
.png)
July 30, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 16, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Six months after Noor’s loops moved off her laptop, Northwind has eleven registered triage and maintenance loops, and the problems have changed shape. Nothing is on fire the way the weekend token bill was on fire. Instead: two loops both “own” the release-notes draft and overwrite each other every Friday; the Tuesday dependency-bump loop quietly stopped doing anything useful three weeks ago because a model it depended on was deprecated and it kept passing its own checker anyway; a security reviewer noticed that the loop reading inbound bug reports will cheerfully follow instructions written in a bug report; and the cheapest, most-used loop now spends more than the next four combined, and nobody can say whether it’s worth it. None of these are the failures the first post fixed. They’re the failures that only appear once the pattern works well enough to multiply. That’s the subject here.
The first post did the vertical translation — laptop primitive to governed primitive, one loop at a time. This post does the horizontal one: what an organization has to make true across loops and over their lifetime. The vocabulary still follows Addy Osmani’s June 2026 essay and the surrounding discussion (Steinberger, Cherny, Willison), paraphrased with credit; the enterprise half follows TrueFoundry’s Agent Harness and Gateway documentation.
The first post vs. this one
Osmani’s anatomy describes a loop in the singular — one heartbeat, one set of skills, one maker and one checker. That is the right way to learn the pattern and the wrong way to run it, because loops do not stay solitary. They are useful, so they reproduce, and the moment there are several they start interacting in four ways the single-loop picture never has to account for.
Four ways loops interact once there is more than one
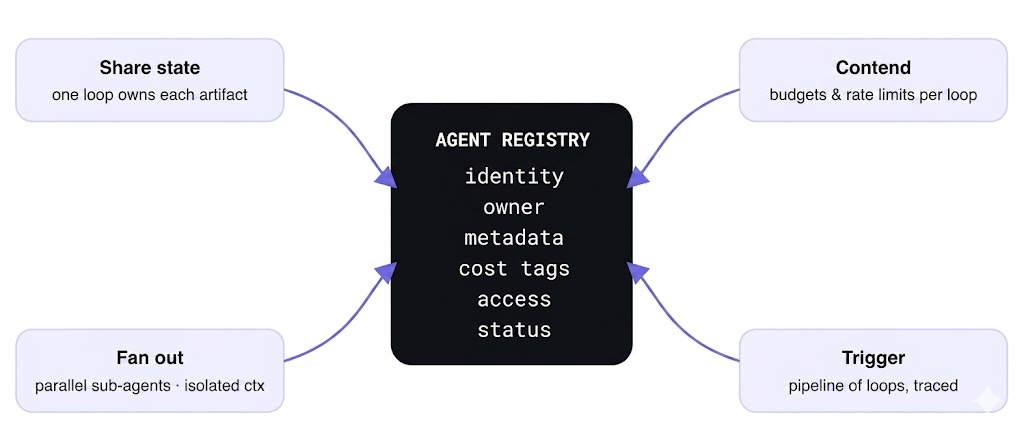
The fan-out case is already first-class on the harness. TrueFoundry’s Agent Harness sub-agents let the root agent delegate focused subtasks to parallel sub-agents, each with its own isolated context, returning only concise results — a context-hygiene win and a fleet-management win, since each delegated run is a unit you can trace independently. Delegation is deliberately one level deep and sub-agents can’t message the user — guardrails against a fleet that spawns a fleet that spawns a fleet. (Worth being precise: sub-agents share the root agent’s tools and sandbox, so the isolation here is about context, not a separate set of tool grants — privilege boundaries belong at the agent and MCP level, which is the next section.)
The operating pattern that answers all four interactions is to treat each loop as a registered agent definition rather than a script, so the fleet has an inventory. On the harness, each loop is an agent definition — a model, MCP servers, skills, instructions — that lives in a catalog, runs in the same gateway plane as all other model and tool traffic, and carries its own identity. That last word is what makes the fleet tractable: per-agent identity is what lets contention, cost, and access be reasoned about per loop instead of per laptop. Northwind’s release-notes collision gets fixed not with cleverness but with ownership — one loop owns the artifact, the registry says so, and “which loops touch this?” is a lookup, not a hunt.
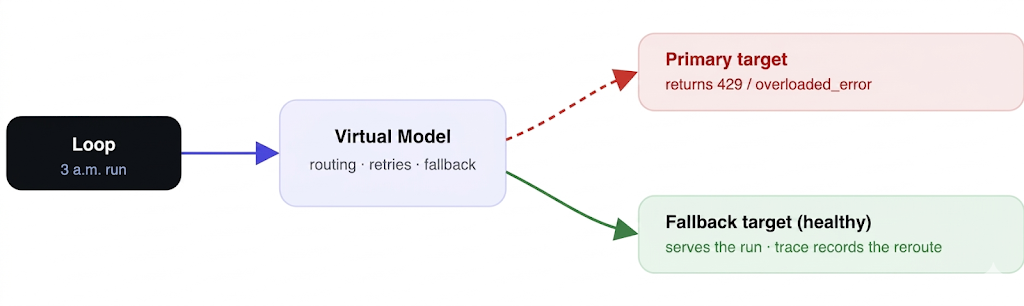
The defining fact about a loop is that nobody is watching it, and the corollary the single-loop discussion underplays is that nobody is watching it when the world breaks. A human at the keyboard absorbs a provider 503 without noticing — they just hit enter again. An unattended loop at 3 a.m. meets the same 503 and either dies, or worse, retries forever against a broken dependency and reprises Noor’s weekend bill. Reliability mid-run is not a nice-to-have for loops; it is the difference between a loop and a liability.
The AI Gateway is where a loop borrows the reliability it can’t build for itself.
Reliability a loop borrows from the gateway
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada

.webp)
.webp)




.webp)


.webp)
.png)
.webp)
.webp)
.webp)




