











Ajusta cualquier modelo
Afina los modelos LLM y ML clásicos con integraciones de Hugging Face y plantillas listas para la producción
Ajuste fino sin código o con código completo
Empieza rápido con una interfaz de usuario sin código o trae tus propios scripts de entrenamiento para tener un control y una flexibilidad totales.
PEFT y ajuste completo
Soporta LoRa, QLoRa y un ajuste completo para equilibrar el costo, el uso de la memoria y el rendimiento del modelo.
Puntos de control y control de versiones
Controle automáticamente las ejecuciones, reanude el entrenamiento y versione modelos y conjuntos de datos para garantizar la reproducibilidad.
Seguimiento de experimentos incorporado
Realice un seguimiento de los hiperparámetros, las métricas, los conjuntos de datos y los resultados en las ejecuciones de ajuste fino.
Administración de adaptadores
Entrene, reutilice, combine y cambie los adaptadores LoRa para acelerar el ajuste y reducir los costos.
.webp)
Afina cualquier modelo de cara que se abrace/modelo ML clásico
- Soporta LLM de ajuste fino como LLama, Mistral, BERT, Falcon y GPT-J
- Empieza a afinar los LLM en cuestión de minutos con el hub de modelos Hugging Face integrado
- Las plantillas preconfiguradas simplifican el proceso de ajuste de modelos lingüísticos de gran tamaño
- La infraestructura escalable se encarga de todo, desde pequeños experimentos hasta el ajuste fino de la LLM a nivel de producción
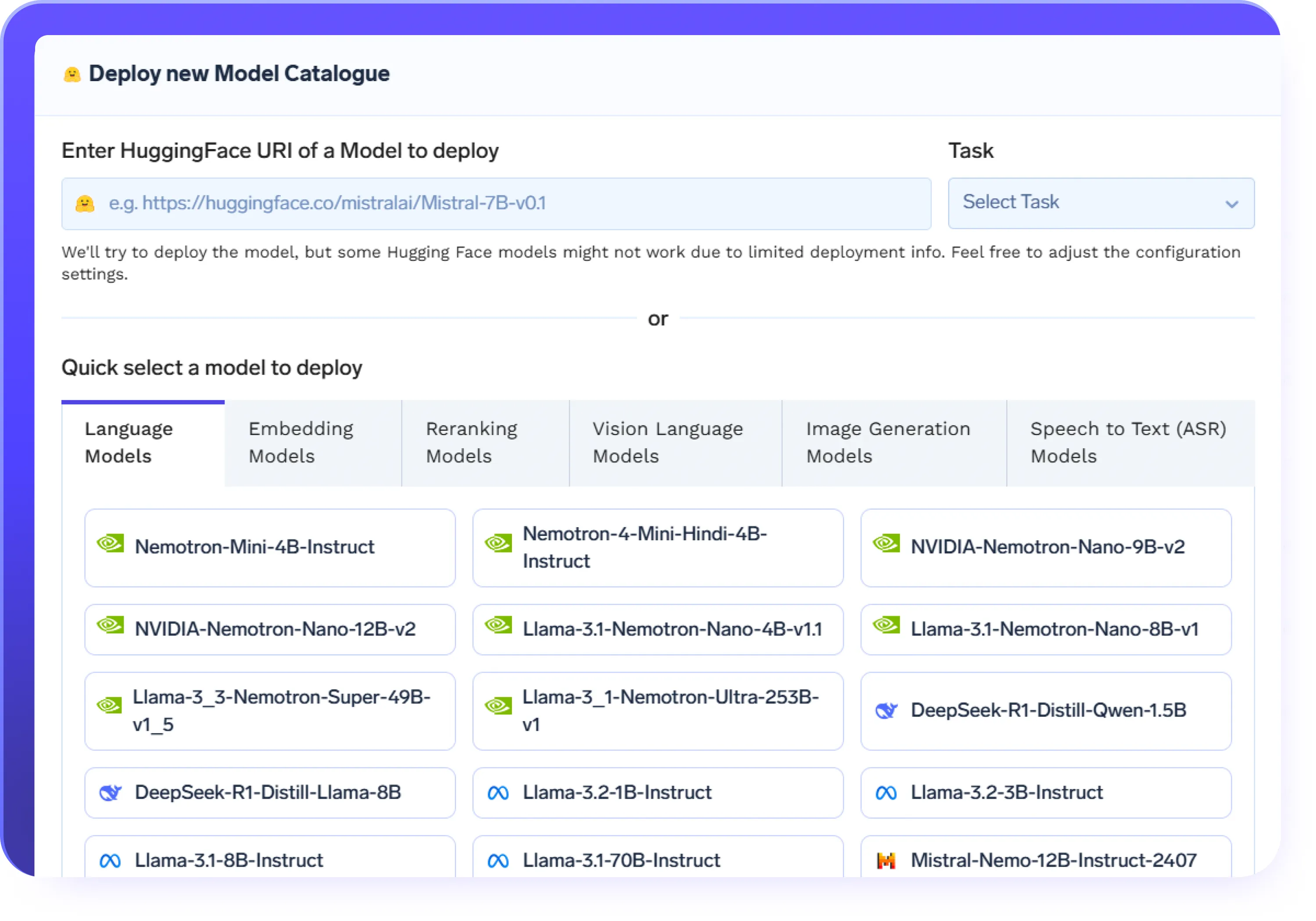
Sin código o con código completo: su elección
- Optimice los LLM mediante una interfaz de usuario sin código para una configuración e iteración rápidas
- Traiga sus propios guiones de entrenamiento con control total en modo código
- Gestione automáticamente el escalamiento de la infraestructura y los recursos
- Obtenga total transparencia en cada ejecución de ajuste, con registros, métricas y control de versiones integrados.
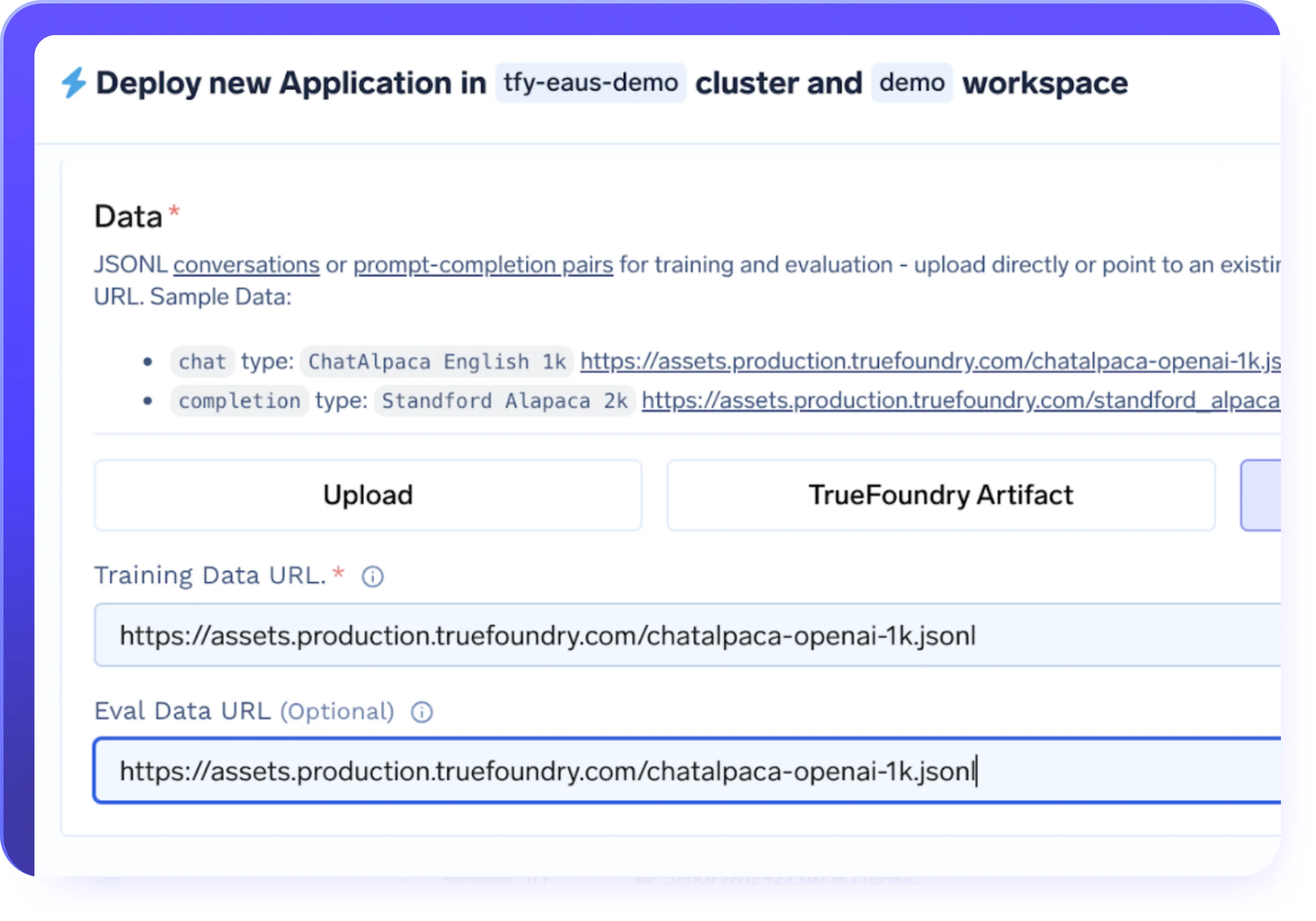
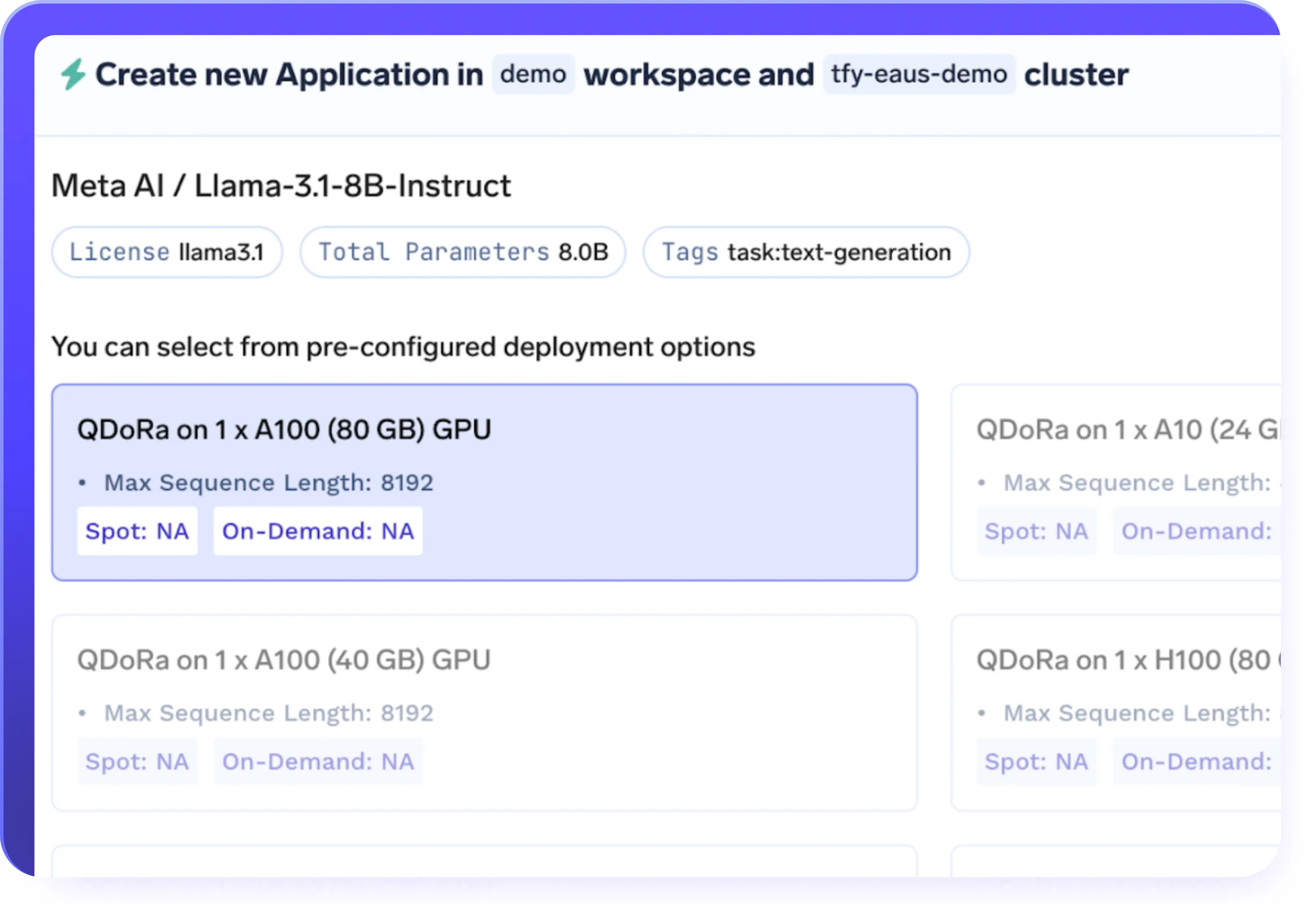
PEFT (LoRa/QLoRa) y soporte completo de ajuste
- Admite el ajuste fino con eficiencia de parámetros (LoRa, QLoRa), así como el ajuste fino del modelo completo
- Elija LoRa o QLoRa para un ajuste más rápido y rentable de grandes LLM
- Reduzca el uso de memoria de la GPU sin perder la calidad y el rendimiento del modelo
- Seleccione el enfoque de ajuste adecuado en función del tamaño del modelo, el costo y las necesidades de carga de trabajo
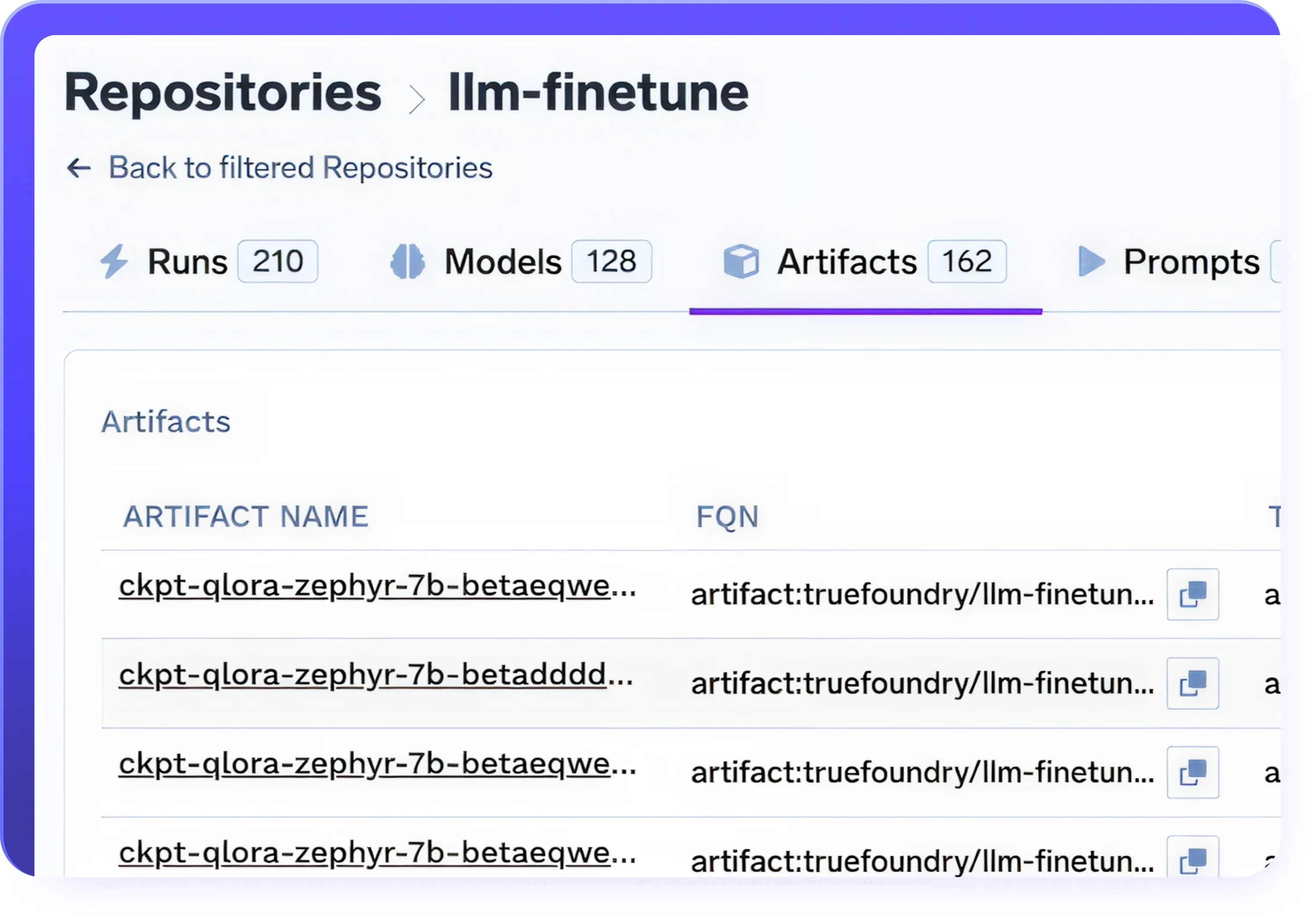
Puntos de control y control de versiones
- Guarda los puntos de control automáticamente durante el ajuste para evitar la pérdida del progreso del entrenamiento
- Reanude los trabajos de ajuste interrumpidos o pausados desde cualquier punto de control
- Modelos de versiones, conjuntos de datos y ejecuciones de entrenamiento para una reproducibilidad total
- Vuelva a los puntos de control anteriores y compare el rendimiento entre las versiones
Seguimiento de experimentos incorporado
- Registra automáticamente todos los metadatos del entrenamiento: hiperparámetros, métricas, conjuntos de datos y resultados
- Compare varias ejecuciones para ajustar los LLM de manera más eficaz
- Intégralo con tu pila de LLMOps o usa nuestra interfaz visual nativa
- El control de versiones incorporado garantiza la reproducibilidad y la auditabilidad
Administración de adaptadores para un ajuste eficiente de la LLM
- Aproveche los adaptadores LoRa para ajustar los modelos actualizando solo un pequeño conjunto de parámetros.
- Reutilice adaptadores previamente entrenados en proyectos y dominios
- Combine o cambie adaptadores para diferentes tareas, lo que permite una rápida experimentación y un diseño de modelos modulares
- Acelere la formación y reduzca los costes mediante la formación de módulos adaptadores compactos en lugar de utilizar pesas LLM completas
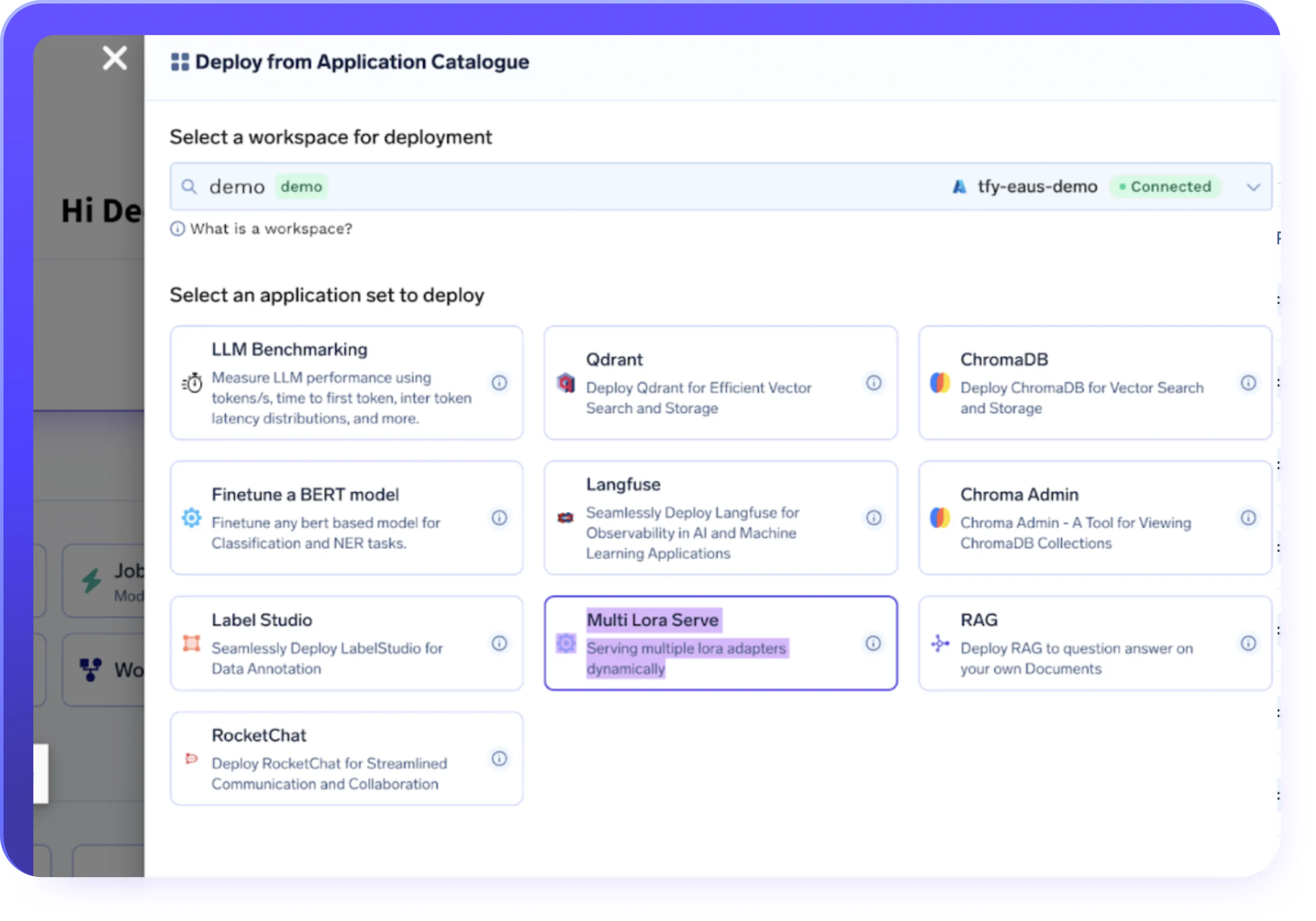
Integraciones de datos e infraestructuras
- Importe conjuntos de datos de S3, GCS, Azure Blob o Hugging Face
- Ejecute trabajos de ajuste en una infraestructura totalmente gestionada o en sus propios clústeres
- Implemente cargas de trabajo en entornos cloud, híbridos o locales
- Usa el escalado automático, la segmentación temporal y el aprovisionamiento rentable de la GPU de forma predeterminada
Hecho para la IA del mundo real a escala
Preparado para la empresa
Implemente una pasarela de IA segura que mantenga sus datos y modelos dentro de su infraestructura en la nube o local.


Cumplimiento y seguridad
Estándares SOC 2, HIPAA y GDPR para garantizar una protección de datos sólidaGobernanza y control de acceso
Control de acceso basado en roles SSO + (RBAC) y registro de auditoríaSoporte y confiabilidad empresariales
Soporte ininterrumpido con respaldo de SLA SLA de respuesta
VPC, local, aislada o en varias nubes.
Ningún dato sale de tu dominio. Disfrute de total soberanía, aislamiento y cumplimiento de nivel empresarial dondequiera que se ejecute TrueFoundry


Resultados reales en TrueFoundry
Por qué las empresas eligen TrueFoundry






3 veces
tiempo de obtención de valor más rápido con agentes de LLM autónomos
80%
mayor utilización de los clústeres de GPU tras la optimización automatizada de los agentes

Aarón Erickson
Fundador de Applied AI Lab
TrueFoundry convirtió nuestra flota de GPU en un motor autónomo y con optimización automática, lo que aumentó un 80% la utilización y nos ahorró millones en cómputos inactivos.
5x
menor tiempo de producción de la plataforma interna de AI/ML
50%
menor gasto en la nube después de migrar las cargas de trabajo a TrueFoundry

Pratik Agrawal
Director sénior de Ciencia de Datos e Innovación en Inteligencia Artificial
TrueFoundry nos ayudó a pasar de la experimentación a la producción en un tiempo récord. Lo que hubiera llevado más de un año se hizo en meses, con una mejor adopción por parte de los desarrolladores.
80%
reducción del tiempo de producción de los modelos
35%
ahorro de costes en la nube en comparación con la configuración anterior de SageMaker
.webp)
Vibhas Geji
Ingeniero de ML en plantilla
Redujimos la carga de DevOps y simplificamos las implementaciones de producción en todos los equipos. TrueFoundry aceleró la entrega de aprendizaje automático con una infraestructura que va desde experimentos hasta servicios sólidos.
50%
despliegue más rápido de la pila de RAG/Agent
60%
reducción de los gastos de mantenimiento de las tuberías de RAG/Agent
.webp)
Indroneel G.
Líder de procesos inteligentes
TrueFoundry nos ayudó a implementar una pila RAG completa, que incluía canalizaciones, bases de datos vectoriales, API e interfaz de usuario, el doble de rápido y con un control total sobre la infraestructura autohospedada.
60%
despliegues de IA más rápidos
~ 40-50%
Reducción efectiva de costos en todos los entornos de desarrollo
.webp)
Nilav Ghosh
Director sénior de IA
Con TrueFoundry, redujimos los plazos de implementación en más de la mitad y redujimos la sobrecarga de infraestructura a través de una interfaz MLOps unificada, lo que aceleró la entrega de valor.
<2
semanas para migrar todos los modelos de producción
75%
reducción del tiempo de coordinación de la ciencia de datos, acelerando las actualizaciones de los modelos y el despliegue de funciones
.webp)
Rajat Bansal
CTO
Hemos ahorrado mucho en costes de infraestructura y hemos reducido el tiempo de coordinación de DS en un 75%. TrueFoundry aumentó la velocidad de implementación de nuestros modelos en todos los equipos.
Preguntas frecuentes
¿Qué es el perfeccionamiento del LLM y por qué es importante?
¿Cómo simplifica TrueFoundry el ajuste fino del LLM?
- Flujos de trabajo sin código y con código completo: utilice una interfaz de usuario intuitiva o scripts de entrenamiento personalizados
- Seguimiento de experimentos incorporado: registro automático de hiperparámetros, métricas y versiones de modelos
- Orquestación de la infraestructura: ejecute trabajos en infraestructura gestionada por TrueFoundry o en su propia nube/VPC
- Soporte para métodos PEFT: soporte nativo para ajustes precisos basados en LoRa y QLora
- Control de puntos y control de versiones: reanude la formación sin problemas y mantenga la reproducibilidad
- Administración de adaptadores: reutilice, combine o implemente adaptadores en múltiples tareas/modelos
¿Qué tipos de modelos puedo ajustar con precisión en TrueFoundry?
- LLM basados en decodificadores (por ejemplo, LLama, GPT-J, Falcon, Mistral)
- Modelos de codificadores (por ejemplo, BERT, RobErta, DisTilbert)
- Modelos de codificador-decodificador (p. ej., T5, FLAN-T5)
¿Puedo traer mi propio conjunto de datos y código de entrenamiento?
- Traiga sus propios conjuntos de datos de S3, GCS, Azure, Hugging Face Hub o archivos locales
- Traiga su propio código a través de scripts de entrenamiento personalizados (PyTorch, Transformers, PEFT, etc.)
- O usa plantillas prediseñadas para ajustar los flujos de trabajo más comunes
¿Cómo admite TrueFoundry el ajuste fino de LoRa y QLoRa?
- Usa nuestra interfaz de usuario para configurar capas e hiperparámetros de LoRa
- Guarde e implemente adaptadores LoRa independientemente de los modelos básicos
- Combine los adaptadores con los modelos básicos para la implementación o la inferencia fuera de línea
- Reduzca drásticamente el uso de la memoria de la GPU, ideal para las empresas que optimizan el gasto en infraestructura
¿Puedo implementar modelos ajustados de TrueFoundry en la producción?
- Implemente modelos con VLLM, SGLang u otros servidores de inferencia
- Exponga su modelo como una API con limitación de velocidad y RBAC integrados
- Supervise la latencia, el uso de los tokens y el rendimiento en tiempo real
- Use adaptadores para una implementación rápida o combínelos con el modelo base para una inferencia independiente

GenAI infra: simple, más rápido y más barato
Con la confianza de más de 30 empresas y empresas de Fortune 500








