














June 26, 2026
|
5 min read

Published: June 14, 2026

Blazingly fast way to build, track and deploy your models!
The evolution of generative AI has hit a predictable bottleneck: the single-prompt paradigm. Asking one monolithic large language model (LLM) to research, write, review, and format a complex report often leads to context window exhaustion, hallucinations, and degraded reasoning. As artificial intelligence grows more capable, the infrastructure demands grow with it. These are unique challenges that no amount of prompt engineering can fully resolve.
To solve this, engineering teams are adopting multi agent architecture. By dividing complex workflows into smaller, specific tasks handled by distinct AI agents working toward a shared goal, organizations can achieve higher accuracy and reliability. However, while building a multi-agent swarm on a local laptop using agent frameworks like LangGraph, AutoGen, or CrewAI is incredibly easy, deploying agentic systems into enterprise production is a completely different reality.
This guide explores the most effective patterns and use cases for multi agent architecture. We will also cover the severe infrastructure bottlenecks teams face when scaling on traditional cloud platforms and how to overcome them with modern, compute-neutral platforms.
As AI applications grow more complex, relying on a single AI agent to manage many tools, contexts, and responsibilities becomes increasingly difficult. A multi agent architecture addresses this by distributing responsibilities among specialized intelligent agents that collaborate to complete a larger task. Understanding when this pattern makes sense requires examining the limits of single-agent systems and the situations where specialization improves reliability and performance.
One starting point that most teams use is a single agent connected to a small set of available tools. This works well in early prototypes. The AI agent receives a prompt, selects a tool to use, performs the action, and returns a result. However, as more tools and complex workflows are added, this model reveals real limitations.
The first limitation is reliability. When a single agent is responsible for managing a large number of agents' worth of tools, it must constantly decide which tool is most appropriate for each step. As the entire system becomes more complex, the quality of these decisions often suffers. The agent must hold more instructions and reason across more possibilities, leading to incorrect tool decisions and greater latency.
The second solution that addresses this limitation is a multi-agent system. Instead of a single AI agent trying to manage everything, the system is built with smaller individual agents that each specialize in a single role. Each agent is responsible for a different task in a workflow — one for research, another for data processing, another for summarization, and another for execution. Each agent has a smaller reasoning space and is more accurate in its decision-making.
The rationale for moving to a multi agent architecture should be driven by the nature of the problem. Problems that can be decomposed into sub-problems, each handled by a different agent, are strong candidates. Workflows divided into research, planning, execution, and validation steps can be handled by intelligent systems specializing in each stage. Similarly, problems requiring context management across parallel tasks, such as analyzing multiple documents simultaneously, are well-suited to autonomous agents running concurrently.
Another indicator is whether access control is a relevant factor. In enterprise environments, different agents may require different access permissions to external systems. A workflow may require read permissions for one resource but write permissions for another. This division of labor is more secure than granting a single agent simultaneous access to multiple resources.
The reality is that most developers should not use a multi agent architecture from day one. Start with a single agent connected to a small set of tools, validate the workflow, and understand the problem space. Over time, as the system evolves and the single-agent approach fails at tool selection, latency, or reasoning, more agents can be introduced. This gradual evolution toward a team of LLM agents is the most common path for building multi agent architectures that serve specific business needs.
Although multi-agent systems can be designed in many ways, most implementations follow a few recurring patterns that define how different agents collaborate, divide responsibilities, and combine results. These patterns apply across various industries and form the foundation of most production AI systems.
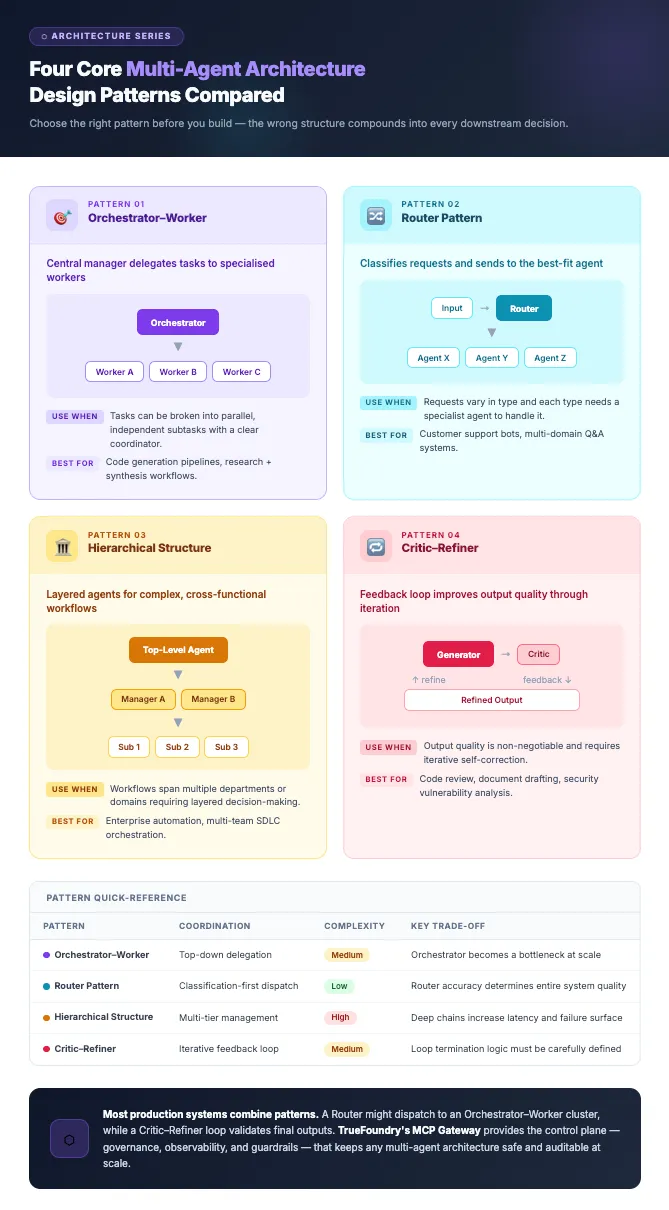
The orchestrator-worker pattern is one of the most common structures used in multi-agent systems. In this design, a central orchestrator agent acts as the manager agent, understanding the overall goal and breaking it into smaller, manageable subtasks. Each subtask is delegated to specialized worker agents that perform it independently, using different skills.
For example, in a research workflow, the orchestrator breaks the task into information retrieval, summarization, validation, and final report generation. Individual agents execute these tasks and pass results, either sequentially or to the next agent in the chain, and the orchestrator combines them into the final output.
This pattern works well when tasks follow a clear sequence and responsibilities can be divided into distinct functional roles. It simplifies coordination because only the orchestrator needs to be aware of the full workflow, while worker agents focus solely on their assigned steps. This separation of concerns is one of its greatest strengths.
The router pattern uses a routing agent, which is a decision-making layer placed at the beginning of the workflow. Rather than directly assigning tasks, this agent analyzes the request and determines which type of specialized agent or agents should process it.
This is especially useful when a wide variety of requests come into the system. In a customer service or customer support system, there may be requests about billing, technical issues, or product information. The router agent analyzes each request and directs it to the appropriate specialized agent. Natural language processing plays a key role here in accurate request classification.
Advanced versions of this pattern use multiple AI agents to process a request when different perspectives or types of analysis are required. The agents provide their answers, which are combined into a final response. This pattern improves efficiency by ensuring each request is processed by the most appropriate agent and delivers the necessary information to the user quickly.
The hierarchical structure arranges agents into layers of responsibility, similar to an organizational management hierarchy. At the top is a high-level supervisory agent responsible for strategic planning and overall coordination. Below it are mid-level agents responsible for specific domains, each managing virtual or worker agents that carry out actions such as retrieving data or performing market analysis.
This structure is particularly well-suited to complex systems with multiple interdependent processes. The hierarchical structure makes it easier to manage the entire system because each level handles a different level of abstraction. This means the system can tackle far more complex tasks without overwhelming any single agent, supporting scalability across various industries from supply chain management to financial services.
The critic-refiner pattern enables the incorporation of a feedback loop that enhances the quality of the AI system's output. In this pattern, one AI serves as the initial output producer, while the other serves as the output critic. The critic receives the output and compares it with the criteria for the output, such as accuracy and completeness.
If the output does not meet the required standard, the producer refines it based on the critic's input. This cycle may repeat several times until quality thresholds are met. The pattern is widely used for creative writing, code generation, report writing, and any generative AI application where precision matters. It minimizes errors and produces more accurate, reliable outputs across complex problems.
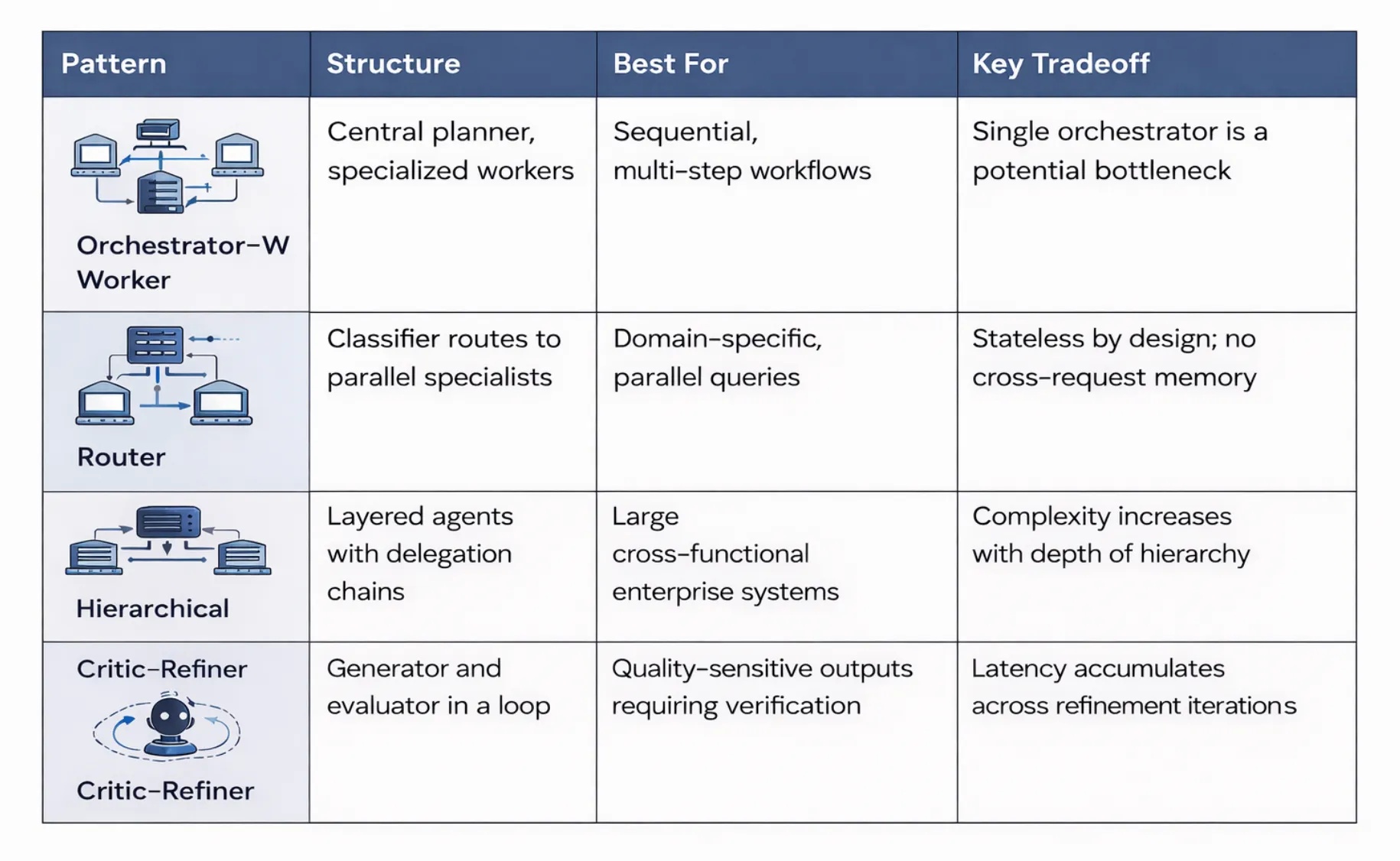
To make these patterns concrete, it helps to see how multi-agent systems are applied in real enterprise workflows across different aspects of business operations. These use cases demonstrate the practical value of autonomous systems in real-time business environments.
In practice, many multi-agent systems that work well in demos begin to fail once they reach production scale. The challenges rarely come from model quality alone but from infrastructure gaps around state management, credentials, observability, and governance. These are the unique challenges of taking autonomous agents from prototypes to software systems that handle real business data.

Here's The Evaluation Framework for Proposal Template
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Gateway & Developer Experience | |||
| Unified model access | Does the platform provide one consistent interface for hosted models, self-hosted models, and provider-native requests? | Must have | ✅ Supported: unified access to 1000+ LLMs. |
| OpenAI-compatible API | Can teams keep existing OpenAI, Anthropic, or provider-compatible client code while moving traffic behind a governed gateway? | Must have | ✅ Supported: OpenAI-compatible API plus native SDK support. |
| Prompt lifecycle management | Can prompts be created, versioned, A/B tested, and reused with a built-in playground for rapid iteration? | Should have | ✅ Supported: versioned prompts, playground, and experimentation. |
| Playground and experimentation | Is there a playground UI for non-developers to test prompts, models, and tools without code? | Should have | ✅ Supported: playground with model and tool experimentation. |

Running multi-agent systems reliably in production requires more than connecting models and external tools. Teams must build supporting infrastructure for state management, identity enforcement, observability, and scalable execution. Without this foundation, even well-designed agent systems fail under real-world load.
As multi-agent platforms mature, many foundational capabilities required for production AI systems are packaged as premium features. Understanding how vendors price observability, state management, and governance helps explain where the real operational costs of multi-agent systems emerge and why they often exceed initial estimates for generative AI initiatives.
Operating multi-agent systems in production requires infrastructure that connects agents, tools, identity systems, and observability into a single execution layer. TrueFoundry approaches this by providing a unified platform that standardizes governance, state management, and runtime visibility across agent workflows.
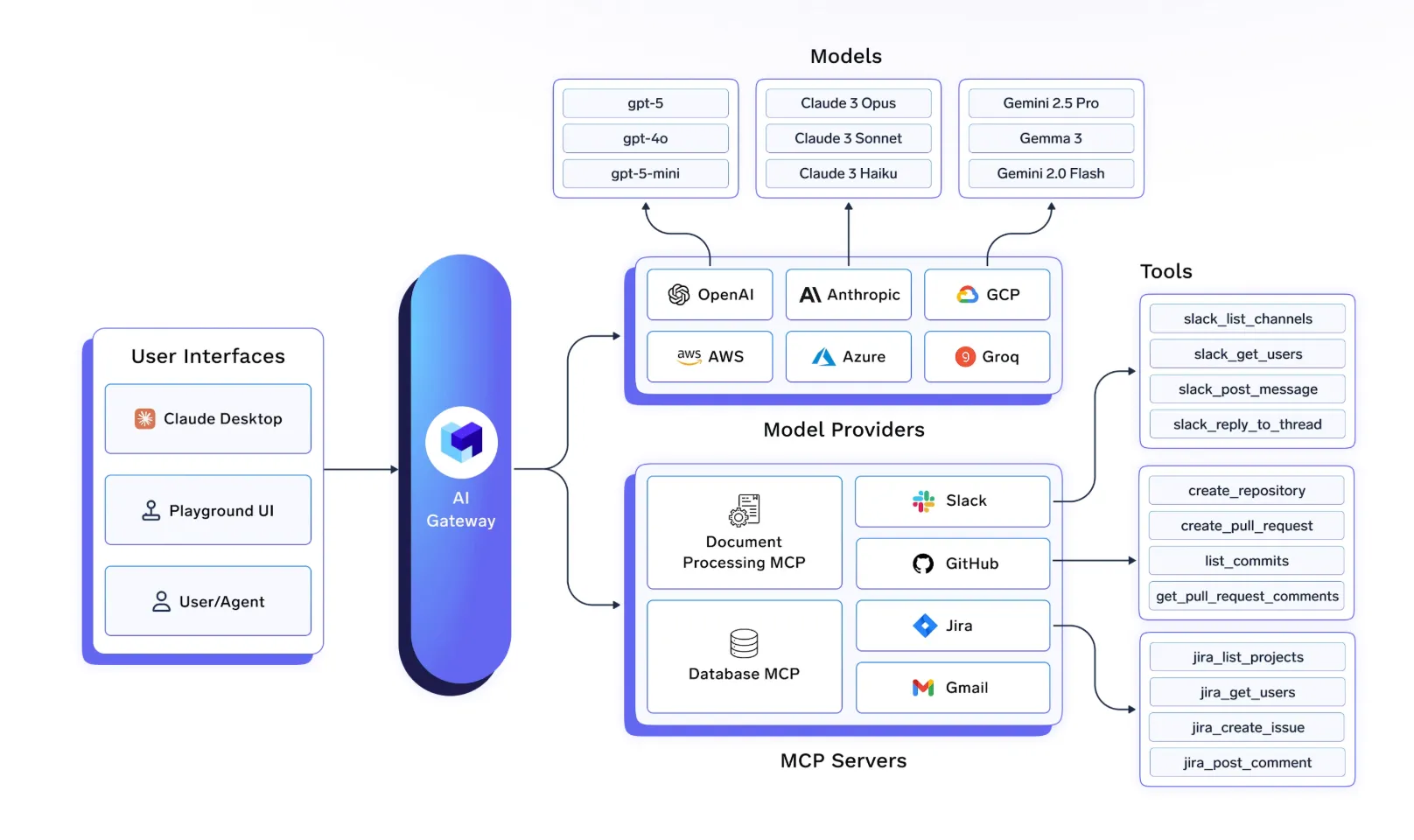
Multi agent architecture is proven for complex, parallelizable enterprise AI applications where single agents consistently fall short. The gap between demo and production comes down to state management, credential governance, and end-to-end observability, the same unique challenges that undermine most autonomous systems at scale.
Teams using lightweight agent frameworks to close this gap accumulate engineering debt that slows them at the worst moment. TrueFoundry provides the unified infrastructure multi-agent systems need, without compute markups or governance paywalls, so your team can focus on building intelligent agents rather than maintaining the infrastructure beneath them.
Multi agent architecture is an AI design pattern where multiple intelligent agents, each with a specialized role, collaborate to accomplish a task. Unlike a single agent handling everything, this approach distributes complex tasks across individual agents: improving accuracy, scalability, and reliability for enterprise AI systems.
A single agent is best used in cases where the workflow is very simple, the AI model uses a limited set of tools, and the context is very limited. However, a multi agent architecture is best used when tasks involve several agents with specific roles, when tasks are parallel, or when agents have separate permission levels.
Some architectural patterns that are commonly observed in multi-agent systems include the Orchestrator-Worker pattern, which uses a central planner that decomposes tasks and assigns them to workers; the Router pattern, which routes requests to the most appropriate agents; and the Hierarchical pattern, which uses a hierarchy of agents in which a higher-level agent manages a group of workers. The Critic-Refiner pattern uses evaluation loops in which one agent produces outputs and another criticizes and refines them.
Multi-agent systems are easy to design and implement in a prototype environment, but in production, several challenges must be addressed. Some challenges include managing state across agent calls, managing credentials for agents connecting to many tools, and debugging issues that span multiple agents. In a production environment, centralized state management, identity-aware execution, and high observability are necessary. TrueFoundry solves this problem by providing a framework that logs agents' actions and manages sessions and tool governance.
One of the issues a multi-agent system faces is managing state across tasks and agents. In a multi-agent system, a working memory is typically maintained between tasks in order to be able to use previous results in a subsequent task. In a production environment, this state is typically retrieved from a backing store, such as Redis or a database, as agents move through a workflow. Managing this state is a significant problem in a production environment because agents may need to be retried in case of a failure.
To run multi-agent systems reliably, however, it is not sufficient to have models and prompts. There are additional requirements for state management, identity-aware tools, centralized agent and tool registries, and overall system observability across the entire chain of agent actions. Compute orchestration is also important for managing concurrent agent workloads and retries. TrueFoundry delivers the infrastructure for integrating these requirements into a single execution layer for enterprise AI systems.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.





.webp)





.webp)






