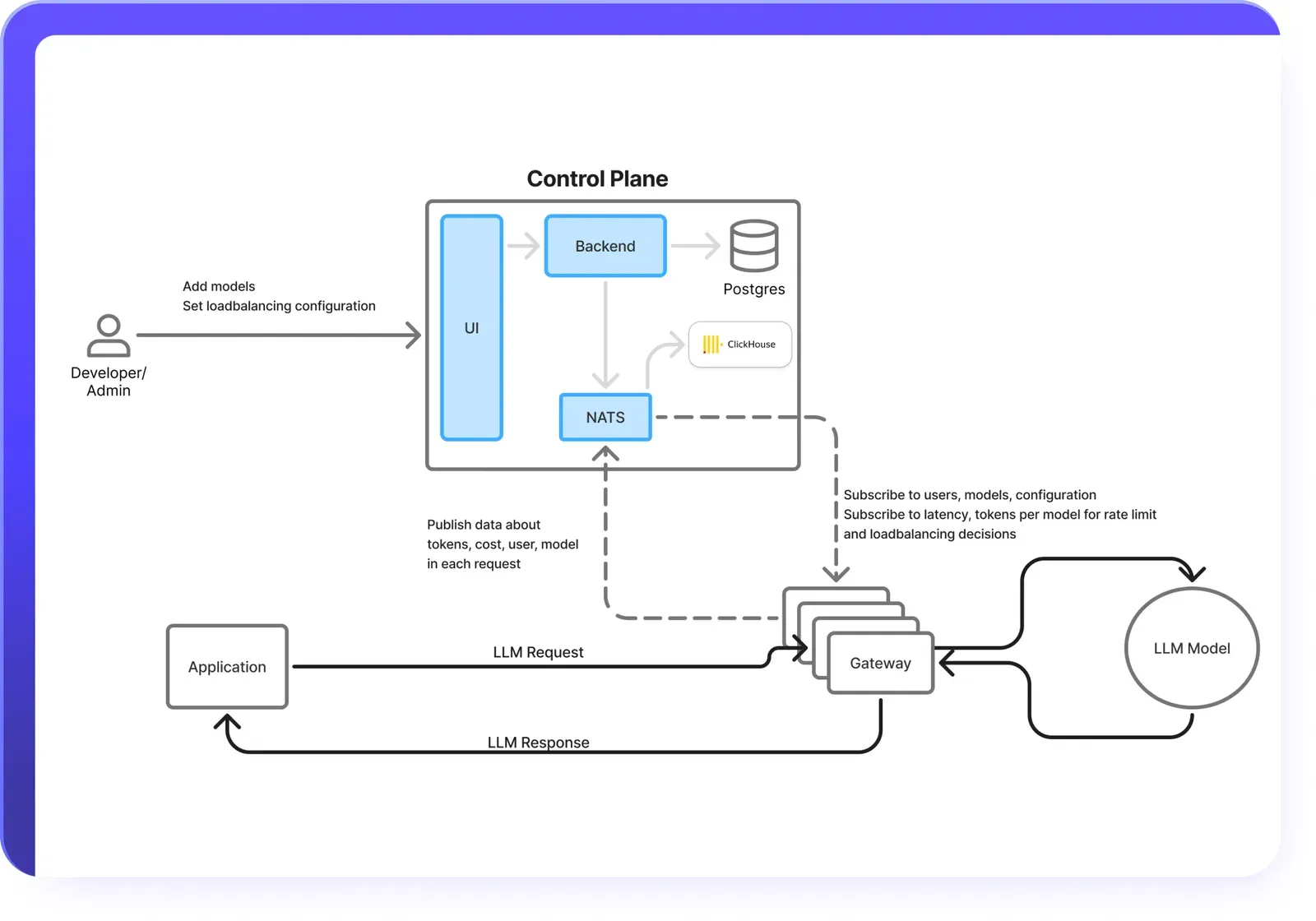
The LLM Gateway coordinates multi-step agent workflows, handling memory, tool integration, and reasoning across tasks. This ensures agents can plan, act, and adapt seamlessly while giving teams full visibility and control. The architecture separates the control plane from the data plane - processing authentication, authorization, and rate limiting in-memory for consistent sub-millisecond overhead regardless of governance complexity.
Token-level usage attribution lets you understand costs by user, team, geography, or custom dimension. Real-time budget enforcement prevents surprises, and detailed cost observability helps optimize spending patterns. Teams typically report 30–70% cost reduction compared to direct provider usage.
With its MCP and Agents Registry, TrueFoundry offers a centralized library of APIs and tools with schema validation and access controls. Prompt Lifecycle Management adds versioning, testing, and monitoring - enabling consistent, auditable agent behavior. The MCP Gateway provides centralized MCP server management with OAuth 2.0 secured access to tools like Slack, GitHub, and Confluence.
Supports any LLM or embedding model, with optimized backends like vLLM, TGI, and Triton. Integrates with frameworks such as LangGraph, CrewAI, and AutoGen. Also supports on-premise LLM gateway deployments and air-gapped environments for regulated industries.
SOC 2 Type 2 and HIPAA compliance, running in secure VPC, on-prem, hybrid, or air-gapped environments. GPU orchestration, fractional GPU support, and autoscaling keep costs efficient - some enterprises report 80% higher GPU utilization.
Organizations managing multiple LLM providers who need granular control over access, costs, and compliance. Ideal for teams who want the complete AI infrastructure stack - not just a proxy.
Considerations: The comprehensive feature set may be more than needed for small teams or simple individual use cases.
Also explore: TrueFoundry vs Portkey vs Helicone - enterprise comparison
Helicone is an open-source LLM gateway designed for developers who want a lightweight, high-performance solution. Built in Rust and optimized for edge deployments, it offers a unified API that simplifies integration and improves observability.
Unified API for Multiple Models: A single API works across dozens of LLMs including GPT, Claude, and Gemini, eliminating the need for multiple SDKs or keys.
Intelligent Routing and Failover: Automatically switches models, optimizes for cost, and balances load across providers for reliable performance.
Built-in Observability: Real-time monitoring of requests, responses, token usage, latency, and costs through a centralized dashboard.
Edge-Optimized Performance: ~8ms P50 processing time with very low overhead even under heavy load.
Limited enterprise features - lacks advanced RBAC, audit logging, and strict policy enforcement for regulated environments. Basic integration support without extensive model ecosystems for complex enterprise setups.
For teams that need advanced access control or broader integrations, see: Helicone alternatives for enterprise teams | Helicone vs Portkey comparison
OpenRouter is a developer-focused gateway providing access to multiple LLMs through a single API. It simplifies integration and management, making it ideal for teams seeking maximum model flexibility.
Unified API Access: Connects to models from OpenAI, Anthropic, Google, Mistral, and dozens more — reducing the complexity of managing multiple SDKs. One of the widest provider selections available.
Automatic Routing and Fallback: Routes requests to the best model based on performance, cost, and availability, with automatic fallback on failure.
Transparent Pricing: Clear per-token pricing and consolidated billing make cost management straightforward. Bring Your Own Key (BYOK) for more control over authentication.
Rate limits on free-tier models restrict testing at scale. Latency can increase under heavy traffic depending on model and load. Limited enterprise governance features — no advanced audit logging, RBAC, or compliance certifications.
Also explore: OpenRouter vs AI Gateway - a direct comparison | LiteLLM vs OpenRouter | Requesty vs OpenRouter
Portkey is an open-source AI gateway designed to streamline access to over 1,600 AI models, including large language models (LLMs), vision, audio, and image models. It offers a unified API that simplifies integration and management, making it an ideal choice for developers seeking flexibility and efficiency.
Portkey positions itself as an LLMOps platform rather than just a gateway, offering end-to-end AI application lifecycle management alongside traditional proxy functionality. The LLMOps layer is, however, limited, missing key features like model deployment.
Unified API Access - Access 1,600+ AI models including LLMs, vision, audio, and image models through a single endpoint.
Smart Routing and Failover - Intelligently routes requests based on cost, performance, and availability with automatic fallback. Includes semantic caching to reduce latency and costs.
Advanced Observability - Real-time monitoring of request/response payloads, token usage, latency, and costs in a centralized dashboard.
Guardrails Integration - Integrates with Prisma AIRS for real-time AI security. 50+ pre-built guardrails for content filtering and PII detection.
Enterprise Reliability - SOC2, ISO27001, HIPAA, and GDPR compliance with SaaS, hybrid, and air-gapped deployment options. 99.99% uptime SLA.
Enterprise pricing is complex — key features like budget limits are restricted to Enterprise customers only. Some users report limited data export functionality requiring manual support team intervention. Model deployment is not natively supported in the LLMOps layer. Some users find the platform overwhelming due to the feature density.
Also explore: Portkey alternatives for 2026 | Portkey pricing guide | Portkey vs LiteLLM | Langfuse vs Portkey
LiteLLM is the most widely-used open-source gateway for standardizing LLM calls, providing a Python-based proxy server that unifies access to 100+ LLM APIs in OpenAI format.
Universal API Compatibility - Connects to major providers including OpenAI, Azure, AWS Bedrock, HuggingFace, and Google Vertex AI with consistent formatting. Strong for teams wanting to avoid vendor-specific SDKs.
Budget and Rate Limit Management - Set budgets and rate limits per user, team, or API key to control costs and ensure fair usage.
Logging and Observability - Integrates with Prometheus, Datadog, and S3/GCS for logging and monitoring.
Open-Source Transparency - YAML-based configuration management enables infrastructure-as-code approaches. Full control over your AI infrastructure.
No formal commercial backing means no enterprise support plan, no SLAs for uptime, and no dedicated escalation path. Users report frequent regressions between versions, edge-case bugs, and instability at scale. Latency overhead becomes a bottleneck for real-time applications. Lacks advanced observability, AI guardrails, and enterprise features beyond basic routing. Advanced features like JWT auth and audit logs require the paid enterprise version.
Also explore: LiteLLM alternatives for enterprise teams | LiteLLM pricing guide | Detailed LiteLLM review: features, pricing, pros & cons | LiteLLM enterprise pricing TCO vs TrueFoundry | Bifrost vs LiteLLM
Unify AI is an open-source gateway focused on dynamic, intent-aware model routing, routing requests to the optimal model based on real-time performance benchmarks, cost, and availability.
Dynamic Model Routing: Intelligently routes to the best model across providers based on cost, performance, and availability. Particularly strong for teams running experiments across many models simultaneously.
Unified API Access: Single endpoint connecting to models from OpenAI, Anthropic, and Google Vertex AI.
Real-Time Observability: Monitoring of request/response payloads, token usage, latency, and costs.
Semantic Caching: Reduces latency and costs through semantic caching matching intent rather than exact strings.
Rate limits on free-tier models restrict development and testing at scale. The extensive capabilities may introduce unnecessary complexity for smaller projects. Still maturing in enterprise features compared to established platforms.
The right LLM gateway depends on your team's scale, workflow, and compliance requirements:
If you're an enterprise with complex workflows → TrueFoundry or Portkey. Both provide robust orchestration, fine-grained access control, and compliance features. TrueFoundry leads on latency performance, deployment flexibility, and AI governance. Portkey leads on LLMOps depth.
If you're a startup or small dev team → Helicone or LiteLLM. Low overhead, fast integration, strong observability without requiring extensive infrastructure or compliance management.
If maximum model flexibility is the priority → OpenRouter or Unify AI. Single API, intelligent routing, widest provider selection for teams experimenting across multiple LLMs.
If you need on-premise or air-gapped deployment → TrueFoundry. The only option here that combines enterprise compliance with deployment flexibility inside your own VPC. See: LLM gateway on-premise infrastructure guide.
If you're evaluating cost → Start with LLM gateway cost considerations before committing to any platform.
The ideal choice is the one that supports your growth, keeps infrastructure manageable, and lets your team focus on building, not firefighting.
يمكن أن يحدد اختيار بوابة LLM المناسبة نجاح أو فشل استراتيجيتك للذكاء الاصطناعي في عام 2026. سواء كنت تعطي الأولوية للسرعة، أو كفاءة التكلفة، أو الامتثال، أو الوصول إلى نماذج متعددة، فإن البوابات التي تناولناها تقدم حلولاً لكل حاجة. تتفوق TrueFoundry وPortkey في التنسيق والأمان على مستوى المؤسسات، بينما توفر Helicone وLiteLLM وOpenRouter وUnify AI مرونة صديقة للمطورين وتكاملًا خفيف الوزن. المفتاح هو مواءمة اختيارك مع سير عملك، وحجم عملياتك، وأهدافك. فالبوابة المختارة بعناية لا تبسط إدارة النماذج فحسب، بل تمكّن فريقك أيضًا من الابتكار بشكل أسرع، وتحسين الموارد، وتقديم تطبيقات الذكاء الاصطناعي بثقة.
تُعد TrueFoundry أفضل بوابة LLM لفرق الذكاء الاصطناعي في المؤسسات التي تحتاج إلى بنية تحتية آمنة وقابلة للتطوير وجاهزة للإنتاج لـ LLM. على عكس الوكلاء الأساسيين، تم تصميم بوابة الذكاء الاصطناعي من TrueFoundry للحوكمة والموثوقية والنشر على نطاق واسع، مما يجعلها مثالية للمؤسسات التي تدير تطبيقات ذكاء اصطناعي بالغة الأهمية.
عند اختيار بوابة LLM، ابحث عن دعم مزودين متعددين، والتوجيه الذكي والعودة الاحتياطية، وتحديد المعدل، والتخزين المؤقت، وتحليلات الاستخدام التفصيلية، وتتبع التكلفة، والتحكم في الوصول المستند إلى الدور (RBAC)، وإدارة المفاتيح الآمنة، وقابلية مراقبة قوية. يجب على فرق المؤسسات أيضًا إعطاء الأولوية لسجلات التدقيق، والتحكم في الوصول على مستوى البيئة، والتوافر العالي.
تعمل بوابات LLM على تحسين الأداء من خلال التوجيه الذكي، وإعادة المحاولة التلقائية، والتخزين المؤقت للاستجابة. كما أنها تقلل التكلفة من خلال تمكين اختيار النموذج بناءً على مفاضلات السعر والأداء، وفرض حدود المعدل، وتوفير رؤية الاستخدام في الوقت الفعلي لمنع الإفراط في الإنفاق.
تبرز TrueFoundry كأفضل بوابة LLM من خلال توفير لوحة تحكم موحدة لتنسيق النماذج والأمان. فهي تدمج قابلية المراقبة في الوقت الفعلي مع التجاوز التلقائي للفشل، مما يضمن التوافر العالي عبر المزودين. كما أن دعمها الأصلي لوحدات معالجة الرسوميات (GPU) والتحكم في الوصول المستند إلى الدور (RBAC) على مستوى المؤسسات يسمح للمؤسسات بتوسيع نطاق الذكاء الاصطناعي في الإنتاج مع الحفاظ على الإقامة الصارمة للبيانات والامتثال.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








أحدث الأخبار والمقالات والموارد تصلك مباشرة إلى بريدك الوارد
© 2026 جميع الحقوق محفوظة.







.png)
.webp)










.webp)
