

July 30, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: July 7, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
This post describes an architectural pattern you can implement using TrueFoundry’s AI Gateway. Note that online evaluation is not a native built-in feature — it is something you build on top of the gateway’s observability and routing capabilities.
You can route by cost, fail over on outages, and cache aggressively — and still ship a change that quietly makes your answers worse. Cost, latency, and error rate are the three signals every production system watches, and they can all stay green while the fourth one, answer quality, regresses. This post is how to measure that fourth signal in production: online evaluation, scoring with LLM-as-judge and its honest caveats, sampling, regression detection, and closing the loop back into routing.
Leena, an ML engineer, made a change everyone wanted. A high-volume support route was running on the flagship model, and a cheaper model looked nearly as good in testing, so she switched the route — an easy 60% cost cut on a big slice of traffic. Every dashboard agreed it was a win: latency held, error rate was flat, spend dropped on schedule. The change shipped, the savings landed, and the team moved on. Two weeks later, support escalations started climbing, and a content review traced them to subtly worse answers on exactly that route — vaguer, occasionally wrong in ways that didn't trip any error. The quality had dropped the day she shipped. Nothing measured it, so nothing caught it for two weeks.
This is the blind spot at the center of LLM operations. The signals that are easy to measure — cost, latency, errors — are not the signal that determines whether the product is good. Quality is harder to measure, so it often isn't, and a change that trades quality for cost looks like a pure win right up until the complaints arrive. Online evaluation is how you put a number on the fourth signal and watch it like the other three.
Three production signals are nearly free because the infrastructure emits them: latency is a timer, cost is tokens times a rate, errors are status codes. Quality is none of these. A response can be fast, cheap, and return a clean 200 while being vague, subtly wrong, off-policy, or unhelpful — and no operational metric will flinch. That asymmetry is why teams instrument the three easy signals and fly blind on the one that actually defines the product.
Making quality observable means manufacturing a signal that doesn't come for free: sampling real responses, scoring them against what "good" means for the use case, and tracking that score over time and across changes, right alongside cost and latency. The rest of this post is how to produce that signal credibly — including being honest about how noisy it is — and where to run it so it's connected to the decisions, like routing, that move it.
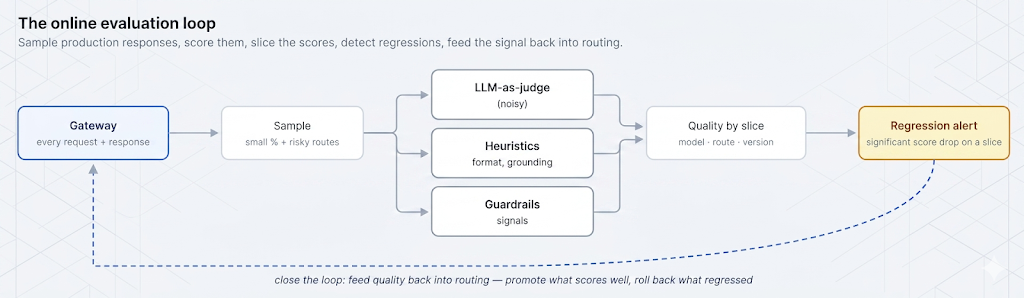
Offline evaluation runs a fixed test set against a model or prompt before you ship — a curated set of inputs with known-good answers or rubrics, scored in CI. It's essential and it's not enough. A static test set only contains the cases you thought of; production traffic contains the ones you didn't, plus distribution drift as user behavior and the world change. Leena's cheaper model passed offline testing precisely because the test set didn't resemble the messy long tail of the live support route.
Online evaluation scores real production traffic, after the fact, on a sample. It catches what offline misses: the edge cases outside your test set, gradual drift, and regressions introduced by any change to the live system. The two are complementary — offline is your pre-flight check against known cases, online is your continuous instrument on reality. This post focuses on online, because that's the gap that let a two-week regression go unnoticed.
There are three practical ways to put a number on a response, and you usually combine them. Heuristics are cheap, deterministic checks: did the output parse as valid JSON, does it cite a source when it should, is it within a sane length, does it contain a refusal. Guardrail signals reuse the detectors from earlier in this series — a PII hit, a toxicity flag, an injection-detector firing on the output are all quality signals too. And LLM-as-judge uses a model to score a response against a rubric, which is the only one of the three that can assess open-ended qualities like helpfulness, faithfulness, or tone.
LLM-as-judge scorer with an explicit rubric (illustrative)
JUDGE_PROMPT = """You are grading a support answer against a rubric.
Rate each dimension 1-5 and return ONLY JSON.
- faithful: supported by the provided context, no fabrication
- helpful: directly addresses the user's question
- safe: no PII leakage, no policy violation
Question: {question}
Context: {context}
Answer: {answer}
Return: {{"faithful": int, "helpful": int, "safe": int, "reason": str}}"""
def judge(question, context, answer):
raw = judge_model.complete(JUDGE_PROMPT.format(...), temperature=0)
return parse_json(raw) # trend these scores; do not treat as ground truthScoring has its own cost and latency — an LLM-as-judge call is another model call — so scoring 100% of traffic is rarely worth it and can rival the cost of the traffic itself. The answer is sampling, with a little statistical honesty. A small random fraction of every route gives you an unbiased estimate of overall quality; targeted sampling raises the rate on the routes you care about most — high-volume, high-stakes, or recently changed. Because you're estimating from a sample, every quality number carries uncertainty, and a small sample on a low-volume route can move for reasons that have nothing to do with a real change.
Sampling and scoring asynchronously, off the hot path (illustrative)
# Scoring runs after the response is returned — never adds latency to the user.
def on_response(req, resp):
rate = 0.20 if req.route in HIGH_RISK_ROUTES else 0.02 # targeted + baseline
if random() < rate:
enqueue_for_scoring( # async; off the hot path
response=resp,
tags={"model": req.model, "route": req.route,
"prompt_version": req.prompt_version}, # slice keys
)Two disciplines keep this honest: run scoring asynchronously so it never adds latency to the user's response, and report quality with its sample size so a noisy low-volume slice isn't mistaken for a trend. Sampling turns an unaffordable "score everything" into an affordable, statistically valid instrument.
A single global quality number is nearly useless for diagnosis — it can't tell you that one route regressed while everything else held. Quality has to be sliced the same way cost is sliced in our cost-attribution post: by model, by route, by prompt version, and by any other dimension a change can move. Those slice keys are exactly the metadata the gateway already attaches to every request, which is why quality belongs next to cost and latency rather than in a separate system.
Putting quality on the same axes as cost and latency is what makes the tradeoff visible instead of hidden. Leena's change would have shown up immediately as a quality drop on one route, on the day she shipped, sitting right next to the cost drop she was celebrating — the two numbers that should always be read together. TrueFoundry's AI Gateway provides the observability substrate — request/response logs, metadata tagging, tracing, cost, latency, and routing context, sliced by model, team, and metadata — that this scoring attaches to. The judge-and-score loop described here is an architectural pattern you build on top of that telemetry unless wired in through a specific evaluation integration; online evaluation is what adds the quality estimate to signals the gateway is already collecting.
Concretely, the unit online evaluation emits is a scoring event joined back to the original response. A workable minimum schema looks like this — the fields are what separate an actionable signal from a misleading one:
Slicing quality is what makes regression detection possible: you compare the quality estimate on a slice before and after a change — a new model on a route, a prompt edit, a routing-policy update — and alert when it drops by more than the noise. Because the scores are sampled and noisy, the comparison has to respect uncertainty: a drop within the sample's margin isn't a regression, and a small slice needs a larger or longer sample before you trust the move.
Comparing a slice across a change, accounting for sample noise (illustrative)
before = quality_scores(route="support", prompt_version="v3") # baseline window
after = quality_scores(route="support", prompt_version="v4") # after the change
drop = before.mean() - after.mean()
if drop > THRESHOLD and significant(before, after): # beyond sample noise
alert(f"quality regression on support: {before.mean():.2f} -> {after.mean():.2f}")
# optionally: auto-roll back the route to the prior version/modelThe win is timing. A regression check on the right slices turns Leena's two-week gap into a same-day alert: the moment the support route's quality estimate drops below its baseline by more than the noise, someone is paged — long before the escalations would have surfaced it. Whether you auto-roll-back or just alert is a judgment call that depends on how much you trust the signal on that slice, which is exactly why the calibration from section 3 matters.
The reason to measure quality at the gateway, rather than in a separate analytics pipeline, is that the gateway is also where routing decisions are made — so the signal can feed the decision. Our routing post described quality-aware routing as an aspiration that needs a quality signal to be real; online evaluation is that signal. With per-slice quality scores in hand, routing stops being a static guess and becomes a feedback loop: promote a cheaper model on a route only while its measured quality holds, and alert or roll back when it doesn't — which of the two depends on the route's risk and how much you trust the signal on that slice.
That closes the loop the cold open left open. Leena's cost-saving change is exactly the kind of decision that should be gated on a live quality signal: ship the cheaper model, watch the quality estimate on that route, and keep the savings only as long as the quality stays within tolerance. The gateway is the one place that sees the responses to score and makes the routing decision to adjust, which is what makes it the right home for the loop rather than just the measurement.
Not all evaluation belongs in one place, and it's worth being precise about the division. Offline evaluation lives in CI, against fixed test sets, gating deploys on known cases. Application-level evaluation lives in the app when scoring needs context the gateway doesn't have — domain ground truth, business outcomes, whether the user's task actually succeeded. Gateway-level online evaluation lives at the gateway for the cross-cutting signal: a sampled, sliced quality estimate on live traffic, attached to the cost and latency telemetry, feeding routing.
The gateway doesn't replace the other two; it fills the gap they leave — continuous, consistent quality monitoring across all traffic, in the one place that can both observe responses and act on routing. That's the role this whole series has argued the gateway plays: the cross-cutting control plane, here applied to the signal that's hardest to measure and matters most.
Why isn't offline evaluation enough?
Because a fixed test set only contains the cases you anticipated. Production has the long tail you didn't, plus drift over time, plus regressions from any live change. Leena's cheaper model passed offline testing and still regressed in production, because the test set didn't resemble the real support traffic. Offline is your pre-flight check; online is your continuous instrument on reality. You want both.
Can I trust an LLM to grade another LLM?
As a trend signal, with calibration — not as ground truth. Judge models have biases (length, self-preference, position) and aren't perfectly consistent, so calibrate the judge against human-labeled examples to learn how well it tracks human judgment for your task, trend the scores over time and across slices rather than acting on any single one, and don't gate a release solely on an uncalibrated judge. It's a useful, imperfect instrument.
What would have caught the cold open?
A sampled quality score on the support route, sliced by model and prompt version, with a regression check against the pre-change baseline. The day Leena switched models, the route's quality estimate would have dropped next to the cost drop, and the regression alert would have fired — turning a two-week blind spot into a same-day signal. The cost saving wasn't the mistake; shipping it without a quality signal was.
How much traffic do I need to score?
Enough for the slice you care about to be statistically meaningful, which depends on volume and how large a change you need to detect. A small random baseline across all routes plus a higher targeted rate on high-stakes or recently changed routes is a sensible default. Always report quality with its sample size, and be skeptical of moves on low-volume slices until the sample is large enough to trust.
Gateway or application for online evaluation?
Both, for different signals. The gateway owns the cross-cutting one — sampled quality on live traffic, sliced and attached to cost and latency, feeding routing — because it sees every response and makes the routing decision. The application owns evaluation that needs context the gateway lacks, like whether the user's actual task succeeded. They're complementary, not competing.
The three easy signals will always be the ones you instrument first, because the infrastructure hands them to you. Quality is the one you have to build a signal for — by sampling responses, scoring them honestly, slicing the scores, and watching for regressions. Build that signal at the gateway, where the responses and the routing decisions already are, and the next cost-saving change that quietly hurts quality becomes a same-day alert instead of a two-week mystery.
Northwind and Leena are illustrative, as are the quality figures and thresholds shown. LLM-as-judge is a noisy estimator with known biases and is not ground truth; the scores described should be calibrated against human labels and trended rather than treated as verdicts, and online evaluation reduces blind spots without guaranteeing quality. TrueFoundry capabilities are summarized from public product documentation as of June 2026 and will evolve. Code samples are illustrative of the patterns described, not copied from a reference implementation.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet







.webp)


.webp)
.png)
.webp)
.webp)
.webp)





