














June 27, 2026
|
5 min read

Published: April 9, 2026
Blazingly fast way to build, track and deploy your models!
Choosing the right AI gateway for production AI applications requires understanding not just features, but how pricing scales with usage. Portkey AI has emerged as a popular choice for startups and platform teams, but its unique pricing model based on "recorded logs" can be confusing.
This comprehensive guide breaks down Portkey pricing for 2026, explains what you're actually paying for, and helps you determine if Portkey is the right fit or if alternatives like TrueFoundry, LiteLLM, or Kong might better serve your needs.

Portkey AI gateway is a production-ready AI infrastructure platform that provides a unified interface to access over 250 different models from providers like OpenAI, Anthropic, Google, AWS Bedrock, Azure, and more. It serves as a control panel for managing, routing, and monitoring LLM requests in production environments.
Portkey gateway positions itself as the "Control Panel for Production AI" with features designed for teams moving from a proof of concept phase to production. The platform offers a unified API interface with a single endpoint to access 250+ models across multiple providers with standardized request and response formats.
Its observability suite provides detailed logs, tracing, analytics, and cost tracking for every LLM request. Reliability features include automatic fallbacks, load balancing, conditional routing, retries logic, and circuit breakers to prevent model downtime. Production performance optimization comes through semantic caching and simple caching to reduce latency and costs.
The platform holds SOC2 Type 2, ISO 27001, GDPR, and HIPAA certifications at the Enterprise tier and claims 2-minute integration time with immediate monitoring of all LLM calls. Portkey AI targets startups scaling to production and mid-market companies that need managed AI infrastructure without the complexity of self-hosting open-source solutions.
Unlike traditional API gateways that charge based on requests or compute resources, Portkey pricing uses a usage-based pricing model centered on "recorded logs," which is a metric unique to observability-focused AI gateway solutions.
Portkey pricing reflects its positioning as an observability-first platform. While the gateway itself routes requests to LLM providers that you pay separately, Portkey charges primarily for three components:
This model works well for teams that want comprehensive monitoring but can become expensive at scale, especially if you need long-term log retention or generate high request volumes.
When you pay the Portkey cost, you're paying for managed edge deployment infrastructure with 99.99% uptime SLA and 20-40ms latency overhead, the observability platform for storage, indexing, and querying of request logs, traces, and analytics, feature access to advanced routing strategies, semantic caching, prompt management, and guardrails, support ranging from community to production or enterprise-level depending on tier, and compliance infrastructure including security certifications like SOC2 and HIPAA.
Important Note: Portkey pricing is separate from your LLM provider costs, meaning you still pay OpenAI, Anthropic, and other providers directly for model usage while Portkey serves as the middleware layer on top.
The most distinctive aspect of Portkey pricing is billing based on recorded logs rather than raw API requests. Understanding this metric is crucial to estimating your costs. A recorded log represents a single LLM API request that Portkey captures, stores, and makes available in your observability dashboard.
Each log includes request metadata (timestamp, user, application), prompt and response content (unless explicitly excluded for privacy), provider and model information, latency metrics and performance data, cost calculations, custom metadata and tags, and guardrail violations or errors.
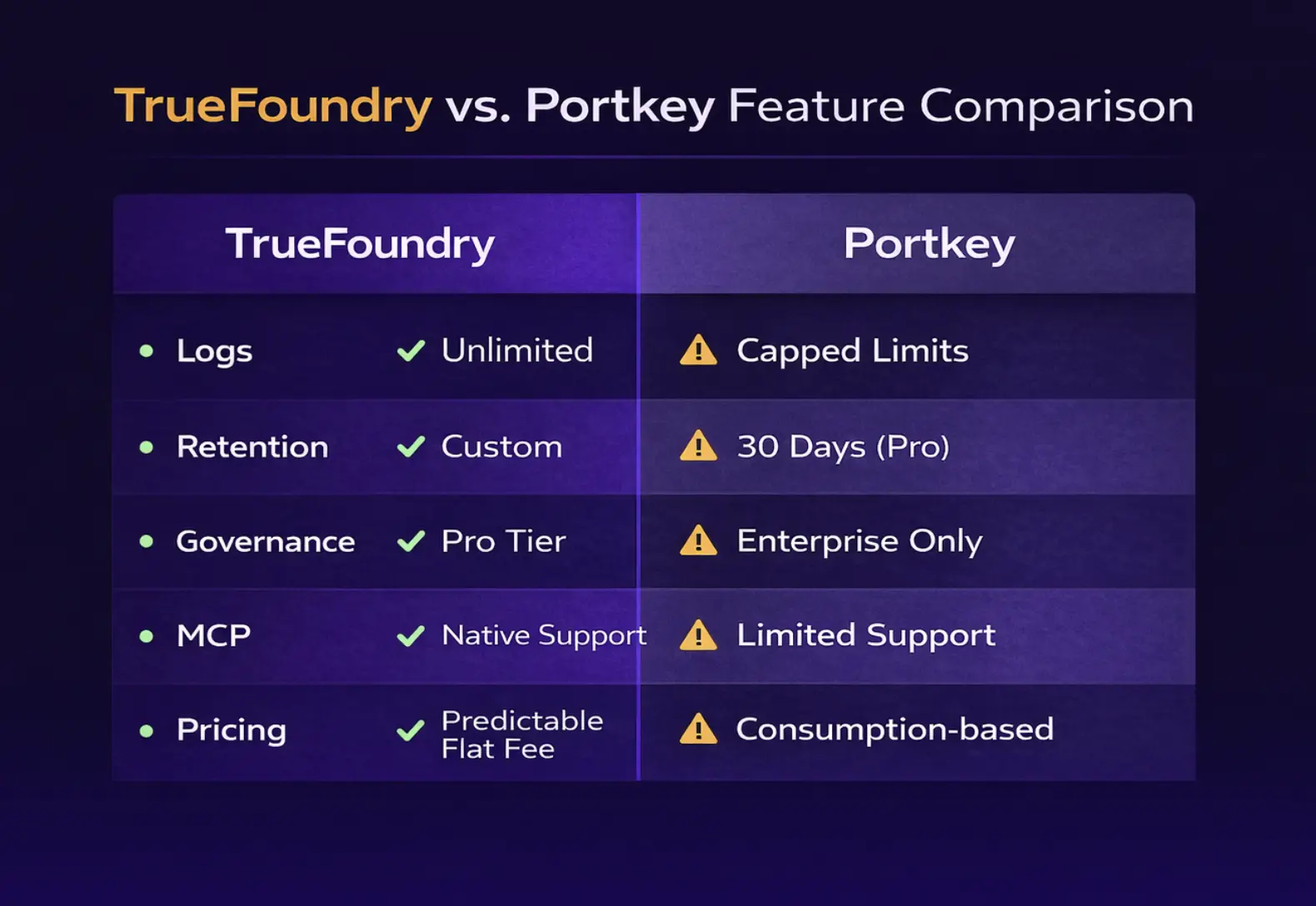
The key distinction between recorded logs and total requests is that Portkey gateway continues routing requests even after you exceed your log limit. Your gateway doesn't stop working; you simply stop recording new logs for observability. This is both a benefit and a limitation. The benefit is that your production application code never goes down due to log limits. The limitation is that you lose visibility into requests beyond your log limit, which defeats the purpose of an observability platform.
For example, if your startup generates 500,000 LLM requests per month, the Dev plan only captures the first 10K requests for $0, but 98% of traffic is invisible. The Pro plan includes base 100K logs in the base price, requires 400K additional logs, and costs the base plan plus (4 × $9) = base plus $36 per month for log coverage.
At 500K requests per month, you're likely generating significant revenue and need full visibility, so the Pro tier becomes essential, but Portkey pricing scales linearly with traffic.
Understanding how Portkey pricing behavior changes at log limits is critical for production planning.
For small teams on the Dev tier, 10K monthly logs equals roughly 330 requests per day. If you exceed this regularly, you are blind to most production traffic, making an upgrade to Pro necessary for any real production workload.
For growing startups on the Pro tier, you must monitor usage closely to avoid hitting the 100K base limit. Each 100K additional logs costs $9, which is manageable but adds up quickly. At 1M+ requests per month, consider the Enterprise tier for better unit economics.
For enterprises, custom log limits are negotiated based on volume, typically 10M+ logs with volume discounts and configurable retention periods crucial for compliance.

Let’s have a look at the different Portkey pricing plans:
The Dev plan includes unified API access to 250+ models, basic observability (logs, traces, feedback, metadata), automatic fallbacks, load balancing, simple caching (1-day TTL), up to 3 prompt templates, and community support. However, with only 10K requests/month visible (roughly 330/day), no semantic caching, no alerts or advanced dashboards, and no user access control, it's insufficient for production applications.
The Pro plan adds detailed observability (alerts, FinOps dashboard, analytics), semantic caching with unlimited TTL, unlimited prompt templates with version control, user access control, and production support with standard SLA. Key limitations include 3M monthly log cap, 30-day retention only, no VPC deployment, and no SSO or advanced RBAC.
Cost Examples: 500K requests = Base + $36/mo | 1M requests = Base + $81/mo | 2M requests = Base + $171/mo
The Enterprise plan includes everything in Pro plus advanced governance (RBAC, SSO, granular budgets), enterprise infrastructure (private cloud, VPC hosting, data export, data isolation), compliance certifications (SOC2, ISO 27001, GDPR, HIPAA, custom BAAs), priority 24/7 support with guaranteed response times, and three deployment options (managed SaaS, hybrid, or fully air-gapped).
Typical Portkey pricing ranges from $2,000-$10,000+/month depending on volume, retention, deployment model, and support level.
Understanding how Portkey pricing stacks up against alternatives helps determine the best fit for your use case.
If you're evaluating major AI gateway providers, here's how they stack up:
Also Read: Portkey vs LiteLLM

Portkey pricing makes it the right choice for specific organizational profiles and GenAI use cases.
Early-stage startups with 3 to 5 person teams building AI-powered products benefit because the free 10K logs per month gets them through initial prototyping, 2-minute integration means less engineering time on infrastructure, Pro tier scales from beta to initial production, and managed service eliminates infrastructure headaches. Cost profiles of $0 to $500 per month in the first year are manageable for VC-backed startups.
Teams without DevOps expertise benefit when engineering teams are strong in the development process but lack Kubernetes, Docker, or cloud infrastructure expertise, making self-hosting LiteLLM require hiring or training.
Portkey AI gateway offers fully managed infrastructure with 99.99% uptime SLA, no need to manage servers, scaling, monitoring, or updates. Security and compliance are handled by Portkey, and a support team is available when issues arise.
Self-hosting LiteLLM requires DevOps expertise worth $120K to $180K per year, making Portkey cost of $3K to $6K per year Pro tier dramatically cheaper if you lack this capability.
Teams with moderate request volumes between 100K and 2M per month, past the prototype stage but not yet at massive scale, find Portkey pricing competitive. At $9 per 100K logs, this is reasonable for observability value and easier to budget than unpredictable infrastructure costs.
At 500K requests per month, the additional $36 in log costs is manageable, and at 1M requests per month, the additional $81 in log costs is still reasonable. Above 3M requests per month, competitors with unlimited logging like TrueFoundry or self-hosted options like LiteLLM become more economical.
As AI applications scale from thousands to millions of monthly requests, Portkey pricing models and architectural choices create friction for high-growth teams.
Log limits create operational blind spots because once you exceed your log limit, new requests aren't recorded and your observability platform stops observing. If your app generates 5M requests per month and Portkey AI Pro maxes out at 3M logs, 40% of your traffic is invisible in dashboards.
You can't debug issues affecting 2M requests per month, and cost analytics become unreliable because 40% of spend data is missing. The Enterprise workaround requires paying $5K to $10K per month for Enterprise tier with 10M+ log limits, where competitors offer unlimited logging at lower price points.
30-day retention is insufficient for compliance in many regulated industries. Healthcare under HIPAA requires 6+ years for medical records, financial services under SOX require 7+ years for transaction logs, and government contracts require 3+ years minimum.
Portkey gateway features on the Pro tier offer 30 days only, while the Enterprise tier offers custom retention available at premium pricing. TrueFoundry offers custom retention available at Pro tier for $499, and LiteLLM offers unlimited retention since you control storage.
Missing Portkey MCP gateway for agentic AI is a significant gap. By 2026, agentic AI workflows are becoming mainstream, and the Model Context Protocol (MCP) enables AI agents to use tools, access databases, and interact with external systems safely.
Portkey has limited MCP support and hasn't prioritized MCP gateway capabilities yet, meaning you can't build sophisticated agentic workflows like AI agents querying internal databases with user-level permissions, tool use with OAuth token injection, or virtual MCP servers abstracting complex tool chains.
TrueFoundry offers full MCP gateway with virtual server support, OAuth 2.0 identity injection where agents act on behalf of specific users, 99% inference token savings through active tool use versus context stuffing, and approximately 10ms latency for tool calls.
Limited governance until Enterprise tier creates challenges because modern AI operations require Role-Based Access Control (RBAC) on models, budget controls per team, user, or application, rate limiting by user or department, and custom guardrails and content filtering.
Portkey enterprise AI gateway gates these features at the Enterprise tier, meaning Pro tier customers lack basic governance, requiring approximately $2K to $5K per month spend for governance capabilities. TrueFoundry offers RBAC available at Pro tier for $499 per month, budget controls and rate limiting at Pro tier, and governance accessible to smaller teams earlier in their growth journey.
For teams hitting Portkey's limitations, especially log limits, MCP support, and governance features, TrueFoundry offers a compelling alternative with fundamentally different architectural and Portkey pricing choices.
TrueFoundry provides governance features at Pro tier for $499 per month that include Role-Based Access Control (RBAC) on models, budget controls per user, team, or application, rate limiting policies flexible per user, model, or app, virtual models for abstraction, custom metadata logging, and fine-grained access control.
A 20-person startup can implement production-grade governance for $499 per month instead of $5,000+ per month with the Portkey enterprise AI gateway, democratizing AI governance for smaller teams.
TrueFoundry's full MCP gateway support represents its most significant differentiation for 2026 agentic AI use cases.
What TrueFoundry's MCP Gateway Enables:
TrueFoundry offers VPC and on-premises deployment very seamlessly. Regulated industries need data in their VPC from day one and TrueFoundry includes VPC, airgapped option for enterprises with strict SLAs.
Portkey is an excellent choice for teams looking to start fast, but observability-based pricing can quickly become a bottleneck as your request volume grows. When you are billed per log, you’re often forced to make a difficult choice: pay a premium for full visibility or risk flying blind during critical production incidents to stay under budget.
TrueFoundry offers a different path. By decoupling the gateway from the underlying compute and offering unlimited observability for a flat monthly fee, we ensure that your architecture encourages visibility rather than penalizing it. You get enterprise-grade RBAC, budget controls, and full data ownership without the "success tax" of per-log billing.
Ready to scale your AI applications without the hidden costs? Book a demo with TrueFoundry today to see how we deliver unlimited observability and governance for a predictable flat fee.
No, Portkey only charges for recorded logs based on your tier and feature access for Pro versus Enterprise tiers. You pay your LLM providers like OpenAI and Anthropic separately for actual model usage, while Portkey is the middleware layer for routing and observability.
Your requests continue to be routed normally to LLM providers, and the gateway doesn't stop working. What stops is recording new logs in the observability dashboard, meaning you lose visibility into request and response content, cost tracking for those requests, performance metrics and latency, and error monitoring and debugging.
Yes, but only with the Enterprise plan via an air-gapped deployment option. Alternatives include LiteLLM, which is fully open-source and can be self-hosted on any infrastructure for free, and TrueFoundry, which offers VPC and on-premises deployment available at Pro tier for $499 per month.
As of 2026, Portkey has limited MCP support and hasn't prioritized Portkey MCP gateway features yet. For full MCP support, TrueFoundry offers a full-featured MCP gateway with virtual servers, OAuth injection, and hybrid deployment, and Kong offers an MCP proxy plugin available at the Enterprise tier.
Pro tier logs are retained for 30 days then automatically deleted, while the Enterprise tier offers custom retention periods of 90+ days, 1 year, or more that can be negotiated. Many industries require longer retention including healthcare at 6+ years, financial services under SOX require 7+ years for transaction logs, and government contracts require 3+ years minimum.
Yes, TrueFoundry integrates with popular tools like GitHub for version control, managing PRs (Pull Requests), and maintaining documentation for your models. You can also configure timeouts for long-running audio or chat generation tasks, and use Python SDKs for custom integrations.
TrueFoundry offers the best caching solution with semantic capabilities to reduce costs. It also supports robust testing frameworks to ensure model quality before deployment, providing detailed observability features and detailed logs that give clear insights into your AI performance. This provides immediate value and makes a huge difference for a senior ML engineer managing complex systems. Any user would find the level of visibility invaluable for preventing unexpected outputs in production.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.




.webp)

.webp)
.webp)
.png)






.webp)
.webp)
