














November 5, 2025
|
5 min read

Published: January 19, 2026

Blazingly fast way to build, track and deploy your models!
LLM-powered applications have created a pressing need for models to access up-to-date, domain-specific data from diverse sources. MCP addresses this by providing a unified protocol standardising how applications can dynamically expose data and capabilities to any LLM-powered application.
At its core, MCP follows a JSON-RPC-based client-server architecture where a host application can connect to multiple servers:
Transports define how an MCP Client and Server communicate with each other.
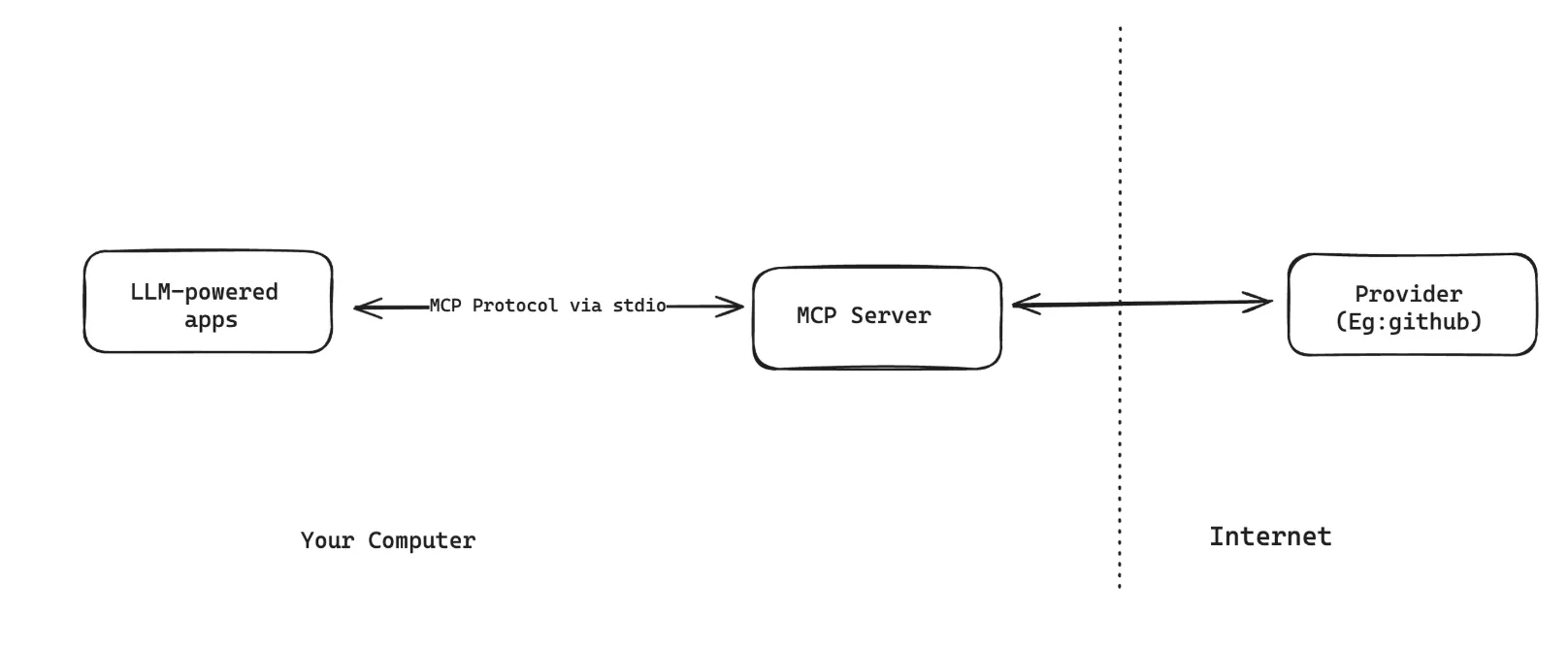
In this setup, the MCP Client within the MCP Host is responsible for spinning up the MCP Server on the same machine. Communication between the MCP Client and MCP Server happens via STDIN and STDOUT. Here, one MCP Server only communicates with a single MCP client.
A typical configuration looks like this:
Example: You can run GitHub's MCP Server locally using Docker and a Personal Access Token (PAT)
GitHub - github/github-mcp-server: GitHub's official MCP Server
{
"mcpServers": {
"github": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"-e",
"GITHUB_PERSONAL_ACCESS_TOKEN",
"ghcr.io/github/github-mcp-server"
],
"env": {
"GITHUB_PERSONAL_ACCESS_TOKEN": "<YOUR_TOKEN>"
}
}
}
}Typically, the authorisation can happen in two ways
Given the limitations, STDIO transport is unsuitable for creating custom MCP Servers on top of a company’s service and data source or SaaS subscriptions like GitHub or Slack. However, it will be helpful for developer tools use cases in IDEs.
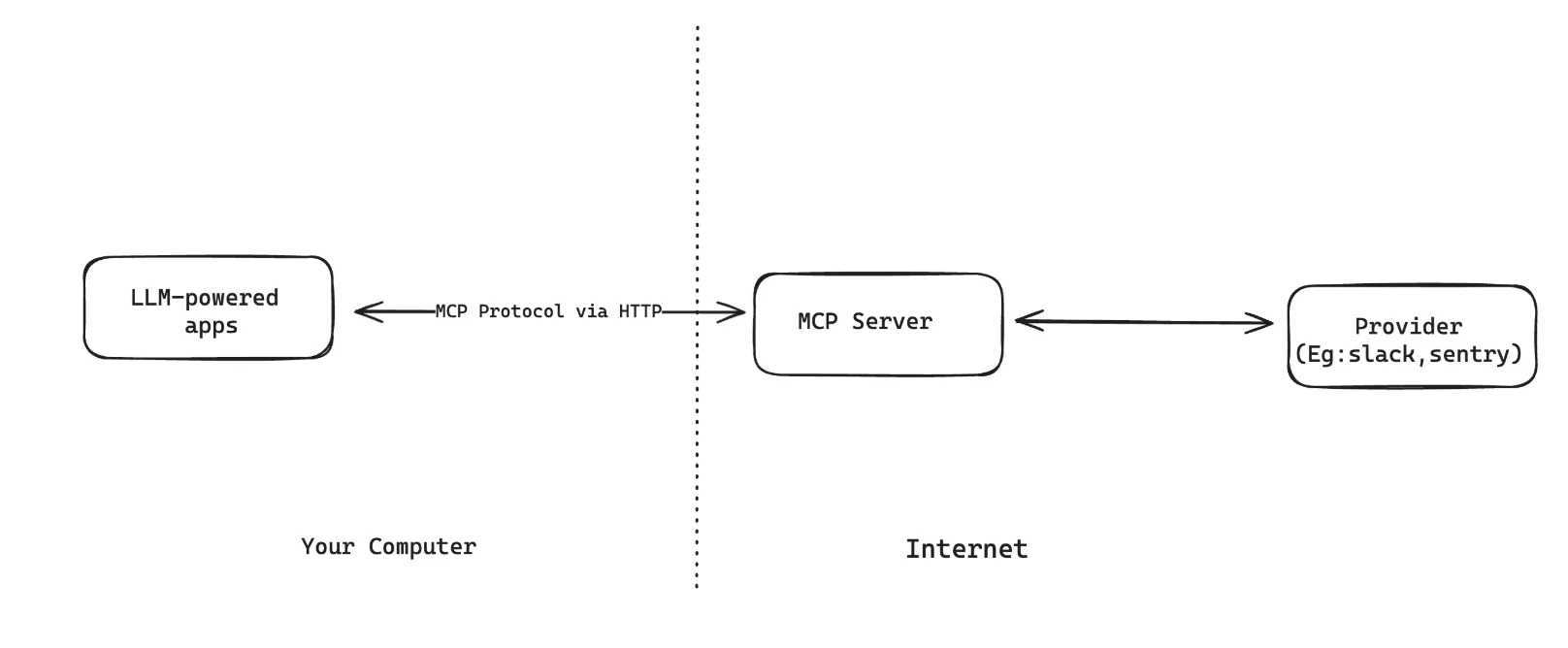
Streamable HTTP allows MCP Servers to handle multiple MCP clients connecting and communicating using the HTTP protocol. This removes a lot of the limitations of the STDIO transport. Mainly:
Authorisation in this transport is actively being developed. The latest specification released on 2025-03-26 mentions:
A typical Auth flow would look something like this:
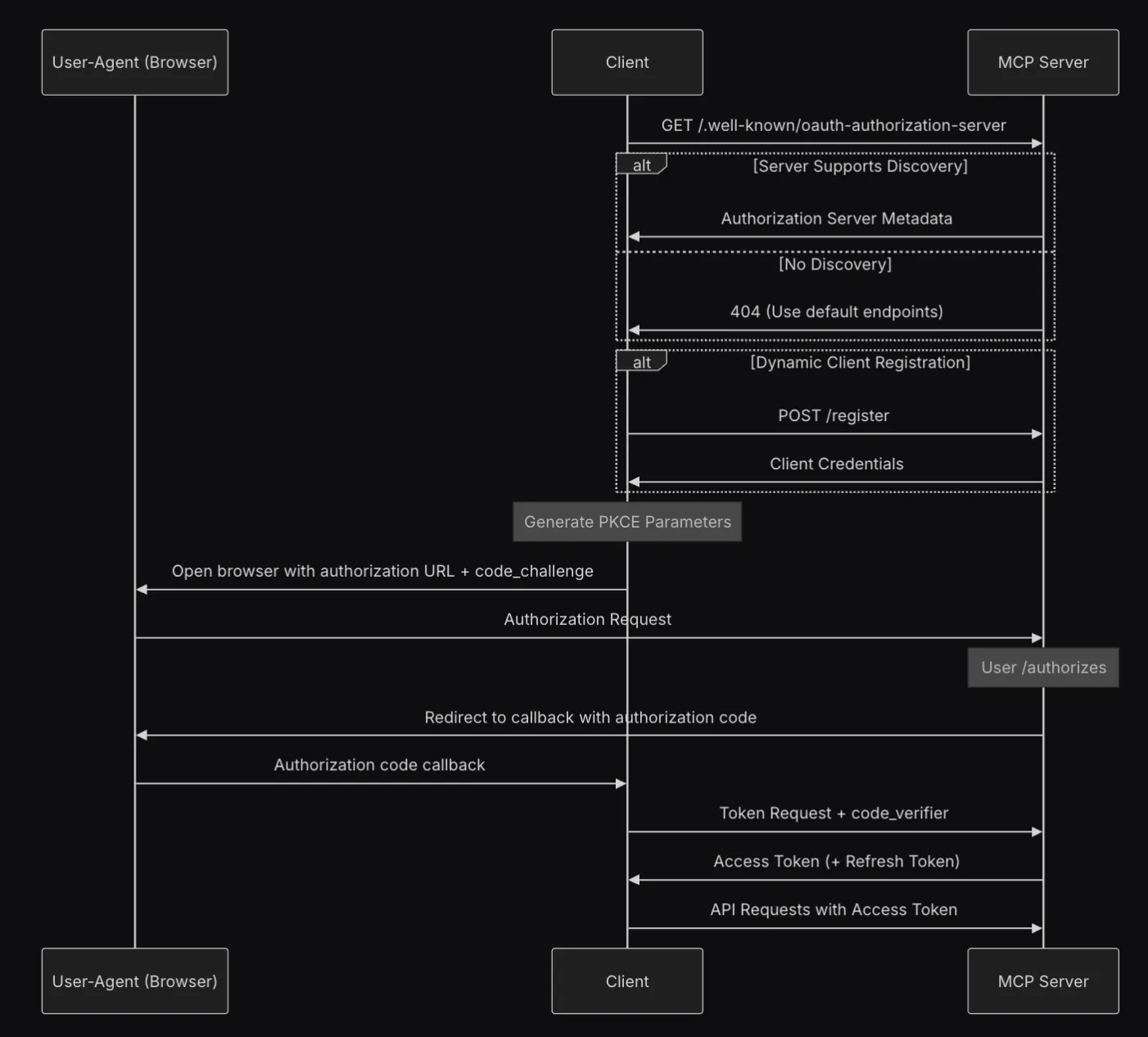
In the above flow, the MCP Server issuing tokens acts as a Resource and an Authorisation Server. This is impractical for MCP Servers for Slack, GitHub, etc, where the provider already implements its OAuth2 Authorisation Server. A company’s internally hosted services behind IDP-provided Authorisation Servers suffer from the same issue (Ex, ArgoCD installation behind an Authorisation Server provided by Okta).
The specification allows delegating this to a third-party authorisation server, but the MCP Server must issue its token and manage the relationship with the third-party token. This negates all the benefits of a third-party authorisation server, as the MCP Server needs to implement secure token management and the OAuth2 routes.
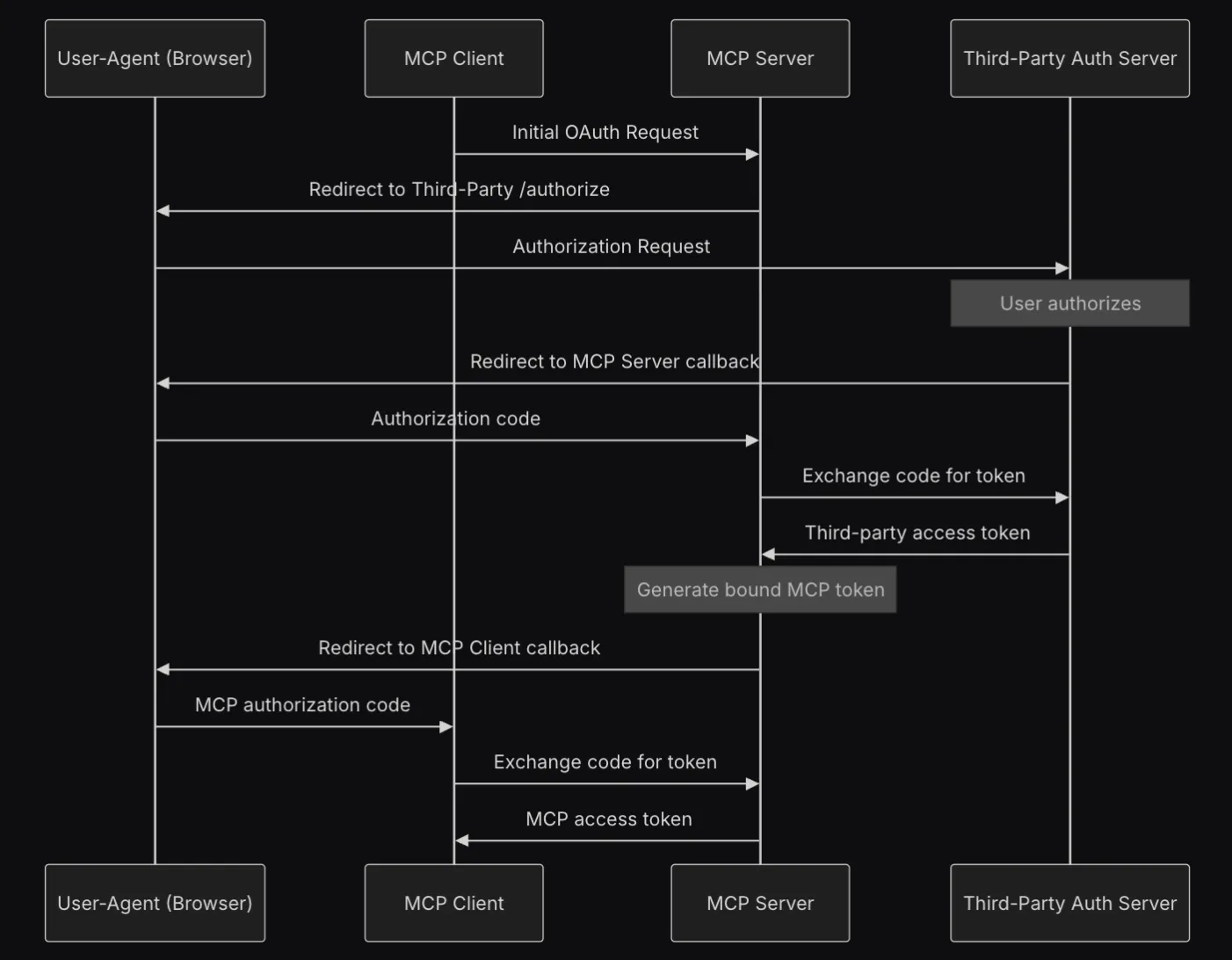
localhost and a select few redirect URIs, like Claude, etc.At TrueFoundry, we want our colleagues to actively be able to connect their Atlassian, Sentry, Slack, GitHub, etc. accounts to LLM as extra context. We also want to ensure that every employee can only access resources or take action on resources via LLMs that they are authorised to. MCP + OAuth2 seems the perfect way to expose this.
Given the above, we came up with the following architecture.
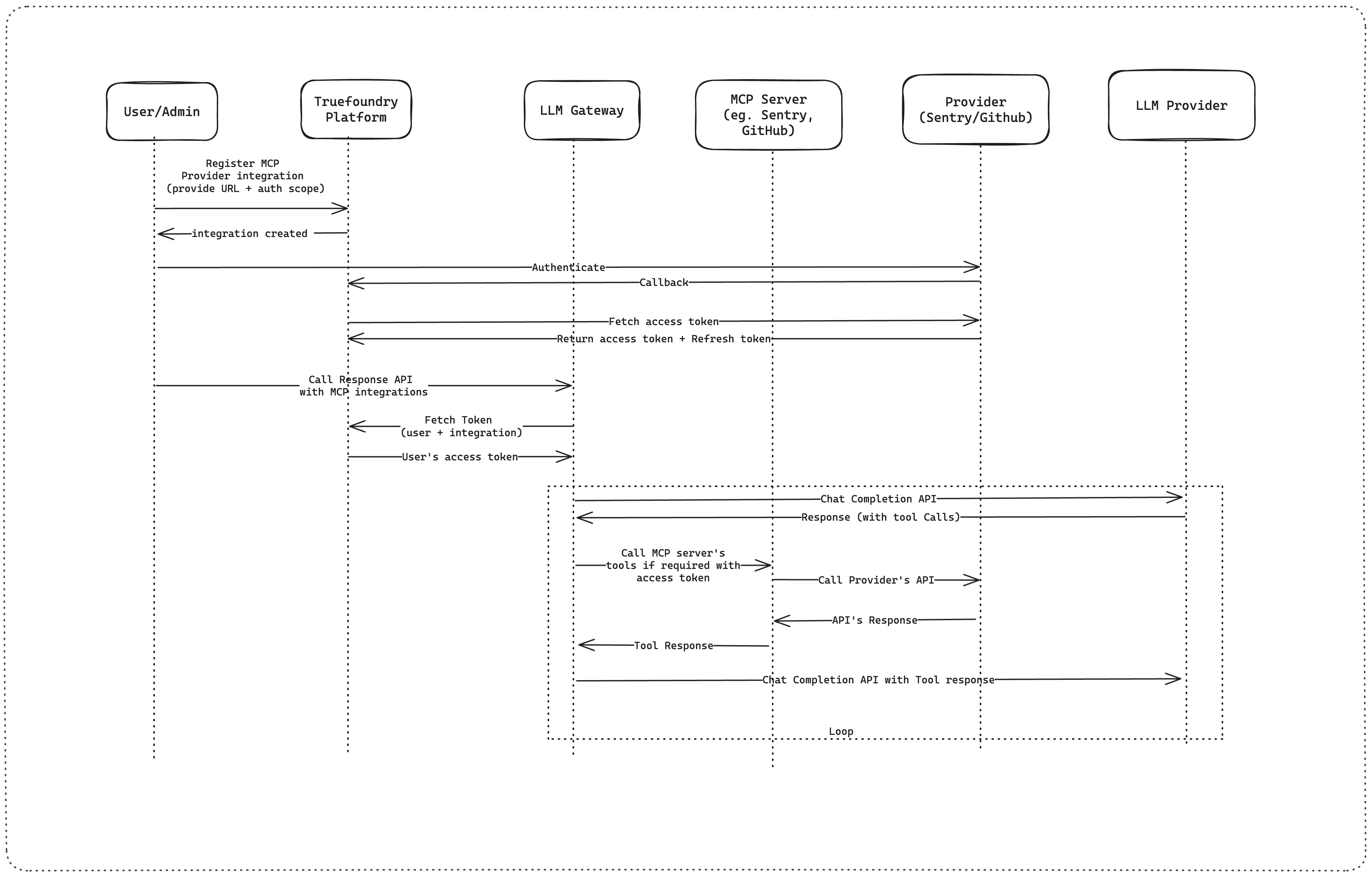
There are a few components here.
We wrote HTTP MCP Servers for providers like Slack, Sentry, Atlasian, Github, etc, following Streamable HTTP transport.
These MCP Servers proxy between the LLM and the Provider’s HTTP APIs. Note that this is not a 1:1 translation. These providers' HTTP APIs have a lot of unnecessary content that can easily derail the LLM and fill up the context window. For example, a list pod tool on a Kubernetes MCP Server will have much duplicate content as the pod spec repeats across multiple pods. Large fields, like managedFields, will not be required for most users’ requests. Other SaaS providers will have nested parent entities, fields that are not functional, like Avatar URL, etc. This is where we want to spend most of our development time. Eventually, we need a system in MCP that can help LLMs discover the data model of a system and then dynamically query for specific fields of resources.
These MCP servers expect an HTTP Authorisation header and directly pass it on to the Provider’s HTTP API.
After deploying the MCP Servers, we create OAuth2 Apps or confidential clients for each Provider. This is how it looks for Slack.
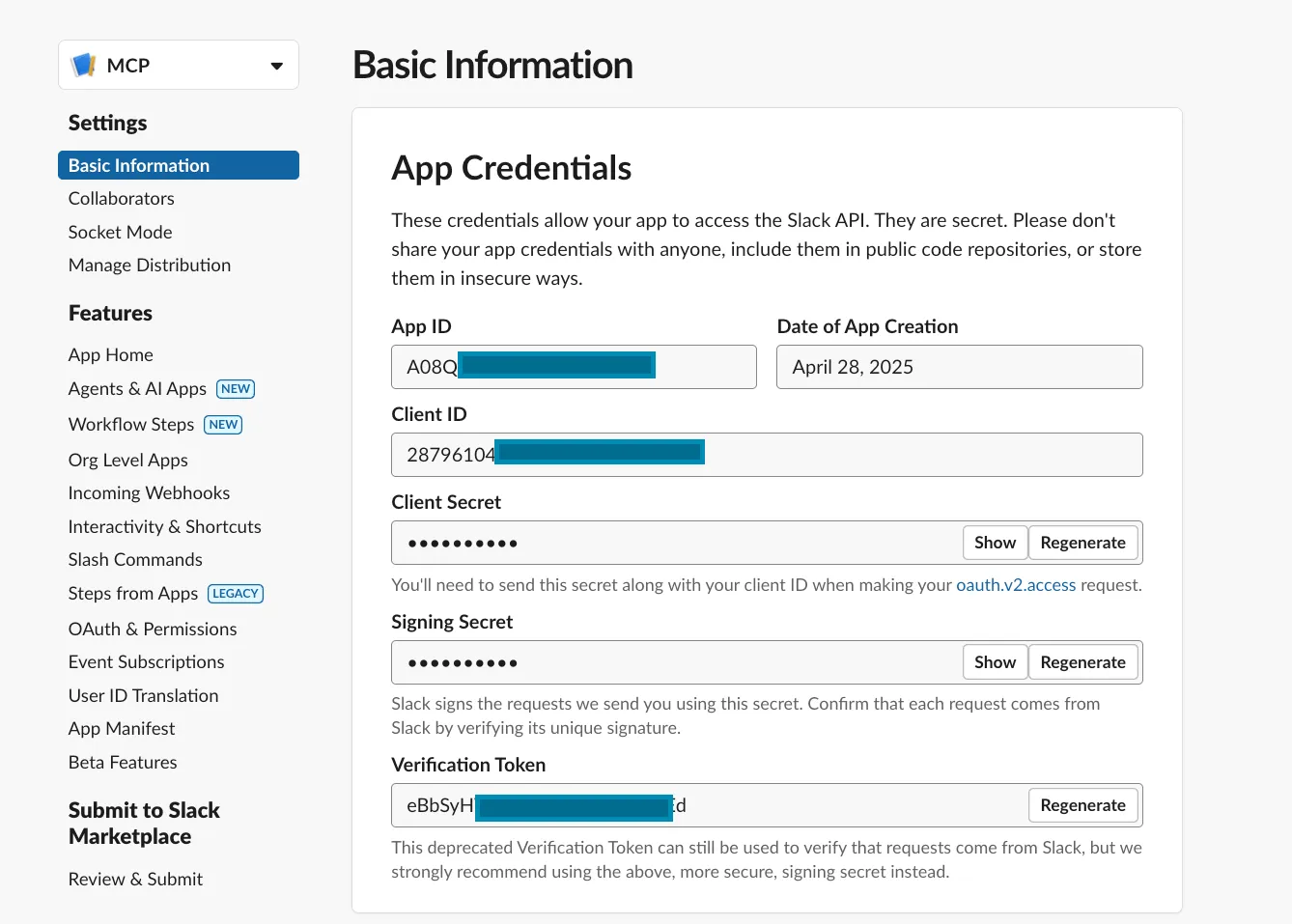
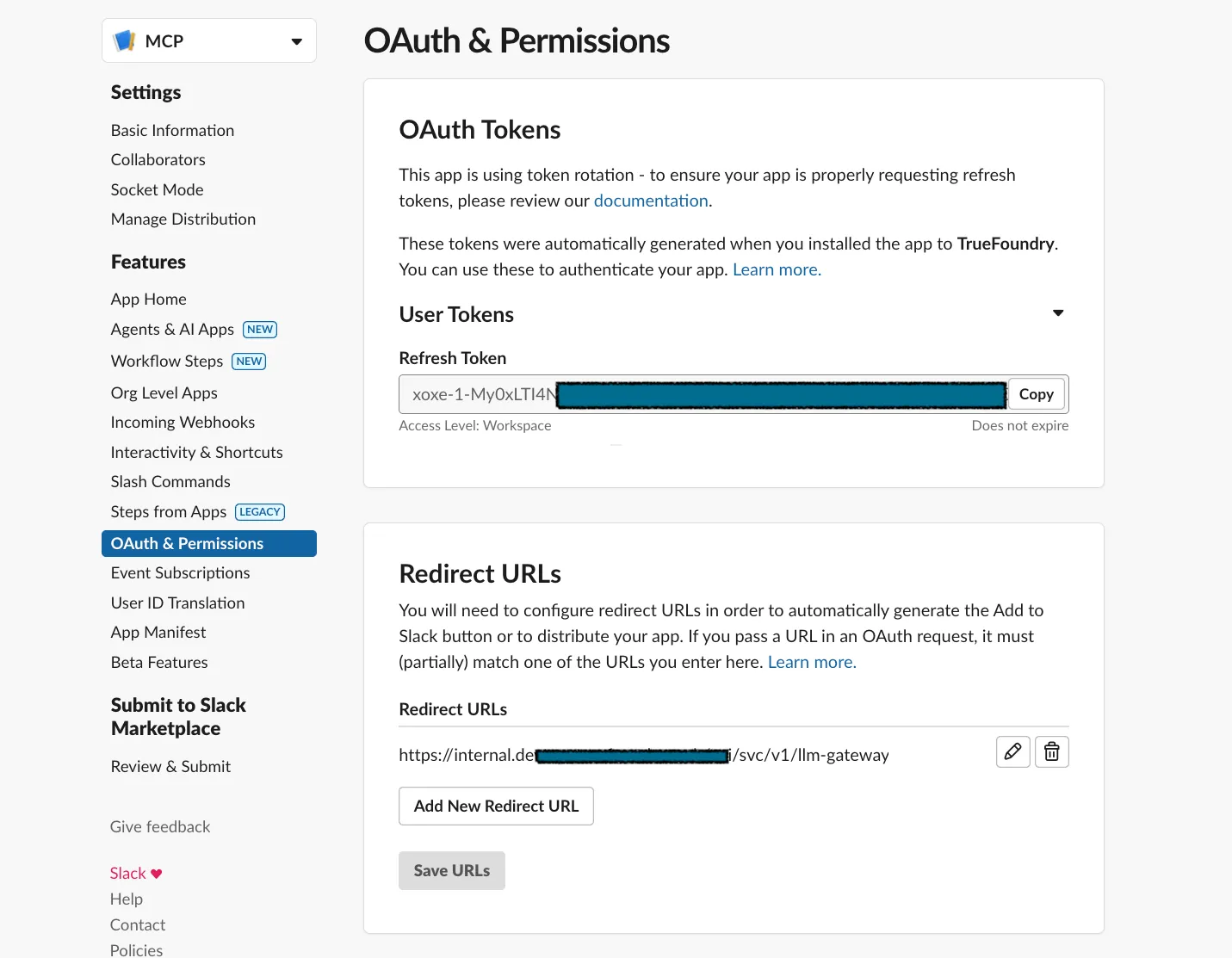
Above, you can also notice that the authorizer redirect URI is configured. It usually looks something like https://base-url/mcp-integrations/oauth2/callback.
Then we integrate the MCP Server along with the URL.
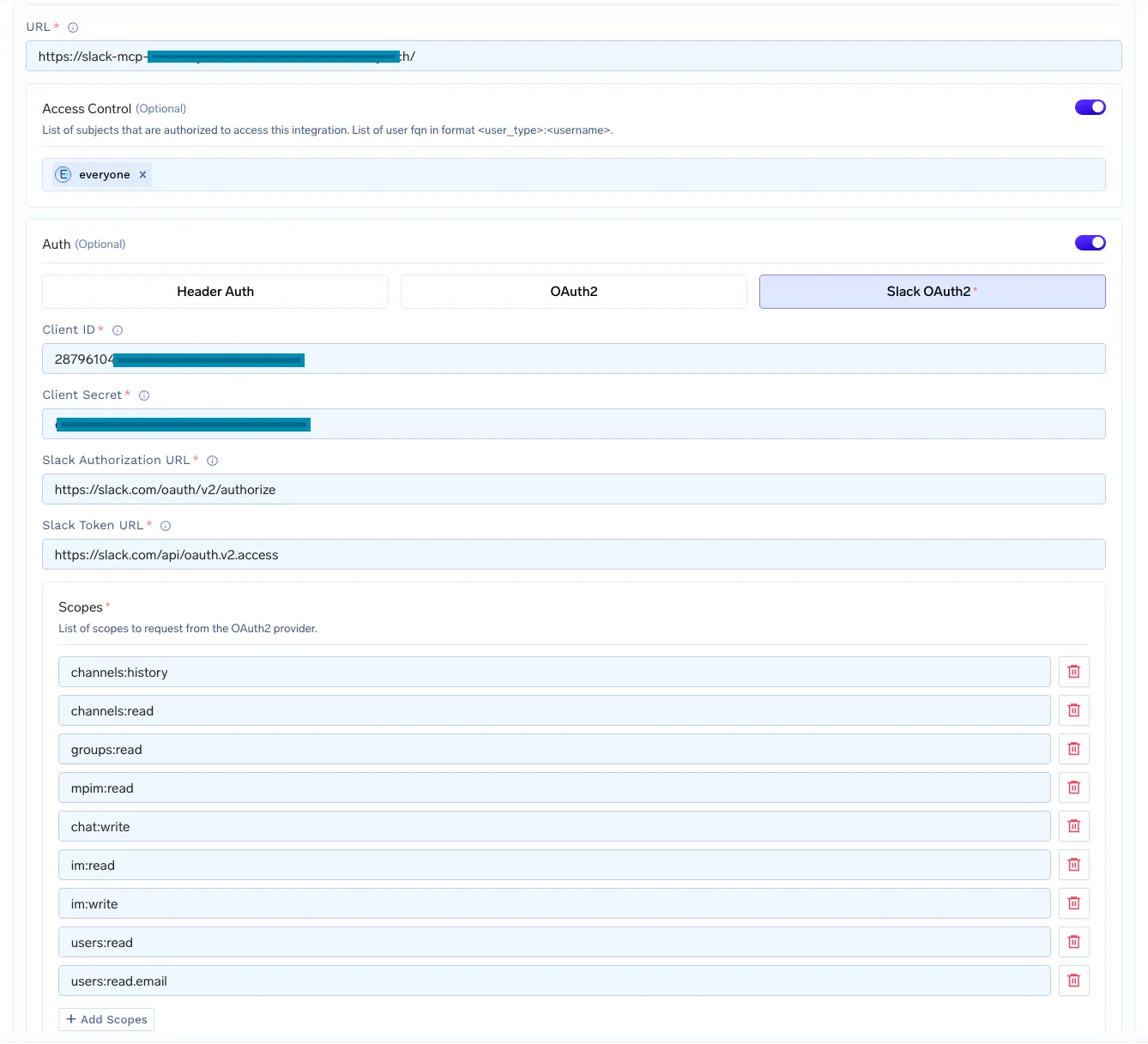
We can use the scopes to make this whole integration read-only, if we want or give permission on specific resource types. Even if the MCP server has tools to “write” any resources and the user has “write” access, LLMs will not be able to get the same privilege.
Once integrated, we can select the MCP Server on the Gateway Playground.
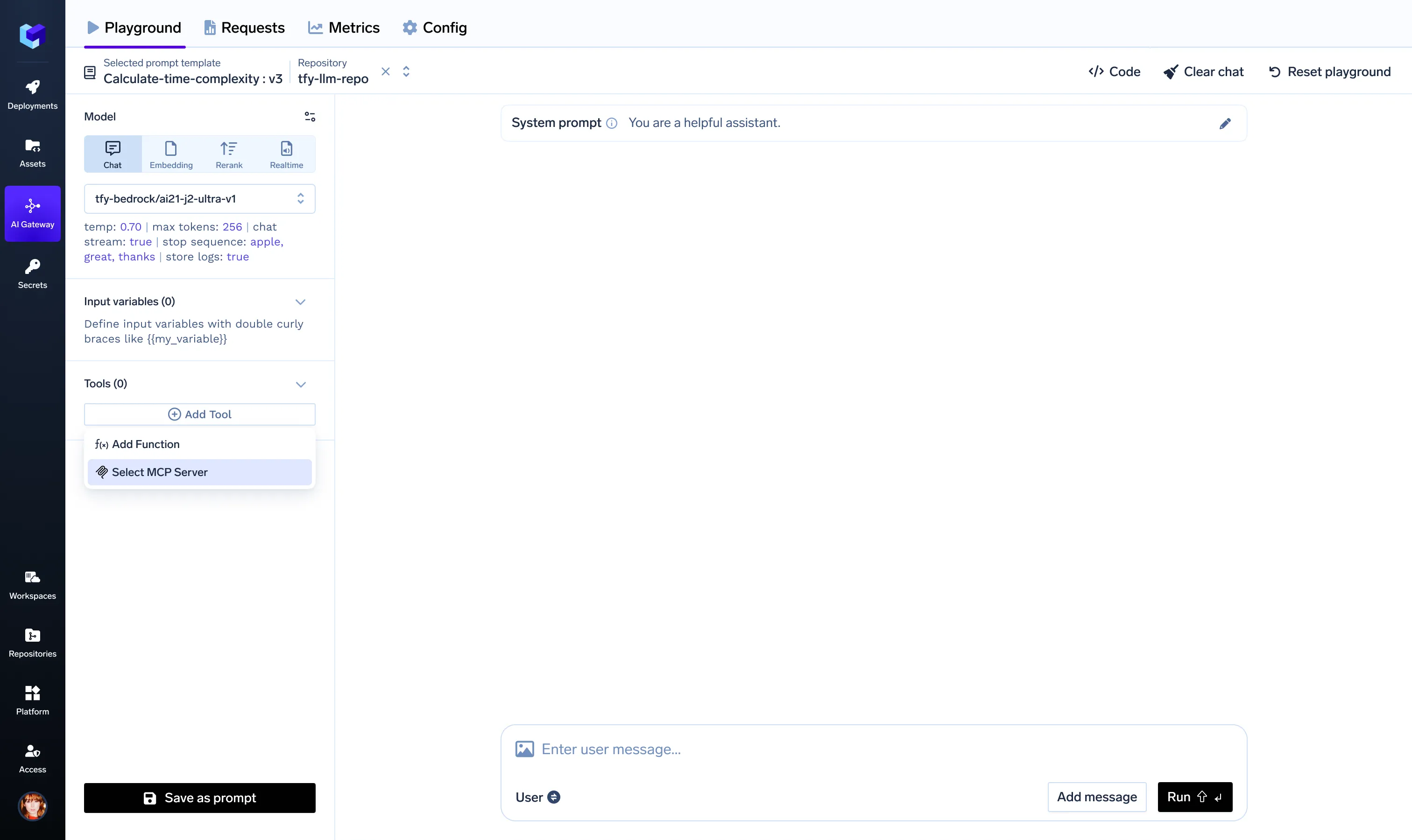
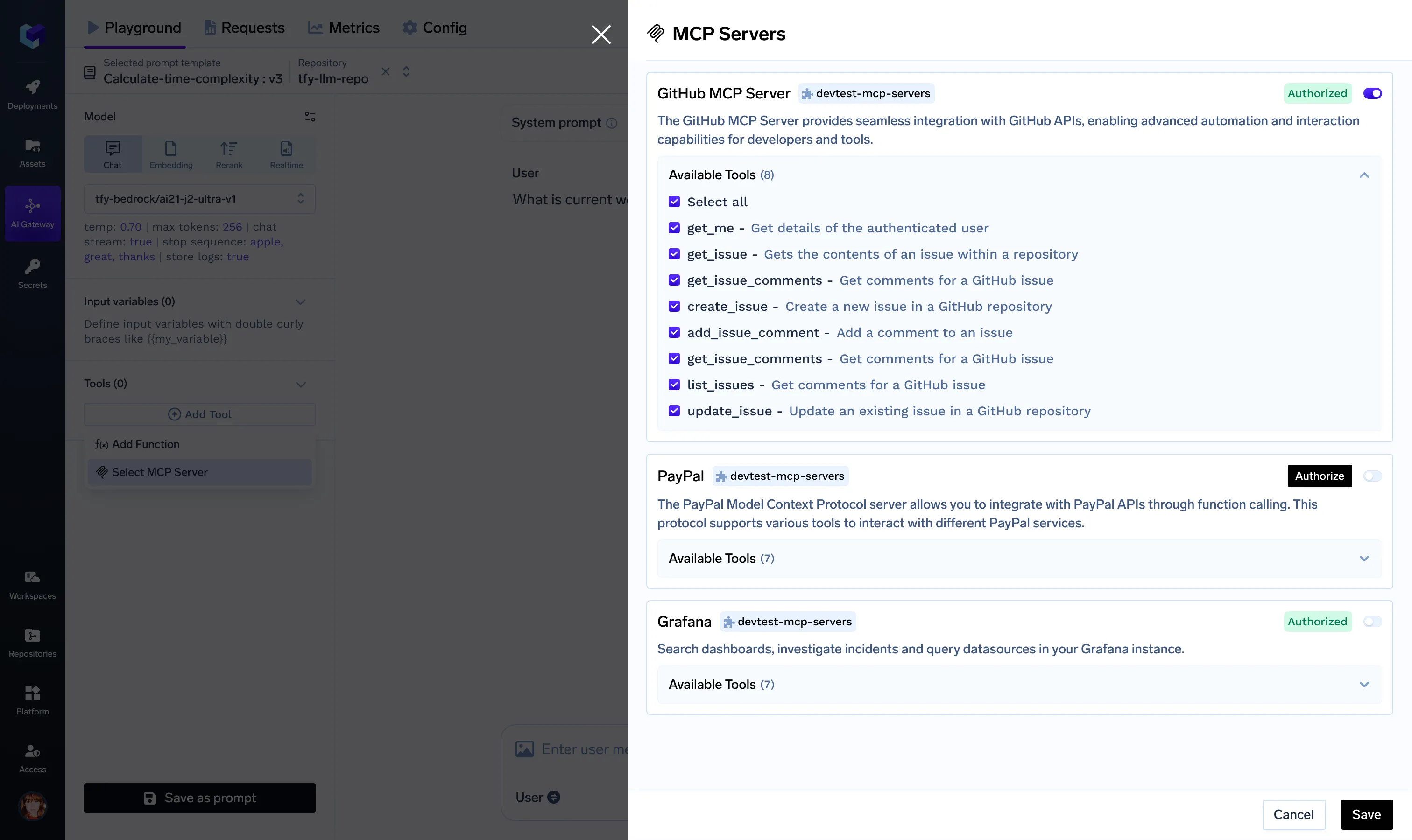
If the user is not authorised, we use the OAuth2 client information in the integration and walk the user through the OAuth2 Authorisation code flow. At the end of the process, TrueFoundry securely saves the Access and Refresh Tokens (if supported and enabled).
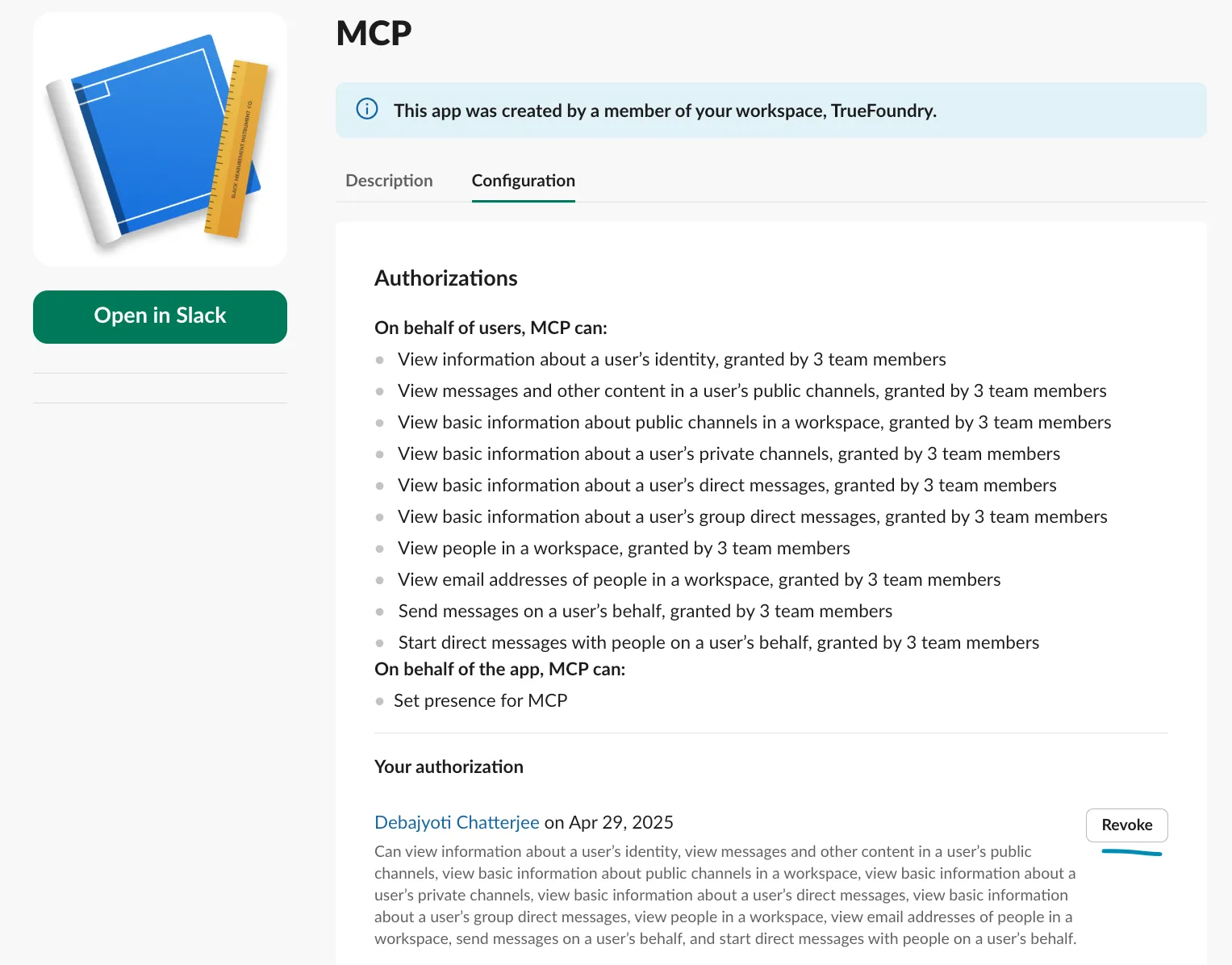
We can remove our credentials from TrueFoundry or even revoke them directly from the Provider.
Once authorised, you can use the context from the MCP servers directly on our Playground.
Note that we do not pass any OAuth2 Credentials to the frontend. Frontend calls an API:
curl -X POST "https://base-url/api/llm/agent/responses" \
-H "Authorization: Bearer YOUR_API_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"model": "openai-main/gpt-4o-mini",
"messages": [
{
"role": "user",
"content": "what are the issues in my app"
}
],
"tools": [
{
"type": "mcp-server",
"integration_fqn": "truefoundry:custom:devtest-mcp-servers:mcp-server:sentry",
"tools": ["list_projects", "list_issues"]
},
{
"type": "mcp-server",
"integration_fqn": "truefoundry:custom:devtest-mcp-servers:mcp-server:slack"
}
]
}'
LLM Gateway implements the “agentic” loop, sending the initial messages and the MCP Server’s tool descriptions to the LLM. The user can also filter the tools exposed to the LLM. Based on the LLM’s Response, LLM Gateway can communicate with the MCP Servers and pass on the callers’ credentials. We automatically refresh any short-lived credentials. The updates are sent to the frontend using SSE.
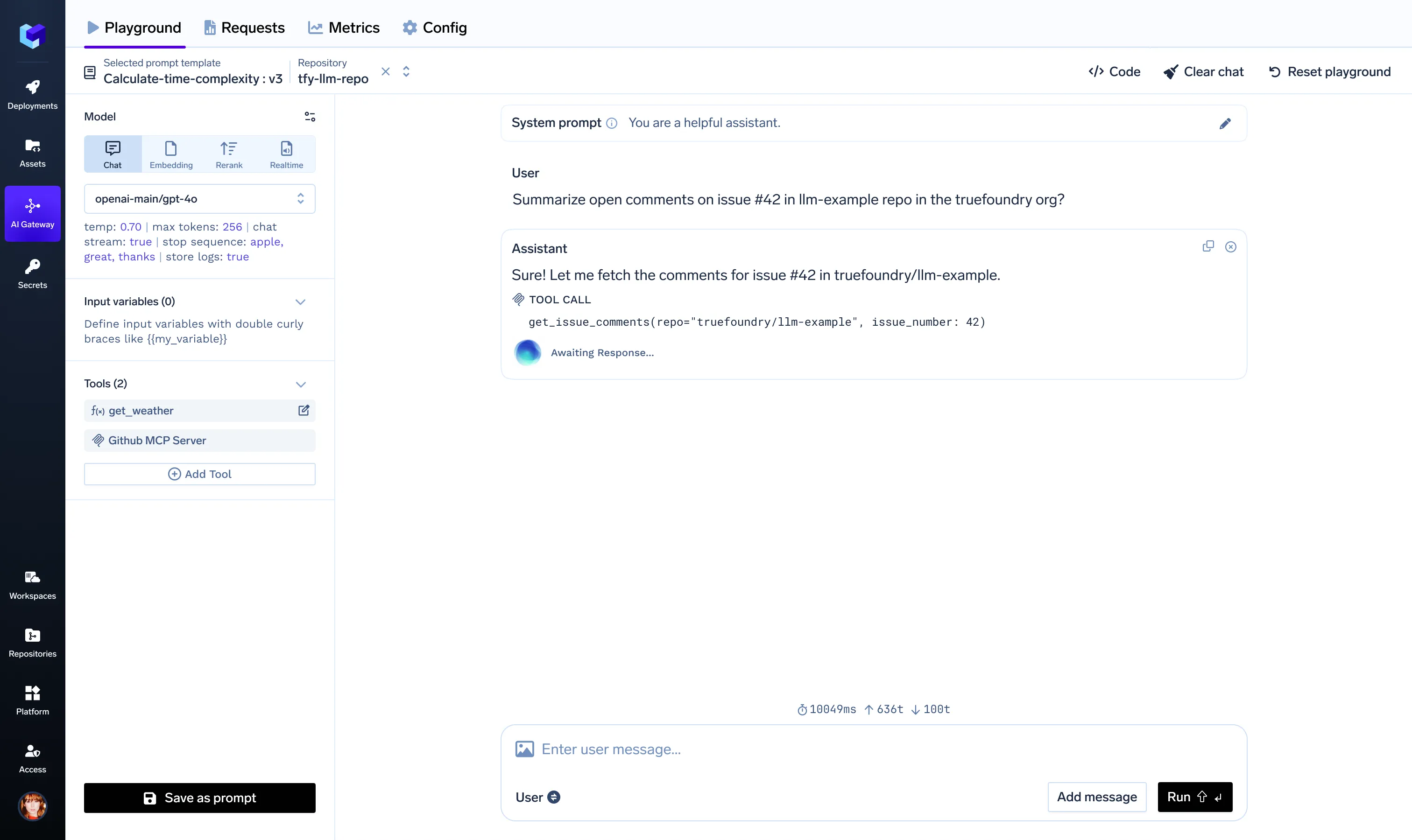
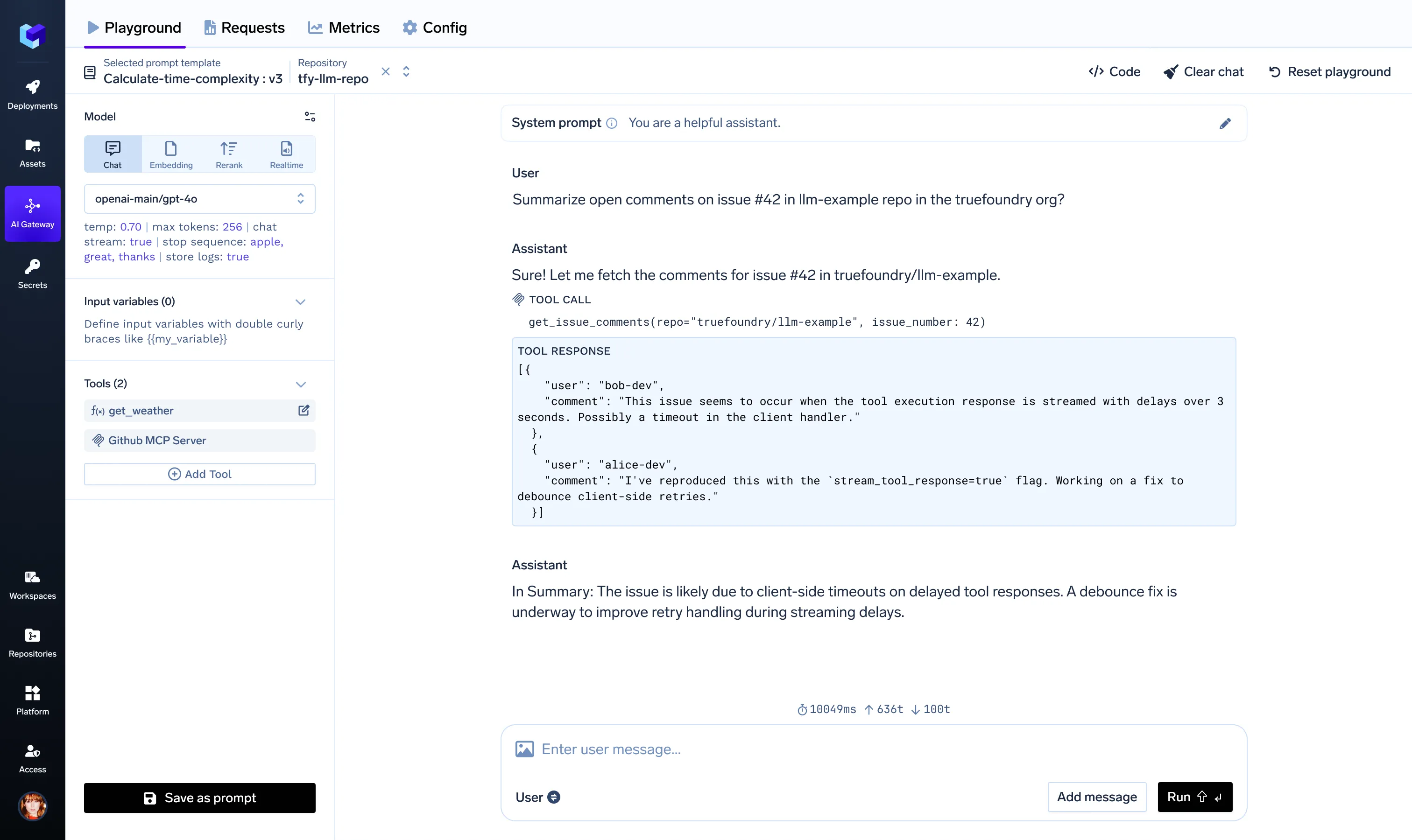
This MCP + OAuth2 flow enabled our colleagues to securely incorporate data from providers like Slack, GitHub, Sentry, etc., into their LLM-centric workflow.
A couple of use cases,
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox
© 2026 All rights reserved.






.webp)

.webp)

.webp)


.webp)
.webp)
.webp)
.png)






.webp)