











どんなモデルでもファインチューニング
Hugging Faceの統合機能と本番環境対応テンプレートを使用して、LLMと従来のMLモデルをファインチューニングします
ノーコードまたはフルコードのファインチューニング
ノーコードUIですばやく開始するか、完全な制御と柔軟性のために独自のトレーニングスクリプトを持ち込むことができます。
PEFTとフルファインチューニング
コスト、メモリ使用量、モデル性能のバランスを取るために、LoRA、QLoRA、およびフルファインチューニングをサポートします。
チェックポイントとバージョン管理
実行を自動的にチェックポイントし、トレーニングを再開し、再現性のためにモデルとデータセットをバージョン管理します。
組み込みの実験トラッキング
ファインチューニングの実行全体で、ハイパーパラメータ、メトリクス、データセット、出力を追跡します。
アダプター管理
LoRAアダプターをトレーニング、再利用、マージ、切り替えることで、ファインチューニングを高速化し、コストを削減します。
.webp)
あらゆるHugging Faceモデル / 従来のMLモデルをファインチューニング
- LLaMA、Mistral、BERT、Falcon、GPT-JなどのLLMのファインチューニングに対応
- 内蔵のHugging Faceモデルハブを使用して、数分でLLMのファインチューニングを開始できます
- 事前設定されたテンプレートにより、大規模言語モデルのファインチューニングプロセスが簡素化されます
- 小規模な実験から本番環境レベルのLLMファインチューニングまで、スケーラブルなインフラがすべてを処理します
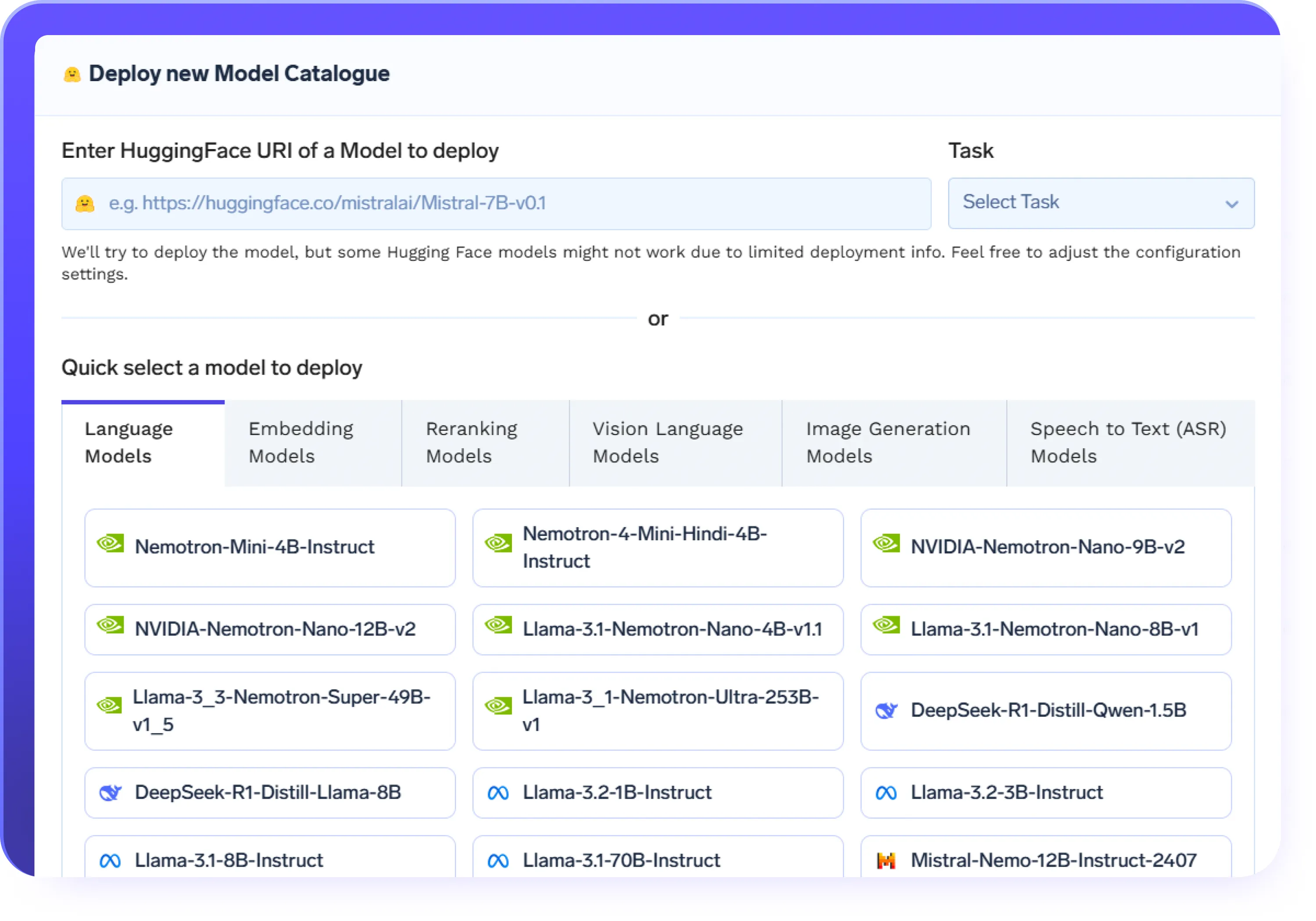
ノーコードかフルコードか — 選択はあなた次第
- 迅速なセットアップと高速なイテレーションを実現するノーコードUIでLLMをファインチューニング
- コードモードで完全に制御しながら、独自のトレーニングスクリプトを持ち込む
- インフラストラクチャとリソースのスケーリングを自動的に管理
- 組み込みのログ、メトリクス、バージョン管理により、各ファインチューニング実行の完全な透明性を確保。
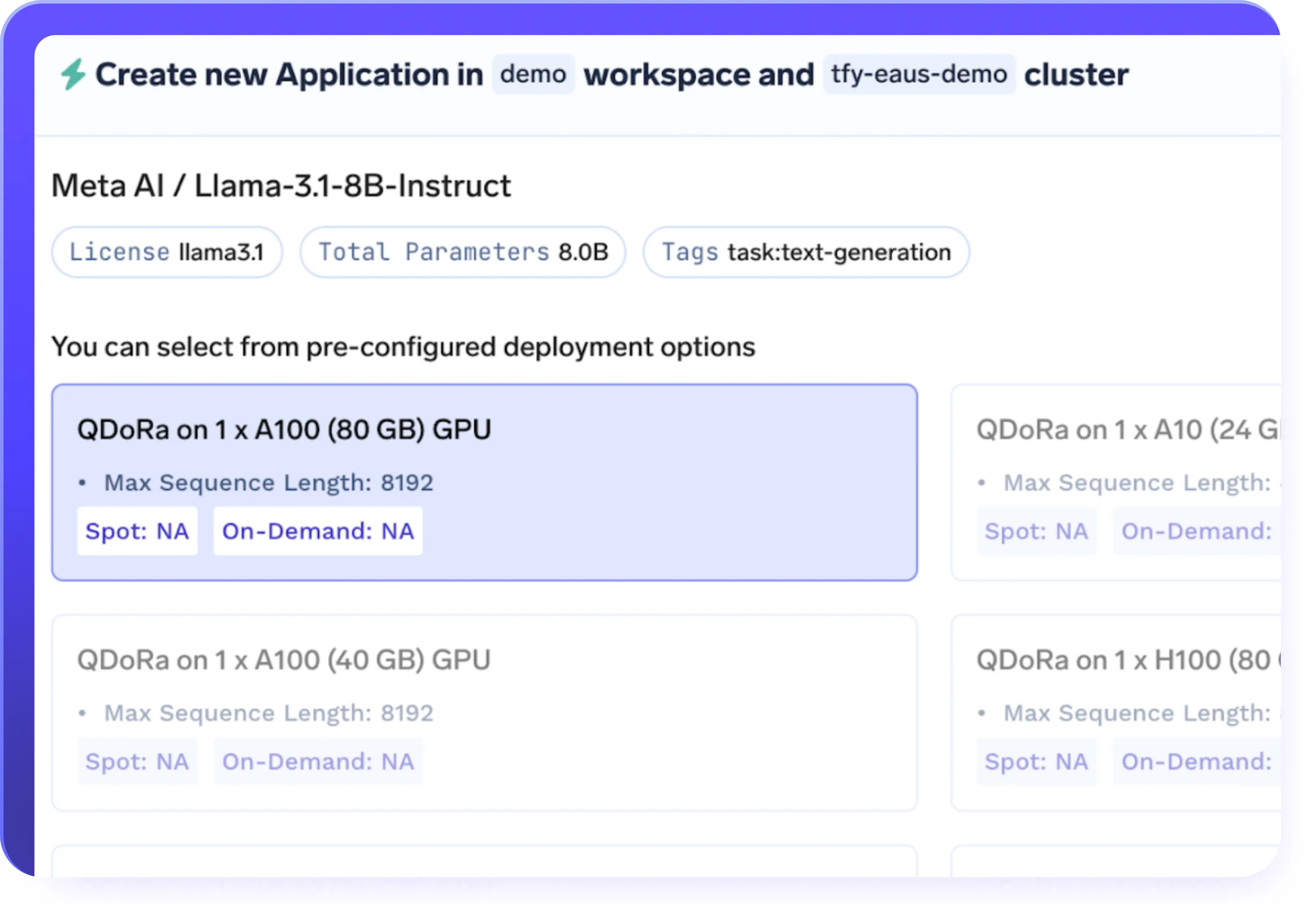
PEFT(LoRA / QLoRA)およびフルファインチューニングのサポート
- パラメータ効率の良いファインチューニング(LoRA、QLoRA)およびフルモデルファインチューニングをサポート
- 大規模LLMのより高速で費用対効果の高いファインチューニングのために、LoRAまたはQLoRAを選択
- モデルの品質とパフォーマンスを維持しながら、GPUメモリ使用量を削減
- モデルサイズ、コスト、ワークロードのニーズに基づいて、適切なファインチューニングアプローチを選択
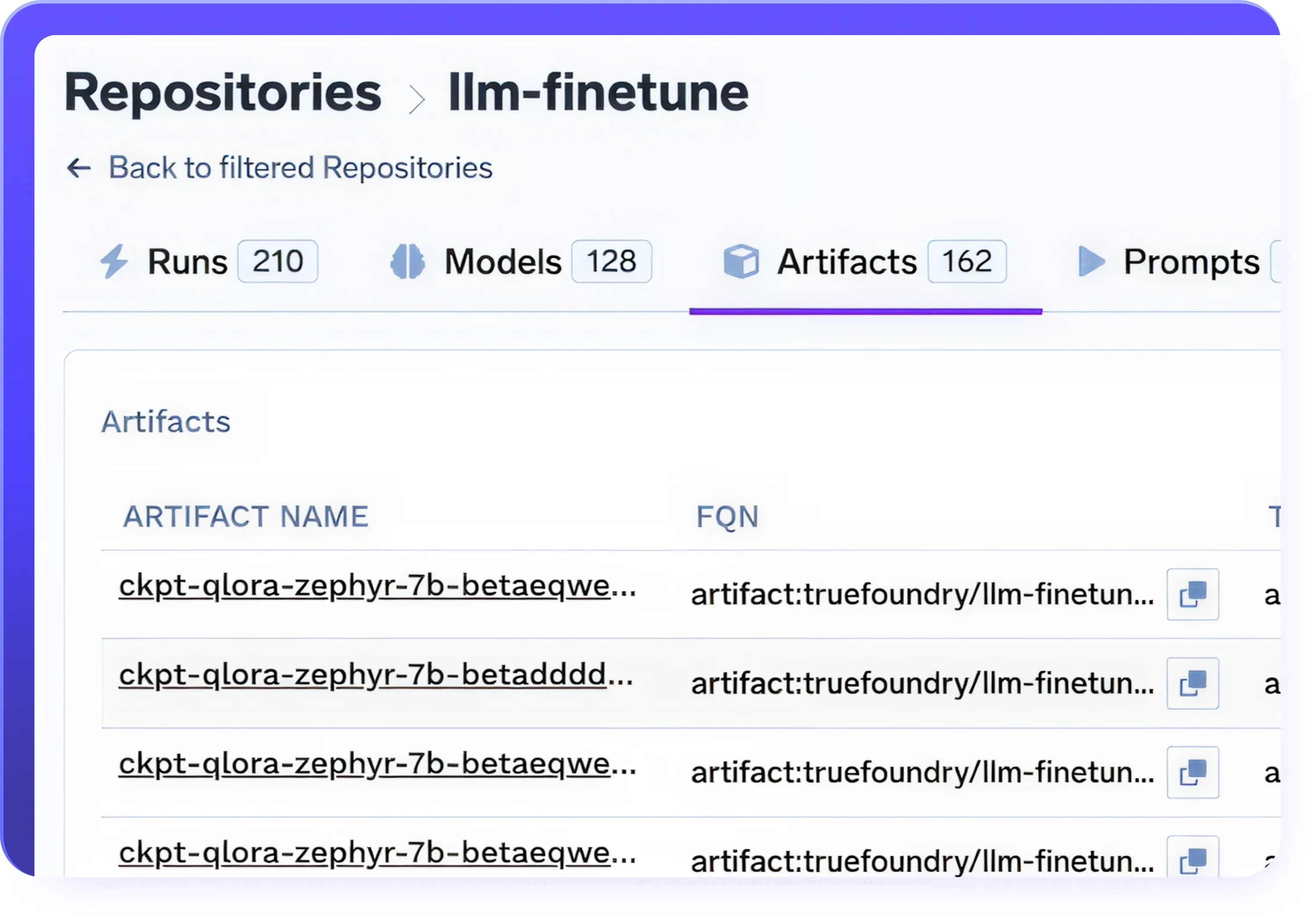
チェックポイント管理とバージョン管理
- ファインチューニング中にチェックポイントを自動的に保存し、トレーニングの進行状況の損失を防ぐ
- 中断または一時停止されたファインチューニングジョブを任意のチェックポイントから再開
- 完全な再現性のために、モデル、データセット、トレーニング実行をバージョン管理
- 以前のチェックポイントにロールバックし、バージョン間でパフォーマンスを比較
組み込みの実験追跡
- すべてのトレーニングメタデータ(ハイパーパラメーター、メトリクス、データセット、出力)を自動ログ
- 複数の実行を比較して、LLMをより効果的にファインチューニングします
- お使いのLLMopsスタックと統合するか、当社のネイティブビジュアルインターフェースをご利用ください
- 組み込みのバージョン管理により、再現性と監査可能性が保証されます
効率的なLLMファインチューニングのためのアダプター管理
- わずかなパラメーターセットのみを更新することで、LoRAアダプターを活用してモデルをファインチューニングします。
- プロジェクトやドメインを超えて事前学習済みアダプターを再利用
- 異なるタスク間でアダプターをマージまたは切り替えることで、迅速な実験とモジュール式のモデル設計が可能になります
- 完全なLLMウェイトの代わりにコンパクトなアダプターモジュールをトレーニングすることで、トレーニングを高速化し、コストを削減
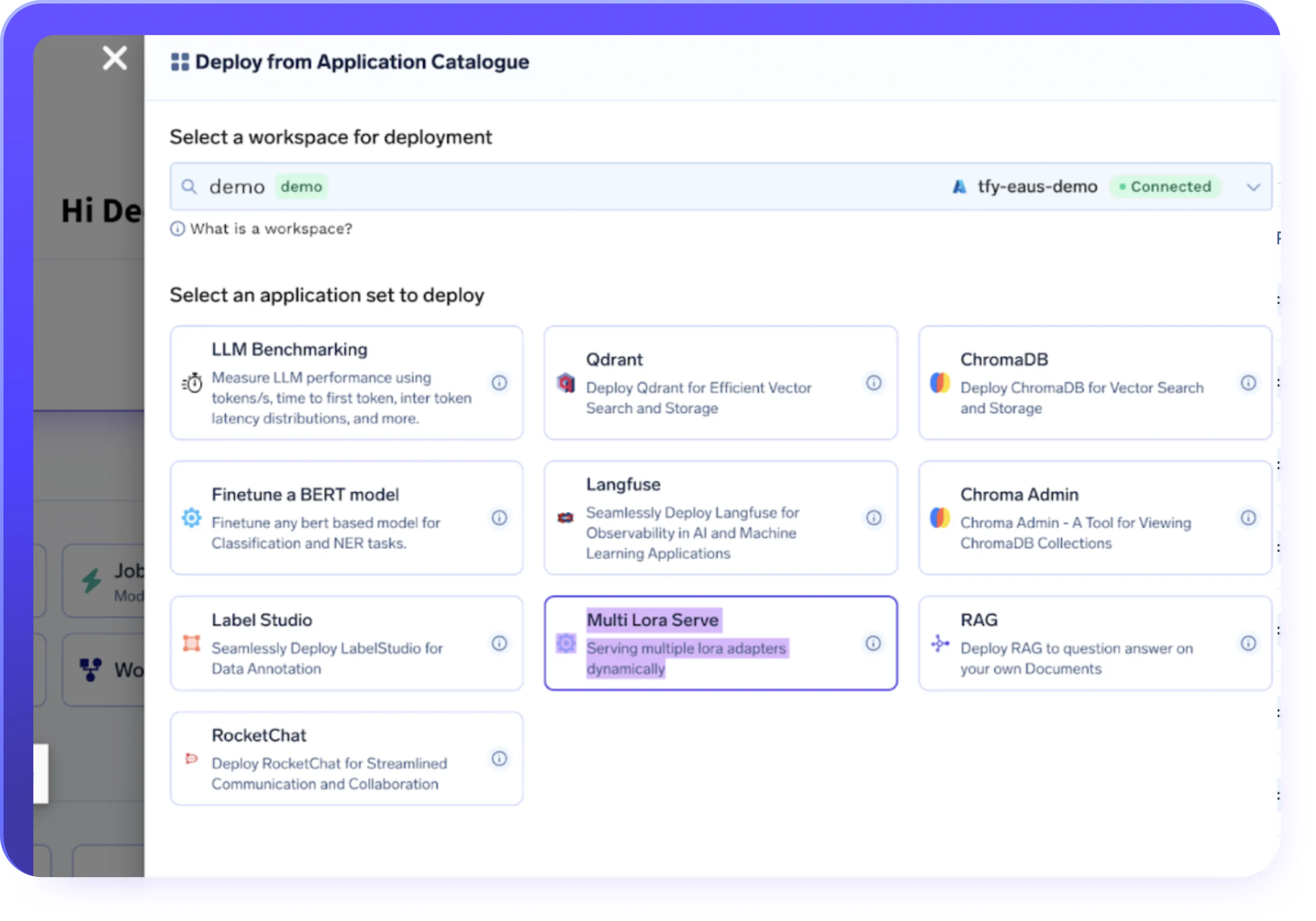
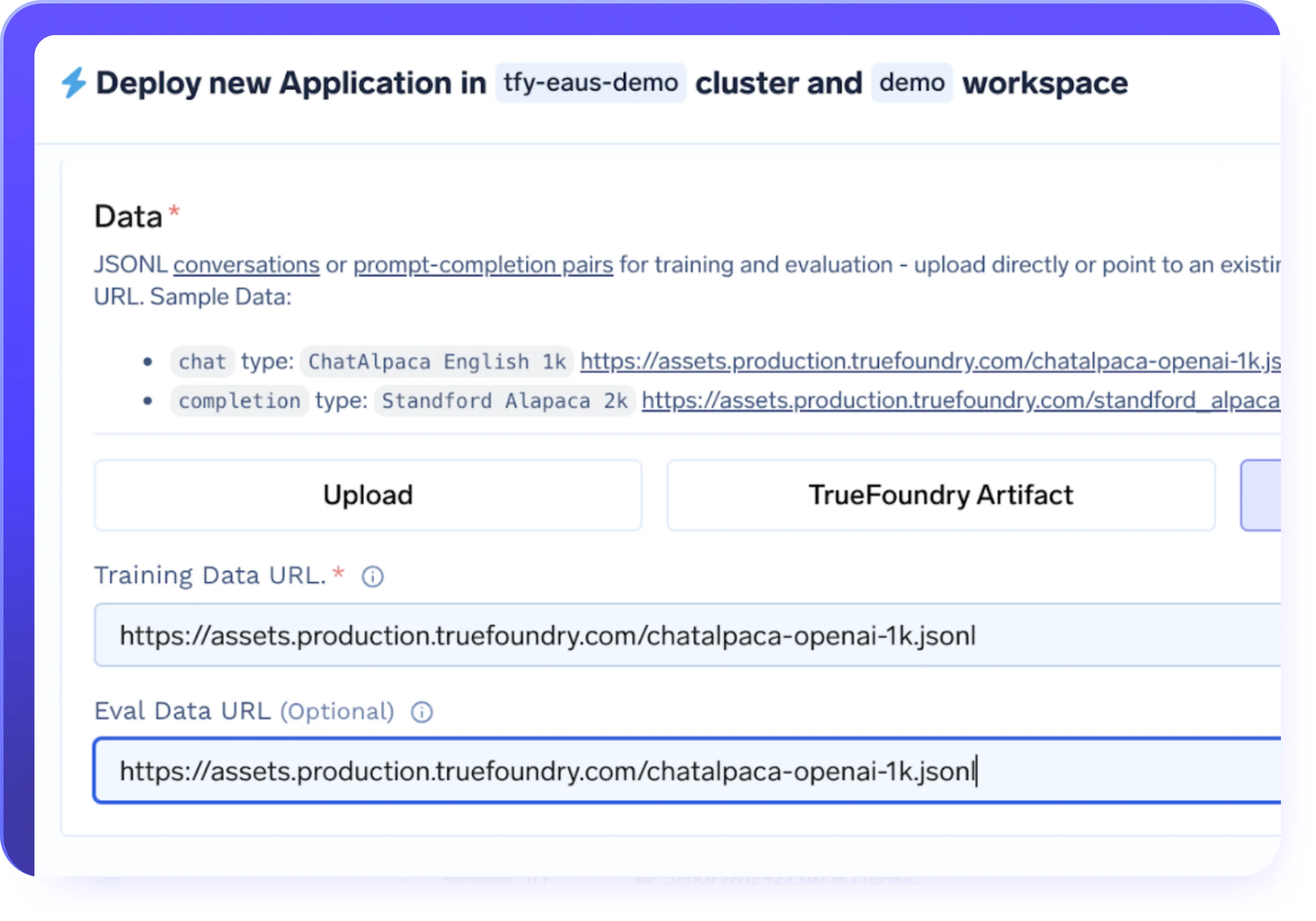
データとインフラの統合
- S3、GCS、Azure Blob、またはHugging Face Datasetsからデータセットをインポート
- フルマネージドインフラストラクチャまたは独自のクラスターでファインチューニングジョブを実行
- クラウド、ハイブリッド、オンプレミス環境にわたってワークロードをデプロイ
- GPUオートスケーリング、タイムスライシング、コスト効率の良いプロビジョニングをデフォルトで使用
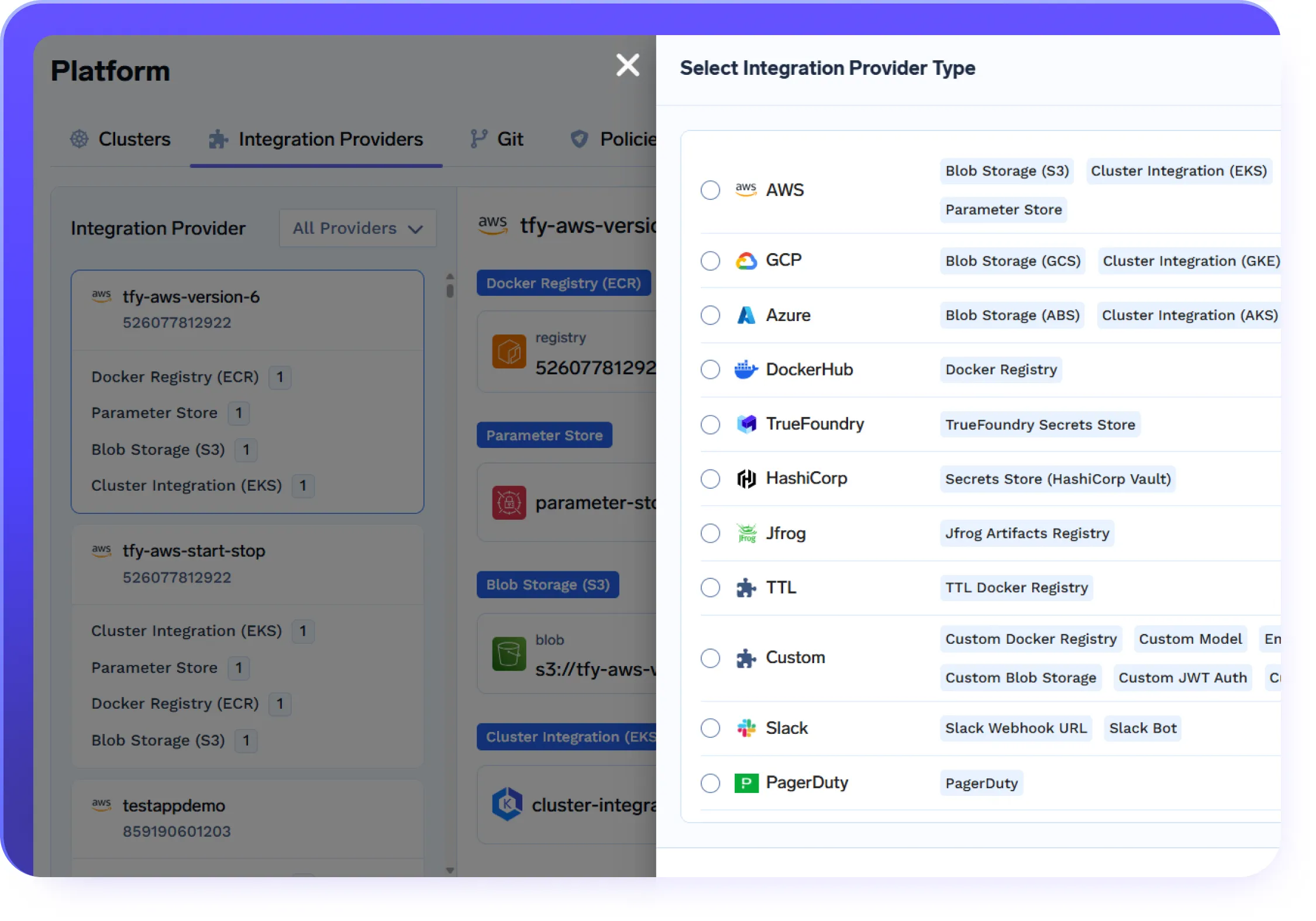
大規模な実世界AI向け
エンタープライズ対応
データとモデルをクラウド/オンプレミスインフラ内に保持する、セキュアなAIゲートウェイを導入。


コンプライアンスとセキュリティ
SOC 2、HIPAA、GDPRの各標準により、堅牢なデータ保護を確実にするガバナンスとアクセス制御
SSOとロールベースアクセス制御(RBAC)および監査ログエンタープライズサポートと信頼性
SLAに基づいた応答SLAを含む24時間年中無休サポート
VPC、オンプレミス、エアギャップ環境、または複数のクラウドにわたって。
データはお客様のドメイン外に出ることはありません。TrueFoundryが稼働する場所であればどこでも、完全な主権、分離、エンタープライズグレードのコンプライアンスを享受できます。


TrueFoundryでの具体的な成果
企業がTrueFoundryを選ぶ理由






3倍
自律型LLMエージェントでより迅速な価値実現
80%
自動エージェント最適化後のGPU‑クラスター利用率向上

Aaron Erickson
Applied AI Lab 創業者
TrueFoundryは、当社のGPUフリートを自律的で自己最適化するエンジンに変えました。これにより、利用率が80 %向上し、アイドル状態のコンピューティングによる数百万ドルのコストを削減できました。
5倍
社内AI/MLプラットフォームのプロダクション化までの時間短縮
50%
ワークロードをTrueFoundryに移行後のクラウド支出削減

Pratik Agrawal
データサイエンス&AIイノベーション シニアディレクター
TrueFoundryのおかげで、私たちは実験段階から本番環境への移行を記録的な速さで実現できました。1年以上かかるところが数ヶ月で完了し、開発者の採用も向上しました。
80%
モデルのプロダクション投入までの時間短縮
35%
以前のSageMakerセットアップと比較したクラウドコスト削減
.webp)
Vibhas Gejji
スタッフMLエンジニア
DevOpsの負担を軽減し、チーム全体のプロダクションロールアウトを簡素化しました。TrueFoundryは、実験段階から堅牢なサービスまで拡張可能なインフラにより、MLデリバリーを加速させました。
50%
RAG/エージェントスタックのデプロイを迅速化
60%
RAG/エージェントパイプラインのメンテナンスオーバーヘッドの削減
.webp)
Indroneel G.
インテリジェントプロセスリーダー
TrueFoundryは、パイプライン、ベクトルDB、API、UIを含む完全なRAGスタックを、セルフホスト型インフラストラクチャを完全に制御しながら、2倍の速さでデプロイするのに役立ちました。
60%
AIデプロイの高速化
~40-50%
開発環境全体での効果的なコスト削減
.webp)
Nilav Ghosh
AI担当シニアディレクター
TrueFoundryの導入により、デプロイ期間を半分以上短縮し、統合されたMLOpsインターフェースを通じてインフラのオーバーヘッドを削減することで、価値提供を加速しました。
<2
全てのプロダクションモデルを移行するのにかかった週数
75%
データサイエンスの調整時間を削減し、モデルの更新と機能の展開を加速
.webp)
Rajat Bansal
CTO
インフラコストを大幅に削減し、データサイエンスの調整時間を75%短縮できました。TrueFoundryは、チーム全体のモデルデプロイ速度を向上させてくれました。
よくある質問
LLMファインチューニングとは何ですか?なぜ重要なのでしょうか?
TrueFoundryはLLMのファインチューニングをどのように簡素化しますか?
- ノーコード&フルコードワークフロー:直感的なUIまたはカスタムトレーニングスクリプトを使用
- 組み込みの実験追跡:ハイパーパラメーター、メトリクス、モデルバージョンを自動ログ
- インフラストラクチャオーケストレーション:TrueFoundryが管理するインフラまたは独自のクラウド/VPCでジョブを実行
- PEFT手法のサポート:LoRAおよびQLoRAベースのファインチューニングをネイティブでサポート
- チェックポイントとバージョン管理:トレーニングをシームレスに再開し、再現性を維持
- アダプター管理:複数のタスク/モデル間でアダプターを再利用、マージ、またはデプロイ
TrueFoundryでどのような種類のモデルをファインチューニングできますか?
- デコーダーベースのLLM(例:LLaMA、GPT-J、Falcon、Mistral)
- エンコーダーモデル(例:BERT、RoBERTa、DistilBERT)
- エンコーダー・デコーダーモデル(例:T5、FLAN-T5)
独自のデータセットとトレーニングコードを持ち込むことはできますか?
- S3、GCS、Azure、Hugging Face Hub、またはローカルファイルから独自のデータセットを持ち込む
- カスタムトレーニングスクリプト(PyTorch、Transformers、PEFTなど)を介して独自のコードを持ち込むことができます
- または、一般的なファインチューニングワークフロー用に事前に構築されたテンプレートを使用します
TrueFoundryはLoRAおよびQLoRAのファインチューニングをどのようにサポートしていますか?
- 当社のUIを使用してLoRAレイヤーとハイパーパラメータを設定します
- LoRAアダプターをベースモデルとは独立して保存およびデプロイします
- デプロイまたはオフライン推論のために、アダプターをベースモデルとマージします
- GPUメモリ使用量を大幅に削減 — インフラ費用を最適化したい企業に最適です
TrueFoundryでファインチューニングしたモデルを本番環境にデプロイできますか?
- vLLM、SGLang、またはその他の推論サーバーを使用してモデルをデプロイします
- レート制限とRBACが統合されたAPIとしてモデルを公開します
- リアルタイムのレイテンシー、トークン使用量、パフォーマンスを監視します
- アダプターを使用して迅速にデプロイするか、ベースモデルとマージしてスタンドアロン推論を行います









