












Plataforma de implementación por agencia y pasarela de IA lista para la empresa: segura, escalable y gobernada.
Nube local, de VPC, híbrida o pública


Controle, implemente, escale y rastree la IA de las agencias en una plataforma unificada
.svg)
.avif)
Organice la IA de la agencia con AI Gateway
Permita el razonamiento inteligente en varios pasos, el uso de herramientas y la memoria con un control y una visibilidad totales de sus agentes y flujos de trabajo de IA.
Puerta de enlace de IA
Gestione la memoria de los agentes, la orquestación de herramientas y la planificación de acciones mediante un protocolo centralizado que admite flujos de trabajo complejos y sensibles al contexto.

Registro de MCP y agentes
Mantenga un registro estructurado y reconocible de herramientas y API accesibles para los agentes, con validación de esquemas y control de acceso.
.webp)
Gestión rápida del ciclo de vida
Cree versiones, administre y supervise las instrucciones para garantizar un comportamiento repetible y de alta calidad en todos los agentes y casos de uso.
.avif)
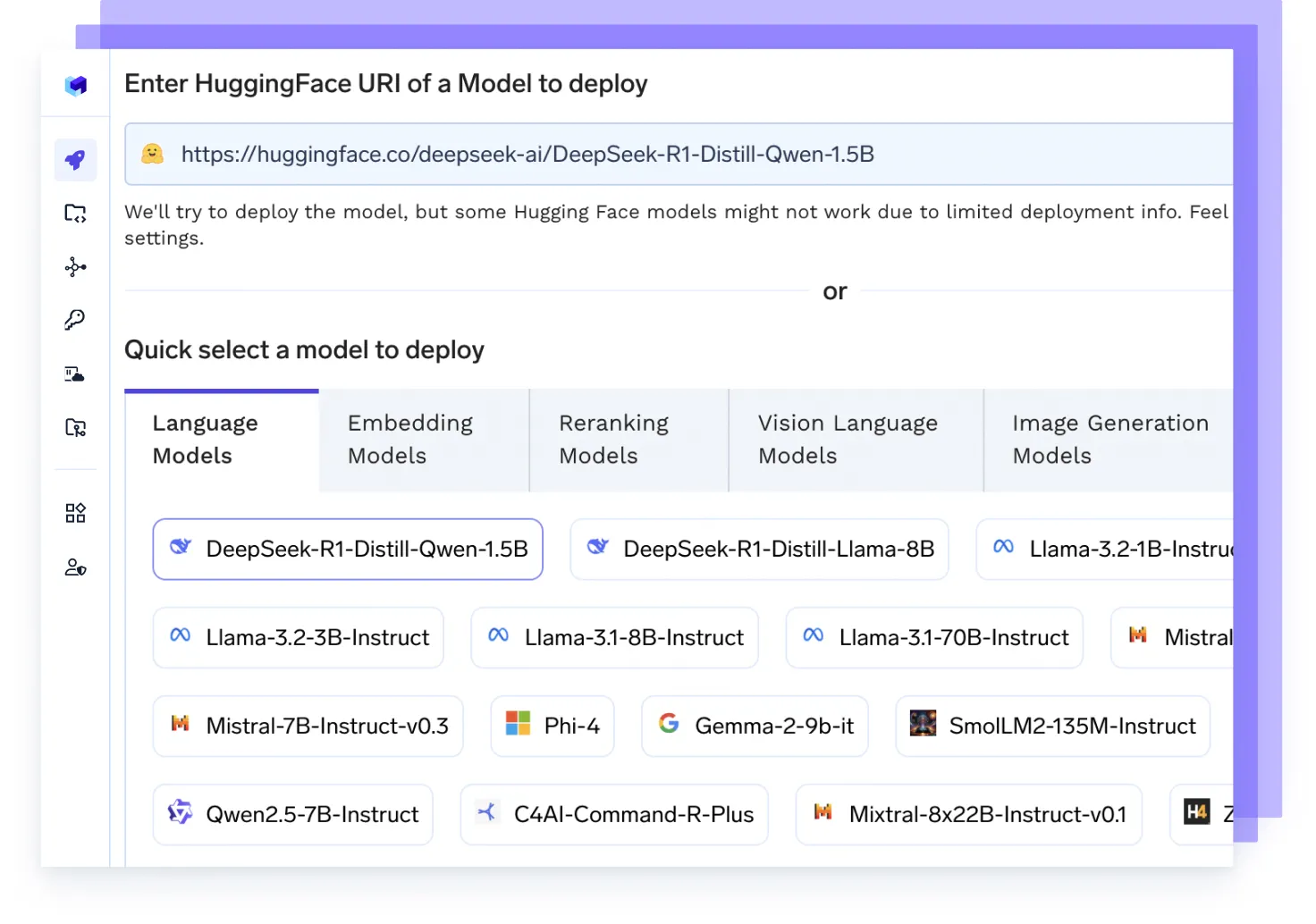
Implemente y escale cualquier carga de trabajo de IA para agencias
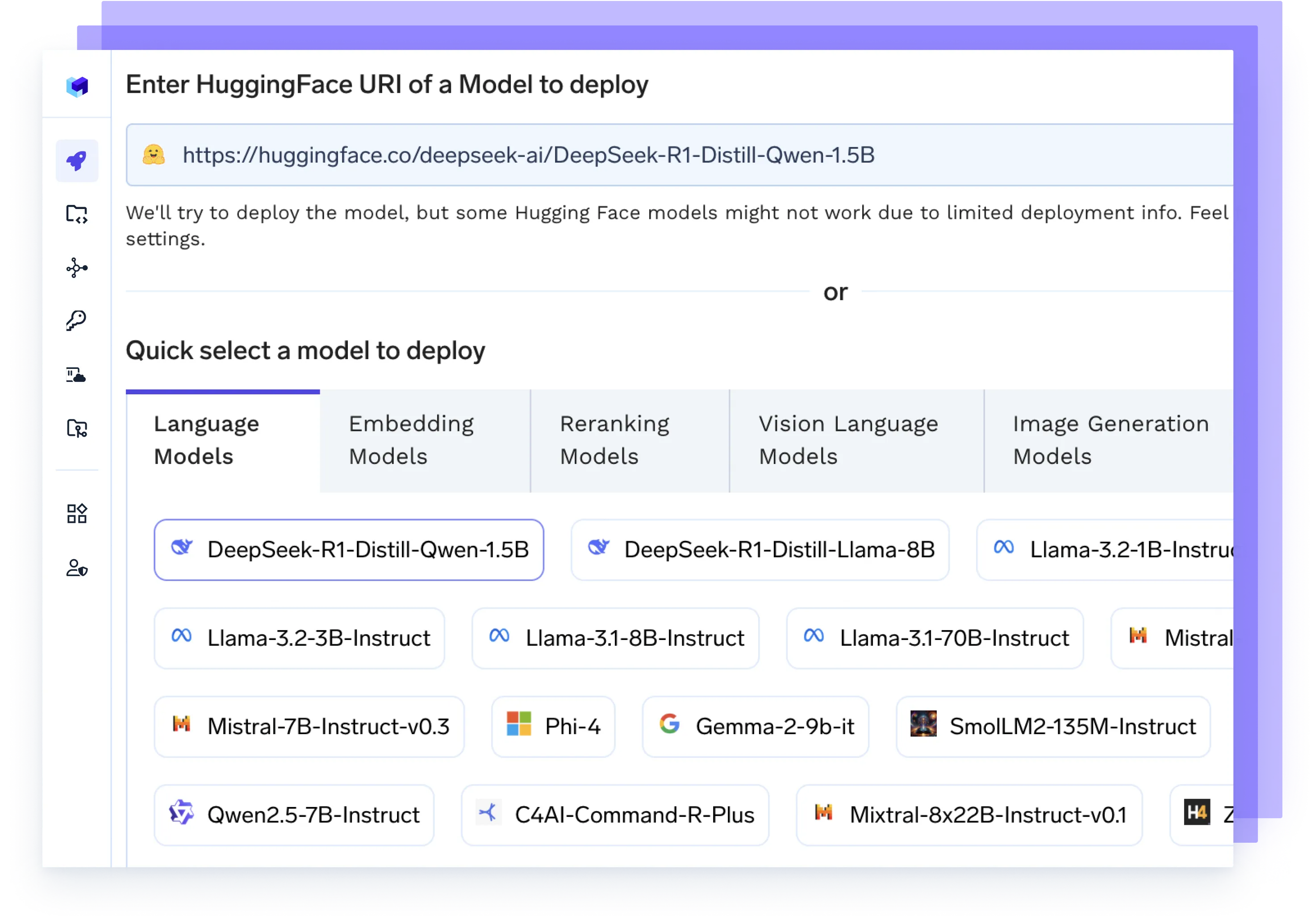
Aloja cualquier modelo de IA
Ejecute cualquier LLM, modelo de incrustación o modelo personalizado con backends de alto rendimiento como vLLM, TGI o Triton, optimizados para la velocidad y la escala.
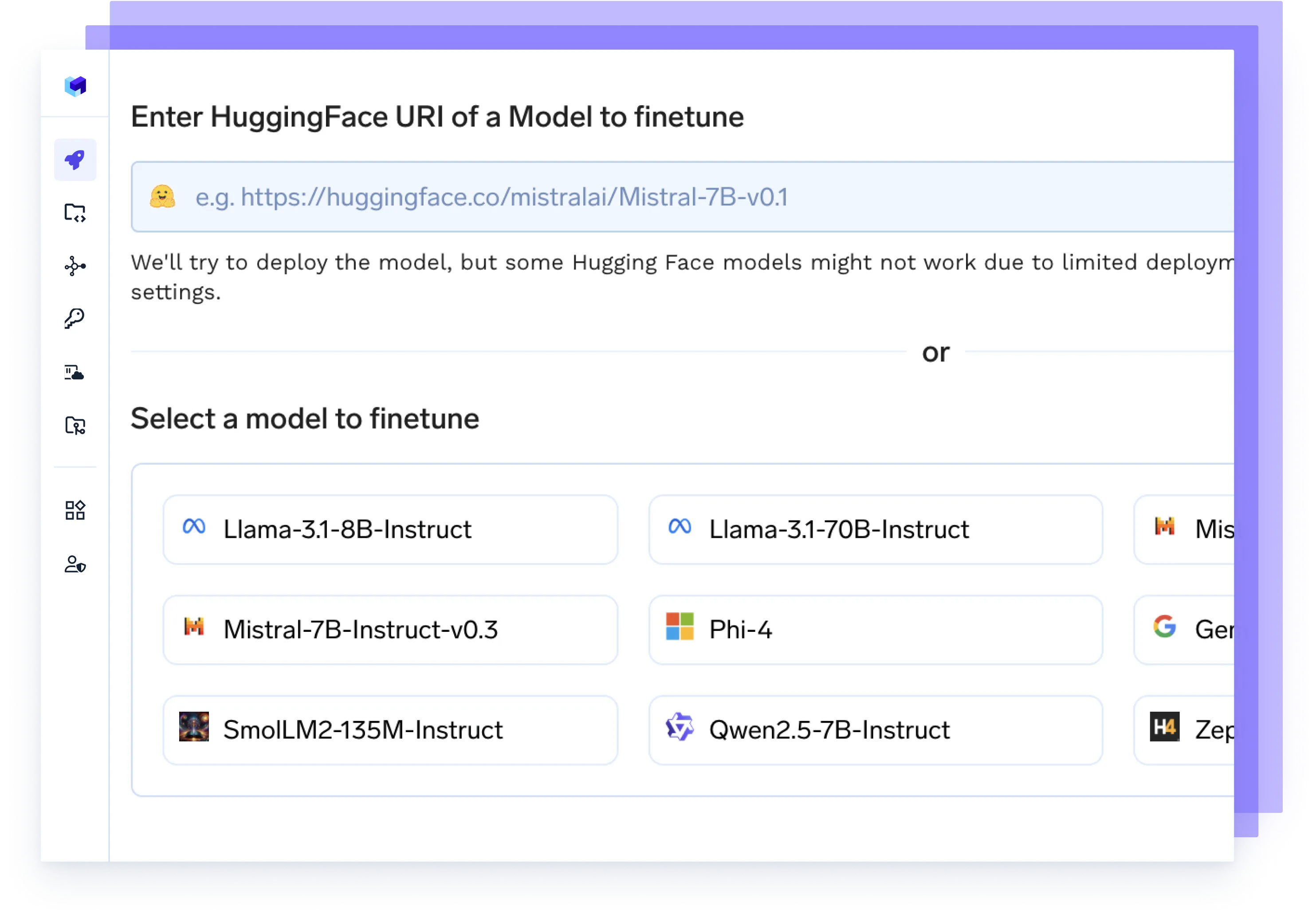
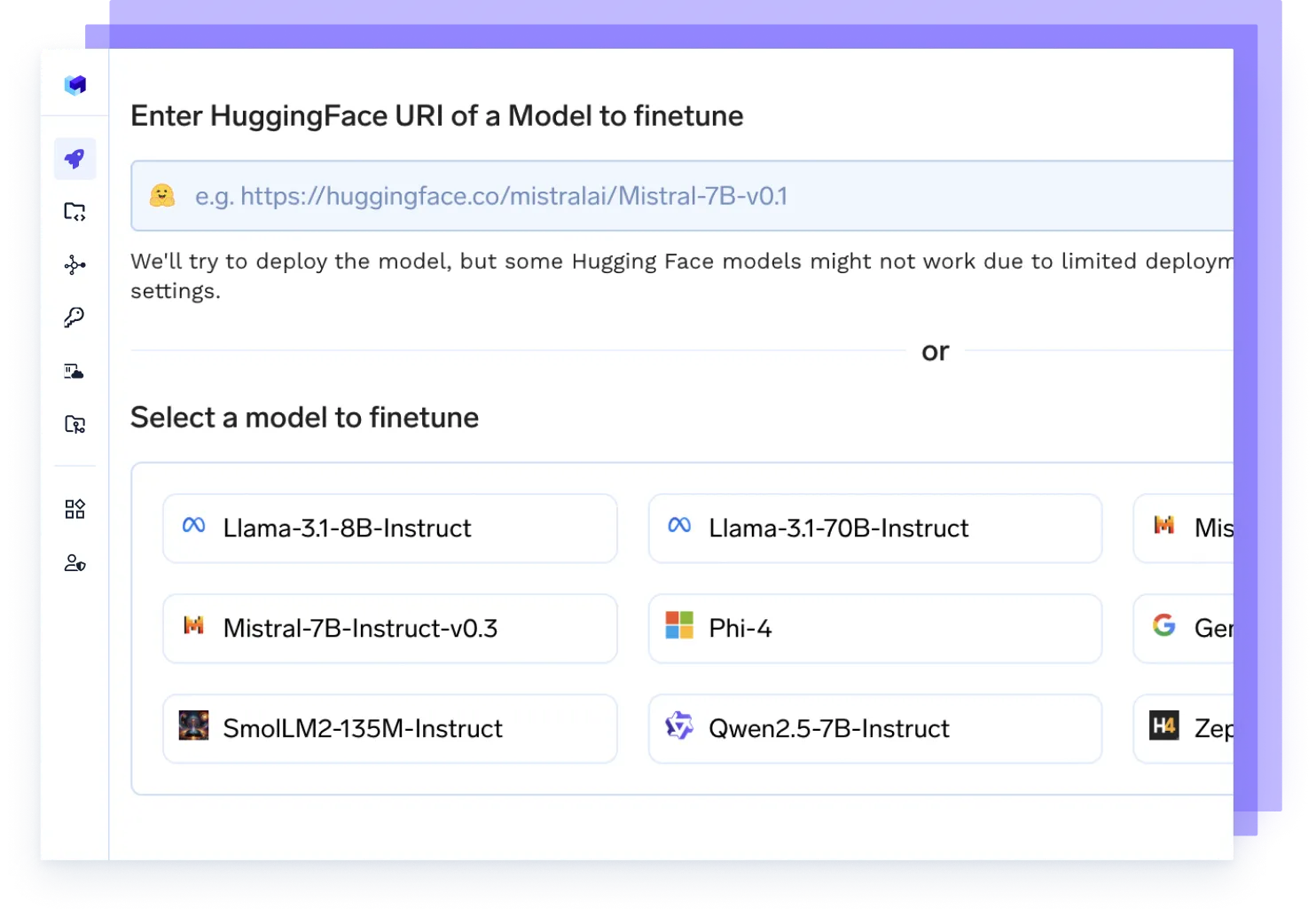
Afina cualquier modelo
Lance trabajos de ajuste de sus datos, realice un seguimiento de los experimentos e implemente puntos de control actualizados directamente en la producción, todo en un solo flujo.
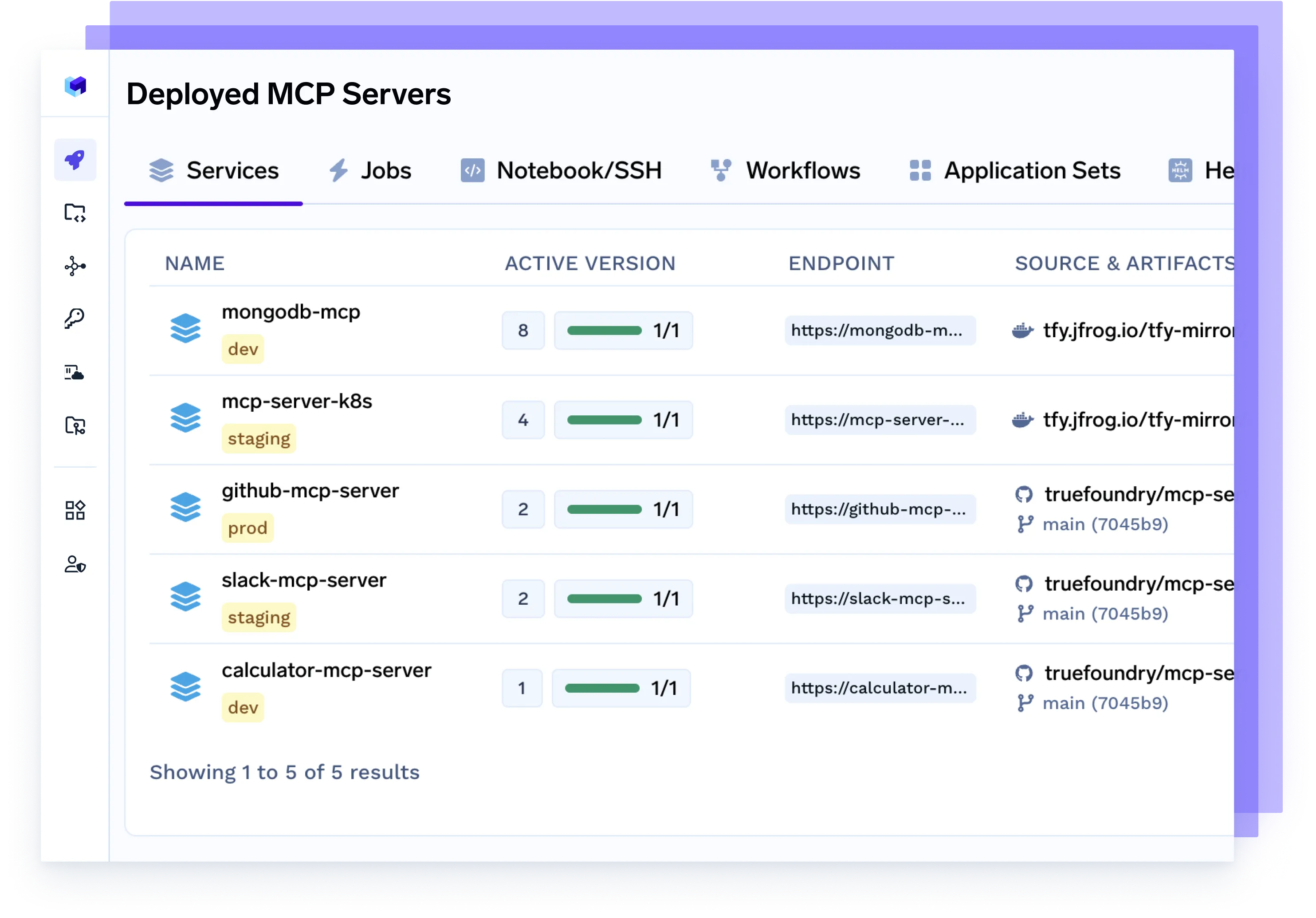
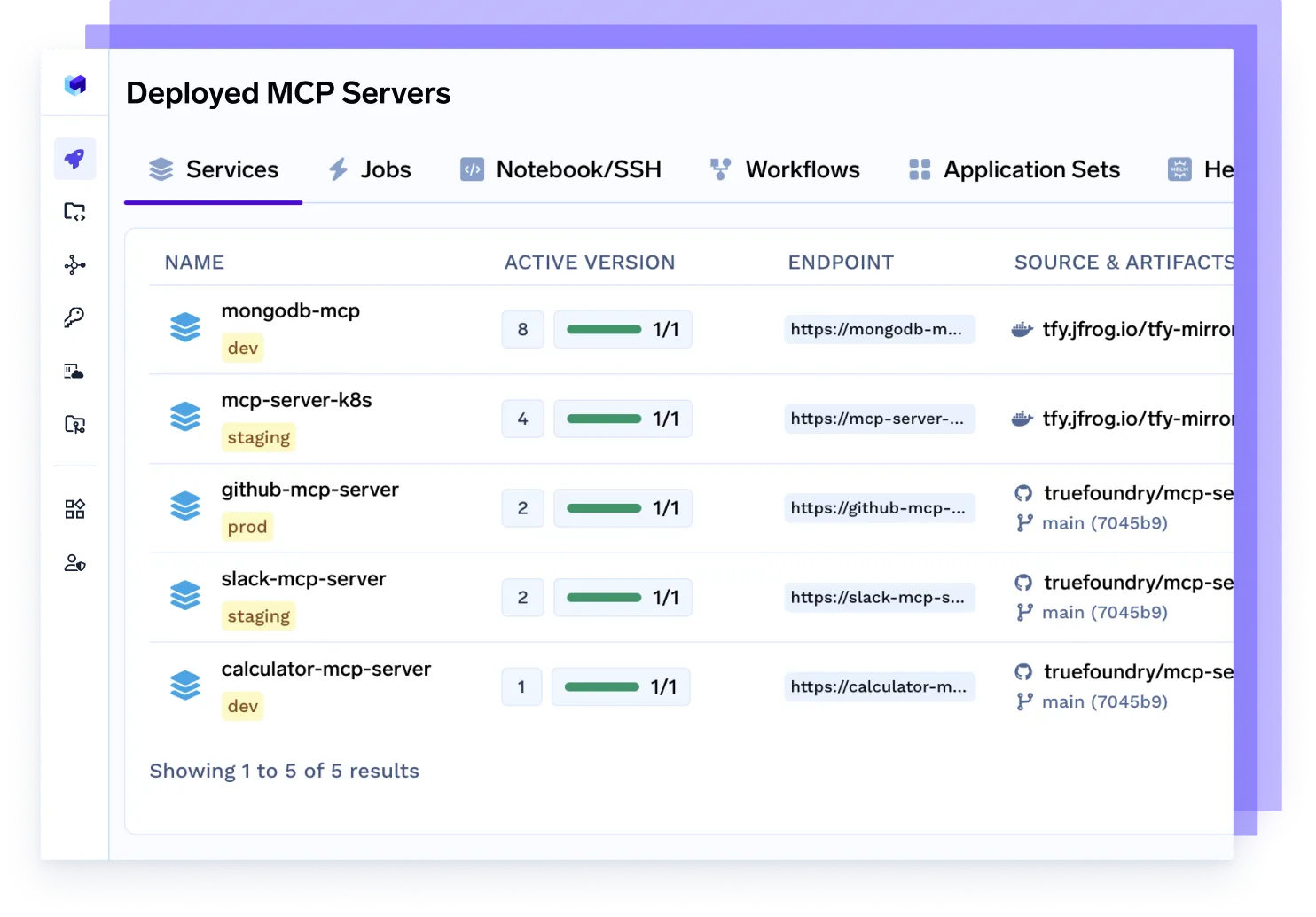
Implemente el servidor MCP
Aprovisione servidores de protocolo de control de modelos (MCP) dedicados para administrar el tráfico de agentes, escalar el acceso a los modelos, aplicar los límites de velocidad y aislar las cargas de trabajo por equipo o proyecto.
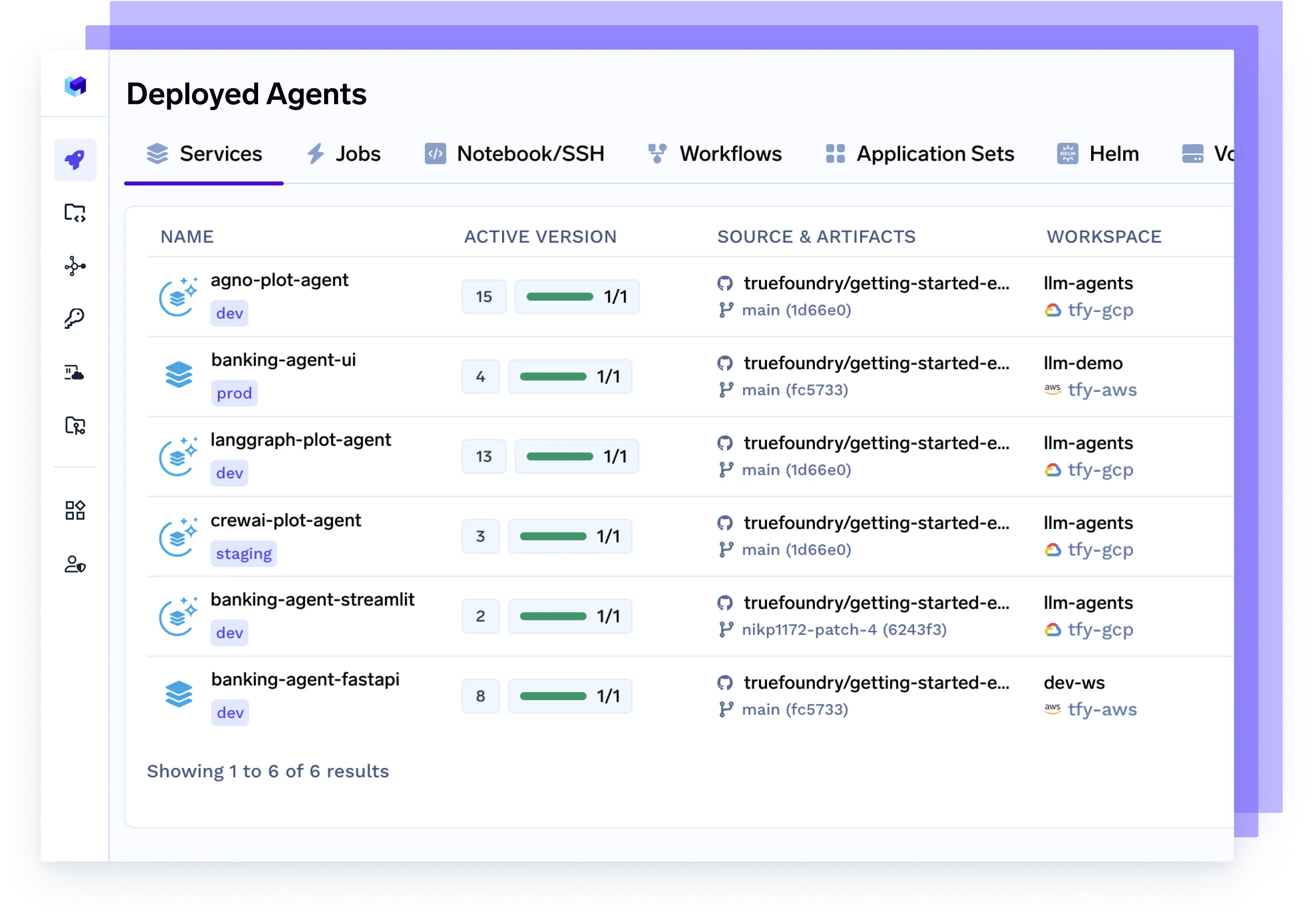
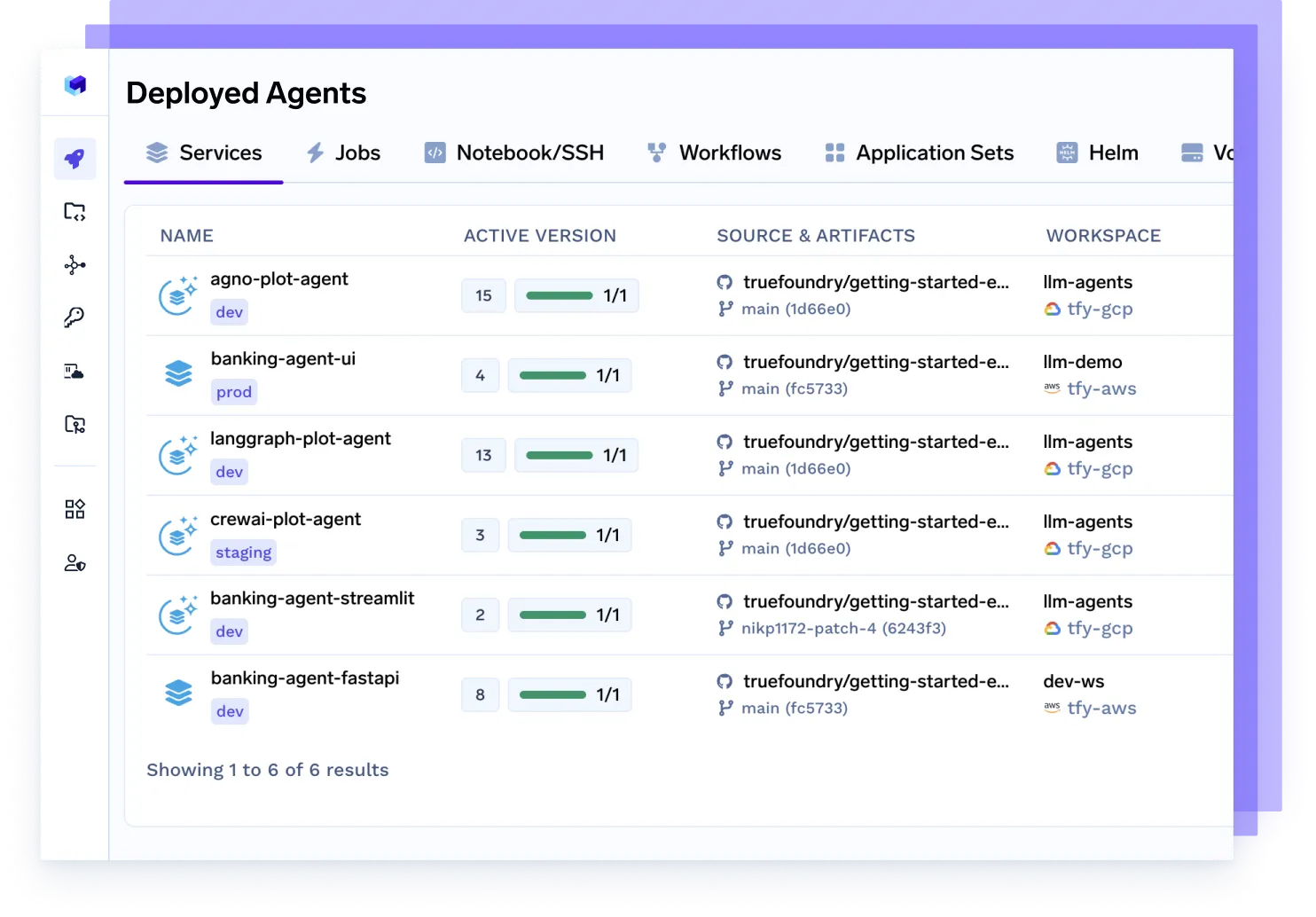
Implemente cualquier agente, cualquier marco
Atienda sin problemas a los agentes creados con Langgraph, CrewAI, AutoGen o su propia organización, completamente en contenedores, observables y listos para la producción.
VPC, local, aislada o en varias nubes.
Ningún dato sale de tu dominio. Disfrute de una total soberanía, aislamiento y cumplimiento de nivel empresarial dondequiera que se ejecute TrueFoundry.


Preparado para la empresa
Implemente una pasarela de IA segura que mantenga sus datos y modelos dentro de su infraestructura en la nube o local.


Cumplimiento y seguridad
Estándares SOC 2, HIPAA y GDPR para garantizar una protección de datos sólidaGobernanza y control de acceso
Control de acceso basado en roles SSO + (RBAC) y registro de auditoríaSoporte y confiabilidad empresariales
Soporte ininterrumpido con respaldo de SLA SLA de respuesta
Observe los agentes y la infraestructura subyacente
Rastreo independiente del marco para todo, desde la ejecución inmediata hasta el rendimiento de la GPU.
Observabilidad total de los agentes
Realice un seguimiento de cada paso, desde la ejecución inmediata hasta la ejecución de la herramienta o el modelo, con métricas, latencia y resultados
.avif)
Integración perfecta con herramientas internas
Compatible con OpenTelemetry; conéctese a Grafana, Datadog, Prometheus o a su pila de observabilidad preferida




Observabilidad de infrarrojos (GPU, CPU, clúster)
Supervise el uso de los recursos en la nube o en las instalaciones, incluida la memoria de la GPU, el estado de los nodos y el comportamiento de escalado
.avif)
Controle y haga cumplir la normativa en toda la IA de nivel empresarial
Establezca la confianza y la disciplina operativa con controles de acceso sólidos, la aplicación de políticas y una capacidad de observación completa, integrados de forma nativa desde el primer día.
.webp)
Control de acceso granular basado en roles (RBAC)
Controle con precisión quién puede acceder a los modelos, los entornos o las API en función de los equipos, los roles y las funciones.
.webp)
Registro de auditoría inmutable
Registre toda la actividad, incluido el uso del modelo, el acceso de los usuarios y los cambios de configuración para garantizar una completa preparación para la auditoría.

Arquitectura preparada para el cumplimiento
Diseñado para cumplir con los más altos estándares de seguridad y cumplimiento, incluidos SOC 2, HIPAA y GDPR.
.avif)
Monitorización y alertas unificadas
Realice un seguimiento de la latencia, el rendimiento, el uso de los tokens, los costos y la utilización de la GPU en toda su pila de IA mediante alertas y paneles centralizados.
.avif)
Aplicación de políticas en tiempo real
Aplica políticas relacionadas con la residencia de datos, las cuotas de uso, los límites de velocidad y el control de costos de forma dinámica a medida que se ejecutan las cargas de trabajo.
Prevemos una infraestructura de IA optimizada para la IA y sin administración
Optimización automatizada de recursos sin gastos operativos

Orquestación de GPU y escalado automático
Programa y escala automáticamente las cargas de trabajo de la GPU para adaptarlas a la demanda, optimizando el rendimiento sin sobreaprovisionamiento.
Soporte de GPU fraccional
(MIG y Time Slicing)
Permita el uso compartido rentable de los recursos de la GPU entre múltiples cargas de trabajo mediante NVIDIA MIG y la reducción del tiempo.
Recurso en tiempo real
Optimización
Ajuste continuamente las asignaciones de CPU y memoria en función de las necesidades informáticas y de tráfico reales.
Ajuste automatizado del tamaño de la infraestructura
Detecte y corrija la infraestructura sobreaprovisionada para reducir el desperdicio de la nube y, al mismo tiempo, mantener el rendimiento de los modelos y los SLA.
Resultados reales en TrueFoundry
Por qué las empresas eligen TrueFoundry






3 veces
tiempo de obtención de valor más rápido con agentes de LLM autónomos
80%
mayor utilización de los clústeres de GPU tras la optimización automatizada de los agentes

Aarón Erickson
Fundador de Applied AI Lab
TrueFoundry convirtió nuestra flota de GPU en un motor autónomo y con optimización automática, lo que aumentó un 80% la utilización y nos ahorró millones en cómputos inactivos.
5x
menor tiempo de producción de la plataforma interna de AI/ML
50%
menor gasto en la nube después de migrar las cargas de trabajo a TrueFoundry

Pratik Agrawal
Director sénior de Ciencia de Datos e Innovación en Inteligencia Artificial
TrueFoundry nos ayudó a pasar de la experimentación a la producción en un tiempo récord. Lo que hubiera llevado más de un año se hizo en meses, con una mejor adopción por parte de los desarrolladores.
80%
reducción del tiempo de producción de los modelos
35%
ahorro de costes en la nube en comparación con la configuración anterior de SageMaker
.webp)
Vibhas Geji
Ingeniero de ML en plantilla
Redujimos la carga de DevOps y simplificamos las implementaciones de producción en todos los equipos. TrueFoundry aceleró la entrega de aprendizaje automático con una infraestructura que va desde experimentos hasta servicios sólidos.
50%
despliegue más rápido de la pila de RAG/Agent
60%
reducción de los gastos de mantenimiento de las tuberías de RAG/Agent
.webp)
Indroneel G.
Líder de procesos inteligentes
TrueFoundry nos ayudó a implementar una pila RAG completa, que incluía canalizaciones, bases de datos vectoriales, API e interfaz de usuario, el doble de rápido y con un control total sobre la infraestructura autohospedada.
60%
despliegues de IA más rápidos
~ 40-50%
Reducción efectiva de costos en todos los entornos de desarrollo
.webp)
Nilav Ghosh
Director sénior de IA
Con TrueFoundry, redujimos los plazos de implementación en más de la mitad y redujimos la sobrecarga de infraestructura a través de una interfaz MLOps unificada, lo que aceleró la entrega de valor.
<2
semanas para migrar todos los modelos de producción
75%
reducción del tiempo de coordinación de la ciencia de datos, acelerando las actualizaciones de los modelos y el despliegue de funciones
.webp)
Rajat Bansal
CTO
Hemos ahorrado mucho en costes de infraestructura y hemos reducido el tiempo de coordinación de DS en un 75%. TrueFoundry aumentó la velocidad de implementación de nuestros modelos en todos los equipos.
Integraciones
Integraciones independientes del marco para todo, desde creadores de agentes con poco código hasta evaluaciones del rendimiento a nivel de GPU.
.avif)

GenAI infra: simple, más rápido y más barato
Los mejores equipos confían en nosotros para escalar GenAI
- © 2022 ENSEMBLE Technologies






Suscríbase a nuestro boletín
Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada














