Built for Speed: ~10ms Latency, Even Under Load Blazingly fast way to build, track and deploy your models!
Handles 350+ RPS on just 1 vCPU — no tuning needed Production-ready with full enterprise support はじめに 先日開催したAIゲートウェイに関するウェビナーでは、まず参加者の皆様が生成AI(GenAI)の導入において現在どの段階にいらっしゃるかを確認しました。
興味深いことに、50%以上がすでにGenAIを本番環境で稼働させていると回答し、さらに15%が複数のチームでGenAIを拡張していると答えました。これは、企業におけるGenAIの導入が強力に進み、GenAIアプリケーションの展開が成熟しつつある明確な兆候です。 中央コントロールプレーンとしてのLLMゲートウェイの進化 私たちは、どのように AIゲートウェイが 過去6〜9ヶ月で、基本的なモデルルーティング層から、最新の生成AIスタックにおける重要な中央コントロールプレーンへと進化してきたか、に焦点を当てました。 当初、LLMは主にプロンプトに対する単一ターンの応答を生成するために使用され、その多くは高度な次単語予測器と見なされていました。 エージェントの現状 2025年まで早送りすると、LLMを搭載したエージェントは自律的かつ目標指向になり、舞台裏で複数のツールやシステムを呼び出すことが可能になりました。例えば、パスワードリセットエージェントは、ユーザーを認証し、APIを呼び出してパスワードをリセットし、確認メールを送信するといった一連の作業を、すべて人間の介入なしで行うことができます。組織の複雑性 企業はしばしば、複数のチームにまたがる数十もの複雑なエージェントを運用しており、さまざまなプロバイダー、フレームワーク、インフラストラクチャ(ハイパースケーラーやハイブリッドクラウドを含む)の多様なモデルを使用しています。一元化されていない場合の課題: この分散化は、モデルAPIの一貫性の欠如、デプロイの容易さ、監査可能性、コスト管理、フェイルオーバー戦略など、重大なガバナンス上の問題を引き起こします。LLMゲートウェイは、これら多様なリソースと運用ニーズを統合する中央ゲートウェイとして不可欠なものとなっており、大規模なガバナンス、可観測性、コスト管理、信頼性を可能にします。
VIDEO
スライドデッキはこちら こちら
複数のLLMプロバイダーを使用する企業が直面する課題 APIフォーマットの不統一 : OpenAI API互換性に関する一般的な主張にもかかわらず、プロバイダーはパラメータの構文(例:最大トークン数、温度範囲、停止シーケンス)が異なり、切り替えやすさや相互運用性を複雑にしています。頻繁な停止 : モデルプロバイダー自体がスタートアップであるため、頻繁なダウンタイムがアプリケーション障害を引き起こします。したがって、アプリケーションはモデルに依存せず、適切にフェイルオーバーできる必要があります。レイテンシーの大きな変動 : プロバイダー間のレイテンシーは大きく変動し、アプリケーションのパフォーマンスを予測不可能にしています。レイテンシーは、完全なダウンタイムと同様にユーザーエクスペリエンスに深刻な影響を与えます。複雑なレート制限 : プロバイダーごとに複数のレート制限があるため、事業部門やコストセンター全体でスロットリングとコスト管理が必要です。一元的な適用は困難ですが、不可欠です。ハイブリッドインフラストラクチャの要件 : 多くの企業は、クラウドプロバイダーとオンプレミスGPUインフラストラクチャ全体で、レート制限とキーローテーションを管理する必要があります。コストのかかる繰り返しクエリ : 生成AIアプリケーションは、同一または意味的に類似した多くのクエリ(例:挨拶メッセージ)を頻繁に受信するため、 生成AIのコスト が、によって軽減されない限り、不必要に増加します。 セマンティックキャッシュ 。ガードレールとコンプライアンス : 企業は、複数のチームとモデル全体で、プロンプトレベルの入力フィルタリング(例:PII漏洩の防止)と出力検証(不適切な表現のフィルタリング)を必要とし、一元的な適用が不可欠です。ガバナンスと監査要件 : 単一のUIアクション内でリクエストが複数のプロバイダーやデータソースにまたがる可能性があるため、企業はコンプライアンス要件を満たすために、一元化された可観測性、監査ログ、説明可能性、トレーサビリティを求めています。これらの課題は、 最適なLLMゲートウェイ が企業向け生成AIエコシステムにおけるコアとなるコントロールプレーンとしての役割の重要性を示しています。
AIゲートウェイの主要な機能と利点 AIゲートウェイ は、モデルへのアクセス、ガバナンス、信頼性を合理化するために設計された、さまざまな技術的機能を提供することで、これらの課題に対処する上で重要な役割を果たします。
主要なゲートウェイ機能:
統合APIレイヤー :プロバイダー固有の詳細や認証メカニズムを抽象化し、単一で一貫性のあるAPIインターフェースを提供します。これにより、以下が保証されます。 ベンダーロックインの回避。 コード変更なしでのプロバイダーのシームレスな切り替え。 開発者向けのSDK使用の簡素化。 一元化されたキー管理 :統合されたシステムを通じて、多様な認証方法(AWS IAMロール、OpenAI APIキー、GCP IDなど)を管理します。利点には以下が含まれます。 追跡可能性を確保するためのユーザーレベルでのAPIキー発行。 アプリケーション向けのサービスアカウントまたは仮想キー。 キーの簡単なローテーションと管理。 包括的なAPIキー共有を回避し、よりきめ細かな権限制御を可能にします。 リトライとコールバック : 自動フェイルオーバーポリシーにより、プロバイダーの障害を適切に処理します。あるモデルから別のモデルへの設定可能なフォールバックにより、アプリケーションコードに影響を与えることなく、サービスの中断を防ぎます。レート制限とコスト管理 : ユーザーごと、アプリケーションごと、または事業部門ごとにAPI使用ポリシーを厳密に適用できます。例: 開発者向けの1日あたりの呼び出し制限。 差別化されたクォータを持つプレミアムユーザー層。 無限ループを呼び出す暴走エージェントからの保護により、予期せぬ請求の急増を防ぎます。 ロードバランシング : リクエストをリアルタイムで最速または最も信頼性の高いモデルに自動的にルーティングし、レイテンシーベースのロードバランシングとヘルスチェックを実行します。新モデルのカナリアリリース : 新しいモデルバージョンの段階的で制御されたロールアウトを促進し、完全な移行の前にテストとパフォーマンス比較を可能にします。さまざまな種類のロードバランシング 一元的なガードレール : 全社的なプロンプトおよび応答フィルターを実装します。例: データを外部に送信する前のPII(個人識別情報)の削除。 応答内の不適切な表現や有害なコンテンツの検出と削除。 プロンプトを一元的にブロックまたは変更する機能。 透過的な統合により、アプリケーション開発者はこれらのルールを個別に管理する必要がありません。 セマンティックキャッシュ : 意味的に類似したプロンプトと応答のペアのキャッシュを維持し、モデル呼び出しを減らすことで、繰り返し行われるクエリに対するレイテンシーとコストを削減します。主なメリット
企業向けの強固な一元管理。 ダウンタイムなしでモデルやプロバイダーを即座に切り替えることが可能。 すべてのモデルインタラクションに対し、きめ細かなメトリクスで監査・監視可能なアクセス。 マルチモデルの複雑性を管理する上でのエンジニアリング工数の削減。 フェイルオーバーとレイテンシーの最適化によるユーザーエクスペリエンスの向上。 将来の展望:AI Gatewayとの連携によるMCPサーバーとの統合 将来的には、LLMゲートウェイはモデルの範囲を超え、MCPおよびA2Aプロトコルを介してツールやエージェント全体を管理するようになります。
MCPサーバーとは? MCPサーバーは、LLMベースのエージェントが発見し利用できる形式で、製品API(例:Slackチャンネル、メッセージ、ユーザー)を公開します。 例:Slack MCPサーバーは、LLMエージェントが理解できる形で、チャンネルの読み取り、メッセージの読み取り、メッセージの送信を行うAPIを公開します。 エージェントとMCPサーバーの連携: エージェントはMCPサーバーにクエリを実行し、利用可能なツールを特定します。 自然言語のリクエストに基づいて、エージェントは自律的にツールの正しいシーケンス(例:メッセージの取得、要約、Jiraタスクの作成)を計画し、呼び出します。 ゲートウェイとMCPの連携: ゲートウェイは、組織内のLLMモデルとMCPサーバーの両方にとって、統合アクセスポイントとして機能します。 ユーザーは、コーディングなしで、統合されたツール全体に対して自然言語コマンド(例:「Slackメッセージに基づいてJiraでタスクを作成」)を発行できるようになります。 認証は、OktaやAzure ADのような既存のIDプロバイダーを介してシームレスに管理・フェデレーションされます。 この統合により、非技術系ユーザーはビジネスプロセスを簡単に自動化できるようになります。 組織内のLLMモデルとMCPサーバーの統合アクセスポイント 詳細については、こちらの詳しいブログ記事をご覧ください。 MCPサーバーとAIゲートウェイ 。
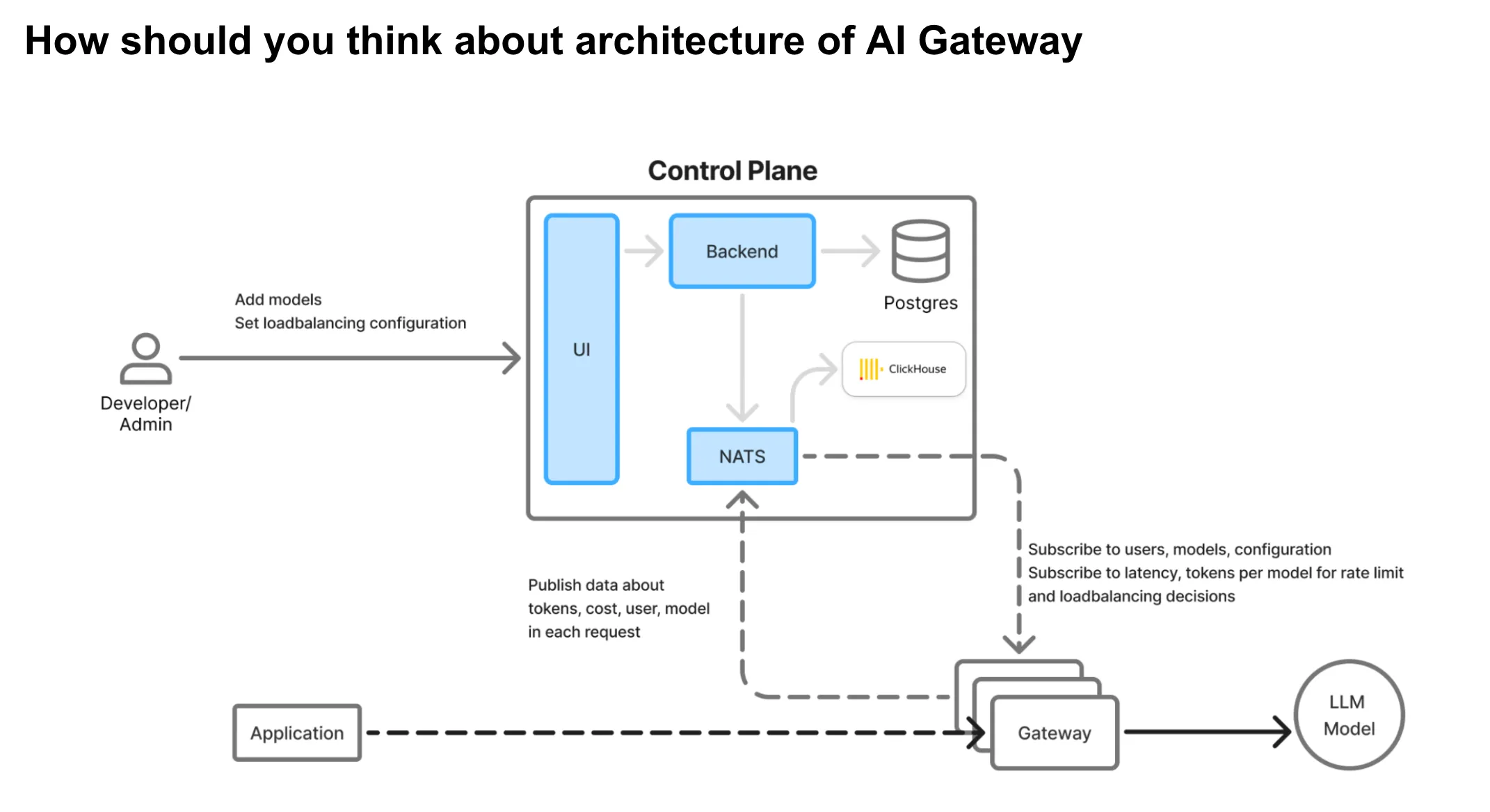
活用例: DatadogとGitHub APIデータを組み合わせてアラートを分析し、トリアージする。 複数のエンタープライズソフトウェアツールを活用し、定期的なワークフローをスケジュール設定する。 すべてのエージェントアクティビティとツール呼び出しに対する集中監査とガバナンス。 AIゲートウェイのアーキテクチャ AIゲートウェイは、アプリケーションと大規模言語モデル(LLM)プロバイダー間の重要なプロキシ層として機能します。ゲートウェイは 本番トラフィックのクリティカルパス上に位置するため 、以下のコア原則を念頭に置いて設計する必要があります。
主要なアーキテクチャ上の優先事項: 高可用性: ゲートウェイは単一障害点となってはなりません。データベースやキューの停止などの依存関係の問題が発生した場合でも、適切にトラフィックを処理し続ける必要があります。低レイテンシー: すべての推論リクエストとインラインで連携するため、ゲートウェイは 最小限のオーバーヘッド を追加し、迅速なユーザーエクスペリエンスを確保する必要があります。高スループットとスケーラビリティ: システムは負荷に応じて線形にスケーリングし、効率的なリソース使用で数千の同時リクエストを処理できる必要があります。ホットパスにおける外部依存の排除: ネットワークまたはディスクに依存する処理は、パフォーマンスのボトルネックを防ぐため、非同期システムにオフロードする必要があります。インメモリでの意思決定: 重要なチェックは、 レート制限 、 負荷分散 、 認証 、および 認可 のように、最大限の速度と信頼性を得るためにすべてインメモリで実行される必要があります。コントロールプレーンとプロキシプレーンの分離: 設定変更とシステム管理は、ライブトラフィックルーティングから分離し、地域ごとの障害分離を伴うグローバルデプロイメントを可能にする必要があります。TrueFoundryのAI Gatewayは、低レイテンシー、高信頼性、シームレスなスケーラビリティを実現するために特別に構築されており、上記の設計原則をすべて具現化しています。
TrueFoundryのAI Gatewayアーキテクチャ Honoフレームワークを基盤に構築: このゲートウェイは Hono 、エッジ環境向けに最適化されたミニマルで超高速なフレームワークを活用しています。これにより、最小限のランタイムオーバーヘッドと非常に高速なリクエスト処理が保証されます。リクエストパスでの外部呼び出しなし: リクエストがゲートウェイに到達すると、外部呼び出しは一切発生しません(セマンティックキャッシュが有効な場合を除く)。すべての運用ロジックは内部で処理され、リスクを低減し、信頼性を向上させます。インメモリでの処理: すべての認証、認可、レート制限、ロードバランシングの決定はインメモリ構成を使用して行われ、サブミリ秒の応答時間を保証します。非同期ロギング: ログとリクエストメトリクスはメッセージキューに非同期でプッシュされ、データ可観測性がリクエストパスをブロックしたり遅延させたりしないようにします。フェイルセーフ動作: 外部ロギングキューがダウンしても、ゲートウェイはリクエストを失敗させません。これにより、部分的なシステム障害時でも稼働時間と回復力が保証されます。水平スケーラブル: ゲートウェイはCPUバウンドでステートレスであるため、スケールアウトが容易です。高い同時実行性と低いメモリ使用量で効率的に動作します。True FoundryのAIゲートウェイ マルチプロバイダー対応: AWS、GCP、OpenAI、Anthropic、DeepInfra、およびカスタム/セルフホスト型オプションからモデルを簡単に追加および管理できます。 統合プレイグラウンド: 1つのインターフェースを通じて、任意のモデルに対してプロンプトをテストおよび実行できます。APIキーとモデル名は、コード変更なしで設定可能です。 ガードレールによるプロンプト管理: プロンプト送信中の機密データのリアルタイム編集を表示し、一元化されたガードレールサーバーと統合されています。 詳細なメトリクスと可観測性: 誰がどのモデルを呼び出しているかをリアルタイムで追跡。 詳細なレイテンシ統計(「最初のトークンまでの時間」や「トークン間レイテンシ」など、LLMのパフォーマンス監視に不可欠)。 レート制限、フォールバック、ガードレールトリガーの統計。 すべてのリクエストとレスポンスのペアの監査ログ(コンプライアンスのためにエクスポート可能)。 設定可能な管理者設定: 開発者またはチームごとにレート制限を定義し、フォールバックポリシー、レイテンシベースのルーティングを設定し、ガードレールを一元的に管理します。 MCPサーバー統合ロードマップ:Gmail、Slack、Confluence、Jira、GitHub、カスタムAPIなどのツール向けに、すべての社内MCPサーバーをサポートする今後の機能のプレビュー。 ライブQ&A:スケーラビリティ、統合、技術的な質問への対応 セッションの最後には、参加者からの質疑応答が行われ、以下の内容がカバーされます:
ゲートウェイのスケーラビリティ :水平スケーラブルに設計されており、パフォーマンスベンチマークでは、1つのCPUで毎秒350リクエスト(RPS)を処理できることが示されています。より高いレートにはスケールアウト展開が必要です。レイテンシと安定性:ゲートウェイは、信頼性を高めるためのコールバックおよび再試行メカニズムを提供し、プロバイダーが停止した場合に自動的にモデルを切り替えます。 モデルの入力サイズ制限:モデルは非常に大きな入力(例:500MB)を処理できません。検索拡張生成(RAG)システムの使用が推奨されます。 フレームワーク統合:LangChain、LangGraphなどの主要なエージェント構築フレームワークと互換性があり、特殊なSDKを必要とせず、標準のOpenAI互換APIを使用します。 プログラミング言語のサポート:ゲートウェイは、高性能で軽量なフレームワーク(Hono、Cloudflare Workersで使用されているものと同様)を使用して構築されており、APIクライアント(Python、JavaScript、Goなど)に対して言語に依存しません。 新しいモデルAPIへの迅速な適応:ベンダー固有のパラメータとマルチモーダル入力をサポートするための継続的な更新が、厳格なドキュメントとともに提供されます。 ガバナンスおよび監査ツール:ガバナンスのニーズに合わせた監査のために、詳細なレイテンシ、使用状況、コストデータをエクスポートする機能。 お問い合わせは support@truefoundry.com にて詳細なデモをご依頼いただくか、 デモを予約する を本日ご予約ください。
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
Built for Speed: ~10ms Latency, Even Under Load


































.webp)




.png)








.webp)
.webp)


