













.webp)
July 3, 2026
|
5 min read

Published: June 17, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
Many organizations adopting LLMs quickly discover the gap between a successful demo and a production-ready system:
These challenges highlight how wide the gap is between "AI that works in a demo" and "AI that works at enterprise scale." An AI gateway is the infrastructure layer that closes it.
An AI gateway is a middleware layer that sits between your applications and multiple LLM providers - managing routing, authentication, cost tracking, and governance through a single API. Think of it as the air traffic control system for your LLM operations.
Unlike traditional API gateways, AI gateways are purpose-built for LLM workloads - handling token-based pricing, context windows, model-capability routing, and the observability needed to debug complex AI workflows.
Here is a quick snapshot of the best AI gateway solutions:
TrueFoundry isn't just another AI proxy. It's a purpose-built platform designed by engineers who've felt the pain of scaling AI at companies like Meta, Apple, and WorldQuant. The results speak for themselves: sub-5ms latency overhead, 350+ requests per second per CPU core, and production deployments serving millions of daily requests.
The platform's architecture separates the control plane from the data plane, enabling both operational flexibility and performance optimization. Unlike solutions that add latency with every feature, TrueFoundry processes authentication, authorization, and rate limiting in-memory, ensuring consistent sub-millisecond response times even with complex governance rules.
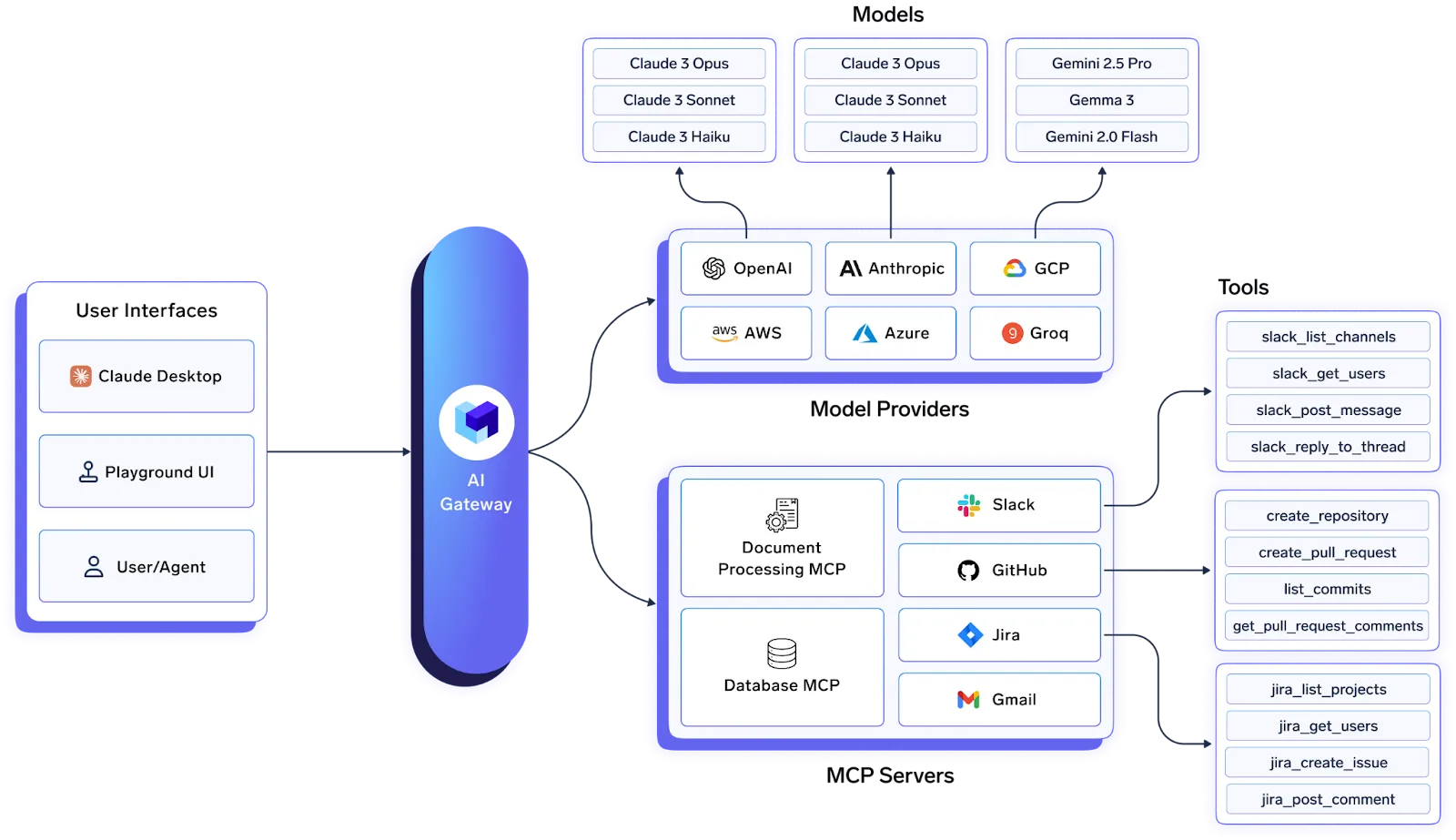
The unified API gives you access to hundreds of LLMs through various vendors (OpenAI, Anthropic, Gemini, Azure, AWS, Databricks, Mistral, Groq, Together, etc.), with support for all OpenAI-compatible providers, along with self-hosted models.
TrueFoundry achieved SOC 2 Type 2 and HIPAA compliance in 2024, with authentication systems supporting Personal Access Tokens for development and Virtual Account Tokens for production, plus OAuth 2.0 integration for enterprise identity providers.
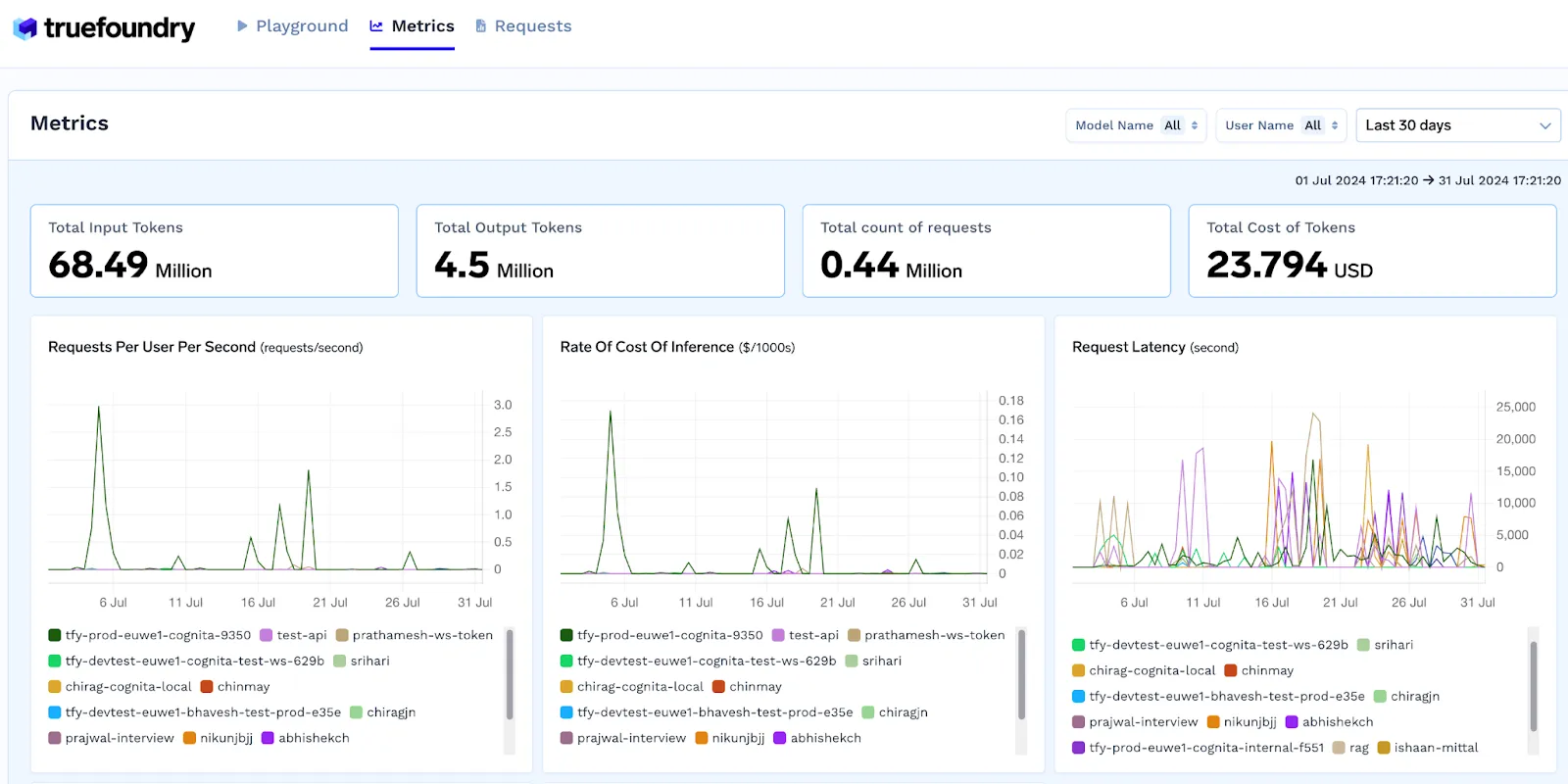
What sets TrueFoundry apart is its comprehensive cost management that goes beyond basic tracking. Token-level usage attribution lets you understand costs by user, team, geography, or any custom dimension. Real-time budget enforcement prevents surprises, while detailed analytics help optimize spending patterns. Teams typically see 30-70% cost reduction compared to direct provider usage.
The Model Context Protocol (MCP) Gateway represents forward-thinking architecture for enterprise tool integration. Instead of building custom connectors for every enterprise tool, you get centralized MCP server management with OAuth 2.0 secured access to tools like Slack, GitHub, and Confluence, plus comprehensive observability across agent workflows.
TrueFoundry's containerization and deployment capabilities support flexible model servers (vLLM, SGLang, TRT-LLM), automatic model caching, and GPU optimization with sticky routing for KV cache optimization. The platform even supports air-gapped deployments for maximum security requirements.
Organizations that need enterprise-grade reliability and governance without sacrificing performance. The platform particularly appeals to teams that value comprehensive observability and monitoring, predictable costs, extensive security management, and integration with existing enterprise infrastructure. If you're managing multiple LLM providers and need granular control over access, costs, and compliance, TrueFoundry delivers the most complete solution. Truefoundry also enables the complete AI-Stack for your team, including managing ML and LLM deployments, integration across providers, and accessing custom and pre-existing mcp server integrations (Slack, GitHub, Sentry, etc.)
Potential Considerations: The comprehensive feature set may be more than needed for simple individual use cases (or use-cases for just starter teams), and the enterprise focus means pricing reflects the full-stack nature of the platform.
Kong is a traditional API management platform that has added AI gateway features to keep pace with market demand. For organizations already running Kong, these additions provide a way to route LLM traffic without introducing a new tool — but this convenience comes with significant tradeoffs when AI is a core workload, not a sidecar.
Kong's plugin ecosystem was built for REST APIs, not LLM workloads. The AI-specific additions, semantic routing, token-based rate limiting, load balancing, are layered onto a platform not designed with LLM-native requirements in mind. Teams consistently report implementation complexity, opaque documentation for AI features, and the absence of capabilities like token-level cost attribution, agent observability, and MCP support that modern AI deployments require from day one.
Kong offers standard enterprise security primitives, OAuth 2.0, JWT, mTLS, RBAC, which integrate with existing identity providers. However, security for AI workloads goes beyond authentication. LLM-native governance requires prompt-level auditing, model access controls by team and use case, guardrails, and compliance tooling for regulated industries. These are not Kong's strengths, and teams building serious AI infrastructure quickly find themselves hitting those limits.
Only when your organization already runs Kong for traditional API management and AI gateway is a minor, low-volume addition to that existing stack — not a strategic capability. If AI is core to your operations, this is the wrong foundation to build on.
Potential Considerations: Kong's pricing model is among the most complex in this space — costs exceeding $30 per million requests, layered across gateway services, API requests, paid plugins, and premium plugins, with enterprise pricing requiring sales consultation. For teams that discover they need more than basic LLM routing, switching costs are high. If your requirement is a purpose-built AI Gateway — with LLM-native observability, token-level cost management, agent and MCP support, and enterprise compliance it might not be the purpose-built vendor.
Also explore: Top 5 Kong AI Alternatives
Portkey positions itself as an LLMOps platform rather than just a gateway, offering end-to-end AI application lifecycle management alongside traditional proxy functionality. The LLMOps functionality of the platform is, however, limited, missing key features like deployment.
The platform provides access to 100s of LLMs through a unified API while extending into prompt management, guardrails, and governance tools. 50+ pre-built guardrails address security and compliance concerns, with automated content filtering and PII detection.
Advanced prompt management includes collaborative templates and versioning capabilities. Real-time monitoring provides comprehensive visibility, though some users report the platform can be overwhelming for new users due to the vast array of features (suggested on AWS marketplace by reviewers of the product).
SOC2, ISO27001, HIPAA, and GDPR compliance certifications, combined with deployment options spanning SaaS, hybrid, and fully air-gapped environments, address enterprise security requirements. The 99.99% uptime SLA provides reliability guarantees.
Organizations requiring integrated LLMOps capabilities beyond basic gateway functionality. The comprehensive feature set justifies the investment for teams building complex AI applications that require sophisticated prompt management and extensive guardrails.
Potential Considerations: Enterprise pricing is complex, key features like budget limits are restricted to Enterprise customers only. Some users report limited export functionality requiring manual support team intervention for data access. The platform’s LLMOps functionality is also limited, as key options like deployment are also not natively supported.
LiteLLM takes an open-source approach to AI gateway functionality, providing a Python-based proxy server that unifies access to 100s of LLM APIs in OpenAI format.
The platform's strength lies in universal API compatibility, supporting major providers with advanced load balancing and retry logic. Cost management features provide basic spend tracking and budget limits, though without the sophistication of enterprise alternatives.
The open-source model provides transparency and customization flexibility. YAML-based configuration management enables infrastructure-as-code approaches, while Docker deployment options support basic production environments.
Teams that value open-source transparency and want to maintain full control over their AI infrastructure.
Potential Considerations: LiteLLM has significant limitations for enterprise use: no formal commercial backing means no enterprise support plan, no SLAs for uptime, and no dedicated escalation path. Users report frequent regressions between versions, edge-case bugs, and instability at scale. The significant latency overhead becomes a bottleneck for real-time applications. Additionally, it lacks advanced observability, security controls, and enterprise features beyond basic routing. The updates also happen slowly and miss out on some lesser-used models, providers, thus hindering basic things like model support for newer models, slowing the development pipeline. In some use-cases, users have to manually raise GitHub issues and add support for newer models across providers.
Lunar.dev is an AI Gateway designed to help teams manage traffic across multiple LLM providers through intelligent routing, caching, rate limiting, and resiliency features. It enables organizations to centralize access to foundation models while improving availability and reducing operational overhead.
Lunar combines its AI Gateway, MCPX (MCP Gateway), and API Gateway into a single control plane, allowing organizations to apply consistent authentication, authorization, auditing, and policy enforcement across model inference, tool calls, and API traffic.
The platform supports intelligent model routing, rate limiting, priority queues, prompt and payload transformation, and data sanitization policies that can be applied per user, application, or AI agent.
Lunar.dev is designed for enterprise deployments with self-hosted VPC installations, air-gapped deployment options, centralized auditing, and SOC 2 compliance available as part of its Enterprise offering.
Best for: Security, IT, and platform engineering teams that need centralized governance across AI model traffic, MCP tools, and enterprise APIs.
When evaluating AI gateways, three technical dimensions matter most:
Performance Characteristics: TrueFoundry's sub-5ms overhead represents best-in-class latency performance, critical for real-time applications and agent workflows. Helicone's 8ms is respectable but still significantly higher, while others introduce substantially more latency that can impact user experience.
Security and Compliance: TrueFoundry's SOC 2 Type 2 and HIPAA compliance, Portkey’s SOC 2, ISO, HIPAA, and GDPR compliance, combined with comprehensive access controls and audit capabilities, provide enterprise-grade security. Other solutions either lack formal compliance certifications or require complex configuration to achieve similar security levels.
As AI usage grows across organizations, having the right controls in place becomes important for security, reliability, and cost management. The following practices can help teams manage AI gateways more effectively.
Centralize AI Credential Management: Store API credentials for providers like OpenAI and Anthropic at the gateway layer instead of embedding them in applications or developer environments. This reduces security risks and simplifies access management.
Implement Strong Access Controls: Use authentication and authorization mechanisms such as OAuth, JWTs, or managed API keys to ensure that only approved users, services, and applications can access specific AI models and endpoints.
Protect Sensitive Data with PII Filtering: Configure the gateway to inspect prompts and responses for sensitive information, including Personally Identifiable Information (PII), and automatically redact or mask data before it reaches external AI providers.
Use Token-Aware Rate Limiting and Budgets: Since LLM pricing depends on token consumption, enforce token-based rate limits and define usage budgets per application or team to prevent excessive costs and maintain predictable usage patterns.
Enable Intelligent Routing and Model Fallbacks: Design the gateway to automatically reroute traffic to backup models or providers when a primary model becomes unavailable, overloaded, or rate-limited. This improves uptime and reliability while supporting a vendor-agnostic architecture.
Establish Comprehensive Monitoring and Auditing: Track AI-specific metrics such as token usage, latency, costs, and model errors. Maintain detailed logs of prompts and responses to support compliance, troubleshooting, and performance analysis.
A traditional API gateway is designed to manage standard API traffic by handling tasks such as authentication, routing, rate limiting, and load balancing. An AI gateway goes a step further by adding capabilities specifically built for AI and large language model (LLM) workloads.
This includes token-based usage tracking, prompt and response monitoring, PII masking, semantic caching, model routing, fallback handling, and AI safety guardrails. While both improve security and traffic management, AI gateways are optimized to address the unique performance, cost, and governance challenges of AI applications.
Running AI in production isn’t just about picking the right model, it’s about managing everything around it. That’s why choosing the best AI gateway solution becomes essential:
Cost Control Gone Wild: LLM costs can spiral out of control faster than any other cloud service. Unlike traditional APIs, where you pay per request, LLMs charge per token, and token usage is inherently unpredictable. A single complex query might use 10x more tokens than expected. Without proper guardrails, a small bug can bankrupt your AI budget in hours.
The Vendor Lock-in Trap: Starting with one provider feels simple, but it creates dangerous dependencies. What happens when OpenAI is down for maintenance? When a model gets deprecated? When the pricing changes overnight? When there is a new high-performing model from another vendor, like Gemini or Anthropic? Teams that hard-code provider-specific APIs find themselves scrambling to rewrite code during outages and these scenarios, making them fall behind their competitors.
Security and Compliance Nightmares: Enterprise data flowing through third-party APIs creates compliance headaches. How do you ensure sensitive customer data isn't logged by third-party LLM routers like OpenRouter, for example? How do you implement role-based access control when different teams need different model permissions? How do you audit AI decision-making for regulatory compliance?
Operational Blindness: LLM applications fail in unique ways. Models can produce incorrect outputs that look correct, use unexpected amounts of compute, or hit rate limits at unpredictable times. Without proper observability, debugging feels like working in the dark.
The solution isn't to build all this infrastructure yourself. That's like building your own database instead of using PostgreSQL. The smart move is choosing the right AI gateway for your needs.
The optimal AI gateway selection depends on your specific requirements, existing infrastructure, and strategic priorities. Here's a practical framework:
Choose TrueFoundry if you need enterprise-grade compliance, extensive LLMOps capabilities, performance, and governance without compromising on any dimension. The platform particularly suits organizations managing multiple LLM providers with granular cost and access control requirements. The unified architecture with comprehensive MCP support and self-hosted model capabilities appeals to teams that want the most complete AI infrastructure management solution. TrueFoundry's sub-5ms latency and proven enterprise compliance make it ideal for mission-critical AI applications.
Choose Kong if you're already running Kong for traditional APIs and want to extend familiar operational patterns to AI workloads, despite the pricing complexity and higher costs. The hybrid approach works for organizations with complex service architectures, though be prepared for the learning curve and cost management challenges.
Choose Portkey if you need integrated basic LLMOps capabilities and can justify the enterprise pricing for sophisticated prompt management and governance tools. Consider the feature complexity and limited data export capabilities when evaluating.
Choose Helicone if performance and developer simplicity are your primary concerns, and you can accept the limitations in enterprise governance features. The approach suits teams building consumer-facing applications where enterprise compliance is not critical.
Choose LiteLLM if you have strong engineering capabilities to manage the open-source complexity and can accept the limitations around enterprise support, stability, and performance overhead. Be prepared for potential production issues and the need for internal maintenance.
The AI gateway market continues evolving rapidly, with traditional API management vendors adding AI-specific features while AI-native solutions mature toward enterprise requirements. Three trends will shape the next generation:
Agentic AI Integration: As AI agents become more autonomous, agentic AI platforms and gateways will need sophisticated orchestration capabilities for multi-agent workflows, tool chaining, and complex reasoning processes. TrueFoundry's MCP Gateway positions it well for this evolution.
Multimodal Support: The expansion beyond text to images, audio, and video will require gateways that can handle diverse data types, manage varying processing costs, and optimize for different latency requirements.
Edge and Hybrid Deployment: Organizations will demand flexible deployment models that support on-premises, cloud, and edge environments while maintaining consistent governance and observability.
The enterprise AI gateway market represents a critical inflection point in AI infrastructure maturity. Teams that get this layer right will have sustainable competitive advantages in the AI-powered future. Those who don't will find themselves constantly fighting infrastructure problems instead of building innovative AI applications.
The choice you make today will significantly impact your ability to adapt as AI capabilities advance. While each solution has merits, TrueFoundry's combination of enterprise-grade performance, comprehensive compliance, and forward-thinking architecture provides the most complete foundation for scaling AI operations. The platform's sub-5ms latency, proven enterprise adoption, and unified approach to LLM management, MCP integration, and self-hosted model support offer the best balance of immediate value and future flexibility.
For teams ready to move beyond experimental AI projects toward production-scale deployments, the choice of gateway platform will determine operational efficiency, security posture, and strategic flexibility. The solutions profiled here represent the current state-of-the-art, but TrueFoundry's comprehensive approach and enterprise-first design make it the strongest choice for organizations serious about scaling AI infrastructure.
Ready to get started? The journey from AI demos to production systems doesn't have to be painful. With the right gateway choice and implementation strategy, you can build AI infrastructure that scales, stays secure, and keeps costs under control. Book a demo today.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




