August 27, 2025
|
5 min read

Published: June 16, 2026

Blazingly fast way to build, track and deploy your models!
In the first week of June 2026, the AI-coding conversation reorganized itself around one idea. Peter Steinberger — creator of the OpenClaw agent project — posted that the skill is no longer prompting coding agents but designing the loops that prompt them; Boris Cherny, who heads Claude Code at Anthropic, put his own job the same way: "My job is to write loops." Addy Osmani's widely shared essay gave the practice a name — loop engineering — and an anatomy: automations, worktrees, skills, connectors, sub-agents, and external state. The idea is real and worth taking seriously. It's also, as practiced, an individual-developer pattern running on individual laptops — and the gap between a loop in your terminal and a loop an enterprise can run unattended at 3 a.m. is exactly the gap this post is about.
Noor, a staff engineer, built the loop everyone now describes: a morning automation that reads overnight CI failures and open issues, drafts fixes in isolated checkouts, has a second agent review them, opens PRs, and leaves a tidy state file saying what's done and what's next. For three weeks it was the best tool on the team — and then it became the subject of three uncomfortable meetings. Finance asked why one weekend's token bill spiked: the loop had spent two days enthusiastically retrying against a broken test environment with nobody watching. Security asked where the loop's credentials lived: a config file on Noor's laptop, holding her personal tokens, running under her identity at 6 a.m. And her director asked the question with no answer at all: four other engineers had copied the pattern, each differently — so how many loops did the org have, what could each touch, and who approved any of it? The loop worked. The runtime was a laptop, and everything wrong traced back to that.
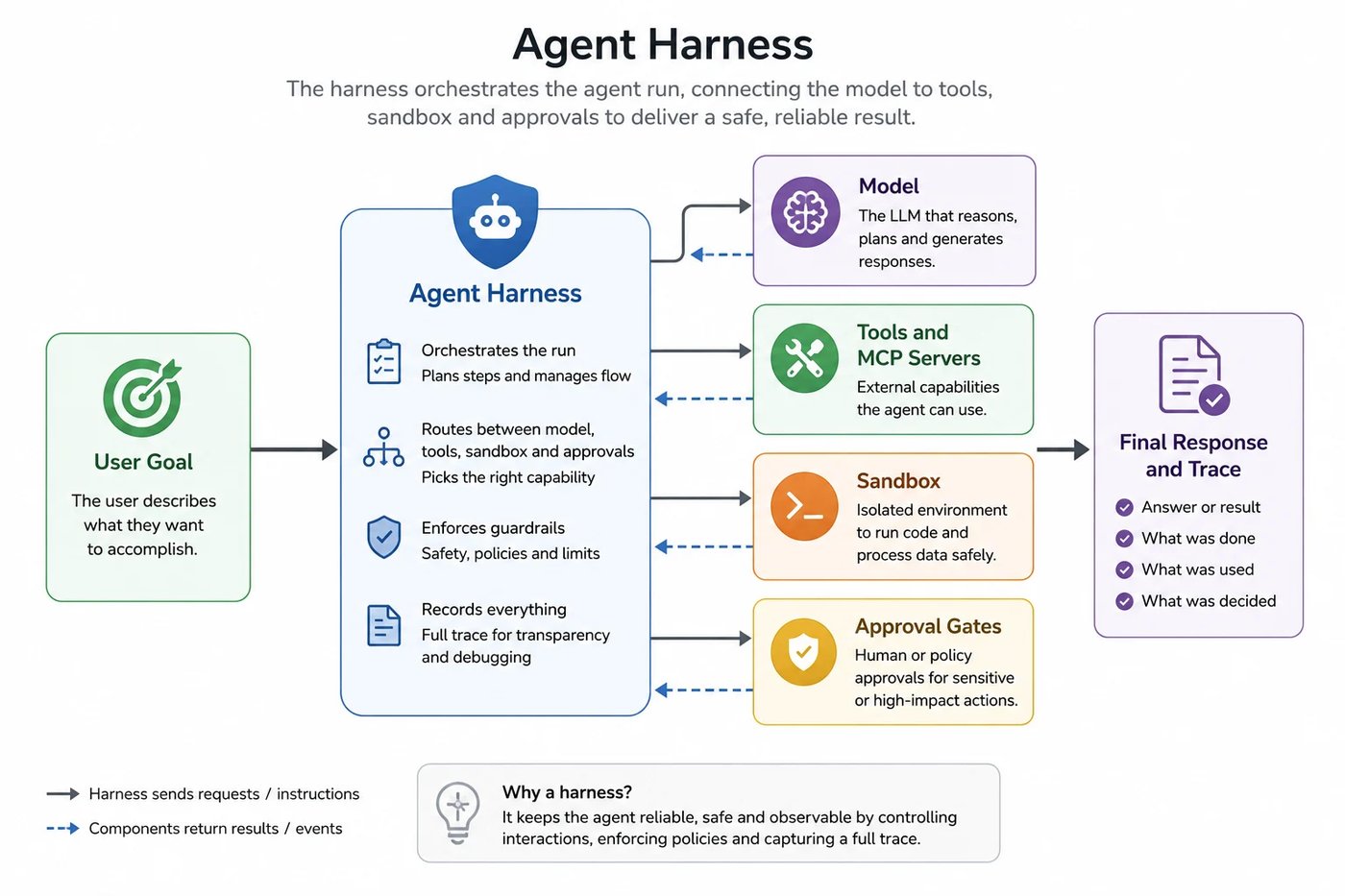
This post takes loop engineering seriously on its own terms — what it is, why it's genuinely the next layer of the discipline, where its sharp edges are — and then does the mapping Noor's director was implicitly asking for: each primitive of the loop, translated from laptop convention to governed infrastructure. The vocabulary follows Osmani's essay and the surrounding discussion; the enterprise half follows TrueFoundry's Agent Harness documentation. The honest summary of the gap is one sentence: loops are a runtime problem wearing a workflow costume.
Strip the discourse and the definition is compact. For two years, working with a coding agent meant holding it: you prompt, you read, you prompt again — the human is the loop. Loop engineering replaces that with a designed system: something finds the work (a schedule scanning CI, issues, error feeds), hands it to an agent, checks the result with a verifier that isn't the maker, records what happened in state that outlives the conversation, and decides what's next. You build it once; it prompts the agents from then on. Osmani places it "one floor above" harness engineering — the harness runs one agent through one task; the loop decides which tasks, when, and what counts as done. Some writers describe it as two nested loops: an inner loop doing work against a spec, an outer loop watching the world and writing the next spec.
If that sounds familiar from this series, it should — the loop is the plan→act→observe pattern promoted one level up, with the same anatomy our harness deep dive took apart: stop conditions (here, "run until the tests pass," judged by a separate model), error handling, and state. Simon Willison was writing about designing agentic loops back in September 2025; what changed in mid-2026, as Osmani notes, is that the primitives stopped being a pile of personal bash and started shipping inside the products — which is exactly the moment a practice stops being a hack and starts being infrastructure. Infrastructure, as we'll see, with infrastructure's requirements.
Osmani's breakdown — which maps near-identically onto both the Codex app and Claude Code, the convergence being his most interesting observation — gives the loop six parts. Automations are the heartbeat: prompts that fire on a schedule, do discovery and triage, and surface findings to an inbox; plus run-until-done primitives where a goal executes until a verifiable condition holds. Isolated workspaces (git worktrees, in the coding case) keep parallel agents from colliding on the same files. Skills — the SKILL.md pattern — codify project knowledge once, so the loop stops re-deriving your conventions every cycle. Connectors, built on MCP, plug the loop into real systems — the difference between an agent that says "here's the fix" and a loop that opens the PR and updates the ticket. Sub-agents split the maker from the checker, because the model that wrote the code grades its own homework too kindly. And external state holds what's done and what's next, because the model forgets everything between runs and the memory has to live outside the context.
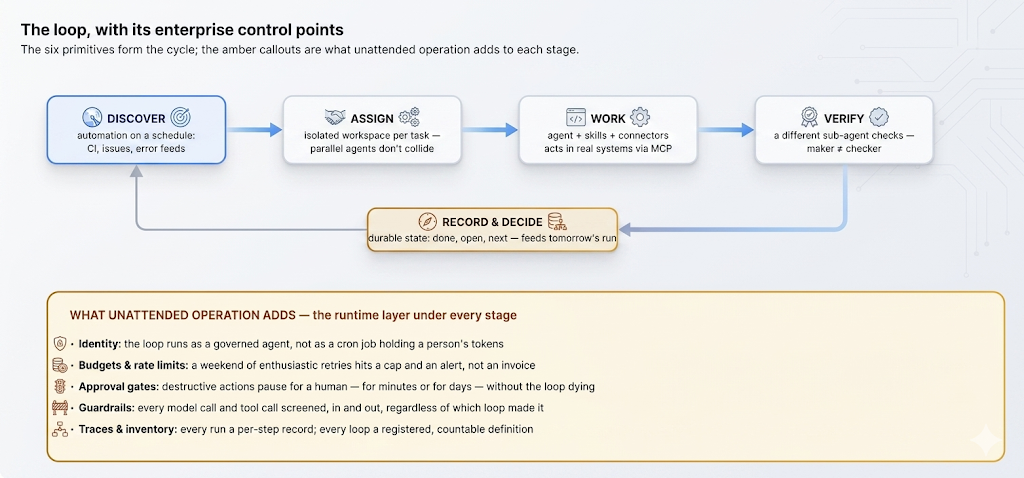
Two things stand out before we translate this list. First, almost none of it is novel machinery — schedules, isolation, packaged knowledge, integrations, delegation, durable state are the oldest ideas in operations, newly arranged around a model. Second, and more importantly: every primitive is a capability grant. An automation is standing permission to act on a schedule; a connector is standing access to a real system; a sub-agent is a delegated identity. On a laptop those grants are invisible. At an organization's scale, they're the whole question.
The discourse is days old and already has a healthy skeptical wing, which deserves airtime before the enterprise translation — translating a bad idea into governed infrastructure just yields governed waste. The practitioners' own conditions for loops paying off, as early commentary converged on them: the task repeats (a loop amortizes design cost across runs; for a one-off, a good prompt is faster); verification is automatable ("all tests pass and lint is clean" is a real stop condition, "looks good" is not); the token budget can absorb the waste (Osmani's own essay leads with the cost warning, and Noor's weekend bill is the canonical incident); and the agent already has the tools the task needs. Miss one and the loop costs more than it returns.
There's also a deeper caution the brute-force-loop enthusiasm tends to skip: failure rates stack. A loop chaining five steps, each 95% reliable, completes cleanly about three-quarters of the time — and an unattended loop's mistakes compound into state, where tomorrow's run builds on them. This is why the maker/checker split is load-bearing rather than decorative, and why Willison's old joke — an agent as "an LLM wrecking its environment in a loop" — is the right thing to keep taped above the automation tab. None of this argues against loops; it argues that a loop is a production system — and the rest of this post treats it as one.
Now run Noor's three meetings as an engineering review. Lifecycle: her loop's runtime was her machine — it dies with the laptop lid, doesn't survive a crash mid-run, and can't pause for a three-day approval, because nothing durable holds the run. One early playbook drew exactly this line: the moment a loop must run at 3 a.m. with no terminal open, survive crashes, and wait indefinitely on a human, you've left tool territory for runtime territory. Credentials: the loop ran as Noor — her tokens, in plaintext config, exercising her permissions on a schedule, indistinguishable in any audit log from Noor herself; a standing automation holding a person's keys is the non-human-identity problem in miniature. Cost: nothing stood between the loop and the provider's meter — no budget, no rate limit, no per-run attribution; the spend was discovered on the invoice. Inventory: five engineers, five divergent copies, zero registry — our coding-agent governance and agent-sprawl story arriving through the side door of productivity tooling.
None of these are flaws in loop engineering; they're properties of the laptop as a runtime, invisible right up until the loop is good enough to matter. The fix isn't banning the pattern — bans produce shadow versions of it — but giving the same six primitives a home built for unattended, multi-tenant, audited operation. That's the mapping the rest of this post does.
Here is the translation, primitive by primitive, with TrueFoundry's Agent Harness as the worked example. Skills translate almost verbatim: the same SKILL.md artifact, but published to the Skills Registry with versions, provenance, and RBAC, and mounted on demand — codified knowledge as a governed catalog instead of a folder on five laptops. Connectors translate to the MCP Gateway: the same MCP servers, reached through a registry with central auth, per-tool RBAC, guardrails, and per-user OAuth delegation — scoped, rotatable credentials instead of whatever tokens were in Noor's config file. Sub-agents translate to harness sub-agents: each checker or explorer with its own isolated context, scoped tool access, and trace — the maker/checker split with an identity boundary, not just a prompt boundary. Isolated workspaces translate to the harness Sandbox: a secure execution environment per run — the worktree idea generalized into "every agent gets its own machine." State becomes durable, platform-held run state that survives crashes and laptop lids. And automations become triggered runs: the same agent definition invoked on schedule or event via REST API or SDK, results landing in traces and notifications rather than a terminal scrollback.
The structural difference the translation buys is the one the laptop can't: no keys anywhere in the loop. Agent definitions reference models, MCP servers, and skills by name; provider credentials live in the AI Gateway, tool auth in the MCP Gateway, configured once by the platform team. Noor's loop, rebuilt this way, runs as itself — a registered agent with its own identity and grants — and "what can this loop touch?" turns into a configuration lookup, not an archaeology project.
Noor's morning loop as a governed agent definition (illustrative)
agent:
name: morning-triage-loop
model: claude-sonnet-4-6 # by name — keys live at the gateway
instructions: ./triage.md@v4 # versioned scaffold
skills: [ci-triage-runbook@v2] # from the Skills Registry, RBAC'd
mcp_servers: [github, ci, linear] # via MCP Gateway: scoped, rotatable auth
subagents:
- { name: fix-drafter, mcp_servers: [github] }
- { name: fix-reviewer, mcp_servers: [] } # checker ≠ maker, read-only
harness:
max_steps: 60
max_tokens_per_run: 1_500_000 # the weekend incident, capped
approvals: { merge_pr: pause_for_human } # waits days if it must
trigger: { schedule: "0 6 * * 1-5" } # the heartbeat — no laptop requiredThe defining property of a loop is that nobody is watching, so the runtime's job is to make "nobody is watching" safe. Three mechanisms carry that load. Human-in-the-loop gates: the harness pauses a sensitive tool call — merging a PR, mutating a production system — and holds the run's state durably until someone approves; the loop doesn't die because a human took the weekend. Critically, destructive tools are flagged once at the MCP Gateway, org-wide — the policy applies to every loop automatically, instead of depending on each of five engineers remembering to configure it. Guardrails: every model call and tool call passes the gateway's pre- and post-call checks — PII, content policies, custom rules — so a loop processing real tickets at 6 a.m. is screened exactly like an interactive session at 2 p.m. Stop conditions: run-until-done is only as safe as its bounds, so step ceilings, token budgets, and stall detection are harness configuration, not hope — the difference between "the loop converged" and "the loop stopped when its budget said so," with the trace telling you which.
This is also where the maker/checker idea completes itself. Osmani's verifier sub-agent checks the work; the runtime's gates check the actions. A loop can have an excellent reviewer agent and still need a human between it and an irreversible merge — and the harness is where that judgment becomes enforcement.
Osmani's essay opens with the caveat the invoices later confirm: token costs vary wildly, and an unattended loop has no human in the cost loop either. TrueFoundry's cost-management stack turns that from a finance surprise into an operations parameter, in three layers. First, hard bounds per principal: budgets, quotas, and rate limits apply to the loop as its own agent identity — declared as GitOps YAML at the gateway, enforceable per agent, team, user, or model — so Noor's weekend incident, replayed against a per-agent budget, becomes a capped run and a Saturday-night alert instead of a Monday invoice. Second, per-run attribution: the harness traces every run with tokens and cost per model call, tool call, and sandbox execution — the checker's cost visible separately from the maker's, so section 3's repeats-versus-one-off judgment is made with numbers rather than vibes. Third, the rollup: the gateway's cost analytics aggregate that spend per loop, per team, per model over time — which is where "are loops paying for themselves?" stops being a debate and becomes a dashboard.
The trace earns its keep beyond cost. A loop that ran unattended and produced a strange PR is a forensic question, and a complete per-step record.
Osmani closes his essay on a warning the enterprise translation must keep intact: the loop changes the work, it doesn't delete you from it. Verification remains yours — a checker sub-agent makes the loop's "done" mean something, but done is a claim, not a proof. Comprehension debt grows faster as the loop improves — the gap between what exists and what you understand compounds with every unread PR. And the comfortable posture is the dangerous one: the same loop is leverage for the engineer who uses it on work they understand and an accelerant of decline for the one using it to avoid understanding. A governed runtime doesn't change that ledger; it changes what the organization can see of it — review rates, approval patterns, per-loop outcomes — which is the precondition for managing it, not a substitute for judgment.
What the runtime does change is who can afford the pattern. Today's loop engineering selects for engineers willing to maintain personal automation rigs; on a managed harness it's a definition anyone can author — no-code builder or SDK, same artifact — with the dangerous parts handled by construction. Noor's fifth meeting, in this version, is short: eleven registered loops, what each touches, last week's cost and outcome per loop, and the new one ships Tuesday inside the same rails. Not loops with a compliance tax — loops with the runtime they were always implicitly assuming.
Do we need an enterprise runtime for one engineer's morning loop? For one loop, on low-stakes targets, with its author watching the bill — probably not, and pretending otherwise would be vendor theater. The runtime case arrives with multiplication and stakes: several loops, shared systems, real credentials, unattended hours. Noor's story is the typical trajectory — the pattern spreads because it works, and the governance gap widens exactly as fast.
Can a loop pause for a human approval without dying? On a laptop, effectively no — the run's state lives in a process that won't survive until Monday. On the harness, yes: human-in-the-loop gates hold the run durably until someone decides, which makes "the loop opens the PR but a human merges it" an architecture rather than an aspiration.
How do we stop loop sprawl without banning loops? Make the governed path the easiest path: a registry answers "how many and what can they touch," central credentials remove the reason to paste tokens into config files, and a builder that ships a traced, budgeted loop in an afternoon out-competes the personal bash pile on convenience. Prohibition produces shadow loops; a better default produces registered ones.
Does the maker/checker split really help, or just double the cost? It costs real tokens and earns them selectively: spend the second opinion where being wrong is expensive. Give the checker different instructions (ideally a different model) and keep it read-only — a checker that can edit is just a second maker. The per-step trace tells you, per loop, whether it catches enough to pay its way.
The loop-engineering moment is real: the leverage point has moved from the prompt to the system that prompts. But a loop is a production system the instant it runs without you — with a production system's needs: identity, bounds, gates, traces, and a runtime that doesn't close when the laptop does. Design the loop, as Osmani says, like someone who intends to stay the engineer. Run it, we'd add, on something built to be run on.
Northwind and Noor are an illustrative composite, not a specific organization or incident. The loop-engineering framing follows Addy Osmani's June 2026 essay and surrounding community discussion (Steinberger, Cherny, and early analyses), paraphrased with credit; quoted phrases are under fifteen words and attributed. Tool capabilities of the Codex app and Claude Code are described per that public discussion at the time of writing and evolve quickly. Configuration snippets are simplified for readability and not literal product schema; the reliability arithmetic in section 3 is illustrative. TrueFoundry capabilities reflect public documentation at the time of writing; verify against current docs.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox

.webp)