













Más de 1000 marcas mundiales confían en nosotros
Sirva a cualquier modelo, a cualquier marco
IA generativa
Sirve cualquier modelo de Hugging Face en texto, imagen, multimodal y audio, con total compatibilidad con puntos finales compatibles con OpenAI
ML tradicional
Implemente y escale sin esfuerzo modelos creados con XGBoost, scikit-learn y LightGBM para obtener predicciones confiables y de alto rendimiento.
Aprendizaje profundo
Ejecute modelos listos para la producción desarrollados con PyTorch, TensorFlow o Keras, optimizados para la velocidad, la escalabilidad y la estabilidad.
Contenedores personalizados
Implemente canalizaciones de inferencia totalmente personalizadas con sus propios contenedores Docker para tener un control total sobre el tiempo de ejecución y las dependencias.
TRAPO
Implemente modelos de incrustación, reordenadores y bases de datos vectoriales para crear aplicaciones de IA precisas y sensibles al contexto.
Modelos de visión
Implemente y escale cualquier modelo de visión artificial con facilidad, desde la clasificación de imágenes hasta la comprensión visual avanzada.

Ejecute en cualquier lugar: en la nube, local o perimetral
- Implementaciones basadas en Kubernetes totalmente nativas de la nube
- Implemente en AWS, GCP, Azure, local, o en el borde
Escalado automático sin esfuerzo en CPU/GPU
- Soporta modelos con uso intensivo de CPU y GPU
- Escale a cero o escale automáticamente bajo demanda
.webp)

Acceso seguro y controlado
- Control de acceso detallado basado en roles
- Autenticación basada en tokens y seguridad de API
Inferencia por lotes y streaming
- Ofrezca predicciones en tiempo real a través de REST o gRPC
- Programar o activar la inferencia por lotes
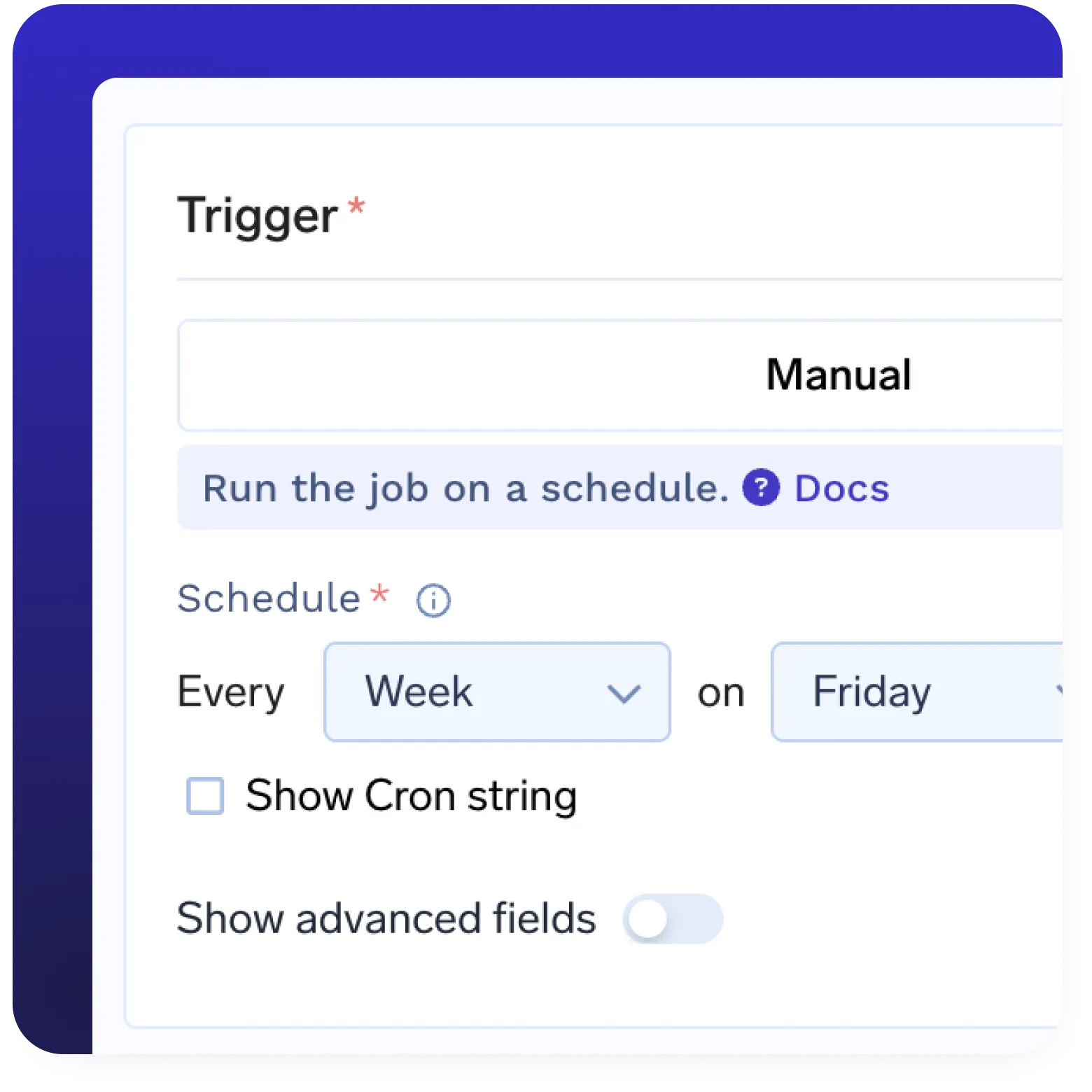

Registro de modelos incorporado
- Registro de modelos completo incorporado
- Despliegue automático de modelos desde el registro
- Administrar versiones y metadatos
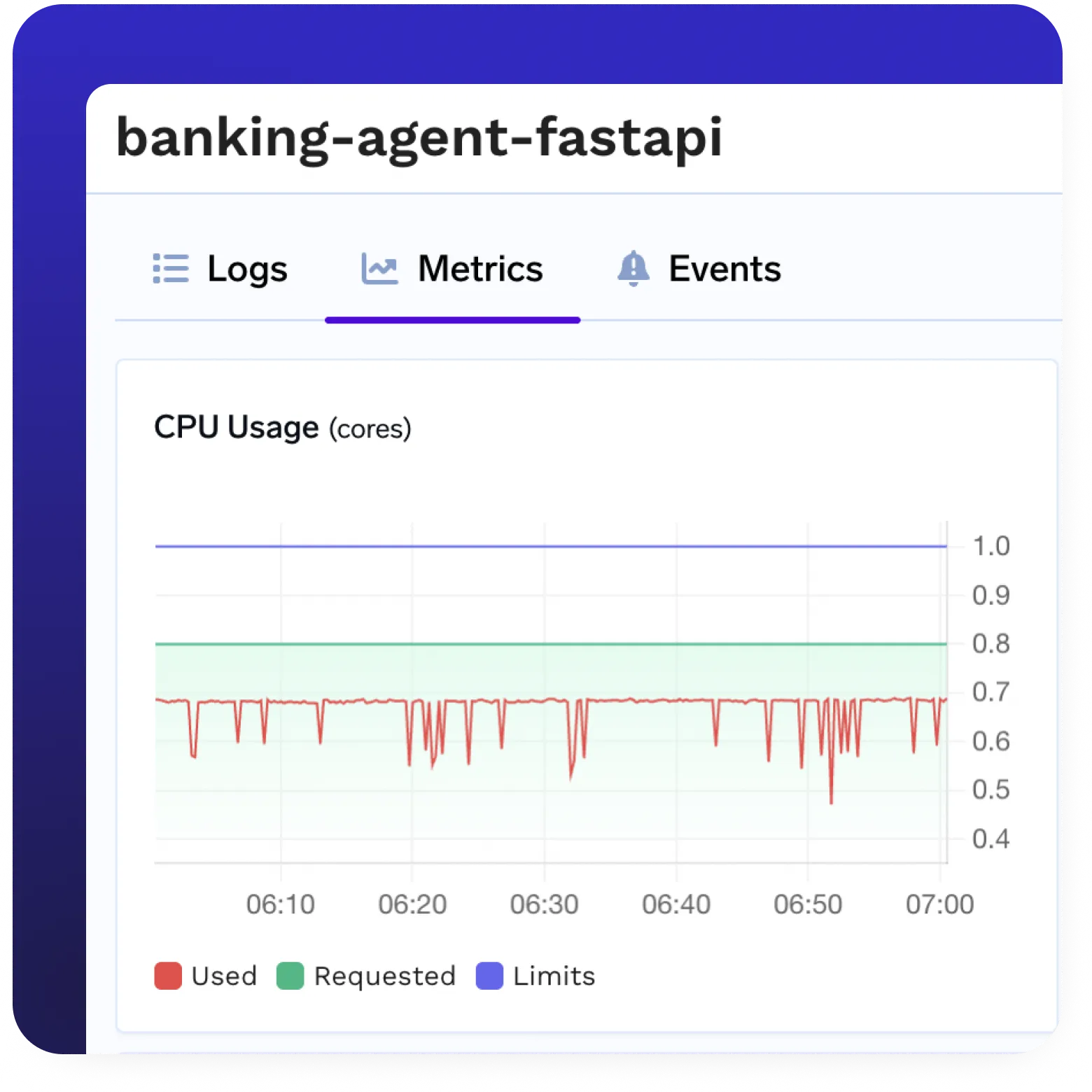
Observabilidad y monitoreo totales
- Soporte nativo para Prometheus, Grafana y OpenTelemetry
- Registros, seguimientos y métricas en tiempo real
- Visibilidad de la implementación, el uso y el estado del sistema

Experiencia de desarrollador encantadora
- Interfaz de usuario, SDK y CLI intuitivos para administrar, probar y monitorear sus modelos.
- Diseño centrado en el desarrollador, desde el desarrollo local hasta la producción.
Rentable
- Optimización inteligente de la infraestructura
- Utilización eficiente de la GPU y compatibilidad con instancias puntuales
- Sin dependencia de un proveedor

Preparado para la empresa
Sus datos y modelos se alojan de forma segura en su infraestructura local o en la nube.

Sistemas totalmente modulares
Se integra con su pila existente y la complementaCumplimiento verdadero
Estándares SOC 2, HIPAA y GDPR para garantizar una protección de datos sólidaSeguro por diseño
Registros de auditoría y control de acceso flexibles basados en rolesAutenticación estándar del sector
Integración de SSO mediante OIDC o SAML

GenAI infra: simple, más rápido y más barato
Con la confianza de más de 30 empresas y empresas de Fortune 500
Testimonios TrueFoundry hace que tu equipo de ML sea 10 veces más rápido
.webp)
Deepanshi S
Científico de datos principal



Mathieu Perrinel
Director de ML


Soma Dhavala
Director de aprendizaje automático


Rajesh Chagantí
CTO


Sumit Rao
Vicepresidente ejecutivo de ciencia de datos


Vivek Suyambu
Ingeniero de software sénior










