














June 27, 2026
|
5 min read

Published: February 13, 2026
Blazingly fast way to build, track and deploy your models!
Large language models are rapidly becoming a core layer of enterprise software. What began as cloud-based experimentation with hosted APIs is now evolving into production-grade systems embedded across internal tools, customer-facing applications, and automated workflows.
As this shift happens, many organizations are encountering a hard reality: not all AI workloads can run in the public cloud.
Sensitive enterprise data, proprietary intellectual property, regulated workloads, latency-critical applications, and compliance obligations are driving teams to deploy LLMs within on-premise or private infrastructure. However, simply self-hosting models does not solve the larger operational problem. As more teams, applications, and models come online, organizations need a consistent way to control access, enforce policies, monitor usage, and manage costs across their LLM ecosystem.
This is where an LLM Gateway on-premise infrastructure becomes foundational.
Rather than allowing every application to integrate directly with individual models, an LLM Gateway introduces a centralized control layer that governs how models are accessed and used. In on-prem environments, this gateway becomes the backbone that enables enterprises to scale LLM adoption securely, compliantly, and efficiently without sacrificing visibility or control.
An LLM Gateway is a centralized access and governance layer that sits between applications and language models. Instead of applications calling models directly, all LLM requests flow through the gateway, which enforces security, routing, observability, and policy controls in one place.
In an on-premise setup, both the gateway and the models run entirely within the organization’s infrastructure - such as a data center, private cloud (VPC), or air-gapped environment. This ensures that prompts, responses, embeddings, and metadata never leave controlled boundaries.
At a high level, an on-prem LLM Gateway provides:
By abstracting model access behind a standardized API, the gateway decouples application development from model infrastructure. Teams can switch models, introduce fine-tuned versions, or enforce new governance rules without modifying application code.
In on-prem environments where infrastructure is finite, compliance requirements are strict, and operational complexity is high, this centralized gateway layer is what makes large-scale LLM adoption viable. It transforms self-hosted models from isolated deployments into a governed, production-ready AI platform.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Running LLMs on-premise is rarely just an infrastructure decision. It is usually driven by non-negotiable enterprise requirements around data control, security, and governance. An LLM Gateway is what makes these deployments practical at scale.
Enterprises often handle sensitive inputs such as internal documents, customer records, source code, or classified data. In regulated environments, even transient prompt data leaving controlled infrastructure is unacceptable.
An on-prem LLM Gateway ensures that:
This is especially critical for organizations operating under strict data localization or sovereignty requirements.
Direct application-to-model integrations create fragmented security boundaries. Each service ends up managing its own credentials, permissions, and access logic making it difficult to enforce uniform security standards.
An LLM Gateway centralizes:
By routing all traffic through a single control layer, enterprises significantly reduce their attack surface and gain confidence in how models are accessed.
Regulatory frameworks increasingly require organizations to answer questions like:
An on-prem LLM Gateway provides built-in audit trails by default. Every request can be logged, metered, and traced without relying on individual application teams to implement compliance logic correctly.
This is essential for environments subject to GDPR, ITAR, HIPAA, or internal governance standards.
On-prem GPU resources are finite and expensive. Without centralized controls, teams can easily over-consume inference capacity or deploy inefficient workloads.
An LLM Gateway enables:
This allows organizations to treat LLM inference as a managed resource rather than an uncontrolled expense.
An on-prem LLM Gateway is not a single service.it is a layered infrastructure stack designed to control how models are accessed, governed, and operated within enterprise environments.
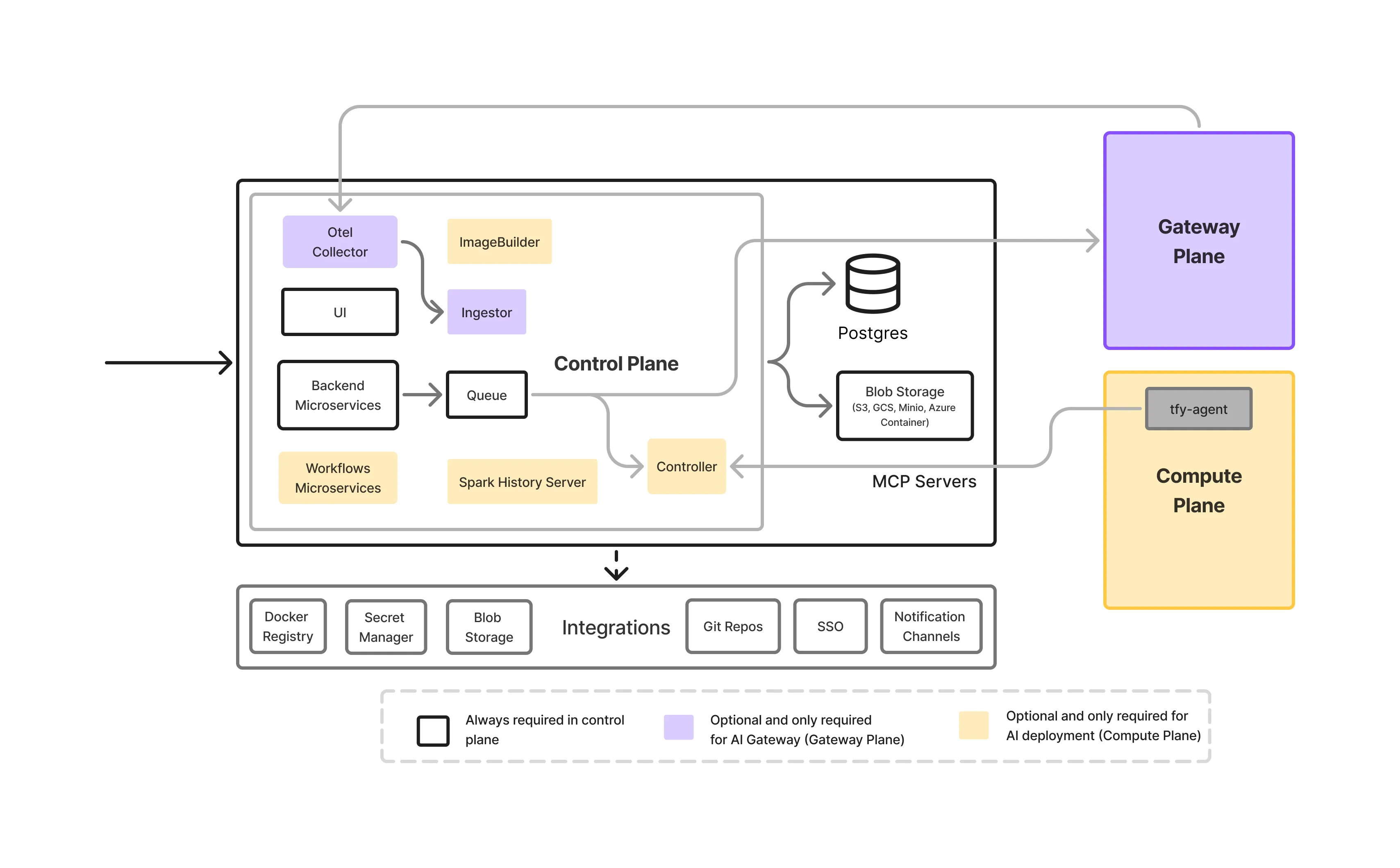
This is the front door for all LLM traffic.
It handles authentication, authorization, request validation, and routing decisions. By enforcing policies centrally, the control plane removes the need for application teams to embed security or governance logic in their code.
This layer is responsible for model serving, hosting the actual LLMs running on-premise and exposing them for low-latency, GPU-accelerated inference, including:
The gateway abstracts these models behind a unified API, allowing teams to change or upgrade models without impacting applications.
Visibility is critical in on-prem environments where resources are limited.
The gateway provides:
This enables teams to understand how models are being used and identify performance or cost issues early.
Governance rules are defined once and enforced everywhere.
This includes:
Centralized governance prevents policy drift across teams and applications.
The gateway and model services typically run on Kubernetes-based infrastructure with GPU support. This layer provides:
It ensures the gateway operates reliably as part of the broader on-prem AI stack.
In an on-premise setup, the LLM Gateway acts as the central control layer between applications and self-hosted models. All requests pass through this layer, ensuring consistent security, governance, and observability.
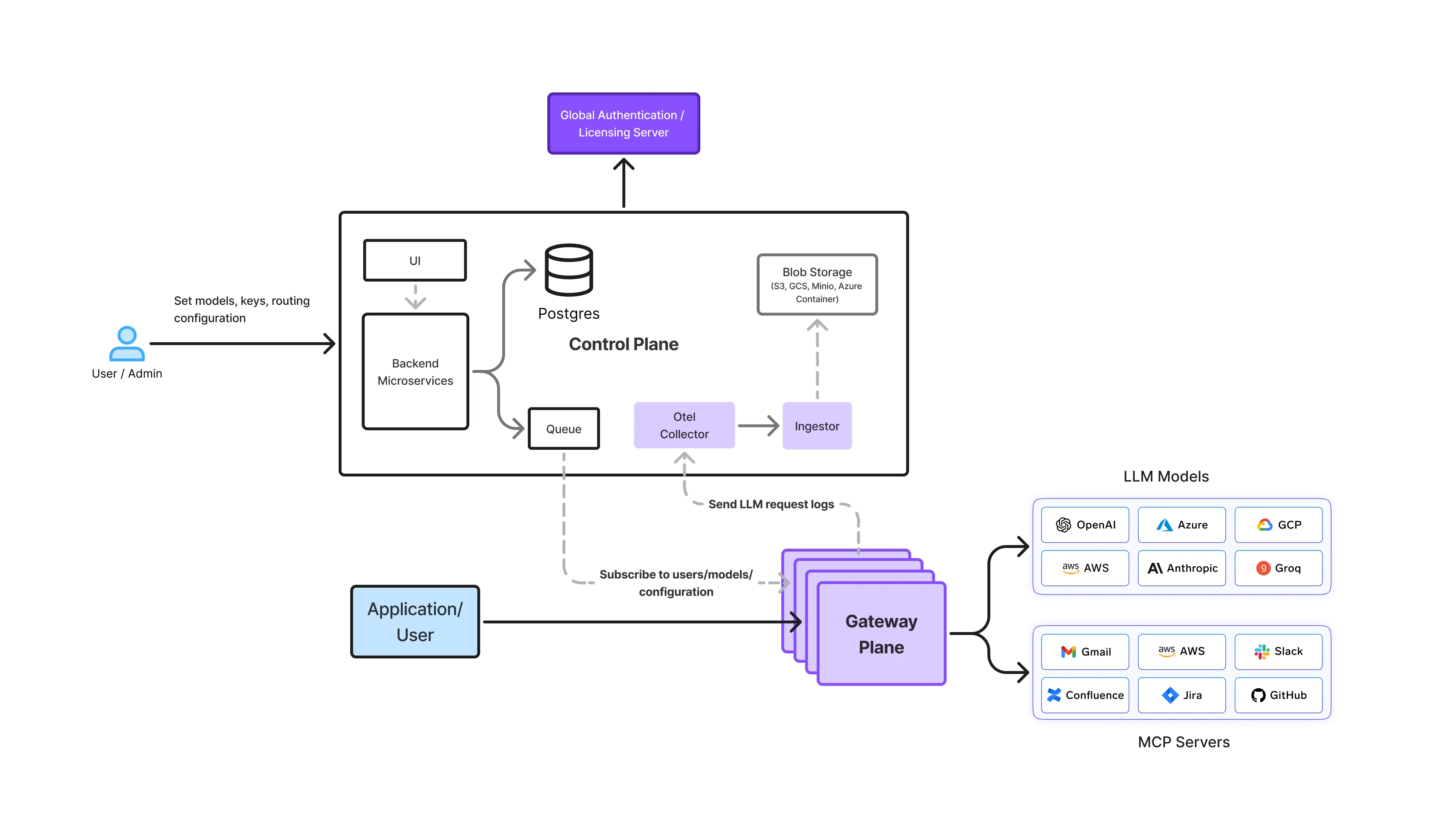
Enterprises deploy on-prem LLM Gateways in different ways depending on security, compliance, and connectivity requirements. The gateway architecture remains the same, the deployment model changes.
In highly regulated environments, infrastructure operates with no external network access.
In these setups, the LLM Gateway provides complete control while meeting strict isolation requirements.
Many enterprises deploy LLM Gateways inside their own cloud accounts or private networks.
This model is common for regulated SaaS and financial services organizations.
Some organizations split workloads based on sensitivity.
The gateway ensures consistent policies even when multiple execution environments are involved.
While on-prem LLM Gateways provide control and compliance, they also introduce operational challenges that enterprises need to plan for.
Managing GPU-backed inference workloads on-prem requires careful capacity planning. Without automation, scaling models or handling traffic spikes can become operationally heavy.
On-prem environments have finite compute. Poor routing or lack of request controls can lead to latency issues or underutilized GPUs. Centralized traffic management is essential to balance performance and efficiency.
As multiple teams adopt LLMs, governance rules can easily drift if enforced at the application level. Maintaining consistent access controls and usage policies across environments is difficult without a centralized gateway.
Enterprises must retain clear records of LLM usage without overwhelming storage or impacting performance. Striking the right balance between observability and overhead is a common challenge.
Enterprises that succeed with on-prem LLM deployments treat the gateway as core infrastructure, not just an API proxy.
All applications and agents should access models exclusively through the gateway. This eliminates shadow integrations and ensures uniform security and governance.
Applications should never depend on specific model endpoints. Abstracting models behind the gateway allows teams to swap, upgrade, or fine-tune models without code changes.
Access controls, rate limits, and usage rules should live at the gateway layer - not inside application logic. This prevents policy drift across teams and environments.
Dev, staging, and production should be isolated at the infrastructure and policy level. This reduces risk and makes experimentation safer.
Capture enough telemetry for auditability and optimization, while masking or limiting sensitive prompt data where required. Observability should enable control, not introduce new risk.
Following these practices ensures that on-prem LLM Gateways remain secure, scalable, and manageable as adoption grows.
As enterprises move beyond experimentation and embed large language models into core systems, control becomes as important as capability. On-premise deployments address data residency, security, and compliance needs but without a centralized access layer, they quickly become fragmented and hard to govern.
An LLM Gateway on-premise infrastructure provides that missing control plane. It standardizes how applications interact with models, enforces consistent policies, and delivers the visibility required to operate LLMs responsibly at scale.
Choosing the best LLM gateway for on-prem deployments requires balancing governance, performance, and operational simplicity rather than focusing on request routing alone.
Rather than treating self-hosted models as isolated services, organizations that adopt a gateway-first approach turn LLMs into managed enterprise infrastructure - secure, observable, and ready for long-term growth.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.




.webp)

.webp)
.webp)
.png)






.webp)
.webp)
