











LLM
オープンソースまたはプロプライエタリなLLMを、GPUアクセラレーションと本番環境レベルの信頼性でデプロイし、提供。
エージェント
メモリ、ツール実行機能を備え、AI GatewayおよびMCPサーバーとシームレスに統合された、長時間稼働するAIエージェントを実行。
MCPサーバー
ツール、API、エンタープライズシステムをAIエージェントに安全に公開するため、MCPサーバーをデプロイ。
ワークフロー
モデル、エージェント、サービスにわたる多段階のAIワークフローを、単一のコントロールプレーンからオーケストレーション。
ジョブ
バッチジョブ、トレーニングワークロード、スケジュールされたAIタスクをオンデマンドで実行。
従来のMLモデル
従来の機械学習モデルとLLMを同じプラットフォームでデプロイし、提供。
.webp)
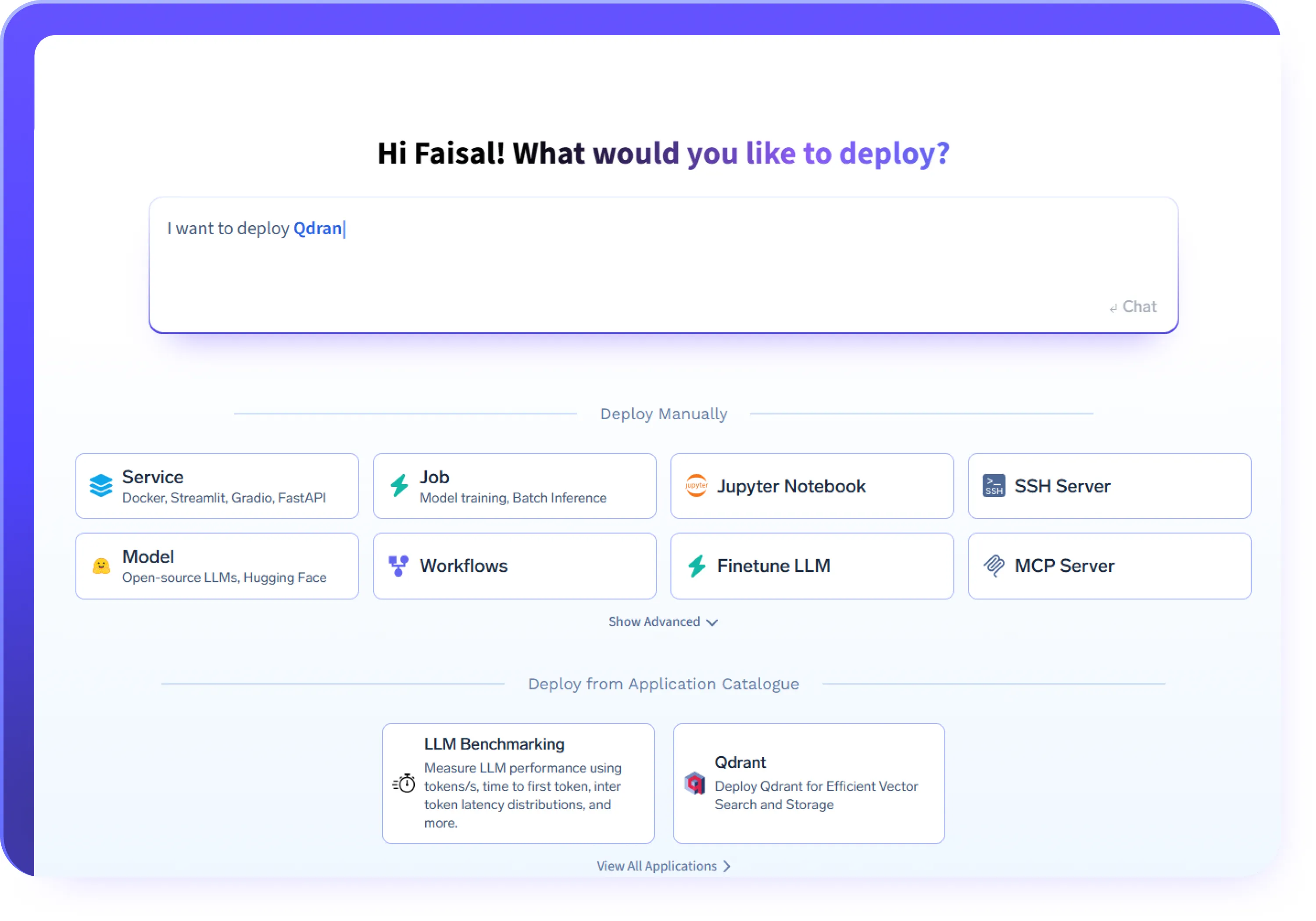
あらゆるAIワークロードをデプロイ
- LLMやGPUベースの推論ワークロードを、vLLM、Triton、KServeなどのフレームワークやカスタムコンテナを使ってデプロイ
- 一貫したランタイムとネットワークでAIエージェントとエージェントサービスをデプロイする
- ツールや内部システムを安全に公開するためにMCPサーバーをデプロイする
- バッチジョブ、API、および長時間実行されるAIサービスを同じプラットフォームで実行する
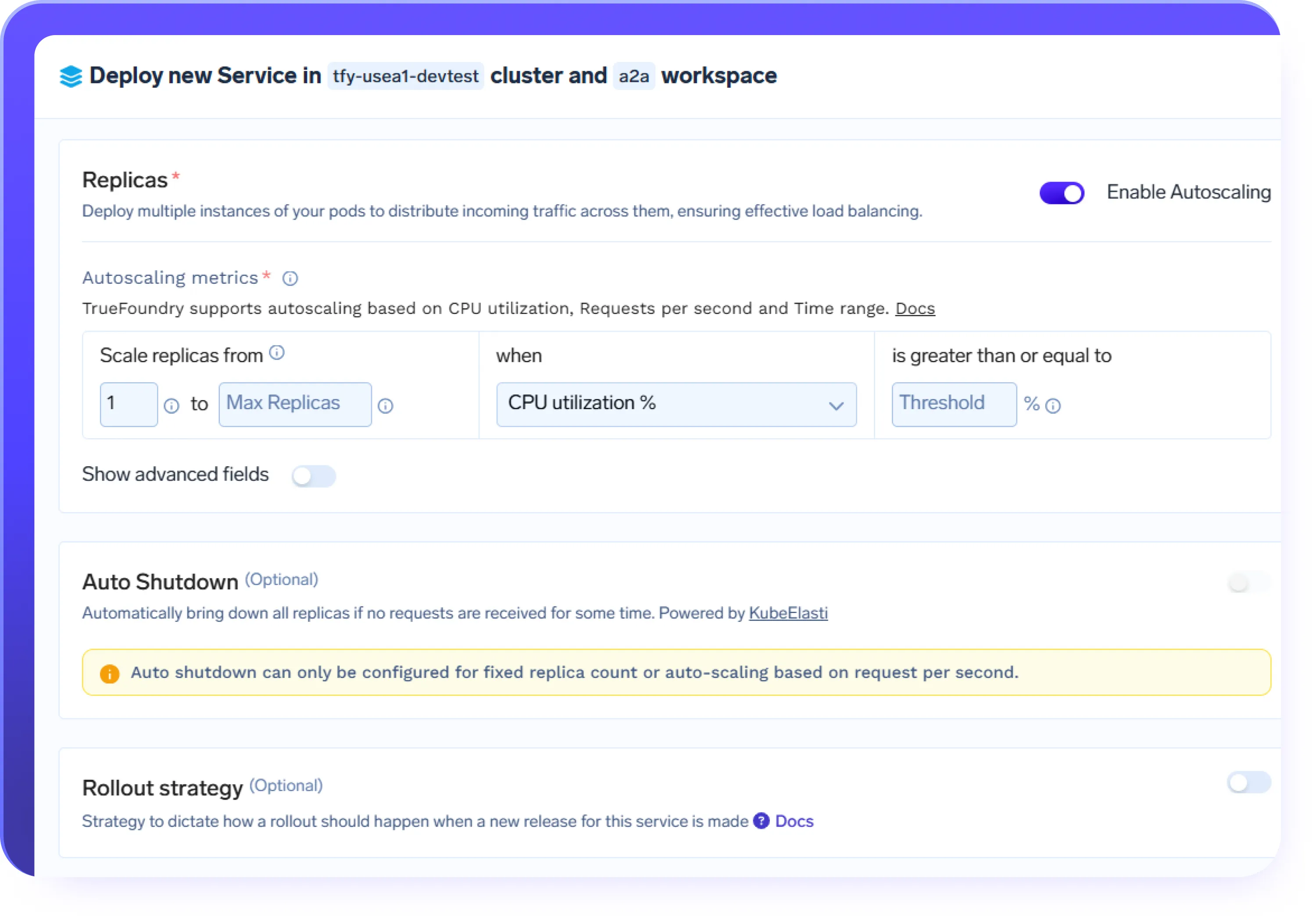
AIワークロードの自動スケーリング
- リクエスト量に基づいて推論エンドポイントとエージェントサービスを自動的にスケーリングする
- ピーク需要時にはGPUワークロードをスケールアップし、トラフィックが減少したらスケールダウンする
- チャット、RAG、エージェント駆動型ワークフローなどのバースト性の高いワークロードをサポートする
- トラフィックの急増時でも予測可能なパフォーマンスを維持する
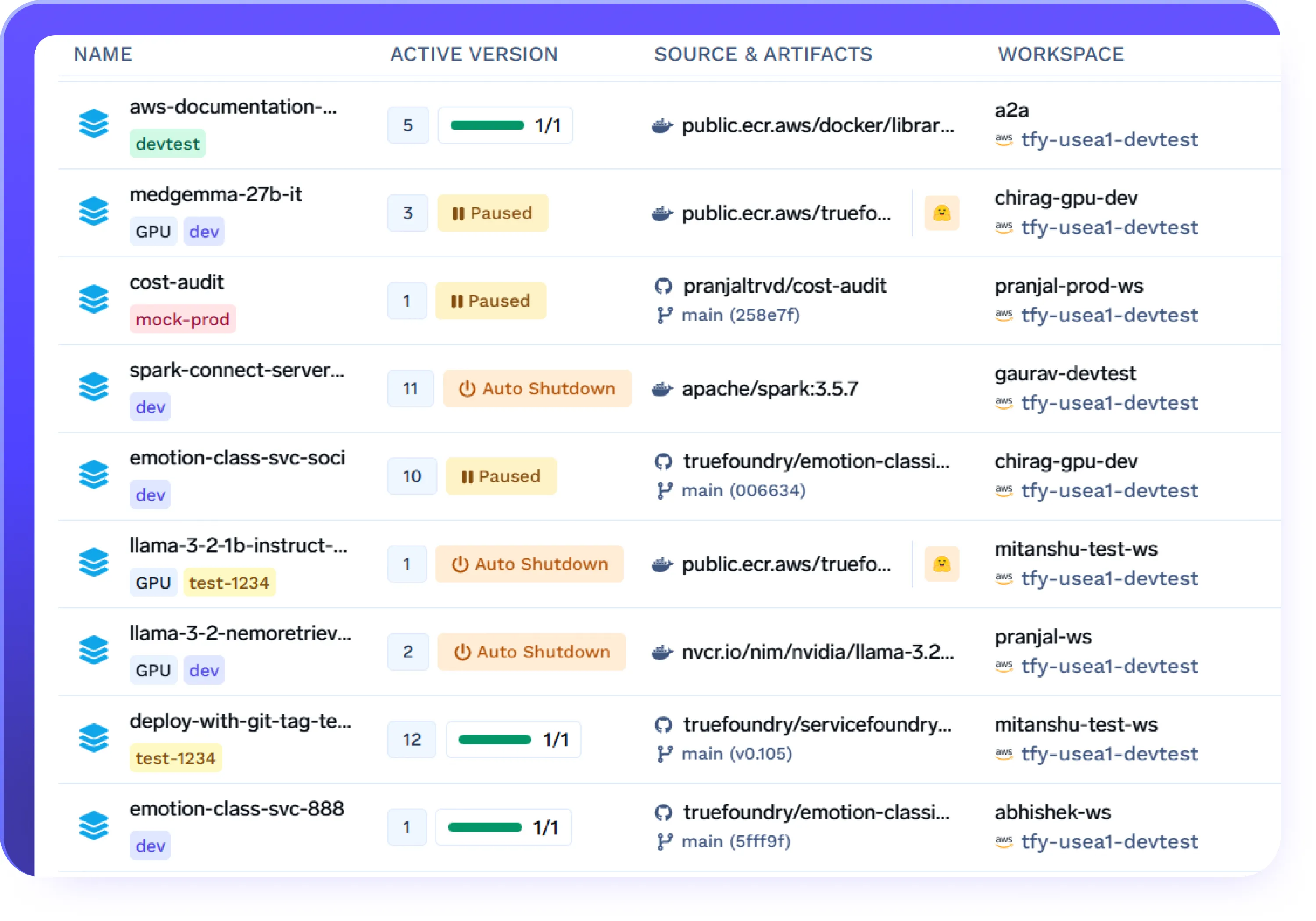
コストを抑えるための自動シャットダウン
- 設定可能なアイドル期間後にエンドポイント、エージェント、またはサービスを自動的にシャットダウンする
- オフピーク時や実験中のGPUの無駄を削減する
- 手動介入なしでオンデマンドにワークロードを再起動する
- チームや環境全体でコスト規律を徹底する
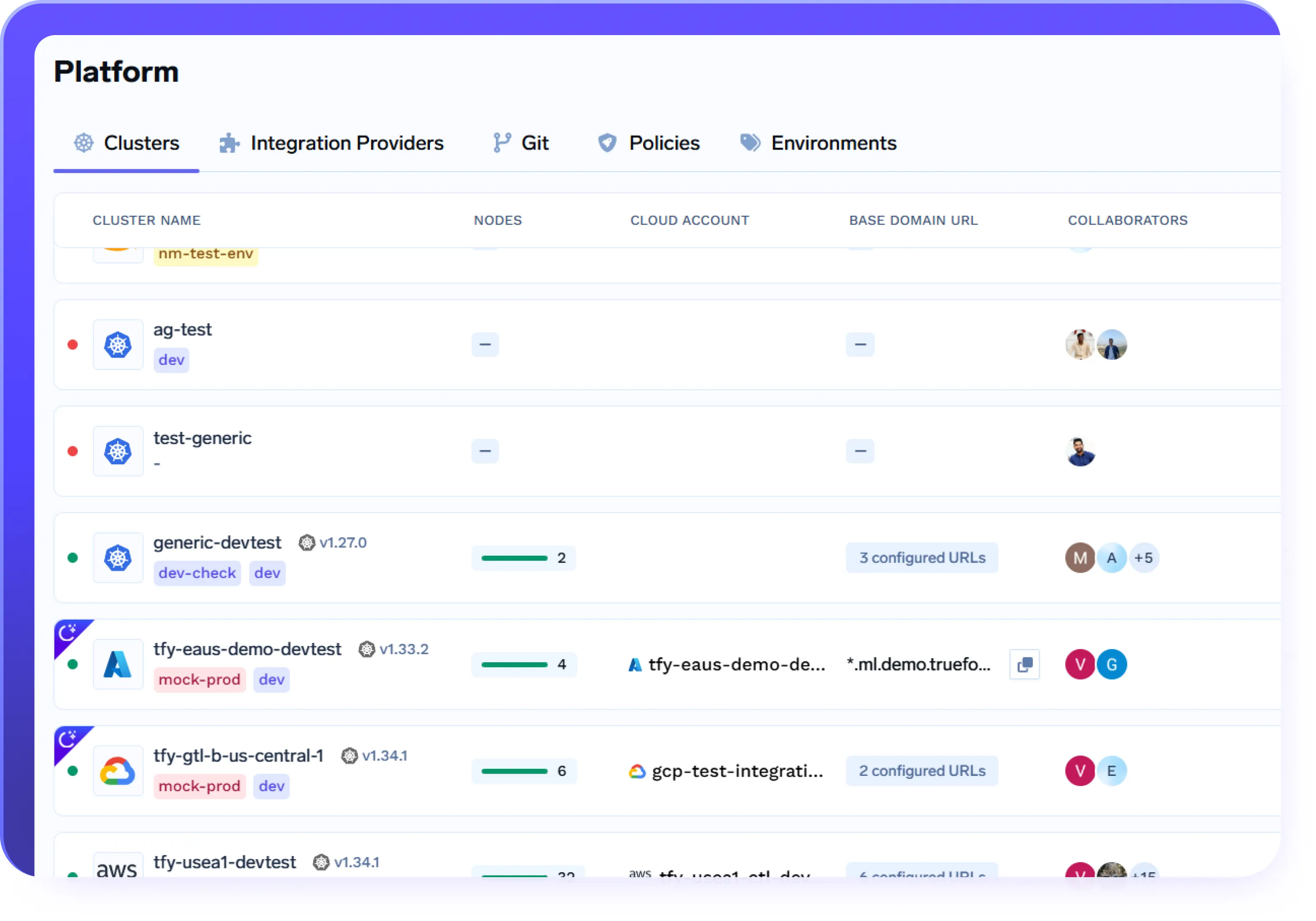
Unified Deployment Experience Across Cloud/Onprem
- Connect and manage AWS, Azure, GCP, and on-prem clusters from a single control plane
- Deploy the same workload to different environments using identical workflows and APIs
- Abstract away cloud-specific complexity while retaining full control and isolation
- Use the same deployment experience across dev, staging, and production, regardless of infrastructure
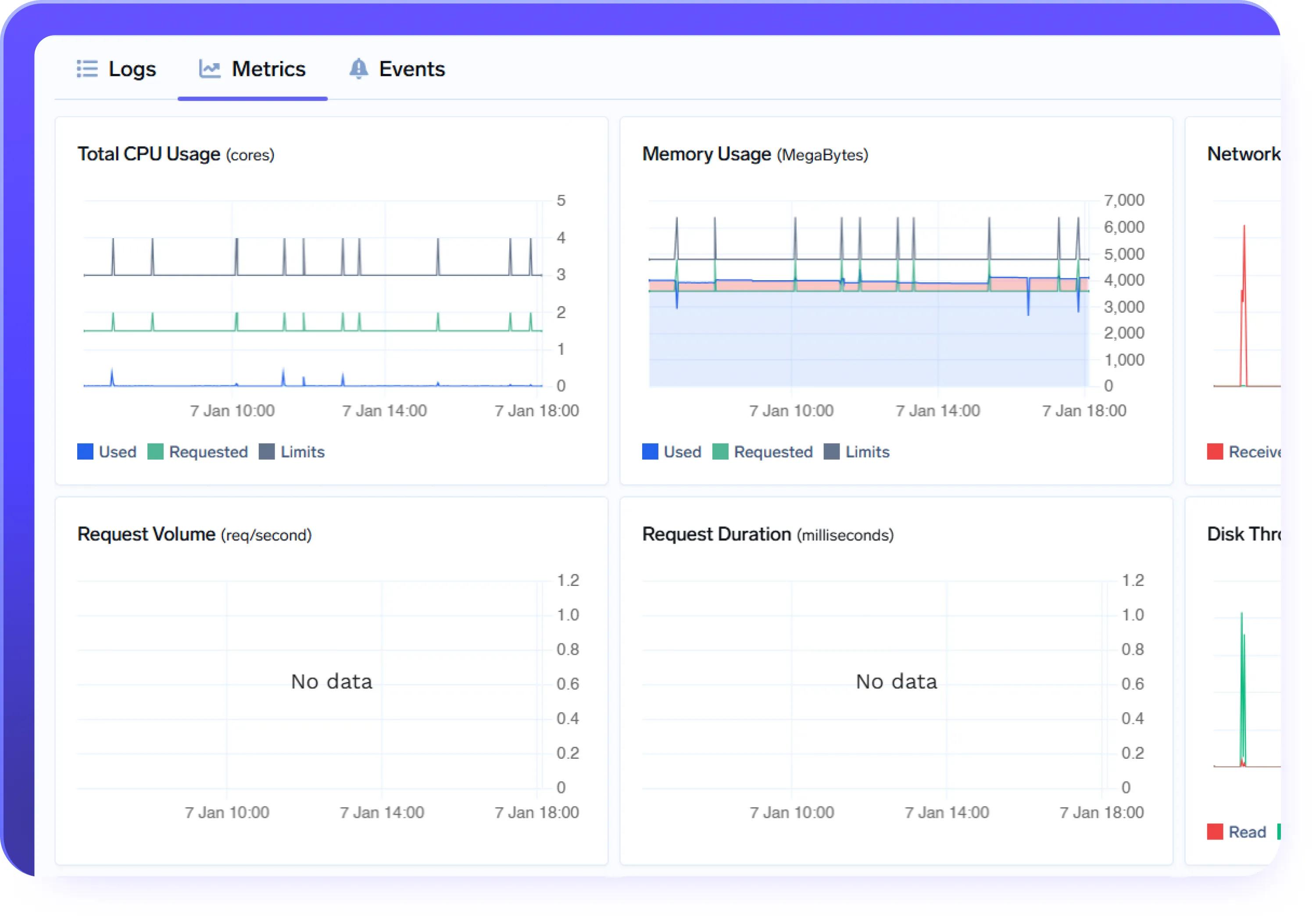
Built for a First-Class Developer Experience
- Integrated logs, metrics, and events for every deployment
- Native monitoring and alerting to quickly detect and resolve issues
- Production-ready deployment features like health checks and rollout strategies
- Secure secret management and seamless CI/CD integrations
Works Seamlessly with AI Gateway & Agent Gateway
above it.
- AI Gateway governs model access, routing, and cost controls
- MCP Gateway governs tool access and execution
- Agent Gateway orchestrates and governs agent workflows
- Unified AI Deployments power the actual execution and infrastructure
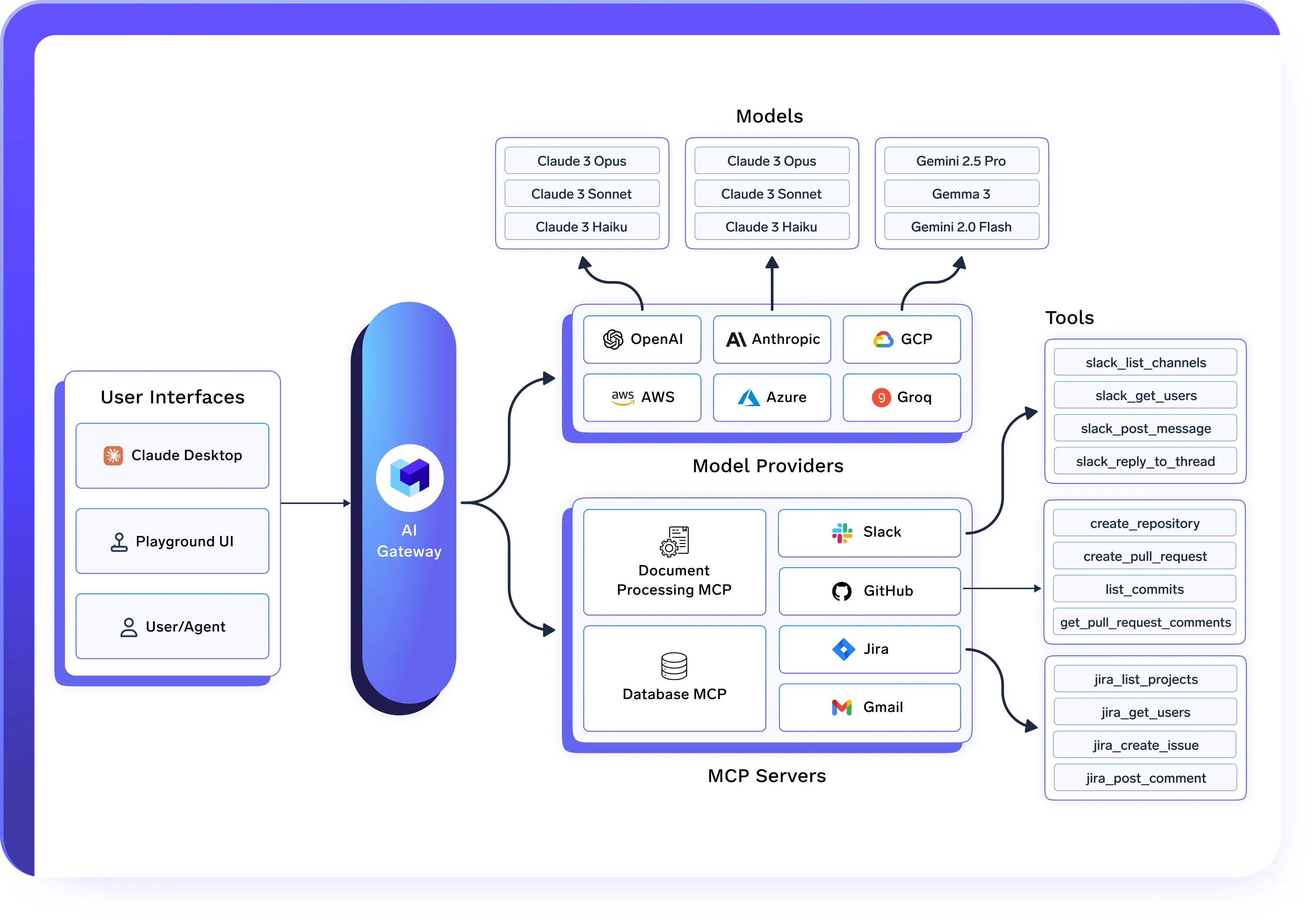
Made for Real-World AI at Scale
エンタープライズ対応
データとモデルをクラウド/オンプレミスインフラ内に保持する、セキュアなAIゲートウェイを導入。


コンプライアンスとセキュリティ
SOC 2、HIPAA、GDPRの各標準により、堅牢なデータ保護を確実にするガバナンスとアクセス制御
SSOとロールベースアクセス制御(RBAC)および監査ログエンタープライズサポートと信頼性
SLAに基づいた応答SLAを含む24時間年中無休サポート
VPC, on-prem, air-gapped, or across multiple clouds.
No data leaves your domain. Enjoy complete sovereignty, isolation, and enterprise-grade compliance wherever TrueFoundry runs

.avif)
Real Outcomes at TrueFoundry
Why Enterprises Choose TrueFoundry






3x
faster time to value with autonomous LLM agents
80%
higher GPU‑cluster utilization after automated agent optimization

Aaron Erickson
Founder, Applied AI Lab
TrueFoundry turned our GPU fleet into an autonomous, self‑optimizing engine - driving 80 % more utilization and saving us millions in idle compute.
5x
faster time to productionize internal AI/ML platform
50%
lower cloud spend after migrating workloads to TrueFoundry

Pratik Agrawal
Sr. Director, Data Science & AI Innovation
TrueFoundry helped us move from experimentation to production in record time. What would've taken over a year was done in months - with better dev adoption.
80%
reduction in time-to-production for models
35%
cloud cost savings compared to the previous SageMaker setup
.webp)
Vibhas Gejji
Staff ML Engineer
We cut DevOps burden and simplified production rollouts across teams. TrueFoundry accelerated ML delivery with infra that scales from experiments to robust services.
50%
faster RAG/Agent stack deployment
60%
reduction in maintenance overhead for RAG/agent pipelines
.webp)
Indroneel G.
Intelligent Process Leader
TrueFoundry helped us deploy a full RAG stack - including pipelines, vector DBs, APIs, and UI—twice as fast with full control over self-hosted infrastructure.
60%
faster AI deployments
~40-50%
Effective Cost reduction of across dev environments
.webp)
Nilav Ghosh
Senior Director, AI
With TrueFoundry, we reduced deployment timelines by over half and lowered infrastructure overhead through a unified MLOps interface—accelerating value delivery.
<2
weeks to migrate all production models
75%
reduction in data‑science coordination time, accelerating model updates and feature rollouts
.webp)
Rajat Bansal
CTO
We saved big on infra costs and cut DS coordination time by 75%. TrueFoundry boosted our model deployment velocity across teams.
Frequently asked questions
What types of AI workloads can I deploy with Unified AI Deployments?
Does Unified AI Deployments support autoscaling?
How does auto-shutdown work for AI workloads?
Can I deploy AI workloads in my own environment?
How does Unified AI Deployments integrate with AI Gateway?

GenAI infra- simple, faster, cheaper
Trusted by 30+ enterprises and Fortune 500 companies








