














July 21, 2026
|
5 min read

Published: February 26, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
The boom in large language models has transformed how teams build AI-driven products, but it has also introduced new challenges. Developers must monitor model performance, optimize costs, refine prompts, and ensure reliability at scale. Managing all these moving parts requires visibility and control over every API call and response.
Helicone emerged to solve this exact problem. It provides a unified platform to track, analyze, and optimize requests to language models such as OpenAI or Anthropic, helping teams debug faster and reduce operational overhead.
However, as organizations evolve, their requirements often surpass what Helicone offers. Some need deeper analytics, on-premise deployment, or stronger control over data privacy. Others look for tools with more flexibility or advanced routing logic.
That’s where alternatives like TrueFoundry come in. Designed for enterprise AI operations, TrueFoundry’s AI Gateway and MCP Gateway provide full-stack visibility, multi-model routing, and compliance-first infrastructure — helping teams scale model usage securely and efficiently.
In this guide, we’ll explore what Helicone is, how it works, why teams seek alternatives, and review the top 5 Helicone alternatives to help you choose the right solution for your AI infrastructure.
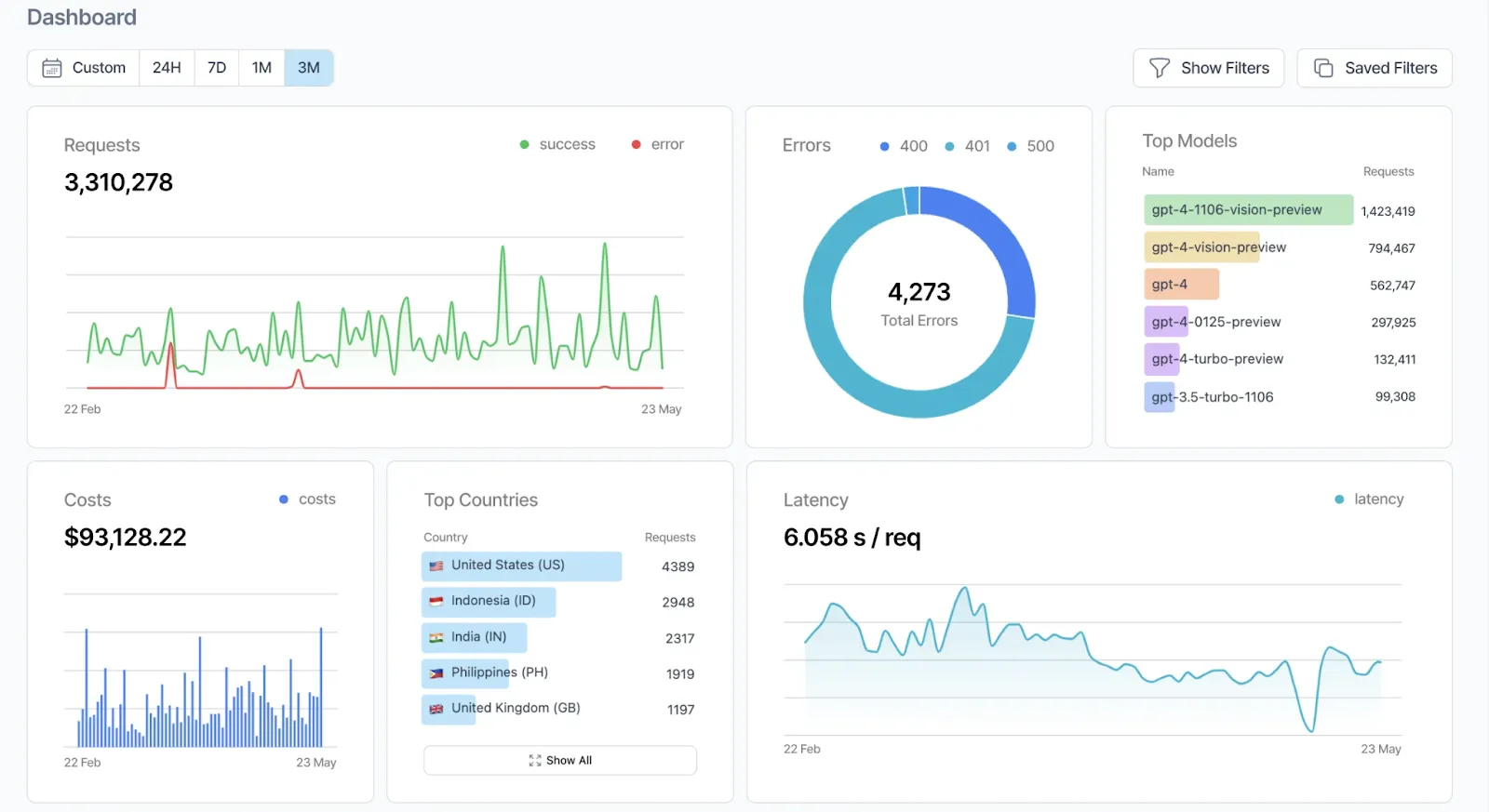
Helicone is an open-source LLM observability and monitoring platform designed to give developers complete control and visibility over their AI applications. It serves as a high-performance gateway that connects your app to leading language model providers such as OpenAI, Anthropic, Google Gemini, Together AI, and many others, all through a single unified interface.
In a rapidly evolving AI ecosystem, visibility and traceability are critical. Helicone simplifies LLM operations by automatically capturing every detail of a request, from prompts and responses to token usage, latency, and cost. This centralization removes the need for manual tracking across multiple APIs and helps teams detect issues, improve performance, and optimize model behavior with precision.
Key Features of Helicone
Beyond its core features, Helicone has built a strong open-source community. With more than 4,000 stars on GitHub and contributions from hundreds of developers, it continues to grow quickly. The community’s focus on transparency and extensibility makes it a trusted choice for AI engineers who want reliability without vendor lock-in.
Whether your goal is to improve model reliability, reduce operational costs, or gain real-time observability across your AI stack, Helicone provides the infrastructure needed to build, monitor, and scale intelligent applications with confidence.
Helicone serves as a unified API gateway that connects your application to over 100 language model providers. By routing requests through Helicone, developers can simplify integrations, improve observability, and optimize model performance without major code changes.
Seamless Integration
Integrating Helicone is straightforward. Developers can configure their existing OpenAI or other LLM SDKs to point to Helicone’s gateway endpoint:
const client = new OpenAI({
apiKey: process.env.HELICONE_API_KEY,
baseURL: "https://ai-gateway.helicone.ai"
});
This approach allows applications to interact with multiple LLM providers using a consistent interface, reducing the complexity of managing diverse APIs.
Comprehensive Observability
Helicone automatically logs detailed metadata for each request, giving developers real-time insights into their AI workflows. Logged data includes:
All this information is available through a centralized dashboard, enabling teams to monitor performance, identify bottlenecks, and analyze usage trends efficiently.
Intelligent Routing and Failover
Helicone includes an intelligent routing engine that optimizes request delivery. Key capabilities include:
This routing system ensures high reliability and consistent performance across different deployment scenarios.
Edge Caching for Performance Optimization
To reduce latency and API costs, Helicone offers edge caching. Frequently requested responses are stored at the edge, allowing faster retrieval and minimizing redundant API calls, improving both speed and cost efficiency.
Flexible Deployment Options
Helicone supports both cloud-hosted and self-hosted deployments:
Both deployment options comply with enterprise-grade standards, including SOC 2 and HIPAA, making them suitable for secure and regulated environments.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

While Helicone provides comprehensive observability, routing, and logging for LLM applications, it may not meet every organization’s specific requirements. Teams often consider alternatives to address limitations in flexibility, cost structure, or specialized features—especially when evaluating trade-offs discussed in helicone vs portkey comparisons.
One reason to explore alternatives is model diversity and control. Helicone supports over 100 models, but some organizations may require native integrations with niche or proprietary LLMs that are not fully supported. Alternatives may offer easier integration with these models or more advanced routing logic.
Key considerations for exploring alternatives include:
Customization and deployment flexibility is another factor. While Helicone supports self-hosting through Helm charts, some teams need deeper control over caching strategies, logging formats, or multi-region deployments. Cost and scalability considerations also drive evaluation. Helicone offers passthrough billing, but enterprises with high-volume requests or strict budget constraints may benefit from tools that optimize usage further.
Exploring Helicone alternatives helps organizations find solutions better aligned with their technical needs, operational objectives, and cost considerations, while maintaining robust LLM observability and reliability.
While Helicone offers powerful observability and routing for LLM applications, it may not fit every team’s specific needs. Developers often explore alternatives to gain more flexibility, enhanced analytics, or specialized integrations.
The following five platforms provide reliable options for monitoring, tracing, and optimizing large language models, each with unique strengths suited to different workflows.
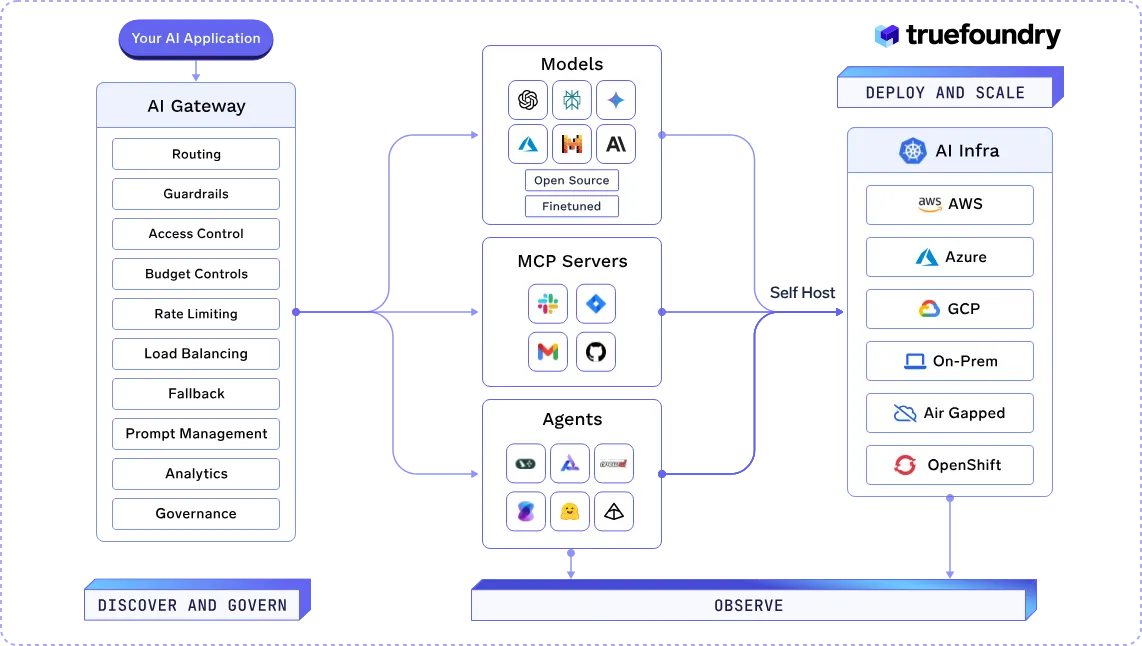
TrueFoundry provides a unified infrastructure for building, deploying, and managing AI applications at scale. It offers tools to orchestrate AI agents, manage model deployments, and ensure security and compliance across various environments.
The platform's core components include the AI Gateway, Model Control Protocol (MCP) Servers, and Tracing capabilities, each designed to address specific challenges in AI application development and deployment.
TrueFoundry is a leading enterprise platform because it unifies AI deployment, observability, and governance in one scalable solution. Its advanced features, like the AI Gateway, MCP servers, and end-to-end tracing, give organizations full control, security, and transparency, making it ideal for managing complex AI applications at scale.
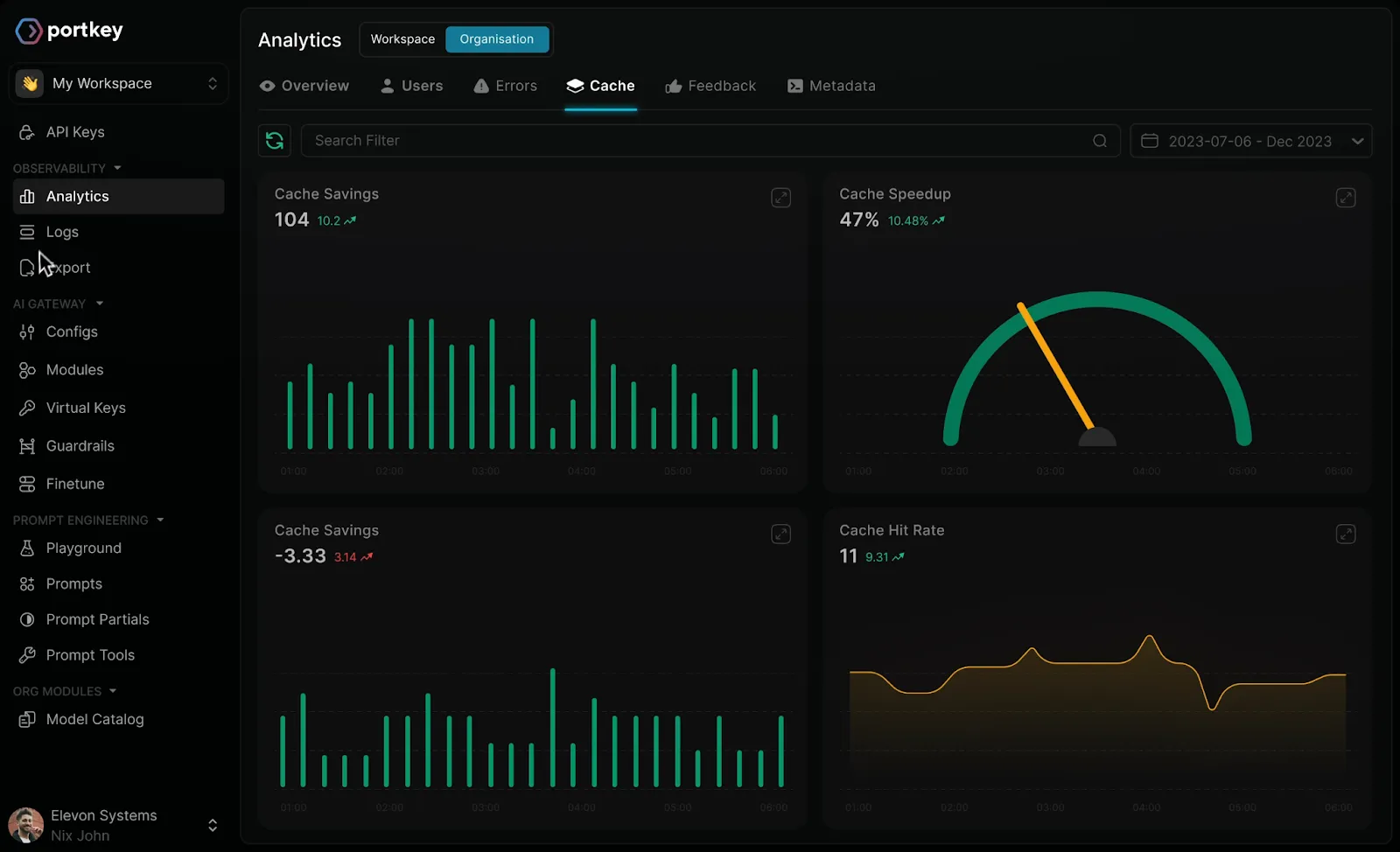
Portkey is an open-source AI gateway built to streamline the way organizations interact with multiple language models. Instead of managing separate APIs for each provider, developers can use Portkey as a single interface to send requests, monitor performance, and route traffic efficiently.
This simplifies workflows and reduces the overhead of integrating and maintaining multiple models simultaneously.
Beyond basic connectivity, Portkey offers intelligent routing features that allow requests to be automatically directed to the most suitable model based on performance, cost, or predefined rules. This is often discussed among teams when comparing alternatives to Portkey. It also supports fallback mechanisms and retries, ensuring reliability even when some endpoints experience latency or downtime. Observability is baked into the platform, with detailed metrics on request success rates, latency, and usage patterns.
Key Features:
Cons:
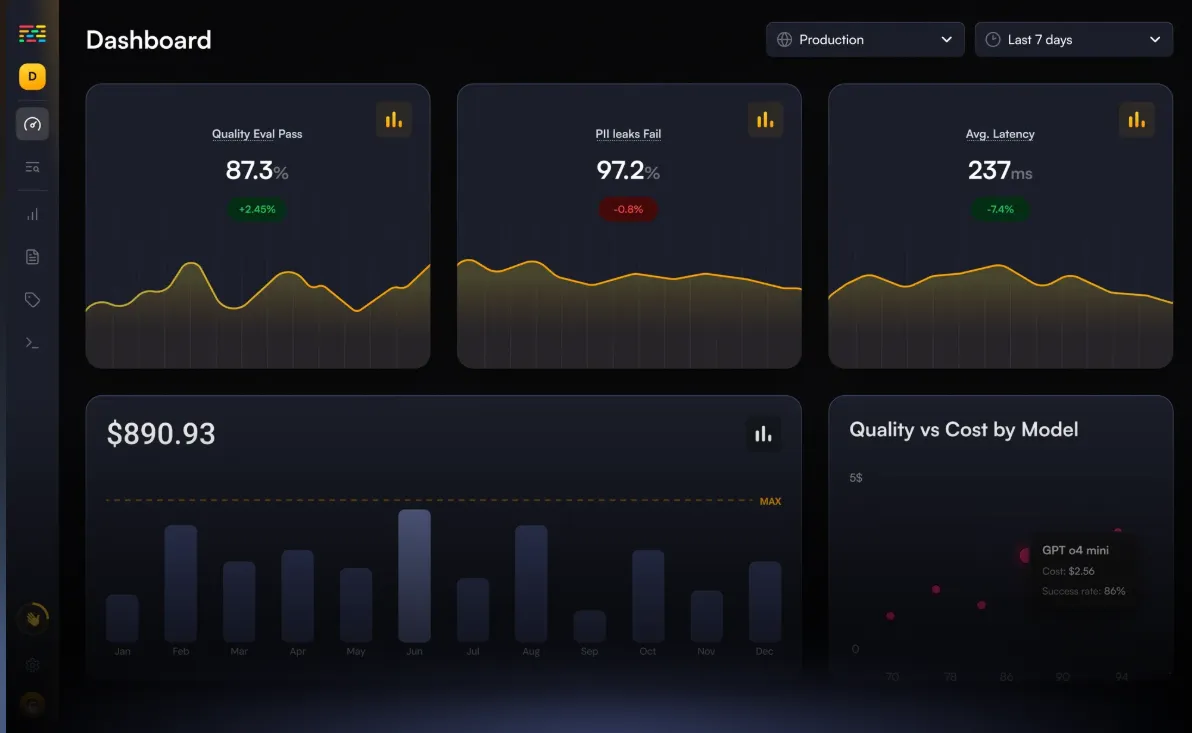
Traceloop's OpenLLMetry is an open-source observability framework built on OpenTelemetry, tailored for monitoring and debugging large language model applications. It provides deep insights into model interactions and performance, facilitating effective troubleshooting and optimization.
Key Features:
Cons:
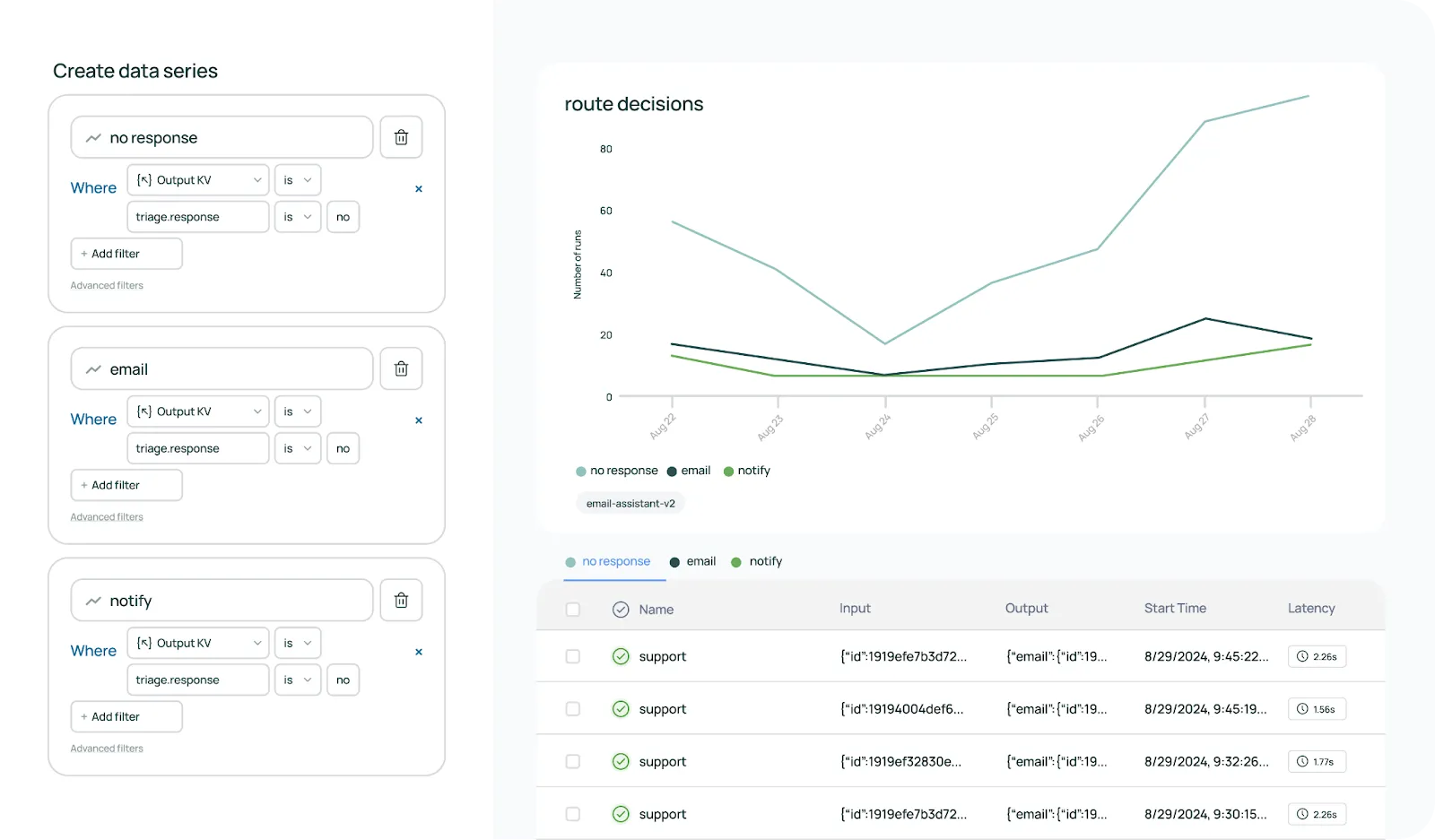
LangSmith, developed by the LangChain community, is a unified observability and evaluation platform for large language model applications. It offers tools for tracing, monitoring, and analyzing AI workflows, enhancing debugging and performance optimization.
Key Features:
Cons:
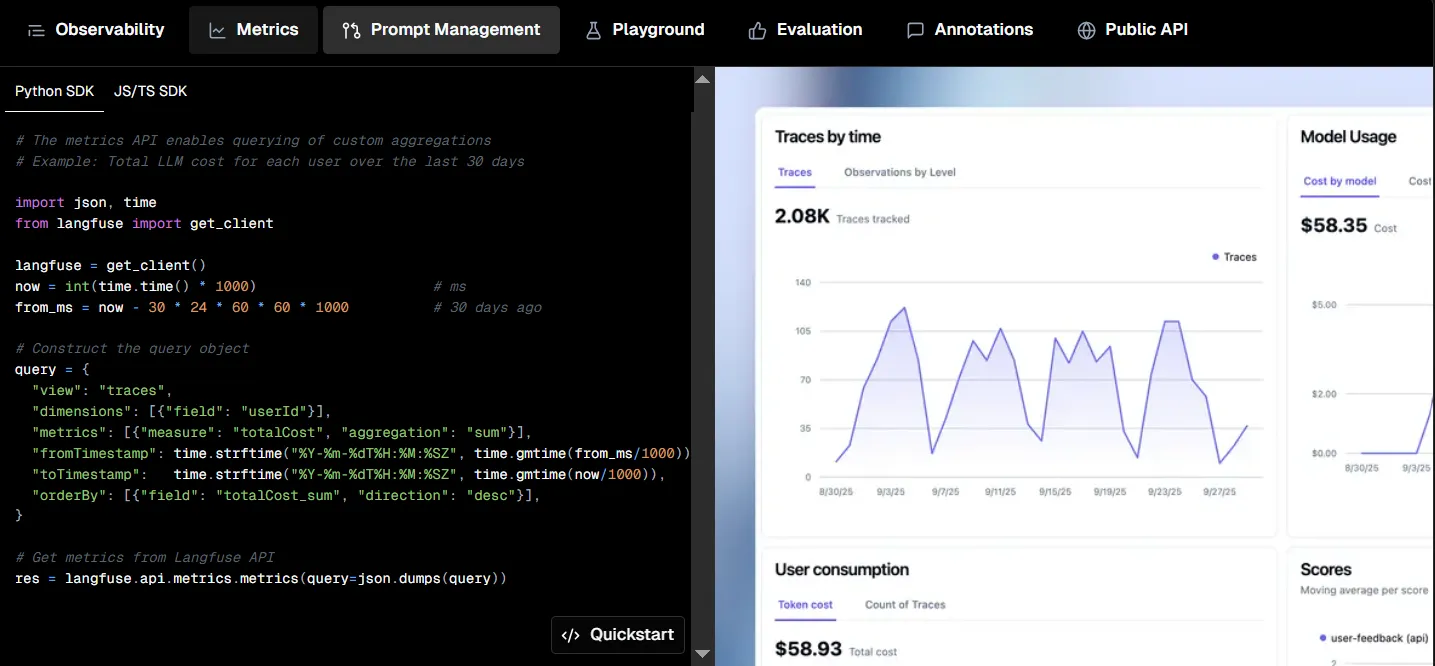
Langfuse is an open-source platform focused on observability and analytics for large language model applications. It enables teams to trace, analyze, and optimize AI workflows, providing deep insights into model interactions and performance.
Key Features:
Cons:
Helicone offers a powerful, open-source platform for LLM observability, routing, and analytics, making it a strong choice for teams seeking comprehensive monitoring of AI applications. Its ability to centralize logging, track token usage, and provide insights across multiple model providers simplifies the operational challenges of building reliable LLM-based systems.
However, as AI applications grow more complex, organizations often require solutions that cater to specific workflows, deployment environments, or integration needs. Exploring Helicone alternatives allows teams to select platforms that align better with their technical and operational requirements. TrueFoundry, for example, provides enterprise-grade orchestration, tracing, and governance with advanced AI Gateway and MCP server capabilities, making it ideal for organizations prioritizing security, compliance, and scalability.
Portkey excels at unified API access and routing across diverse models, while Traceloop delivers deep observability through OpenTelemetry-based tracing. LangSmith offers purpose-built evaluation and debugging for LangChain applications, and Langfuse provides detailed logging and analytics for asynchronous observability.
Choosing the right LLM observability platform depends on factors such as deployment flexibility, model support, monitoring depth, and cost efficiency.
By evaluating the features, strengths, and limitations of each option, development teams can implement robust, transparent, and scalable AI systems that maintain performance, security, and reliability across real-world production workloads.
The best Helicone alternatives for enterprise scale include TrueFoundry, Portkey, and Traceloop. While Helicone focuses on lightweight observability, TrueFoundry provides a unified infrastructure with integrated AI Gateway and security features. Other notable options like Langfuse and Lunary offer open-source tracing for teams requiring deep analytics and specialized evaluation tools for production applications.
Teams often switch when they outgrow basic proxy monitoring and require enterprise-grade governance. Helicone is frequently limited by a lack of strong RBAC, audit logging, and deep support for multi-step agentic workflows. Switching to a platform like TrueFoundry enables deployment within a private VPC and provides advanced cost-control policies necessary for managing production-scale AI systems.
Yes, several prominent open-source alternatives include Portkey, Langfuse, and Traceloop. These platforms allow for self-hosting and deeper integration with existing OpenTelemetry pipelines. For developers seeking a simple Python-based proxy, LiteLLM is a popular community favorite that standardizes API calls across hundreds of models without the overhead and data risks of a managed SaaS provider.
Yes, Helicone supports basic multi-model routing and provider failover through its unified API. However, it lacks the sophisticated, metadata-aware routing logic found in enterprise gateways. Platforms like TrueFoundry extend this capability by allowing teams to define complex fallback chains and team-level quotas, ensuring high availability across both commercial and self-hosted model providers.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


