Get instant access to a live TrueFoundry environment. Deploy models, route LLM traffic, and explore the full platform — your sandbox is ready in seconds, no credit card required.
9.9
Cost Considerations of Using an AI Gateway: Optimizing Enterprise AI Spend
Managing the cost of large language model (LLM) usage has become a mission-critical concern for enterprises deploying AI at scale. Unlike traditional software, LLM-based services often use token-based pricing – providers charge per input/output token – which makes budgeting difficult to predict or control. Multiple factors contribute to this complexity:
Different model pricing: Each LLM provider (OpenAI, Anthropic, Cohere, etc.) or model size has its own rate per token, with larger models (e.g. GPT-4 class) costing significantly more per token than smaller ones.
Unpredictable usage patterns: Token consumption can vary wildly by user, feature, or workflow – one feature might quietly use 10× more tokens than another, and usage can spike unexpectedly with user behavior.
Dynamic prompt pipelines: Advanced use cases like Retrieval-Augmented Generation (RAG), tool-using agents, or multi-step chains can inadvertently expand prompt size and response length, multiplying the tokens (and cost) required per query.
The result is that without proper visibility and controls, teams often don’t realize how fast costs are accumulating until the bill arrives. It’s not uncommon for expenses to balloon unexpectedly, threatening project budgets and impeding scaling efforts. A recent Gartner report also warns that a lack of cost visibility and governance can quickly lead to budget overruns in AI initiatives. In short, as organizations incorporate LLMs into products, controlling usage cost is as critical as model accuracy or uptime. Token-based pricing introduces uncertainty that can sink ROI unless actively managed.
This is where the concept of an AI Gateway comes in. An AI Gateway is emerging as a key component to regain control over LLM usage and spend. Before diving into cost drivers and solutions, let’s define what an AI Gateway is and how it influences cost.
What Is an AI Gateway? (And How It Affects Cost)
An AI Gateway is a specialized middleware layer that manages all interactions between your applications and multiple AI models or providers. Think of it as an API gateway built specifically for AI workloads — one that understands model-specific nuances such as token-based billing, inference latency, and dynamic routing. It provides a unified endpoint for all AI requests, intelligently directing traffic to the right model backend based on policies for cost, performance, or availability.
While adding a gateway introduces minor overhead such as hosting costs and configuration effort — these are outweighed by the control and visibility it provides. By routing every request through a single layer, organizations can monitor usage, enforce budgets, and make real-time decisions about which model offers the best cost-performance trade-off. Gartner describes AI gateways as “intelligent traffic controllers” that help enterprises evaluate and optimize model usage across applications.
TrueFoundry’s AI Gateway functions as this control plane unifying access across models and providers while enforcing enterprise policies such as access control, cost governance, caching, and observability. It turns AI consumption from an unpredictable expense into a managed, measurable, and optimizable system.
Key Cost Drivers in LLM Usage
When using large language models in production, several key factors determine the overall cost of operation. Understanding these drivers is the first step in managing and reducing LLM-related costs:
Model choice and size: The choice of model has an outsized impact on cost. Larger, more advanced models (with higher parameter counts or more capabilities) typically have much higher per-token costs. For example, GPT-4 or other “reasoning” models can cost an order of magnitude more per token than smaller models. Using a top-tier model for every single request – including trivial queries – will inflate costs unnecessarily.
Token usage (prompt and response length): The number of tokens sent in prompts plus the tokens generated in responses directly drives billing. Long conversations or documents, extra-long context windows, or unoptimized prompts that include irrelevant information all rack up token counts. Features like asking the model to be verbose or returning extensive explanations can exponentially increase usage. Effective prompt engineering to keep prompts succinct and outputs focused can significantly cut costs. Every token matters when you’re paying fractions of a cent per token millions of times over.
Traffic volume and patterns: How often and how widely AI features are used will obviously affect cost – but it’s not just total volume, it’s the pattern. Spikey, unpredictable traffic can incur costs during peak usage that bust the monthly budget. Variability between users or features means a few power-users or an internal tool could secretly be consuming the majority of tokens. Sudden usage surges (e.g. a new feature going viral) can lead to unplanned bills if not throttled. Scaling up usage without scaling up cost oversight is a recipe for overruns.
Multi-model usage and provider selection: Many teams use a mix of models – for instance, an open-source model for some tasks and a proprietary API for others, or different providers for different languages. Each model/provider may have different pricing units (some charge per 1000 tokens, others per request, etc.), and possibly additional fees. Moreover, if a team always defaults to the most expensive model “to be safe,” they miss opportunities to save. Selecting the right model for each task is a major cost lever: a simple query doesn’t need an expensive 175B-parameter model when a smaller (and cheaper) model would do. Conversely, some complex tasks might justify the cost of a superior model. The strategy (or lack thereof) in routing traffic to models is a big cost driver.
Infrastructure and overhead: There are also costs beyond the per-token fees. If you self-host open-source LLMs to avoid API costs, you pay in infrastructure – GPU servers, memory, maintenance, and MLOps effort. As one analysis succinctly put it, “Open-source LLMs are not free — they just move the bill from licensing to engineering, infrastructure, maintenance, and strategic risk.” Even using cloud APIs, you may need additional infrastructure to handle requests (e.g. running an internal service or gateway, vector databases for RAG, etc.), which incurs cloud compute costs. Integration overhead and engineering time are “hidden” costs that can creep up.
License or subscription fees: Some models and services entail fixed fees on top of usage. For instance, certain enterprise AI APIs require a monthly subscription or commitment. Even open-source models might have licensing restrictions that push enterprises to paid options. If you adopt a proprietary model serving platform, there could be license costs. These fees need to be factored into total cost of ownership for using a given model – sometimes a “cheaper per-token” model might require an expensive license, nullifying savings.
Integration and inefficiency costs: Finally, how you integrate AI into your systems can create cost inefficiencies. Redundant calls, lack of caching, or poor load management can waste tokens. Early enterprise adopters found that using a standard API gateway or ad-hoc integration led to significant cost overruns – in some cases 300% over initial projections – because the tooling didn’t account for AI-specific optimizations like caching similar prompts or load-balancing across models. There is a cost to building and maintaining your own infrastructure for multi-model access and monitoring. If each team calls AI APIs independently, you miss economies of scale and centralized oversight, often leading to higher aggregate spending than necessary (for example, multiple teams hitting the same model with the same request and paying twice).
Understanding these cost drivers highlights why simply giving teams access to an LLM API is not enough – unmanaged usage across many apps and users will almost inevitably lead to surprises. The more mission-critical and widespread the AI usage, the greater the need for governance.This is where AI Gateways prove their value: they directly target these cost drivers, providing mechanisms to rein in costs without sacrificing performance or reliability.
Managing and Reducing LLM Costs with an AI Gateway
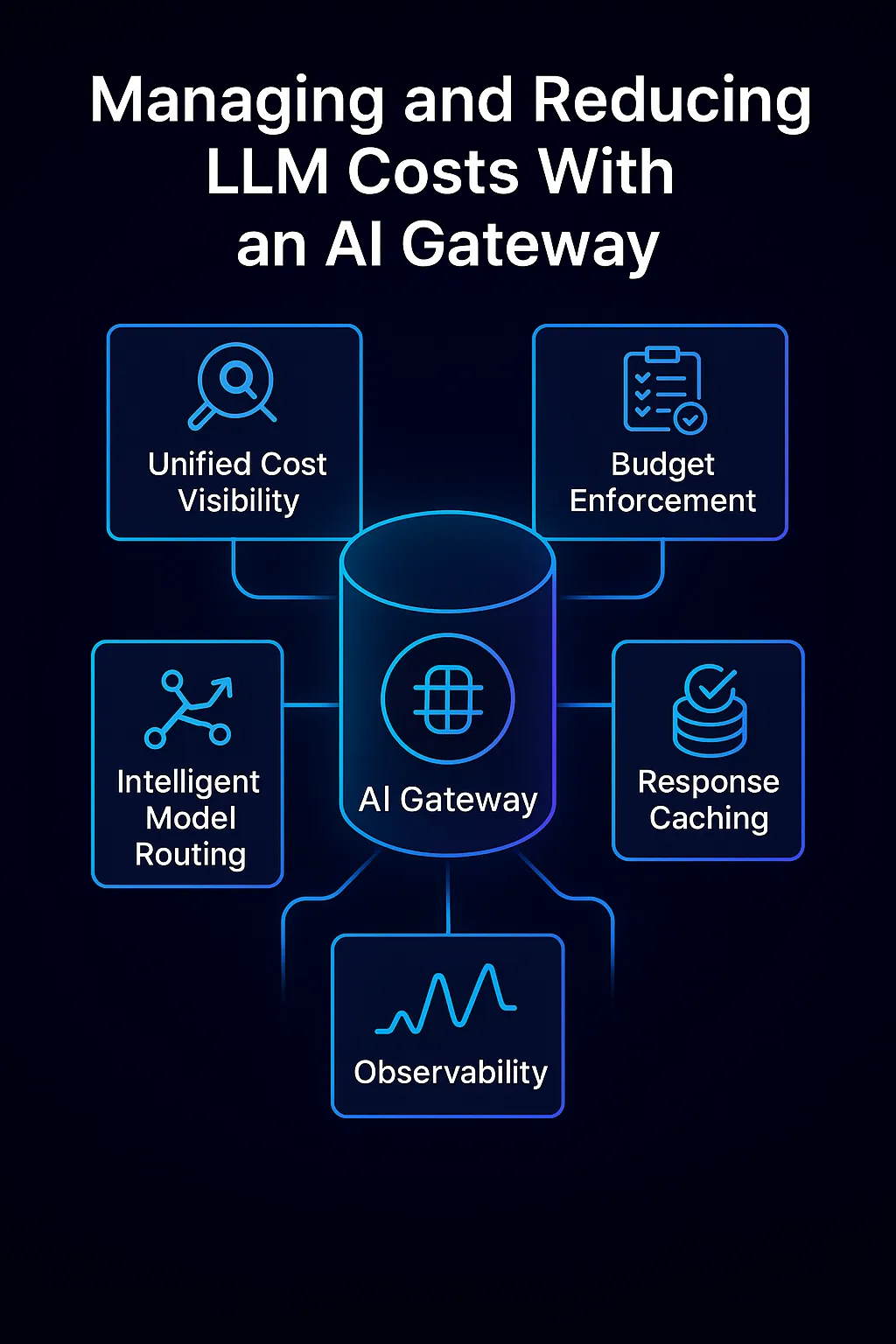
An AI Gateway offers a suite of tools and smart strategies to tackle the cost drivers above. It serves as a central cost governance layer for all AI usage. According to Gartner, AI gateways can mitigate the risk of “spiraling AI costs due to poor governance” by acting as a control point between AI consumers and providers. TrueFoundry’s AI Gateway, as an example, builds in numerous features to monitor and optimize cost. Let’s deep-dive into how an AI gateway helps manage and reduce LLM costs:
Unified cost visibility: All requests route through the gateway, which logs detailed usage metrics for each call – model used, tokens consumed, latency, user/team attribution, etc. This provides granular, real-time visibility into where your token dollars are going. Leaders can finally answer “which applications or use-cases are driving most of our OpenAI bill?” with precision. This cross-app visibility is nearly impossible to get when teams call models directly. With a gateway, you gain a single source of truth dashboard for AI usage and spend. Such transparency enables chargeback/showback accounting (allocating costs to departments), which in turn drives accountability.
Budget enforcement & guardrails: Visibility alone isn’t enough – the gateway also enforces policies to prevent runaway usage. You can define rate limits and quotas (e.g. no more than N tokens or $X spend per day for a given user or feature) and the gateway will reject or throttle requests beyond that. This ensures one misbehaving script or unexpected usage spike doesn’t blow the budget. You can also set up budget alerts or auto-shutoff rules: if a team’s monthly usage exceeds a threshold, the gateway can send notifications or temporarily cut off further calls until approved, preventing surprise bills. Additionally, gateways allow access control and model restrictions – for example, you might only allow expensive models like GPT-4 to be used by certain critical workflows, while less critical uses are restricted to cheaper models. Another form of guardrail is prompt filtering: blocking prompts that would trigger extremely long outputs or otherwise cost-inefficient requests. By applying these governance rules centrally, organizations create hard limits on cost exposure.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Intelligent model routing: Perhaps the biggest cost saver is the gateway’s ability to dynamically route each request to the optimal model or provider based on context. Instead of one-size-fits-all, the gateway can evaluate factors like the query’s complexity, required accuracy, latency, and cost, then choose (or even automatically switch) the model that best meets the needs at lowest cost. For example, a simple factual question could be answered by a smaller, cheaper model with no noticeable quality difference, whereas a complex task is sent to a more powerful model. This kind of real-time model selection slashes costs by avoiding overkill. TrueFoundry’s AI Gateway implements this via smart routing rules and load balancing: you might configure it such that by default queries go to an open-source model like Mistral for speed and low cost, but if the prompt looks complex or if the smaller model’s confidence is low, the gateway routes that request to a larger model like GPT-4. Over hundreds of thousands of requests, this adaptive routing can drive massive savings while maintaining overall quality. It overcomes the false dichotomy of choosing either a high-performance or a low-cost model – you can have both by using each where they make sense.
Response caching: Another cost optimization is caching repeated or common AI responses. If multiple users ask the same question or your system makes identical queries repeatedly, an AI gateway can return a cached answer instead of calling the model again, saving those tokens entirely. Even caching partial results (like expensive intermediate steps) can help. This is especially useful for backend tasks or apps where the same prompt is used frequently. Caching not only reduces cost but also improves latency for those queries. TrueFoundry’s gateway supports both straightforward caching and more advanced semantic caching – where semantically similar prompts can be treated as cache hits. (Semantic caching must be used carefully, as subtle differences in prompts could change the answer, but in the right scenarios it can boost cache hit rates and reduce cost.) Studies have shown semantic caching mechanisms could reduce LLM API costs by up to 70% in enterprise use cases. In practice, even a simpler cache for identical requests provides a significant cost cushion for high-volume apps
Observability & anomaly detection: Because the gateway monitors all requests, it can also detect anomalous usage patterns that might indicate a bug or abuse. For example, if this hour shows 5× the token usage as the last, or one application suddenly starts spamming the model with large prompts, the gateway (and its integrated dashboards) will surface that anomaly. Early detection means you can intervene before it drains the budget. The observability also feeds into reliability: it tracks error rates and latencies, helping differentiate cost-related slowdowns from model issues. Some gateways, like TrueFoundry’s, integrate with tools like OpenTelemetry so you can merge LLM usage metrics with your overall monitoring stack. This holistic observability ensures you maintain cost and performance targets. It also enables internal chargebacks – since usage is centrally logged, you can hold teams accountable for their portion of the AI bill, incentivizing them to be efficient.
How an AI Gateway manages and reduces LLM costss, combining unified visibility, budget enforcement, intelligent model routing, caching, and observability into one control layer.
All these capabilities combine to enforce cost discipline without constant manual oversight. By using an AI gateway, cost management becomes proactive and automated: you have cost limits in place so you can’t overspend, you have real-time insights to adjust usage patterns, and you have automated optimizations (routing, caching) squeezing out inefficiencies on the fly. It turns what could be an opaque, runaway cost center into a governed utility.
TrueFoundry’s AI Gateway exemplifies these cost controls in practice. It provides built-in cost tracking dashboards, budget policy configuration, multi-model routing rules, and caching mechanisms, all configurable through an enterprise-friendly interface. The result is that companies can embrace more AI use cases without the fear of unpredictable bills. Of course, employing such a gateway introduces some considerations around performance and architecture, which we discuss next.
Balancing Cost, Accuracy, Latency, and Complexity
Any strategy to aggressively rein in costs must be balanced against other technical and business requirements. Trade-offs are inevitable. In the context of LLM deployments, the key dimensions to balance are cost, accuracy (or quality of results), latency (response speed), and architectural complexity. An AI gateway helps manage these trade-offs, but understanding them is important for setting the right policies:
Cost vs. Accuracy: Higher-quality models usually mean higher costs but not every task demands GPT-4-level reasoning. A smaller 7B model can answer “What’s the capital of France?” as accurately as a flagship model, but not a complex legal question. The key is to use the gateway’s routing intelligence to decide when premium accuracy is worth the price. Route everyday tasks to smaller models, and reserve high-end models for complex reasoning. Over time, analytics help refine these thresholds striking the balance between acceptable accuracy and substantial cost savings.
Cost vs Latency: Cheaper models often deliver faster responses too, especially when hosted locally. However, naïve multi-model routing can introduce latency if the system tries one model, then falls back to another. TrueFoundry’s Gateway mitigates this with latency-based and load-aware routing, ensuring requests flow to the fastest viable model without unnecessary hops. Its architecture adds only a few milliseconds of overhead (~3–4 ms per request) — negligible compared to model inference times so teams gain efficiency without compromising user experience.
Cost vs. Architectural Complexity: Adding an AI Gateway introduces an extra layer of infrastructure, but also delivers visibility, guardrails, and reliability that single-model setups lack.For small teams or prototypes, direct model calls might suffice. But as usage scales, centralized routing, caching, and cost governance become essential.
Ultimately, balancing these factors is an ongoing exercise. The best practice is to continuously monitor the impact of your cost-saving measures on model output quality and user experience (which the gateway’s observability helps with), and adjust the knobs (routing rules, cache settings, etc.) accordingly. The beauty of the AI gateway approach is that you have these knobs to turn – you’re not locked into a one-size-fits-all model usage. You can dial up or down the spending in certain areas while preserving what matters most for your application, be it response time or answer accuracy.
Best Practices for LLM Cost Optimization Using a Gateway
To get the most benefit from an AI gateway, organizations should combine the technology with sound usage strategies. Here are some practical best practices for optimizing LLM costs while maintaining performance:
1. Optimize prompts and outputs. Trim unnecessary tokens and keep prompts focused. Overly long or verbose instructions waste tokens. Structured formats — like bullet points or JSON schemas — keep responses concise and predictable. Review and shorten common context prompts that get prepended to every call. This “zero-cost” optimization directly lowers spend.
2. Use hybrid model routing. Adopt a tiered model strategy: route simple or low-stakes queries to smaller, cheaper models, and complex ones to premium models. Many teams follow a 90/10 pattern — 90% of traffic to fast, low-cost models; 10% to high-quality ones for critical tasks. TrueFoundry’s Gateway automates this through rule-based or ML-based routing, ensuring you never overpay for capability you don’t need.
3. Batch and parallelize calls. When paying per token or per call, minimize overhead by batching multiple prompts into one request. TrueFoundry’s batch inference API lets you group related tasks — ideal for periodic jobs like summarizing large document sets. In some cases, parallel requests can be sent to both cheap and expensive models, cancelling the costlier one if the first returns a satisfactory result.
4. Cache high-frequency queries. Reuse results instead of recomputing them. The Gateway supports both exact-match and semantic caching, where similar prompts can reuse prior responses. Even modest cache hit rates can save significant token spend while improving latency — a major win for repeated workflows or common queries.
5. Fine-tune or specialize models. For repetitive, domain-specific tasks, fine-tuning a smaller model or integrating RAG (retrieval-augmented generation) can shorten prompts and reduce tokens. TrueFoundry’s platform supports fine-tuning and custom deployment, helping teams balance precision and efficiency at scale.
6. Leverage open-source or self-hosted models. At high volumes, it can be cheaper to host open-weight models on dedicated GPUs rather than pay per API call. The Gateway allows seamless hybrid deployment — routing some traffic to self-hosted models while maintaining unified logging and policy controls. This hybrid setup can yield substantial cost savings while preserving flexibility.
In addition to these practices, always
monitor and iterate
. Use the data from the gateway to see which strategies are having the most impact (e.g., cache hit rates, tokens saved by routing, etc.) and adjust accordingly. Cost optimization is not a one-time set-and-forget, but the gateway gives you the tools to make it an ongoing, manageable effort rather than a fire-fighting surprise.
TrueFoundry’s Approach to Cost Tracking and Governance
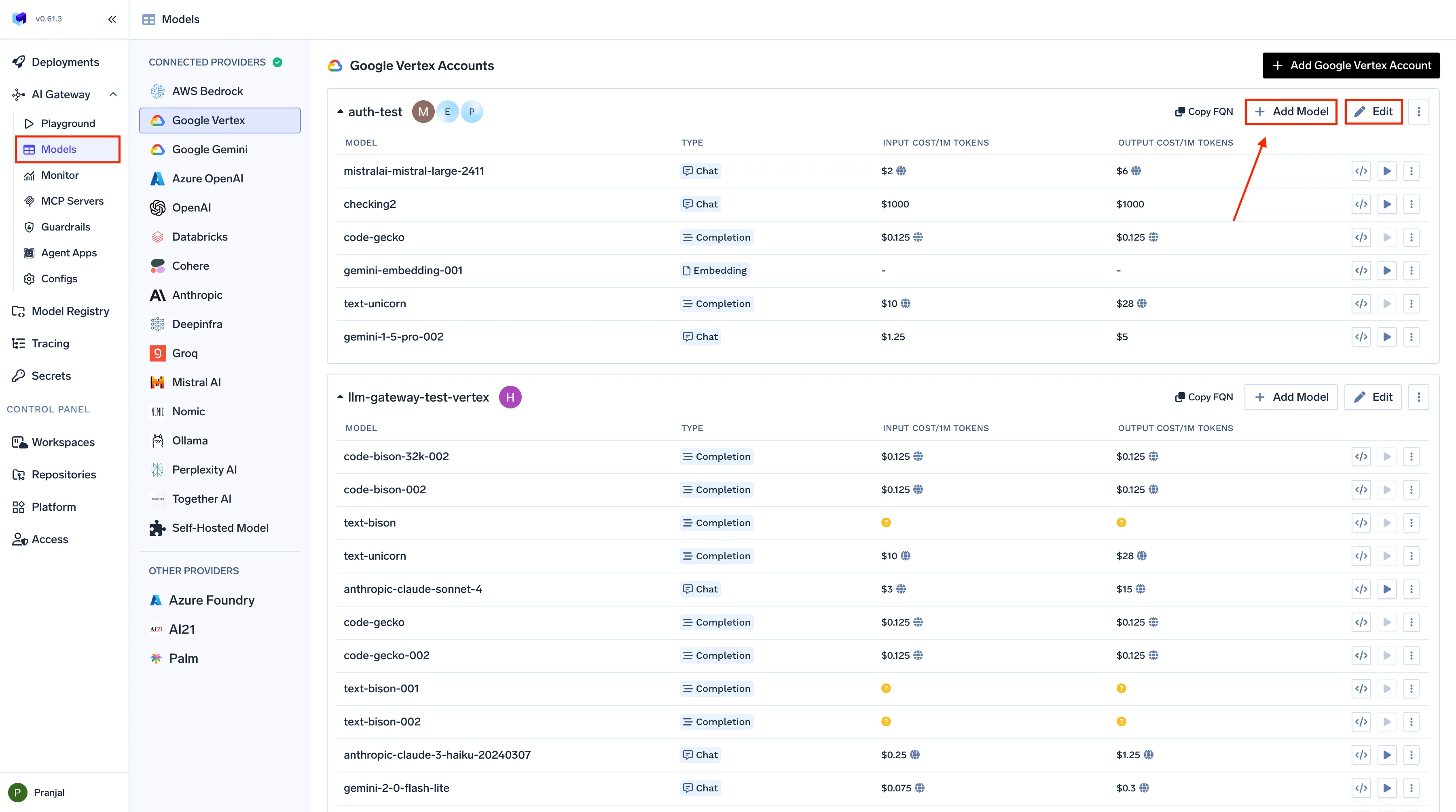
While cost optimization is a universal challenge across LLM deployments, TrueFoundry’s AI Gateway turns it into a structured, measurable, and continuous process. Instead of relying on manual budgeting or scattered cost reports, TrueFoundry embeds governance directly into the infrastructure layer — ensuring every AI interaction is logged, priced, and attributed in real time. This unified infrastructure enables structured LLM cost tracking solution, allowing enterprises to monitor spend at the model, team, and workflow level with complete transparency.
TrueFoundry's Model Cost Configuration Interface
1. Real-Time Cost Attribution
Every request that passes through TrueFoundry’s Gateway is automatically tagged and priced. The system combines input/output token counts with model-specific pricing data, whether from public APIs or enterprise-negotiated rates — to calculate the exact cost per inference. Teams can filter these metrics by model, team, environment, or user, giving precise visibility into who or what drives spend. This makes it simple to allocate costs, run internal chargebacks, or justify ROI for AI features.
2. Configurable Model Pricing and Budgets
TrueFoundry enables enterprises to define custom pricing per model, aligning internal tracking with actual provider contracts or self-hosted compute costs. Administrators can also create budget thresholds or quotas for each app or environment. When spend exceeds a defined limit, the Gateway can trigger automated alerts or even enforce temporary throttling ensuring cost containment without manual intervention.
3. Integrated Observability
TrueFoundry exports cost and usage data to Prometheus and OpenTelemetry, integrating seamlessly with existing monitoring pipelines. This allows AI cost, latency, and reliability metrics to appear in the same dashboards used for infrastructure and application monitoring. The result is a single pane of glass where engineering, finance, and product teams share a unified view of performance and spend.
4. Governance by Design
Because every call includes metadata tagging (team, project, and environment), organizations can implement structured accountability across departments. Combined with role-based access control (RBAC) and model-level permissions, this ensures that high-cost or high-risk models are only accessible to approved teams. These guardrails make compliance, budget discipline, and transparency automatic — not manual.
When an AI Gateway May Not Be Justified
AI Gateways deliver immense value at scale but not every organization needs one right away. For small teams or early-stage projects using a single model and low request volumes, deploying a full gateway may be unnecessary overhead. A prototype calling one OpenAI model with a few thousand tokens a day can be managed easily with direct API calls and basic monitoring.
Industry guidance suggests that when usage is limited (tens of thousands of tokens per month) and compliance or reliability needs are minimal, a lightweight proxy or manual tracking may suffice. The gateway’s true advantage emerges as workloads scale or diversify across models and providers. If your organization is still experimenting with LLMs or has minimal infrastructure, focus on iteration first but plan ahead. TrueFoundry’s Gateway, for example, can scale down efficiently, offering early visibility and governance without heavy setup. In short, assess your AI maturity and scale: for single-model, low-volume use cases, a gateway may be premature; as adoption grows, it quickly becomes essential for cost control, reliability, and long-term governance.
Conclusion
Controlling LLM costs in enterprise environments is complex but AI Gateways are built to solve exactly that. Instead of leaving costs to chance, a gateway like TrueFoundry’s embeds cost governance directly into your AI architecture. Through centralized tracking, budgeting guardrails, intelligent routing, and caching, it turns cost control into a built-in capability rather than an afterthought.
Enterprises using AI gateways report 40–60% reductions in inference costs, along with higher reliability and security. TrueFoundry’s Gateway, in particular, delivers accountability by design — giving teams fine-grained visibility, cost attribution, and chargebacks — and risk reduction at scale via automated limits and fail-safes. It also provides full transparency into usage patterns so no cost or latency issue goes unnoticed.
By unifying policies across regions and teams, the Gateway ensures consistent governance and compliance — critical for industries handling sensitive data. The result: AI projects move from experimentation to production with predictable spend and operational confidence.
In short, AI Gateways make LLM adoption sustainable. Token-based pricing may be unpredictable, but with TrueFoundry’s centralized control plane, enterprises can optimize spend, enforce guardrails, and scale responsibly. It’s how innovation and fiscal discipline coexist — turning AI into a governed, efficient, and enterprise-ready capability.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.





























.webp)


.webp)
.webp)
.webp)
.png)






.webp)
.webp)