

May 8, 2024
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
En una era en la que las LLM impulsan las aplicaciones críticas, la visibilidad de su funcionamiento interno no es negociable. La observabilidad de la LLM es la práctica de capturar y analizar datos a nivel de inferencia, incluidos el uso de los tokens, el rendimiento rápido, las tasas de error, la latencia y las métricas de costos, y correlacionarlos con las interacciones de los usuarios. Esto va más allá de la supervisión de modelos tradicionales, que hace un seguimiento en gran medida de las métricas de la infraestructura, como el uso de la CPU y los tiempos de respuesta. AI Gateway de TrueFoundry incorpora una capa de observabilidad integral con un control rápido de versiones, registros estructurados, paneles de análisis en tiempo real y alertas de anomalías para obtener información útil, optimizar el rendimiento y controlar los costos en cada etapa del proceso de LLM.
La observabilidad del LLM es la práctica integral de instrumentar, recopilar y analizar cada evento de inferencia en una canalización de modelos lingüísticos. Combina dos capas principales:
Análisis interactivo
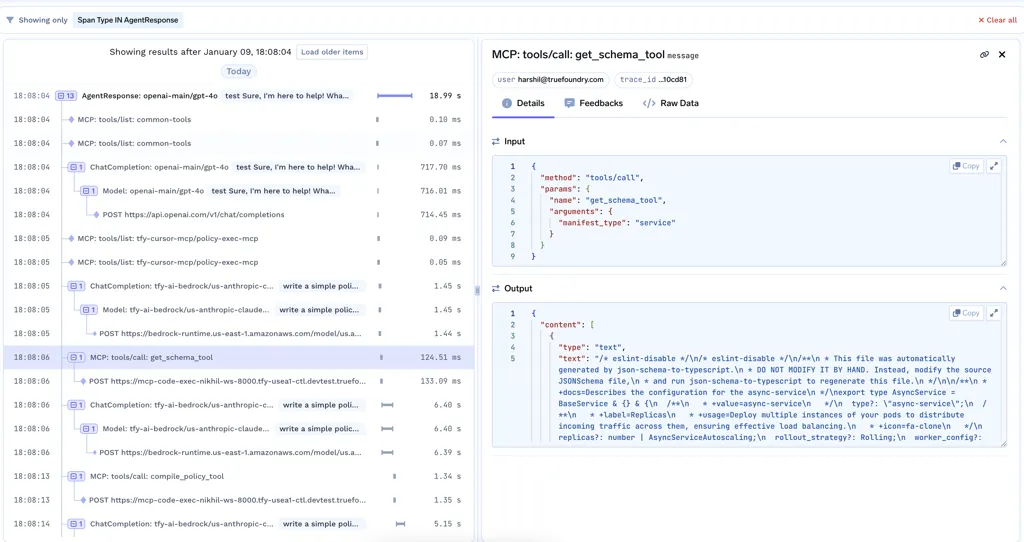
Un panel centralizado muestra métricas en tiempo real sobre el uso de los tokens, el volumen de solicitudes y el costo. Puede ver los tokens de entrada y salida acumulados, el total de solicitudes y los costos de los tokens junto con los percentiles de latencia (P50, P90, P99) de cada modelo. Los gráficos muestran las solicitudes por segundo, las tasas de error, el consumo a nivel de usuario y los desgloses de costos según el modelo. Los filtros permiten aislar las llamadas afectadas por la limitación de la frecuencia, las alternativas o el equilibrio de carga, e inspeccionar qué reglas se han aplicado.
Contexto basado en metadatos
Cada solicitud puede incluir etiquetas personalizadas, como el entorno (dev, staging, prod), el nombre de la función, el ID de usuario, el equipo o cualquier contexto empresarial a través de un encabezado X-TFY-METADATA. Los metadatos permiten:
Exportación de registros
Para un análisis o archivado en profundidad, TrueFoundry admite exportaciones JSON estructuradas de registros y seguimientos a pedido, lo que permite investigar sin conexión los patrones de rendimiento, costo y uso
En conjunto, estas capacidades brindan a los equipos una visibilidad total del comportamiento del modelo, los factores de costo y los posibles problemas, lo que garantiza implementaciones de LLM confiables y optimizadas.
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
La observabilidad de los modelos tradicionales se centra principalmente en el estado de la infraestructura y en las métricas de solicitudes básicas. Usted supervisa los indicadores a nivel del sistema, como el uso de la CPU y la GPU, el consumo de memoria, las E/S de los discos, el rendimiento de la red, la latencia general de las solicitudes y las tasas de error. Estas métricas indican si su plataforma de servicio de modelos está operativa y dónde pueden producirse cuellos de botella informáticos o de red. Las alertas se activan cuando se infringen determinados umbrales, como una carga elevada de la CPU o una tasa de error 5 veces mayor, lo que permite a los equipos de operaciones aprovisionar recursos o investigar las interrupciones del servicio.
La observabilidad del LLM, por el contrario, profundiza en la semántica y la economía de cada inferencia. Los modelos lingüísticos de gran tamaño manejan entradas de longitud variable y generan contenido token por token, por lo que comprender su comportamiento requiere una instrumentación que tenga en cuenta el contenido:
Métricas de token frente a rendimiento fijo
Los modelos tradicionales cuentan las solicitudes por segundo; los LLM rastrean los tokens de entrada y salida. La observabilidad captura los volúmenes acumulados de tokens, los costos de los tokens y el uso de los tokens por modelo. Esto le permite atribuir el gasto a usuarios o funciones específicos y detectar las solicitudes descontroladas antes de que los costos aumenten.
Registro de respuesta rápida versus predicciones de caja negra
Los registros de observabilidad de ML estándar solo solicitan metadatos, como el código de estado y de acceso al punto final. La observabilidad del LLM registra todos los pares de respuestas rápidas y rápidas junto con metadatos contextuales, como el entorno, la función y el identificador de usuario. Esto permite rastrear las alucinaciones o las regresiones de calidad hasta llegar a determinadas plantillas de mensajes o grupos de usuarios.
Percentiles de latencia frente a promedios
Las configuraciones tradicionales suelen informar de una latencia promedio. Los paneles de LLM muestran los percentiles de latencia P50, P90 y P99 por modelo, ya que la generación token por token puede introducir retrasos prolongados que las métricas medias ocultan.
Efectos impulsados por la configuración
Con los LLM, los controles como la limitación de velocidad, el equilibrio de carga y las reglas de respaldo afectan al comportamiento. La observabilidad marca las solicitudes que se ven afectadas por estas reglas (por ejemplo, las llamadas con una velocidad limitada, redirigidas o devueltas a otro proveedor), lo que permite a los equipos ajustar las políticas.
Análisis en tiempo real frente a registros post mortem
Si bien la observabilidad tradicional se basa en el análisis de registros periódicos, las plataformas de observabilidad de LLM, como AI Gateway de TrueFoundry, proporcionan paneles interactivos para el filtrado en tiempo real y la exploración de tendencias, lo que le permite dividir las métricas por etiquetas de metadatos sobre la marcha.
En resumen, la observabilidad tradicional responde a la pregunta: «¿Está en buen estado la infraestructura de servicio?» LLM Observability explica: «¿Cómo, cuándo y por qué se genera cada token y qué significa eso para el costo, el rendimiento y la calidad de los resultados?»
La implementación de una observabilidad sólida para los LLM es esencial para mantener el rendimiento, controlar los costos y garantizar resultados de alta calidad. Estos pilares fundamentales funcionan en conjunto para ofrecer a los equipos una visibilidad completa de cada evento de inferencia. Al comprenderlos y aplicarlos, puede monitorear, diagnosticar y optimizar sus despliegues de LLM de manera efectiva.
1. Análisis interactivo
Un panel unificado ofrece información en tiempo real sobre todos los aspectos de su carga de trabajo de LLM. Puede realizar un seguimiento de los volúmenes acumulados y por modelo de tokens de entrada y salida, los recuentos totales de solicitudes y los costos basados en los tokens. Los percentiles de latencia detallados (P50, P90 y P99) revelan las características de rendimiento. Los gráficos de solicitudes por segundo y las tasas de error ayudan a detectar anomalías. Los filtros te permiten analizar en detalle las llamadas afectadas por los límites de frecuencia, las reglas de equilibrio de carga o las llamadas alternativas para solucionar problemas específicos.
2. Contexto basado en metadatos
Al adjuntar metadatos personalizados a cada solicitud, como el entorno (desarrollo, preparación, producción), el nombre de la función, el ID de usuario o el equipo, podrás desglosar tus métricas. Los metadatos permiten la supervisión granular del uso en todas las cohortes, impulsan los controles condicionales para limitar las tasas y la selección de modelos, y permiten filtrar los registros de forma precisa para realizar auditorías y cumplir con los requisitos. Los metadatos se transfieren a través de un único encabezado X-TFY-METADATA en los SDK de OpenAI o LangChain, las solicitudes REST o las llamadas cURL.
3. Registro completo
Cada inferencia se registra en un formato estructurado que incluye pares completos de respuesta rápida, recuentos de tokens, detalles de latencia, códigos de error y metadatos adjuntos. Este nivel de detalle te permite analizar las causas fundamentales de las alucinaciones, las regresiones de calidad o las anomalías de rendimiento. Puedes comparar versiones rápidas, supervisar cómo afectan los cambios en las plantillas a la calidad de los resultados y rastrear los problemas hasta llegar a grupos de usuarios o funciones específicas.
4. Exportación y auditoría de registros
Para un análisis o archivado sin conexión más profundos, TrueFoundry admite exportaciones JSON estructuradas de registros y trazas. Los administradores simplemente solicitan las exportaciones a través del servicio de asistencia durante un período de tiempo específico. Los datos exportados permiten el análisis personalizado, los informes de cumplimiento o el almacenamiento a largo plazo.
En conjunto, estos pilares brindan total transparencia en cuanto a los factores de costo, los perfiles de rendimiento y la calidad de los resultados, lo que garantiza que sus implementaciones de LLM sigan siendo confiables, eficientes y rentables.
Aquí están los 4 mejores herramientas de observabilidad de LLM, con una breve descripción de cada una de ellas:
AI Gateway de TrueFoundry ofrece una solución unificada de observabilidad y gobierno de nivel empresarial para los LLM con las siguientes capacidades:
Estadísticas en tiempo real
.webp)
Paneles interactivos que muestran los recuentos de tokens de entrada/salida acumulados y por modelo, el volumen total de solicitudes, los desgloses de costos por modelo y usuario y los percentiles de latencia detallados (P50, P90, P99). Mapas térmicos de solicitudes por segundo, tendencias en la tasa de errores y alertas de anomalías configurables para detectar picos de fallos o latencia
Información basada en metadatos
{
«tfy_log_request»: «true», //Si se debe agregar un registro/rastreo para esta solicitud o ahora
«environment»: «puesta en escena»,//El entorno: ¿desarrollo, puesta en escena o producción?
«feature»: «countdown-bot»//¿Qué función inició la solicitud?
}
Etiquete las solicitudes con el contexto empresarial (entorno, función, usuario, equipo) mediante un único encabezado X-TFY-METADATA. Divida los paneles y los registros según los metadatos para comparar los entornos, aislar el uso de las funciones y auditar la actividad de los usuarios o equipos.
Controles de políticas como código
Defina reglas de limitación de velocidad impulsadas por YAML (por ejemplo, «1000 llamadas GPT-4 por día para desarrolladores»), equilibre la carga entre los proveedores y cadenas de respaldo cuando se produzcan errores
Definiciones de políticas controladas por versiones administradas a través de los flujos de trabajo de GitOps, lo que permite revisar las solicitudes de extracción, validar la CI y realizar reversiones
Registro y rastreo exhaustivos

Almacene registros JSON estructurados de pares completos de respuestas rápidas, desgloses a nivel de token, latencia, códigos de error e ID de políticas aplicadas. Correlacione los seguimientos distribuidos para depurar flujos de trabajo de varios pasos o canalizaciones RAG
Exportación y cumplimiento:
Exportación bajo demanda de registros y trazas en JSON para análisis fuera de línea, archivado a largo plazo o auditorías reglamentarias. El RBAC incorporado y los registros de auditoría garantizan que solo los usuarios autorizados puedan ver o exportar datos confidenciales
Estas características convierten a TrueFoundry en una opción sobresaliente para los equipos que necesitan visibilidad de extremo a extremo, un control de costos detallado, una gobernanza de políticas como código y una sólida capacidad de auditoría en sus implementaciones de LLM.
LangSmith se especializa en el rastreo profundo y la depuración para aplicaciones basadas en Langchain. Captura automáticamente cada paso de las cadenas y registra las entradas rápidas, las salidas intermedias y las respuestas finales. Los desarrolladores disponen de un visualizador de trazas interactivo para comparar las plantillas de mensajes a lo largo del tiempo, identificar las regresiones del rendimiento y analizar en detalle las llamadas a funciones. LangSmith también registra las métricas de tiempo de ejecución, como el uso de los tokens y la latencia por paso de la cadena, y permite adjuntar metadatos personalizados para el seguimiento de las funciones. Con la gestión de experimentos integrada, puede etiquetar las ejecuciones, comparar la calidad de los resultados entre las distintas versiones del modelo y volver a configuraciones probadas. Al centrarse en la ergonomía de los desarrolladores y en la transparencia de la cadena, es ideal para realizar iteraciones y depuraciones rápidas.
Helicone ofrece una plataforma de observabilidad centrada en la API diseñada para la IA generativa. Registra todas las llamadas de API a OpenAI, Anthropic u otros puntos finales, y captura los textos completos de las notificaciones, las respuestas, el uso de los tokens y los detalles de los tiempos. El panel de control de Helicone destaca el costo por llamada, las plantillas de avisos más utilizadas y las distribuciones de errores, lo que le ayuda a identificar patrones costosos o propensos a fallar. Las visualizaciones integradas que modelan el tráfico revelan cómo los límites de velocidad y las cuotas afectan al rendimiento, y puedes configurar alertas para detectar picos de costes o tasas de error elevadas. Gracias a sus ligeras integraciones de SDK, Helicone proporciona información rápida sobre los gastos y el rendimiento, lo que la convierte en una excelente opción para los equipos que se centran en el control de los costes de las API y en la optimización inmediata.
Lunary se centra en la simplicidad y la experiencia del desarrollador para la observabilidad de la LLM. Instrumenta automáticamente las llamadas al SDK de OpenAI y Anthropic, registrando los recorridos rápidos, las métricas de los tokens y los tiempos de respuesta con una configuración mínima. Su panel de control presenta plantillas de mensajes versionadas y sistemas de detección de regresión para garantizar la calidad de los resultados, y le avisa cuando los cambios producen resultados inesperados. Lunary también ofrece una API de anotaciones para etiquetar experimentos o pruebas A/B, lo que permite realizar comparaciones claras entre las ejecuciones. Si bien es ligera, admite controles condicionales para la limitación de velocidad y el enrutamiento alternativo. El énfasis de Lunary en la facilidad de configuración y en las principales funciones de observabilidad lo hacen ideal para equipos pequeños o prototipos que necesitan comentarios rápidos sobre el comportamiento del modelo sin integraciones complejas.
Uso de fichas variables: Los LLM generan resultados token por token, por lo que cada solicitud puede consumir recuentos de tokens muy diferentes. El monitoreo y la atribución de los costos se vuelven complejos cuando los volúmenes de los tokens fluctúan enormemente según las solicitudes y los usuarios. Sin un seguimiento detallado de los tokens, los equipos corren el riesgo de que se produzcan picos de facturación inesperados o de recibir solicitudes ineficientes que pasen desapercibidas.
Alto volumen de datos: La captura de pares completos de pronto-respuesta, métricas de token, detalles de latencia y metadatos para cada inferencia puede generar millones de entradas de registro por día. El almacenamiento, la indexación y la consulta de este volumen de datos estructurados requieren soluciones de almacenamiento escalables y motores de consulta optimizados para evitar obstáculos en el rendimiento en su proceso de observabilidad.
Complejidad contextual: El comportamiento del LLM depende en gran medida de la redacción rápida, los ajustes de temperatura y la versión del modelo. Correlacionar los cambios en la calidad o la latencia de la salida con modificaciones rápidas o ajustes de configuración específicos exige una vinculación de trazas y un control de versiones sólidos. Los equipos deben implementar un etiquetado de metadatos coherente y un control rápido de las versiones para desentrañar la red de factores que influyen.
Correlación entre múltiples proveedores: Muchas implementaciones utilizan varios proveedores de LLM para equilibrar la carga o optimizar los costos. La agregación de métricas de OpenAI, Azure, Anthropic y otros puntos finales en una vista unificada requiere normalizar las diferentes API, formatos de respuesta y estructuras de costos. Si no se unifican estos flujos, se obtienen conocimientos fragmentados y puntos ciegos en las comparaciones de rendimiento entre proveedores.
Alertas en tiempo real frente a ruido: Establecer umbrales de alerta significativos para las tasas de error, los picos de latencia o las anomalías de costos es un desafío en un entorno en el que las fluctuaciones naturales son comunes. Las alertas demasiado sensibles provocan fatiga, mientras que los umbrales demasiado altos pueden retrasar la detección de problemas críticos. Los equipos necesitan estrategias de alerta adaptables que aprendan los patrones de uso normales y ajusten los umbrales de forma dinámica.
Cumplimiento y privacidad: El almacenamiento de registros completos de las conversaciones puede entrar en conflicto con las normas de privacidad de datos o las políticas de seguridad internas. Equilibrar la necesidad de datos de observabilidad con los requisitos de minimización de datos, cifrado y controles de acceso requiere una definición cuidadosa de las políticas y un soporte de herramientas para la redacción selectiva o la anonimización de los registros.
Abordar estos desafíos exige un marco de observabilidad sólido que escale con el uso, aplique prácticas de metadatos consistentes, normalice los datos de varios proveedores y ofrezca alertas inteligentes para detectar solo los problemas más críticos.
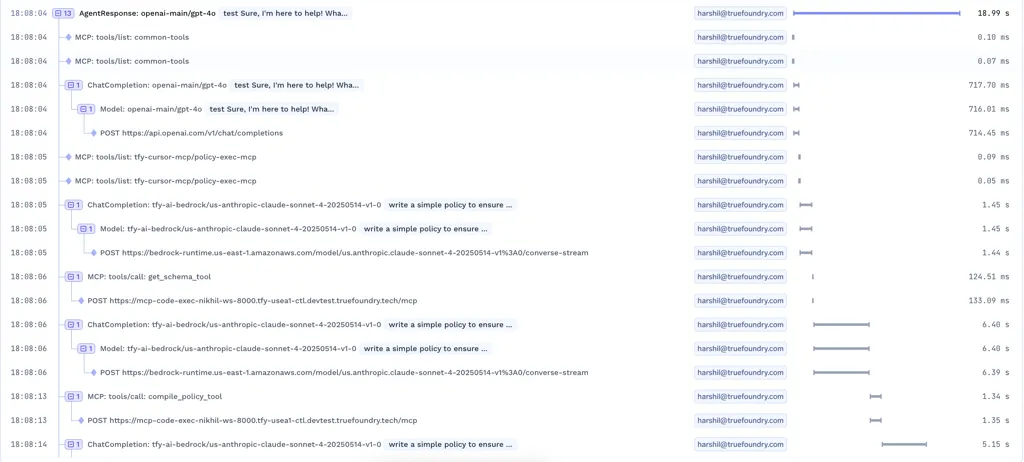
En los sistemas reales, una solicitud de LLM rara vez es una sola llamada a un modelo. Es una cadena de pasos.
La entrada del usuario se convierte en un mensaje. Ese mensaje muestra el contexto. El modelo responde. La respuesta activa una herramienta. El resultado de la herramienta se refleja en el modelo. Solo entonces el usuario ve una respuesta. Cada etapa implica repetir Inferencia de LLM, razón por la cual el rastreo debe capturar todas las decisiones intermedias y no solo el resultado final.
Un buen rastreo lo hace visible.
Los equipos deben ver:
Sin esto, la depuración se convierte en conjeturas. Con él, los equipos pueden seguir exactamente lo que pasó y los puntos en los que las cosas salieron mal.
Para muchos equipos, el costo es la primera señal de alarma real. Los costos de LLM no aumentan como los costos de infraestructura. Crecen con los tokens, la verbosidad, los reintentos y los pasos intermedios ocultos. Un pequeño cambio rápido o un agente que se porta mal pueden duplicar el gasto de forma discreta.
Por eso es importante la visibilidad a nivel de token.
Los equipos deben comprender:
Cuando los datos de los tokens se vinculan a los rastros, el costo deja de ser una sorpresa y comienza a ser algo que puede gestionar.
Una vez que los LLM comienzan a llamar a las herramientas, las cosas se vuelven más poderosas y frágiles. Los agentes pueden buscar en bases de datos, llamar a las API o activar flujos de trabajo. Con MCP, estas herramientas se descubren y se invocan de forma dinámica, lo que hace que los sistemas sean más flexibles, pero también más difíciles de razonar.
En producción, los equipos necesitan respuestas claras a las preguntas básicas:
Sin observabilidad en el Nivel de herramienta de observabilidad LLM, los equipos pierden la confianza rápidamente. Con él, pueden auditar el comportamiento, corregir errores y escalar de forma segura los sistemas basados en agentes.
El objetivo no son mejores dashboards. Es confianza. En la práctica, aquí es donde LLMOP se vuelve fundamental, porque los datos de observabilidad deben alimentar continuamente las decisiones de implementación, los controles de costos y la gobernanza de modelos. Cuando los equipos pueden ver con claridad los rastros, el uso de los tokens y el comportamiento de las herramientas, pueden detectar los problemas antes, controlar los costos y mejorar la calidad basándose en datos de producción reales.
Esto crea un bucle: observe lo que ocurre en la producción, aprenda de ello, mejore el sistema y repita. Plataformas como La puerta de enlace de IA de TrueFoundry ayudan a los equipos a lograrlo reuniendo el rastreo, las métricas y la gobernanza en un solo lugar, de modo que los sistemas de LLM puedan tratarse como la infraestructura crítica que son.
La implementación de la observabilidad de LLM transforma las canalizaciones de inferencia opacas en sistemas transparentes y administrables. Al combinar el análisis interactivo, el contexto basado en metadatos, los controles dinámicos de políticas, el registro completo y la exportación de registros sin interrupciones, los equipos obtienen la información necesaria para supervisar el rendimiento, controlar los costos y mantener la calidad de los resultados. Si bien desafíos como el uso variable de los tokens, el volumen de datos y la correlación entre varios proveedores exigen arquitecturas escalables y prácticas de metadatos disciplinadas, una solución de observabilidad unificada garantiza que pueda detectar las anomalías de forma temprana, solucionar los problemas de manera eficaz y repetir las instrucciones con confianza. En el panorama actual impulsado por la IA, una sólida capacidad de observación de la LLM no es opcional, sino esencial para ofrecer aplicaciones fiables y rentables a escala.
Reserva una demostración para ver cómo TrueFoundry puede ayudarte a mejorar la observabilidad de la LLM.
La observabilidad en la IA se refiere a la capacidad de comprender el estado interno de un sistema mediante el examen de su telemetría y sus salidas. Al analizar los rastros, las métricas y los registros, los equipos pueden diagnosticar los problemas de rendimiento en tiempo real. Esto garantiza que las implementaciones complejas sigan siendo transparentes, confiables y estén estrechamente alineadas con los objetivos comerciales previstos.
Los cinco pilares de la observabilidad de la LLM incluyen el análisis interactivo, el contexto basado en metadatos, el registro integral, las evaluaciones y las exportaciones de registros. Estos elementos proporcionan visibilidad sobre el consumo de los tokens, los costos y la calidad de la respuesta. Juntos, permiten a los equipos de ingeniería monitorear, solucionar problemas y optimizar de manera efectiva sus aplicaciones de LLM.
Las plataformas populares para obtener información profunda sobre los modelos incluyen LangSmith, Helicone y Arize Phoenix. Para las organizaciones que priorizan la soberanía de los datos, TrueFoundry ofrece una forma eficaz de implementar la observabilidad de la LLM en su propia infraestructura. Estas herramientas ayudan a los desarrolladores a depurar las cadenas de razonamiento, hacer un seguimiento de los costos y mantener una alta calidad de salida de las respuestas.
La supervisión tradicional rastrea las métricas conocidas, como la latencia o las tasas de error, para mantener el estado de la infraestructura. La observabilidad de LLM utiliza el rastreo semántico para explicar por qué ocurren problemas específicos. Si bien la monitorización simplemente indica que un sistema ha fallado, la observabilidad proporciona los datos profundos y el contexto necesarios para encontrar y corregir la causa raíz.
TrueFoundry es único porque unifica el seguimiento a nivel de aplicación con la supervisión de la infraestructura dentro de su propia VPC segura. Mantiene una latencia inferior a 10 ms y, al mismo tiempo, gestiona un tráfico elevado en varios proveedores. Esta integración garantiza que los esfuerzos de observación del LLM sigan siendo rentables y seguros, al tiempo que proporciona información detallada sobre cada interacción entre modelos.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


