











LLM
Implemente y entregue LLM de código abierto o propietarios con aceleración de GPU y confiabilidad de nivel de producción.
Agentes
Ejecute agentes de IA de larga duración con memoria, ejecución de herramientas e integración perfecta con los servidores AI Gateway y MCP
Servidores MCP
Implemente servidores MCP para exponer de forma segura las herramientas, las API y los sistemas empresariales a los agentes de IA.
flujos de trabajo
Organice los flujos de trabajo de IA de varios pasos en todos los modelos, agentes y servicios desde un único plano de control.
Empleos
Ejecute trabajos por lotes, cargas de trabajo de entrenamiento y tareas de IA programadas bajo demanda.
Modelos ML clásicos
Implemente y sirva modelos tradicionales de aprendizaje automático junto con los LLM utilizando la misma plataforma.
.webp)
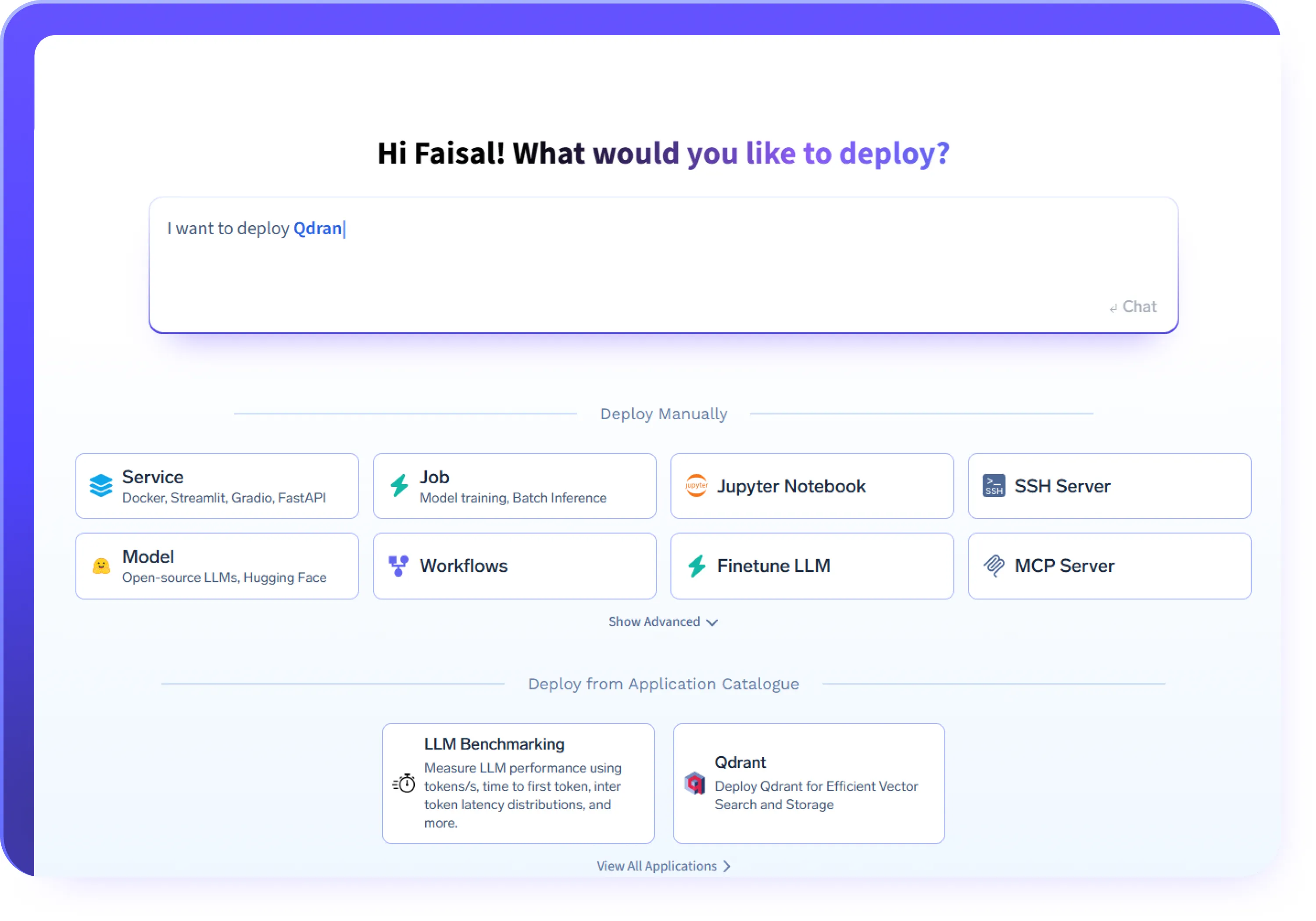
Implemente cualquier carga de trabajo de IA
- Implemente cargas de trabajo de inferencia basadas en LLM y GPU mediante marcos como vLLM, Triton, kServe o contenedores personalizados
- Implemente agentes y servicios de agentes de IA con un tiempo de ejecución y una red consistentes
- Implemente servidores MCP para exponer de forma segura las herramientas y los sistemas internos
- Ejecute trabajos por lotes, API y servicios de IA de larga duración en la misma plataforma
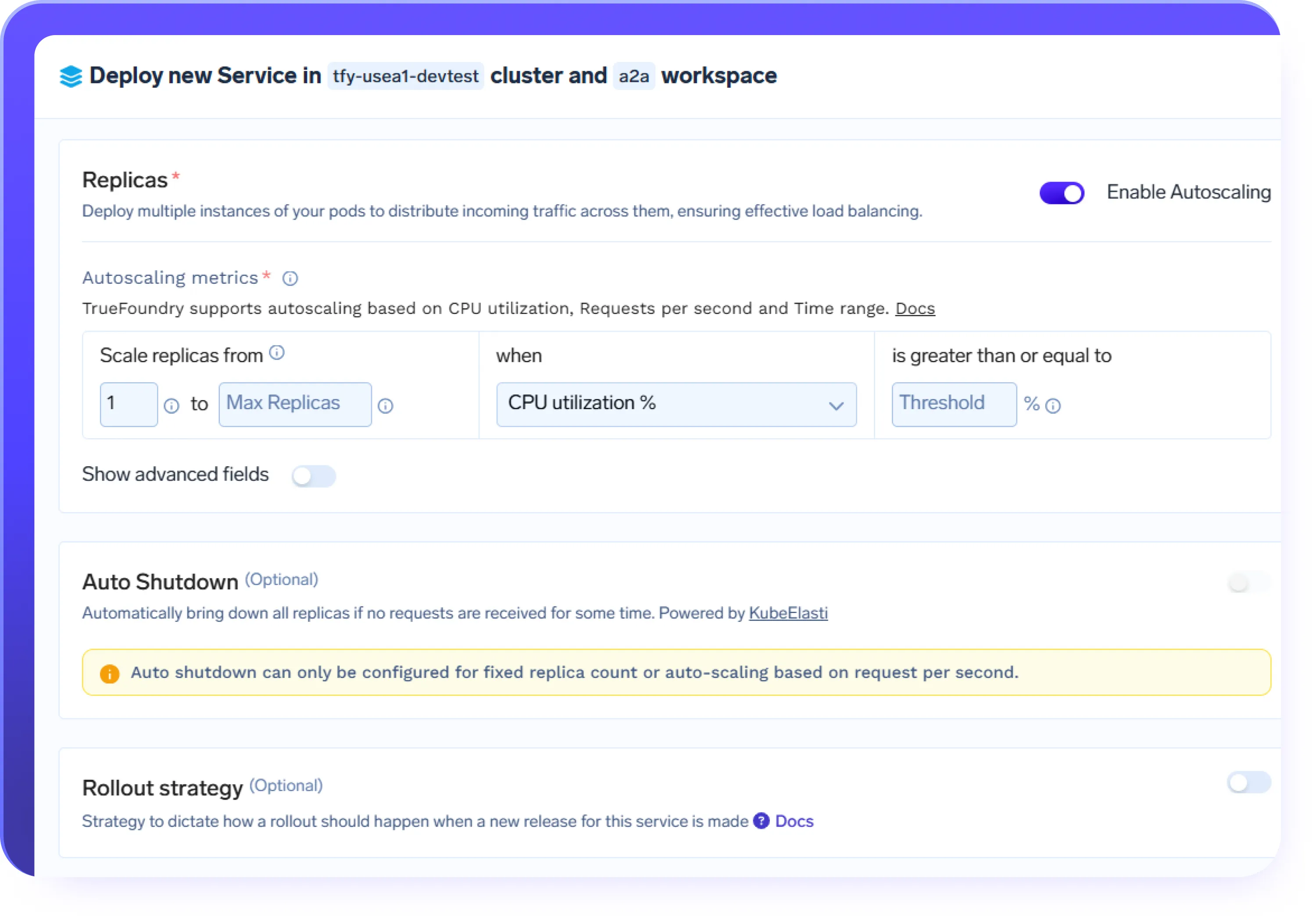
Escalado automático para cargas de trabajo de IA
demanda.
- Escale automáticamente los puntos finales de inferencia y los servicios de agentes en función del volumen de solicitudes
- Aumente las cargas de trabajo de la GPU durante los picos de demanda y disminuya cuando el tráfico disminuya
- Soporta cargas de trabajo rápidas, como el chat, el RAG y los flujos de trabajo impulsados por agentes
- Mantenga un rendimiento predecible durante los picos de tráfico
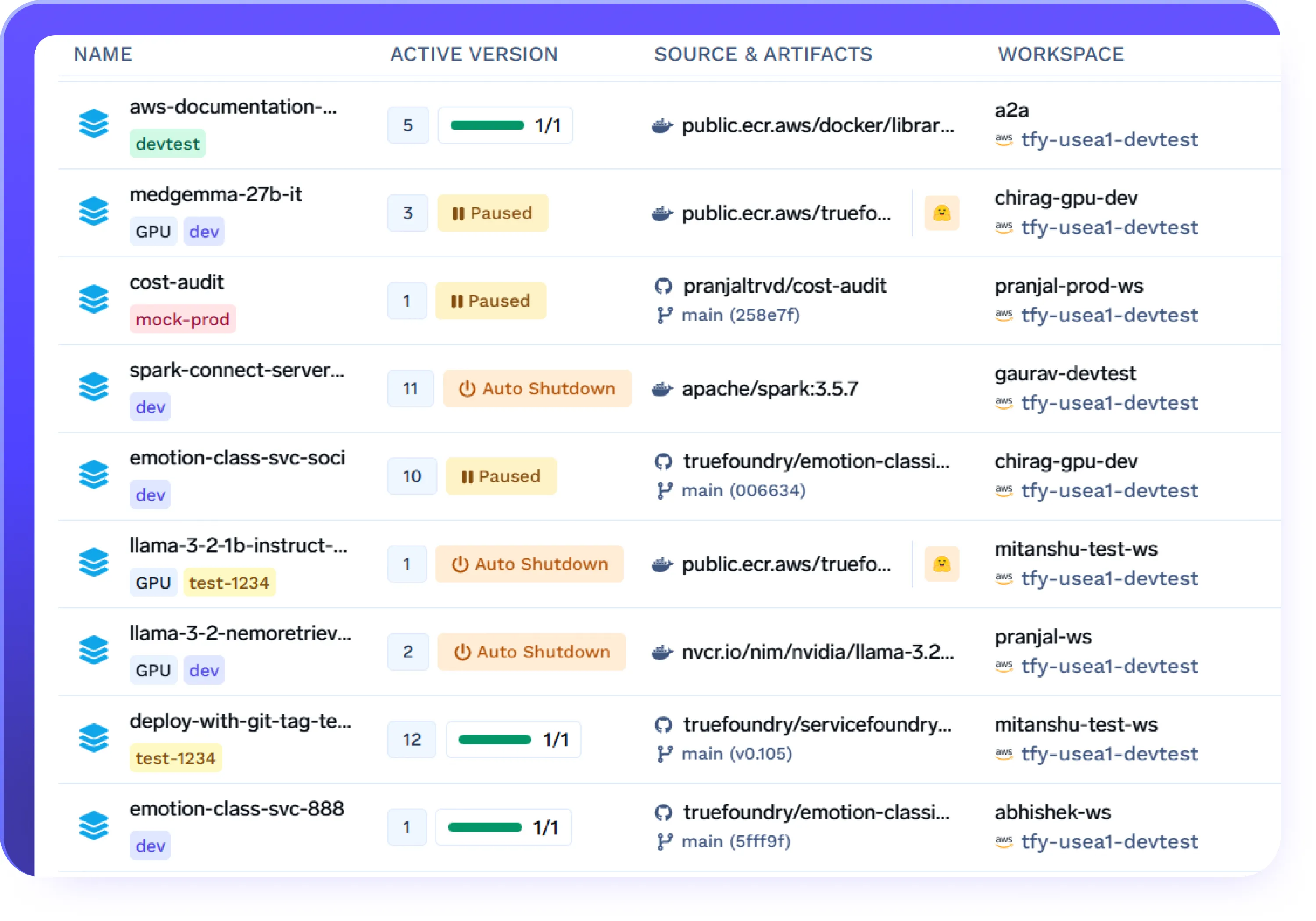
Apagado automático para controlar los costos
- Cierre automáticamente los terminales, los agentes o los servicios después de períodos de inactividad configurables
- Reduzca el desperdicio de GPU durante las horas de menor actividad o durante la experimentación
- Reinicie las cargas de trabajo a petición sin intervención manual
- Implemente la disciplina de costos en todos los equipos y
ambientes
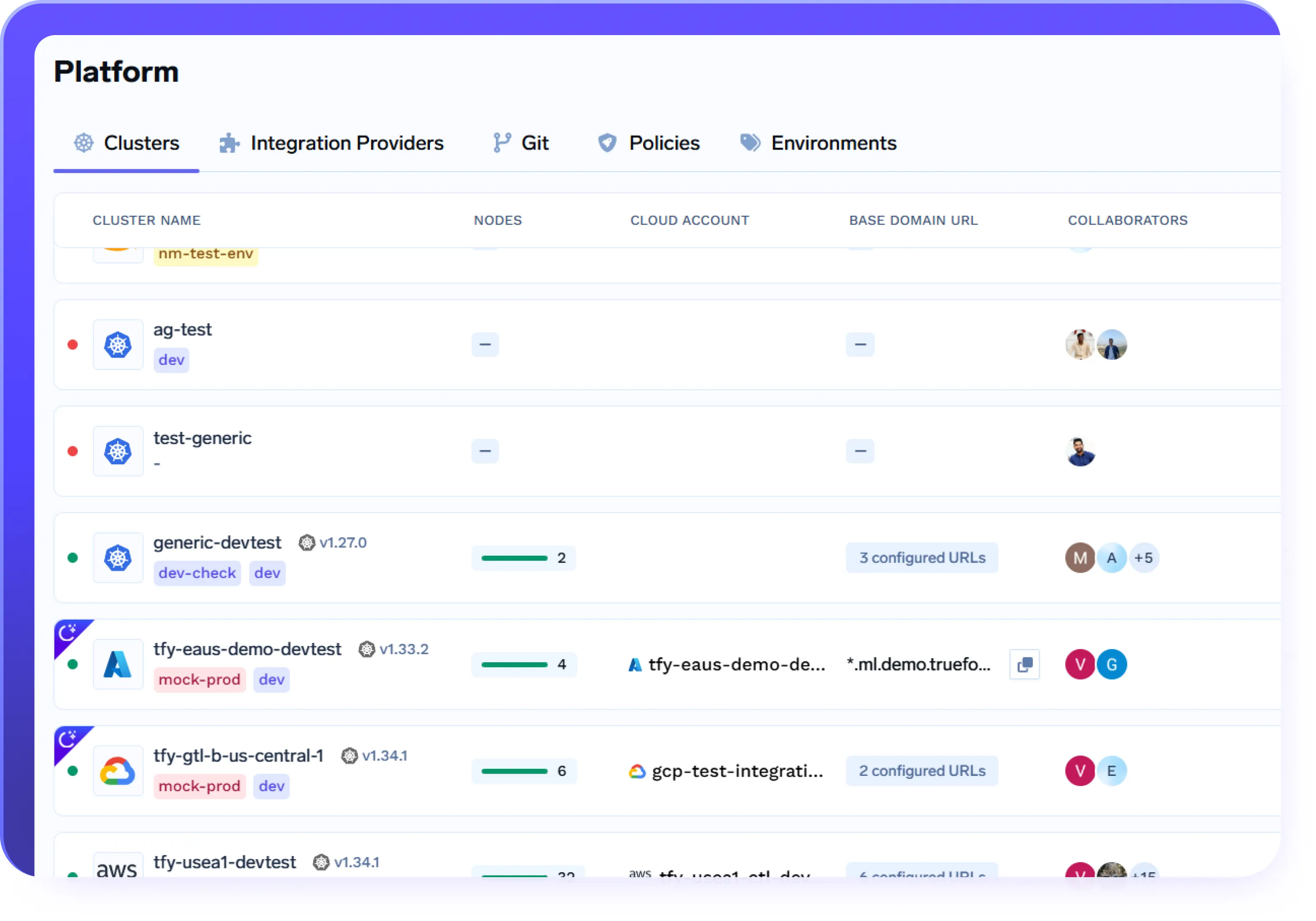
Experiencia de implementación unificada en la nube y local
- Conecte y administre clústeres de AWS, Azure, GCP y locales desde un único plano de control
- Implemente la misma carga de trabajo en diferentes entornos con flujos de trabajo y API idénticos
- Elimine la complejidad específica de la nube y, al mismo tiempo, mantenga el control y el aislamiento totales
- Utilice la misma experiencia de implementación en el desarrollo, la puesta en escena y la producción, independientemente de la infraestructura
Creado para una experiencia de desarrollador de primera clase
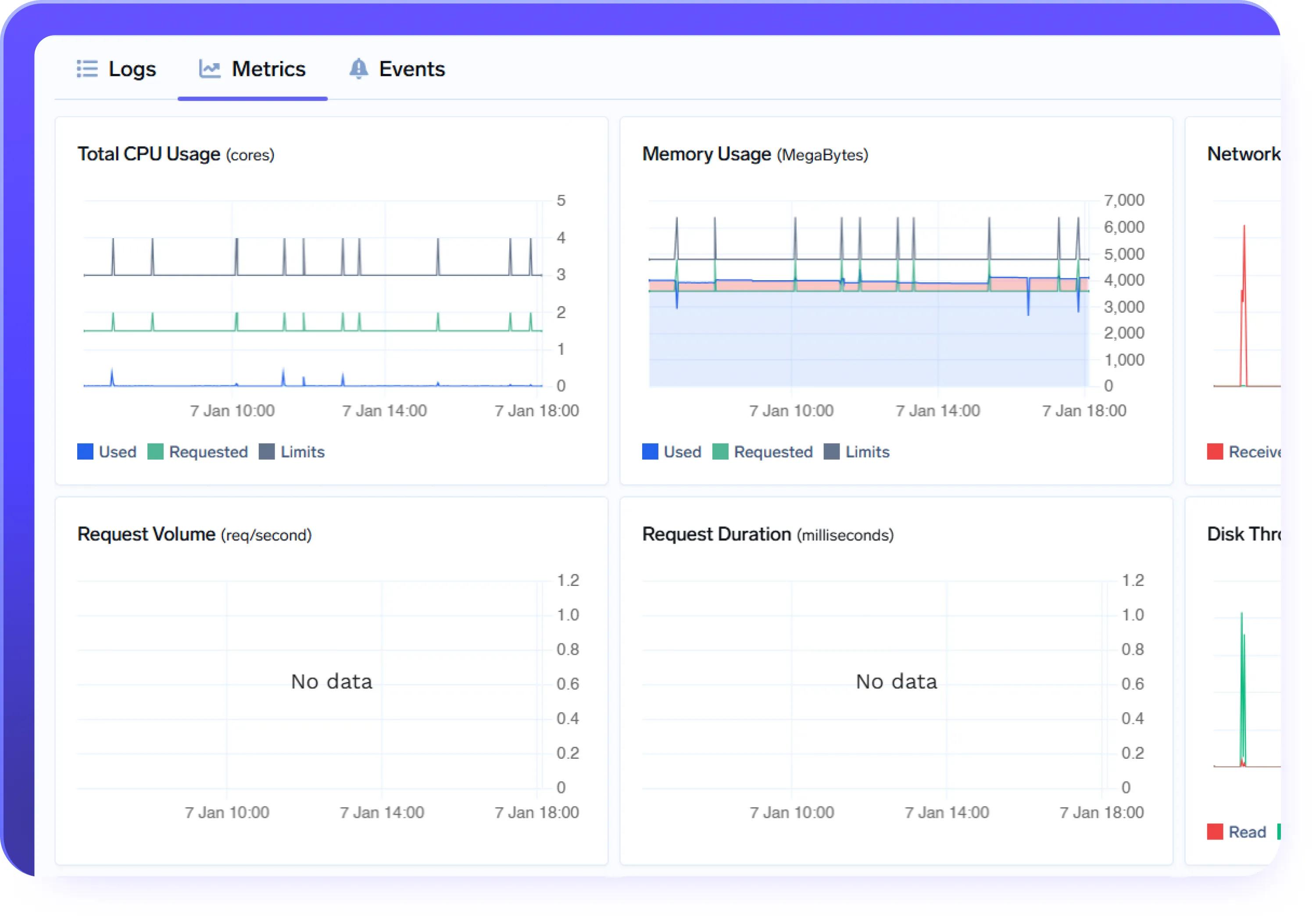
- Registros, métricas y eventos integrados para cada implementación
- Monitorización y alertas nativas para detectar y resolver problemas rápidamente
- Funciones de implementación listas para la producción, como comprobaciones de estado y estrategias de implementación
- Administración segura de secretos e integraciones fluidas de CI/CD
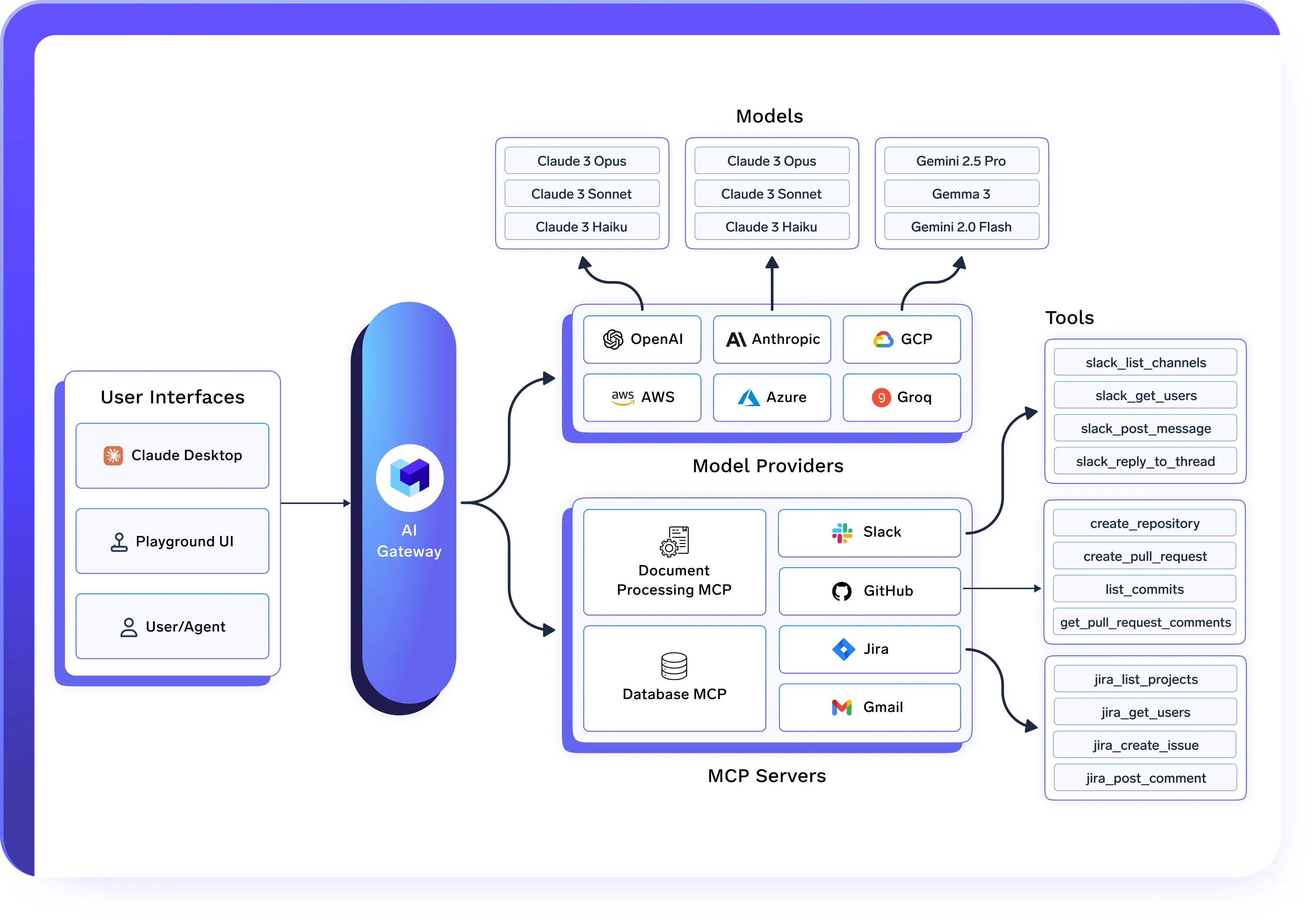
Funciona a la perfección con AI Gateway y Agent Gateway
por encima de él.
- AI Gateway regula el acceso, el enrutamiento y los controles de costos de los modelos
- MCP Gateway regula el acceso y la ejecución de las herramientas
- Agent Gateway organiza y controla los flujos de trabajo de los agentes
- Las implementaciones de IA unificada impulsan la ejecución y la infraestructura reales
Hecho para la IA del mundo real a escala
Preparado para la empresa
Implemente una pasarela de IA segura que mantenga sus datos y modelos dentro de su infraestructura en la nube o local.


Cumplimiento y seguridad
Estándares SOC 2, HIPAA y GDPR para garantizar una protección de datos sólidaGobernanza y control de acceso
Control de acceso basado en roles SSO + (RBAC) y registro de auditoríaSoporte y confiabilidad empresariales
Soporte ininterrumpido con respaldo de SLA SLA de respuesta
VPC, local, aislada o en varias nubes.
Ningún dato sale de tu dominio. Disfrute de total soberanía, aislamiento y cumplimiento de nivel empresarial dondequiera que se ejecute TrueFoundry


Resultados reales en TrueFoundry
Por qué las empresas eligen TrueFoundry






3 veces
tiempo de obtención de valor más rápido con agentes de LLM autónomos
80%
mayor utilización de los clústeres de GPU tras la optimización automatizada de los agentes

Aarón Erickson
Fundador de Applied AI Lab
TrueFoundry convirtió nuestra flota de GPU en un motor autónomo y con optimización automática, lo que aumentó un 80% la utilización y nos ahorró millones en cómputos inactivos.
5x
menor tiempo de producción de la plataforma interna de AI/ML
50%
menor gasto en la nube después de migrar las cargas de trabajo a TrueFoundry

Pratik Agrawal
Director sénior de Ciencia de Datos e Innovación en Inteligencia Artificial
TrueFoundry nos ayudó a pasar de la experimentación a la producción en un tiempo récord. Lo que hubiera llevado más de un año se hizo en meses, con una mejor adopción por parte de los desarrolladores.
80%
reducción del tiempo de producción de los modelos
35%
ahorro de costes en la nube en comparación con la configuración anterior de SageMaker
.webp)
Vibhas Geji
Ingeniero de ML en plantilla
Redujimos la carga de DevOps y simplificamos las implementaciones de producción en todos los equipos. TrueFoundry aceleró la entrega de aprendizaje automático con una infraestructura que va desde experimentos hasta servicios sólidos.
50%
despliegue más rápido de la pila de RAG/Agent
60%
reducción de los gastos de mantenimiento de las tuberías de RAG/Agent
.webp)
Indroneel G.
Líder de procesos inteligentes
TrueFoundry nos ayudó a implementar una pila RAG completa, que incluía canalizaciones, bases de datos vectoriales, API e interfaz de usuario, el doble de rápido y con un control total sobre la infraestructura autohospedada.
60%
despliegues de IA más rápidos
~ 40-50%
Reducción efectiva de costos en todos los entornos de desarrollo
.webp)
Nilav Ghosh
Director sénior de IA
Con TrueFoundry, redujimos los plazos de implementación en más de la mitad y redujimos la sobrecarga de infraestructura a través de una interfaz MLOps unificada, lo que aceleró la entrega de valor.
<2
semanas para migrar todos los modelos de producción
75%
reducción del tiempo de coordinación de la ciencia de datos, acelerando las actualizaciones de los modelos y el despliegue de funciones
.webp)
Rajat Bansal
CTO
Hemos ahorrado mucho en costes de infraestructura y hemos reducido el tiempo de coordinación de DS en un 75%. TrueFoundry aumentó la velocidad de implementación de nuestros modelos en todos los equipos.
Preguntas frecuentes
¿Qué tipos de cargas de trabajo de IA puedo implementar con Unified AI Deployments?
¿Las implementaciones de IA unificada admiten el escalado automático?
¿Cómo funciona el apagado automático para las cargas de trabajo de IA?
¿Puedo implementar cargas de trabajo de IA en mi propio entorno?
¿Cómo se integran las implementaciones de IA unificadas con AI Gateway?

GenAI infra: simple, más rápido y más barato
Con la confianza de más de 30 empresas y empresas de Fortune 500








