












エンタープライズ対応AIゲートウェイ&エージェンティックデプロイメントプラットフォーム — セキュア、スケーラブル、ガバナンス対応。
オンプレミス、VPC、ハイブリッド、またはパブリッククラウド


エージェンティックAIを1つの統合プラットフォームで統制、デプロイ、スケール、追跡
.svg)
%201%20(1).avif)
AIゲートウェイでエージェンティックAIをオーケストレーション
AIエージェントとワークフロー全体にわたる完全な制御と可視性をもって、インテリジェントな多段階推論、ツール利用、メモリを実現します。

.webp)
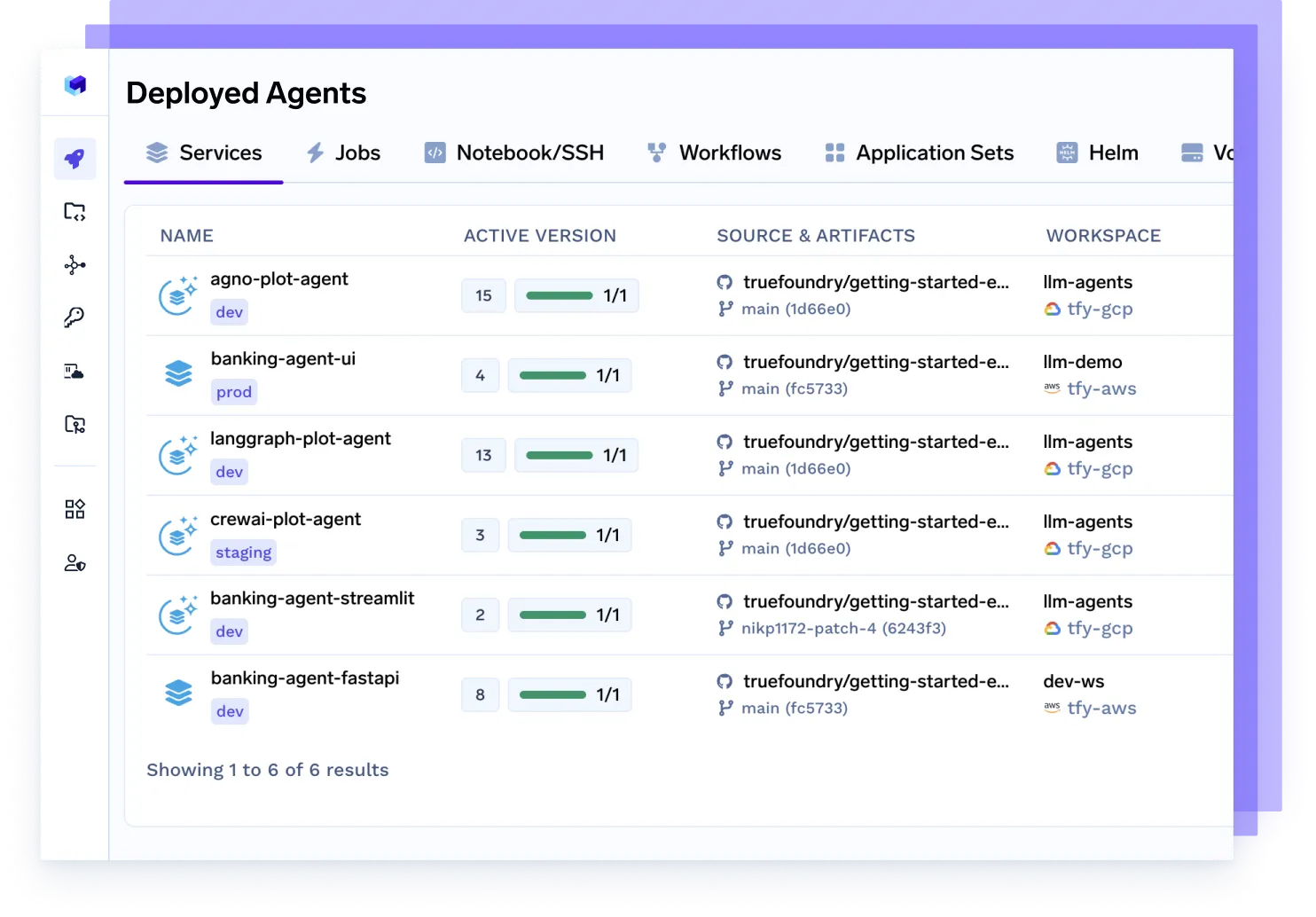
あらゆるエージェントAIワークロードをデプロイし、スケーリング
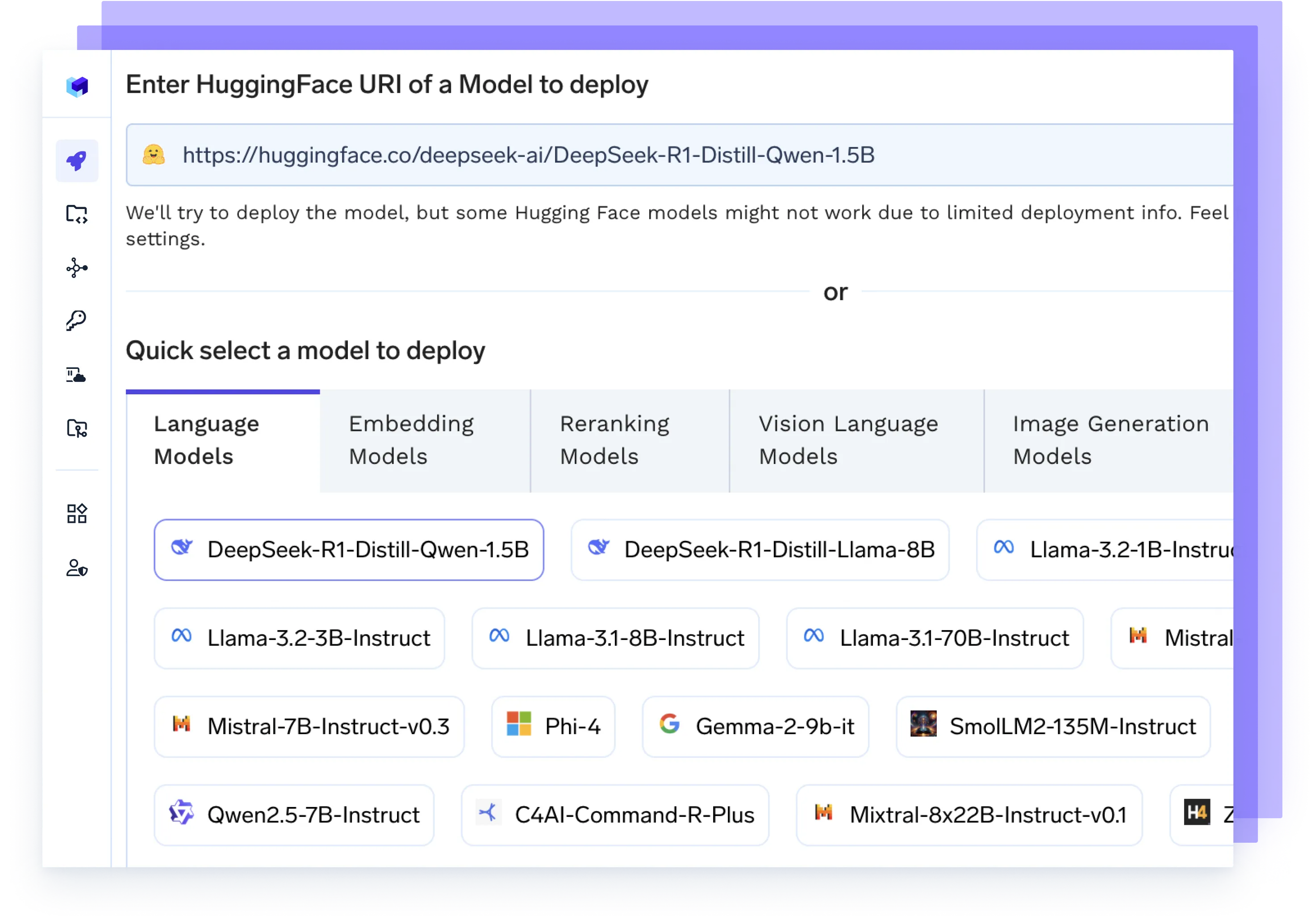
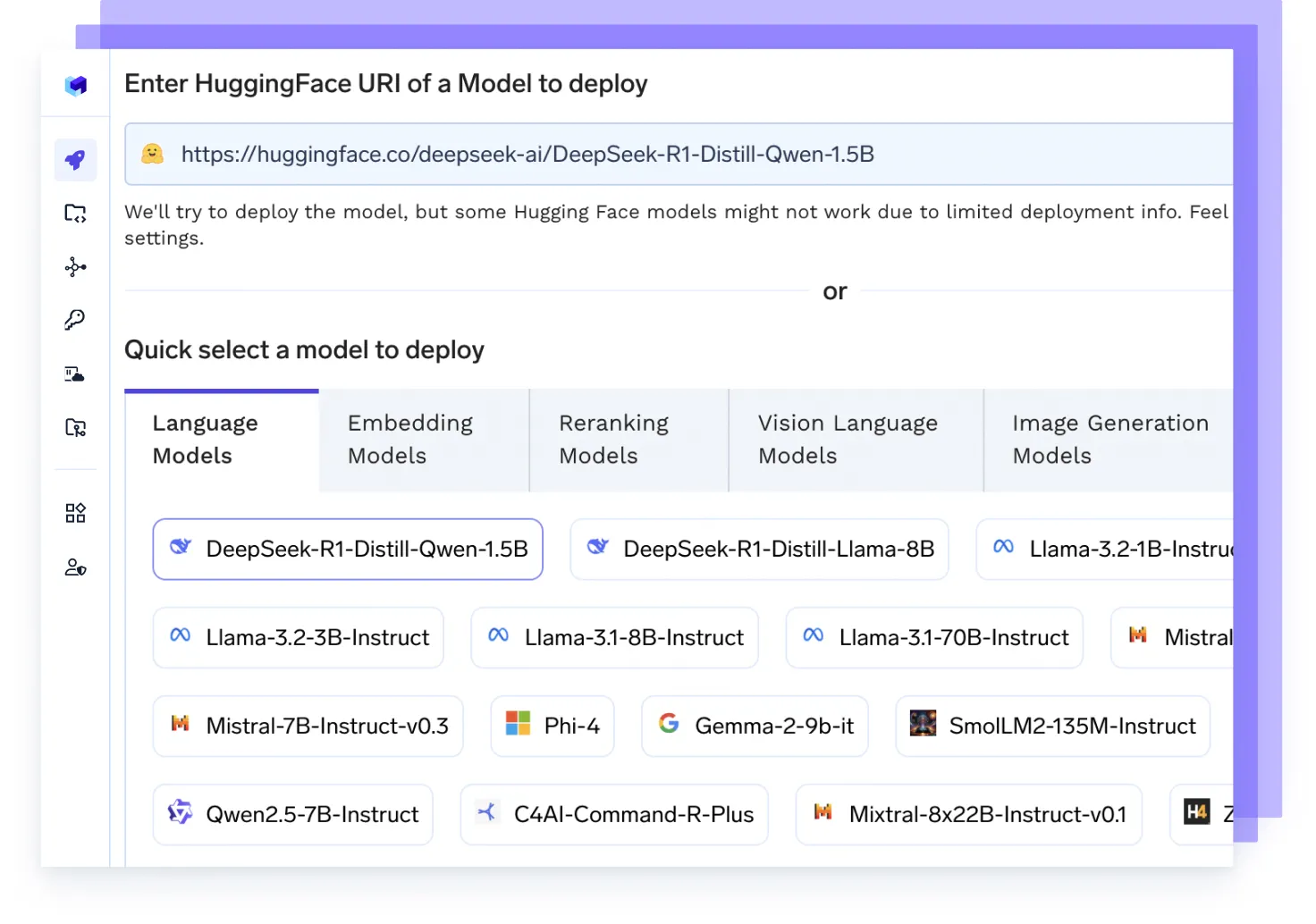
あらゆるAIモデルをホスト
vLLM、TGI、Tritonなどの高性能バックエンドを使用して、あらゆるLLM、埋め込みモデル、またはカスタムモデルを実行します。これらは速度とスケーラビリティのために最適化されています。
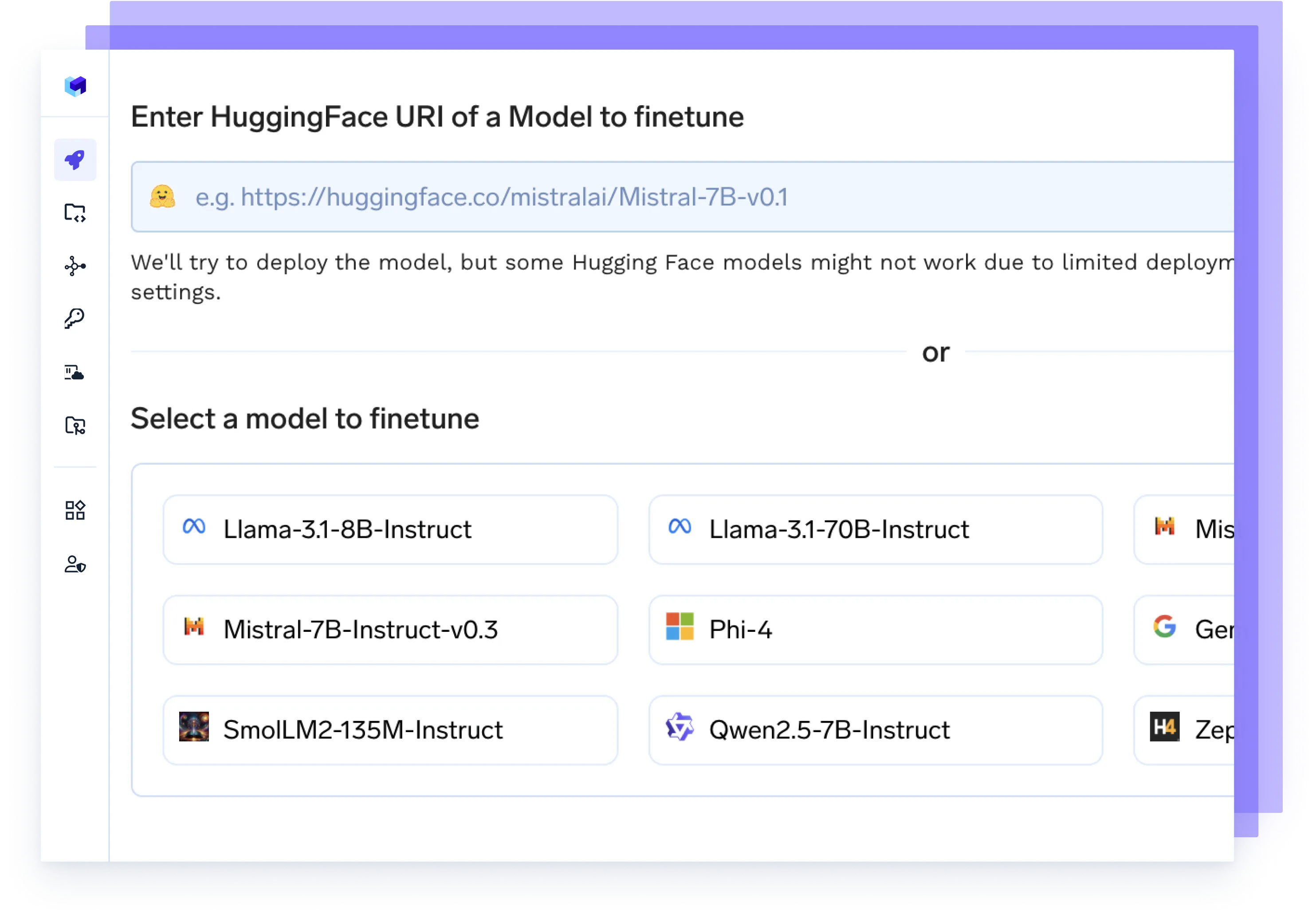
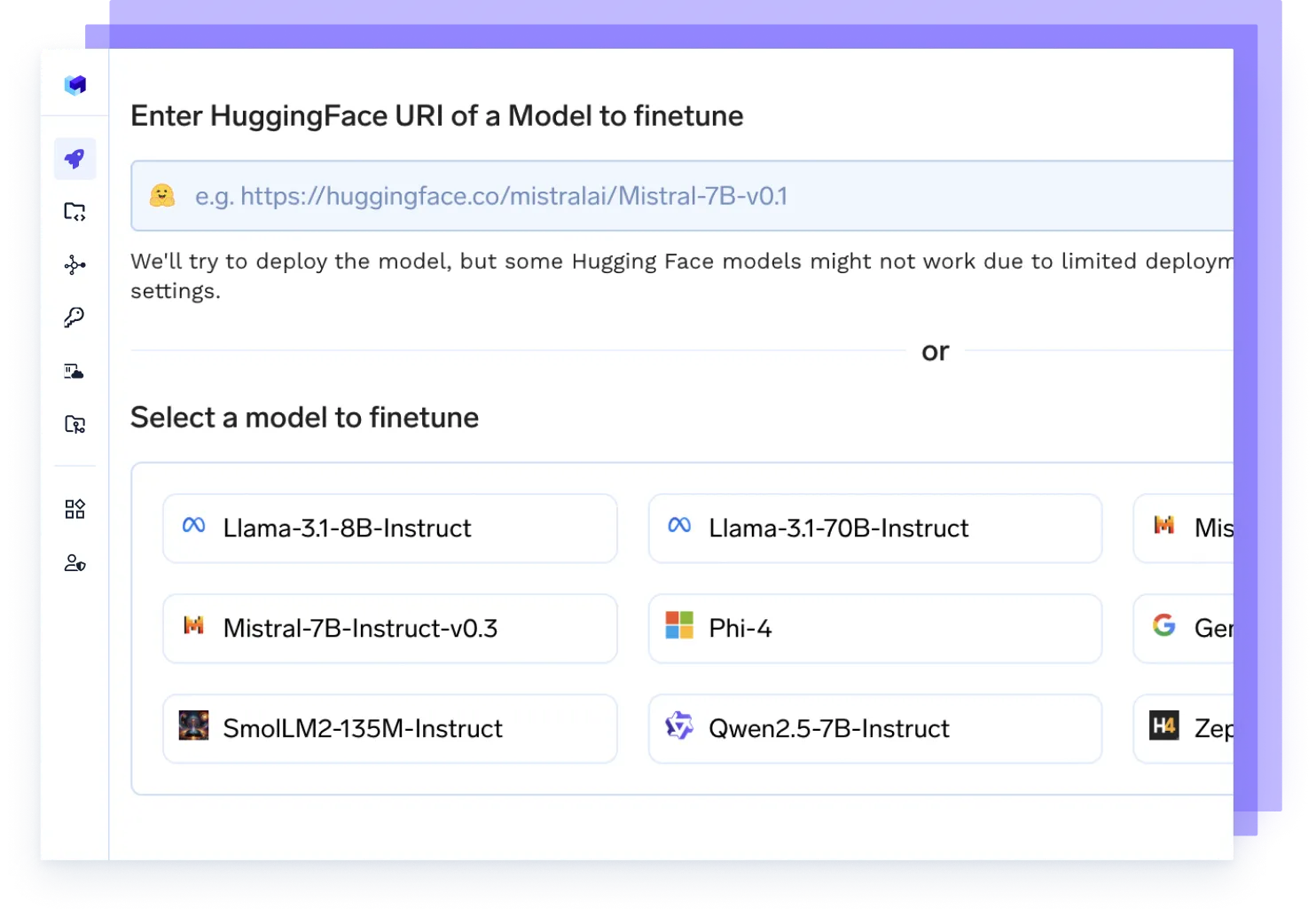
あらゆるモデルをファインチューニング
お客様のデータでファインチューニングジョブを開始し、実験を追跡し、更新されたチェックポイントを直接本番環境にデプロイします。これらすべてを一つのフローで実現します。
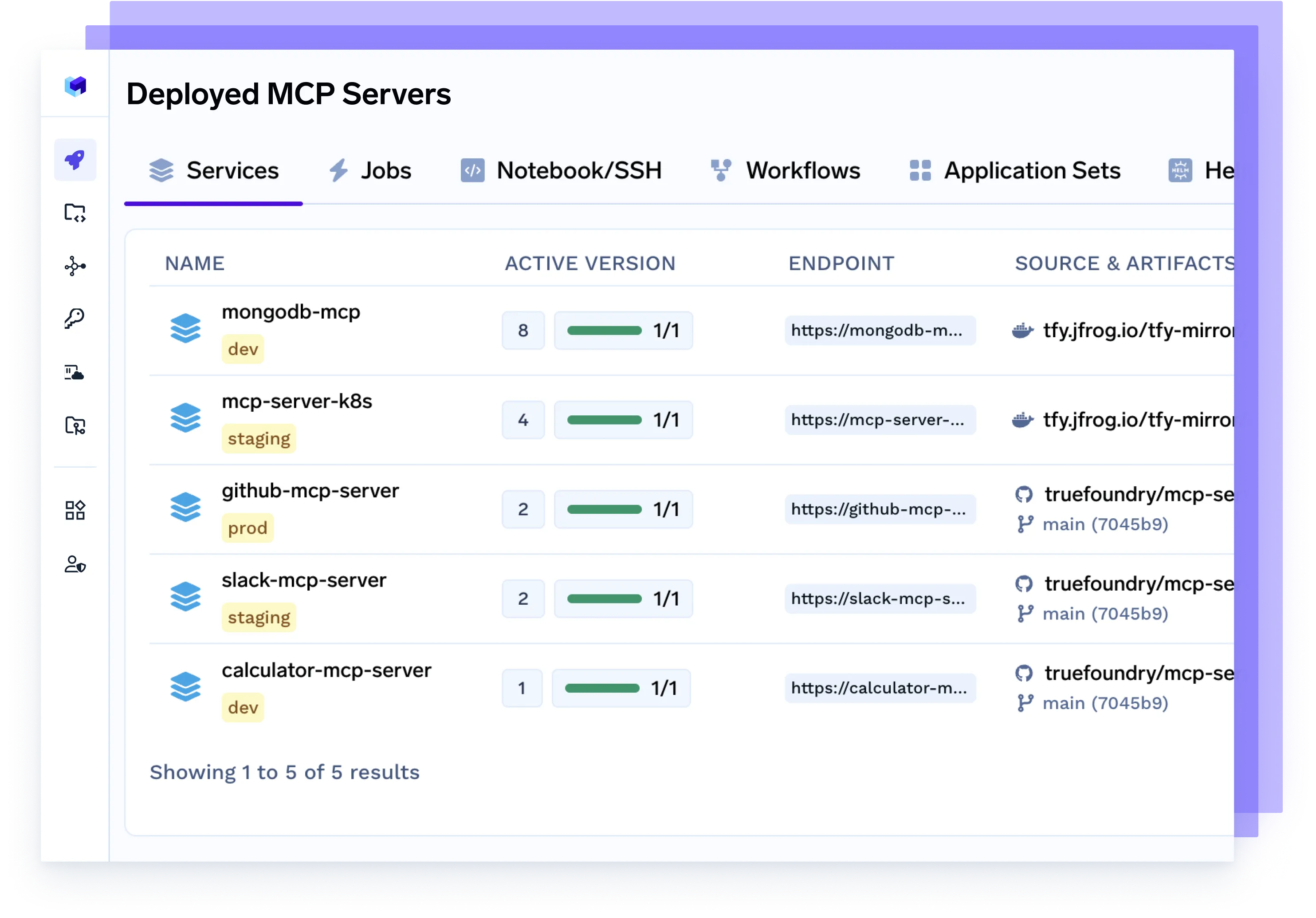
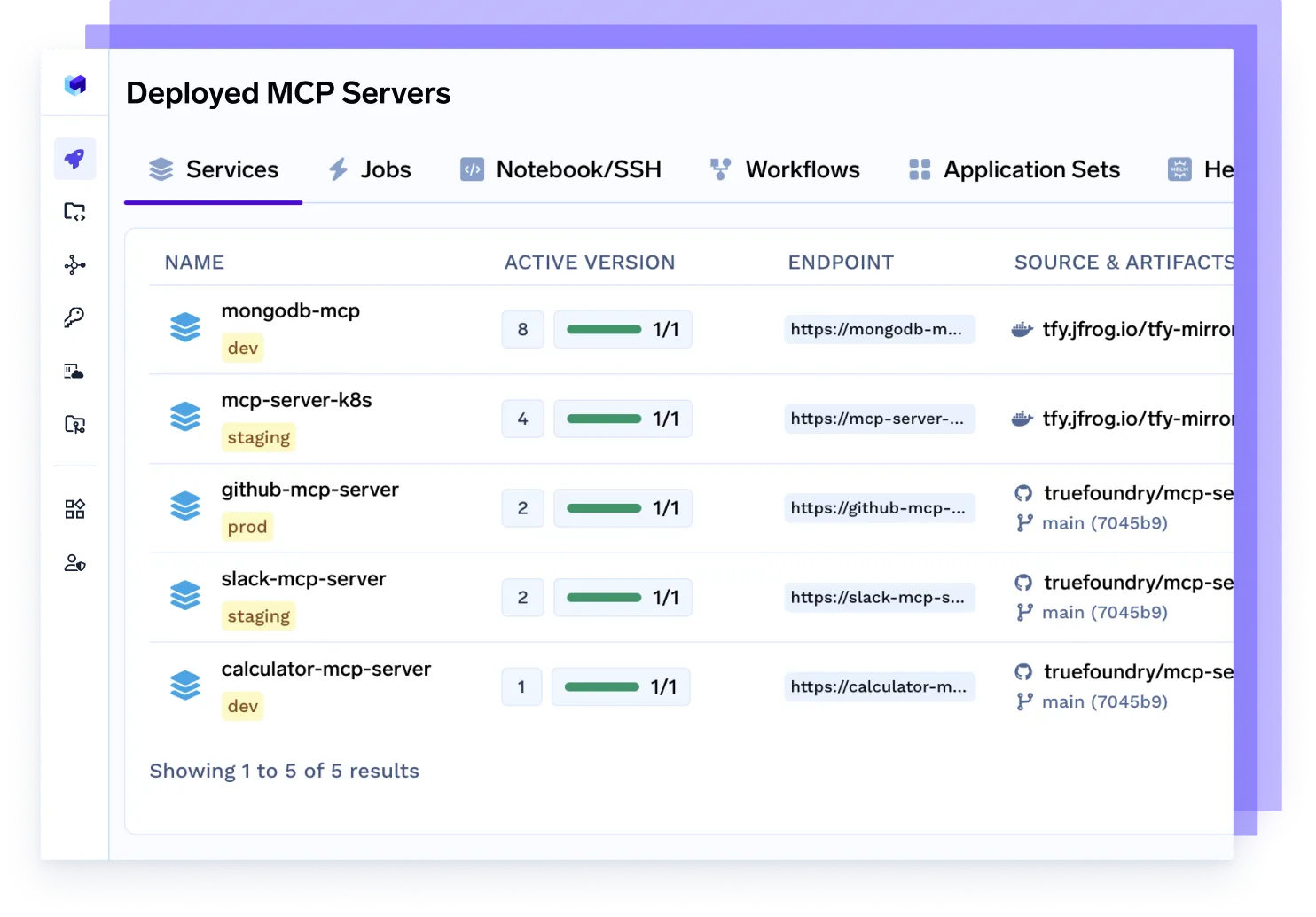
MCPサーバーをデプロイ
専用のモデル制御プロトコル(MCP)サーバーをプロビジョニングし、エージェントのトラフィック管理、モデルアクセスのスケーリング、レート制限の適用、チームやプロジェクトごとのワークロード分離を行います。
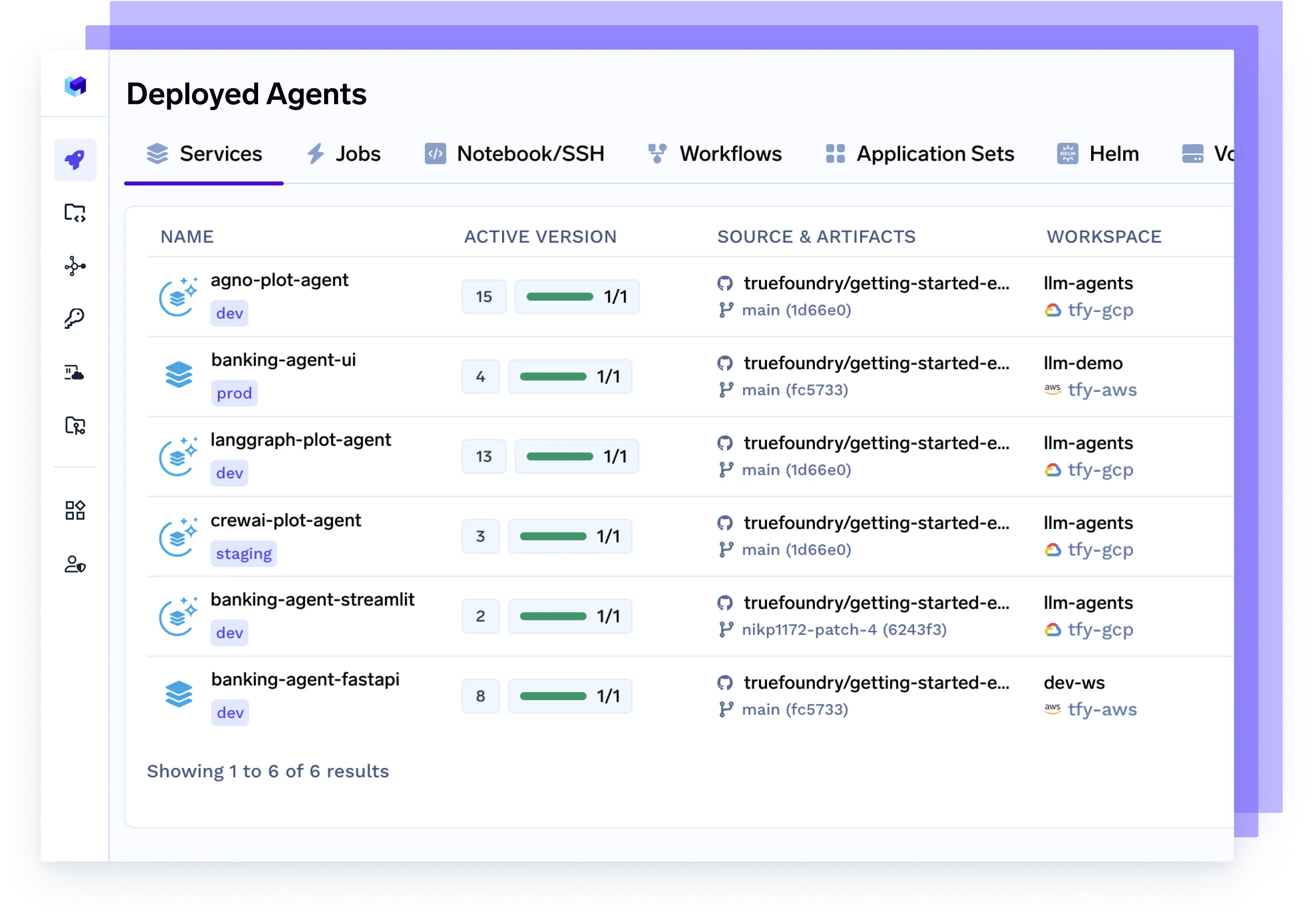
あらゆるエージェント、あらゆるフレームワークをデプロイ
Langgraph、CrewAI、AutoGen、または独自のオーケストレーションで構築されたエージェントをシームレスに提供します。これらは完全にコンテナ化され、監視可能で、本番環境に対応しています。
VPC、オンプレミス、エアギャップ環境、または複数のクラウドにわたって。
データがお客様のドメイン外に出ることはありません。TrueFoundryが稼働する場所であればどこでも、完全な主権、分離、エンタープライズグレードのコンプライアンスを享受できます。


.avif)
エンタープライズ対応
データとモデルをクラウド/オンプレミスインフラ内に保持する、セキュアなAIゲートウェイを導入。


コンプライアンスとセキュリティ
SOC 2、HIPAA、GDPRの各標準により、堅牢なデータ保護を確実にするガバナンスとアクセス制御
SSOとロールベースアクセス制御(RBAC)および監査ログエンタープライズサポートと信頼性
SLAに基づいた応答SLAを含む24時間年中無休サポート
エージェントの完全な可観測性
プロンプトからツール/モデルの実行までのあらゆるステップを、メトリクス、レイテンシ、結果とともに追跡します。
.webp)
社内ツールとのシームレスな統合
OpenTelemetry準拠。Grafana、Datadog、Prometheus、またはお好みの可観測性スタックに接続できます。




インフラの可観測性(GPU、CPU、クラスター)
クラウド/オンプレミス全体のリソース使用状況を監視します — GPUメモリ、ノードの健全性、スケーリング動作など。
.webp)
エンタープライズグレードAI全体でコンプライアンスを統制・適用
強固なアクセス制御、ポリシー適用、フルスタックの可観測性(最初からネイティブに統合)により、信頼と運用規律を確立します。
.webp)
きめ細かなロールベースアクセス制御 (RBAC)
チーム、役割、機能に基づいて、モデル、環境、APIへのアクセス権限を厳密に制御します。
.webp)
不変の監査ロギング
モデルの使用状況、ユーザーアクセス、設定変更を含むすべての活動を記録し、完全な監査対応を保証します。

コンプライアンス対応アーキテクチャ
SOC 2、HIPAA、GDPRなど、セキュリティとコンプライアンスの最高基準を満たすように構築されています。
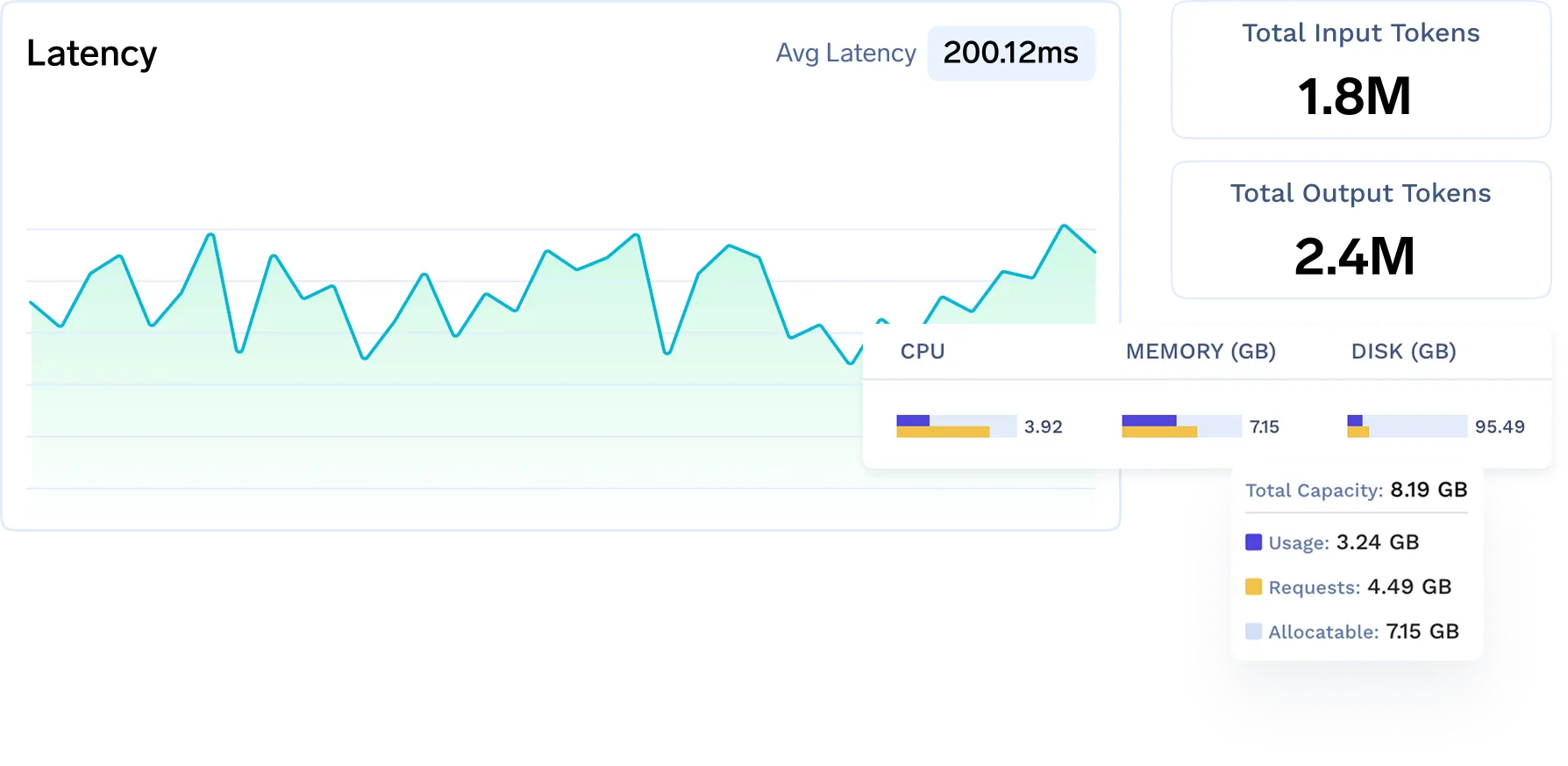
統合された監視とアラート
一元化されたダッシュボードとアラートを通じて、AIスタック全体のレイテンシー、スループット、トークン使用量、コスト、GPU使用率を追跡します。

リアルタイムポリシー適用
ワークロードの実行中に、データレジデンシー、使用量クォータ、レート制限、コスト管理に関するポリシーを動的に適用します。
私たちは、AIに最適化され、管理不要なAIインフラを構想しています
運用負荷なしでリソースを自動最適化

GPUオーケストレーションとオートスケーリング
GPUワークロードを需要に合わせて自動的にスケジュールし、スケーリングすることで、過剰なプロビジョニングなしにパフォーマンスを最適化します。
GPU分割サポート
(MIGおよびタイムスライシング)
NVIDIA MIGとタイムスライシングを使用して、複数のワークロード間でGPUリソースを費用対効果高く共有できるようにします。
リアルタイムリソース
最適化
実際のトラフィックと計算ニーズに基づいて、CPUとメモリの割り当てを継続的に調整します。
インフラの自動適正化
過剰にプロビジョニングされたインフラを検出し修正することで、SLAとモデル性能を維持しながらクラウドの無駄を削減します。
TrueFoundryがもたらす確かな成果
企業がTrueFoundryを選ぶ理由






3倍
自律型LLMエージェントによる価値実現までの時間短縮
80%
自動エージェント最適化後のGPUクラスター利用率向上

Aaron Erickson
Applied AI Lab 創設者
TrueFoundryは、当社のGPUフリートを自律的で自己最適化するエンジンに変え、80%以上の利用率向上を実現し、アイドル状態のコンピューティングで数百万ドルの節約になりました。
5倍
社内AI/MLプラットフォームのプロダクション化までの時間短縮
50%
ワークロードをTrueFoundryに移行後のクラウド支出削減

Pratik Agrawal
データサイエンス&AIイノベーション担当シニアディレクター
TrueFoundryのおかげで、記録的な速さで実験段階からプロダクションへの移行ができました。1年以上かかるところが数ヶ月で完了し、開発者の導入も向上しました。
80%
モデルのプロダクション投入までの時間短縮
35%
以前のSageMaker設定と比較したクラウドコスト削減
.webp)
Vibhas Gejji
スタッフMLエンジニア
DevOpsの負担を軽減し、チーム全体のプロダクション展開を簡素化しました。TrueFoundryは、実験段階から堅牢なサービスまでスケールするインフラにより、MLデリバリーを加速させました。
50%
RAG/エージェントスタックのデプロイの高速化
60%
RAG/エージェントパイプラインのメンテナンスオーバーヘッドの削減
.webp)
インドロニール・G
インテリジェントプロセスリーダー
TrueFoundryは、パイプライン、ベクトルDB、API、UIを含む完全なRAGスタックを、自己ホスト型インフラストラクチャを完全に制御しながら2倍の速さでデプロイするのに役立ちました。
60%
AIデプロイの高速化
~40-50%
開発環境全体での実質的なコスト削減
.webp)
ニラヴ・ゴーシュ
AIシニアディレクター
TrueFoundryの導入により、統合されたMLOpsインターフェースを通じてデプロイ期間を半分以下に短縮し、インフラのオーバーヘッドを削減することで、価値提供を加速しました。
<2
全ての運用モデルを移行するのに要した週数
75%
データサイエンスの調整時間を短縮し、モデル更新と機能リリースを加速
.webp)
ラジャット・バンサル
CTO
インフラコストを大幅に削減し、データサイエンスの調整時間を75%短縮できました。TrueFoundryのおかげで、チーム全体のモデルデプロイ速度が向上しました。
統合機能
ローコードのエージェントビルダーからGPUレベルの性能評価まで、あらゆるものに対応するフレームワーク非依存の統合機能。


- © 2022 ENSEMBLE Technologies






ニュースレターを購読する
最新のニュース、記事、リソースをメールでお届けします
© 2026 全著作権所有。














