from transformers import GPT2Model, GPT2Tokenizer
model_name = 'gpt2-medium' # Choose the model variant
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2Model.from_pretrained(model_name)
for epoch in range(total_epochs):
for batch in data_loader:
inputs, labels = batch
outputs = model(**inputs)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
{"prompt": "What is 2 + 2?", "completion": "The answer to 2 + 2 is 4"}
{"prompt": "Flip a coin", "completion": "I flipped a coin and the result is heads!"}
{"prompt": "", "completion": ""}
Therefore, the behavior of models like GPT-3 and later versions can be adjusted to suit specific applications or to conform to particular content styles and preferences.
While it's not strictly "no-code" because it involves an API, setting it up for training is straightforward compared to the other tools introduced in the previous section.
Fine-tuning code example:
Preparing the Dataset
To fine-tune a model, you first need to prepare your dataset in a format that the OpenAI API can understand. Typically, you'll create a JSON file like the following:
{"prompt": "The capital of France is", "completion": " Paris"}
{"prompt": "The largest planet in the solar system is", "completion": " Jupiter"}
Uploading the Dataset to OpenAI
Datasets can be easily uploaded using the OpenAI CLI (Command Line Interface).
Once the fine-tuning process is complete, you can use the fine-tuned model for text generation and other tasks by specifying its ID.
response = openai.Completion.create(
model="YOUR_FINE_TUNED_MODEL_ID",
prompt="The capital of Italy is",
max_tokens=50
)
print(response.choices[0].text.strip())
It is also possible to deploy the fine-tuned model.
Key Features:
Ease of Use: The API simplifies interaction with powerful AI models, eliminating the complexity of directly managing or training large neural networks.
Scalability: OpenAI handles infrastructure and scaling, providing consistent performance regardless of workload.
Continuous Updates: OpenAI frequently updates its API and models, giving users access to the latest advancements in AI research.
3. Microsoft Azure
Microsoft Azure is a cloud computing platform that offers a wide range of services, including computing, storage, and analytics. It provides users with tools to efficiently build, deploy, and manage applications.
Replicateは、ソフトウェアアプリケーションのさまざまな側面をファインチューニングするために設計された多機能ツールです。ファインチューニングツールとしてのReplicateの用途には、パフォーマンスの最適化、構成の調整、最小限の労力での機能強化が含まれます。GPUのセットアップを処理することで、プロセスを簡素化します。Open AI APIと同様に、リストにある他のツールのように厳密には「ノーコード」ではありませんが、前のセクションの他のツールと比較して、トレーニングのために簡単にセットアップできます。
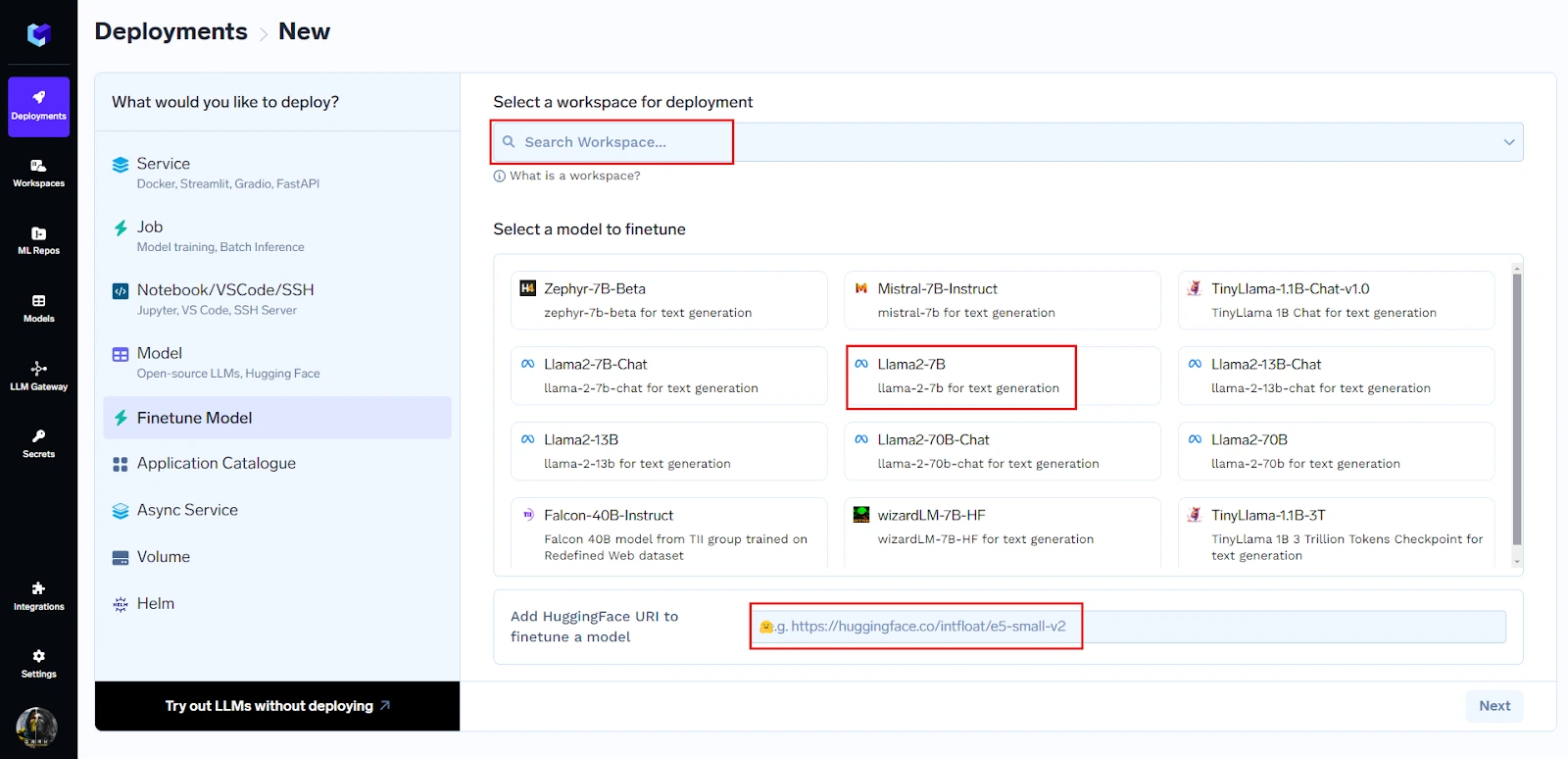
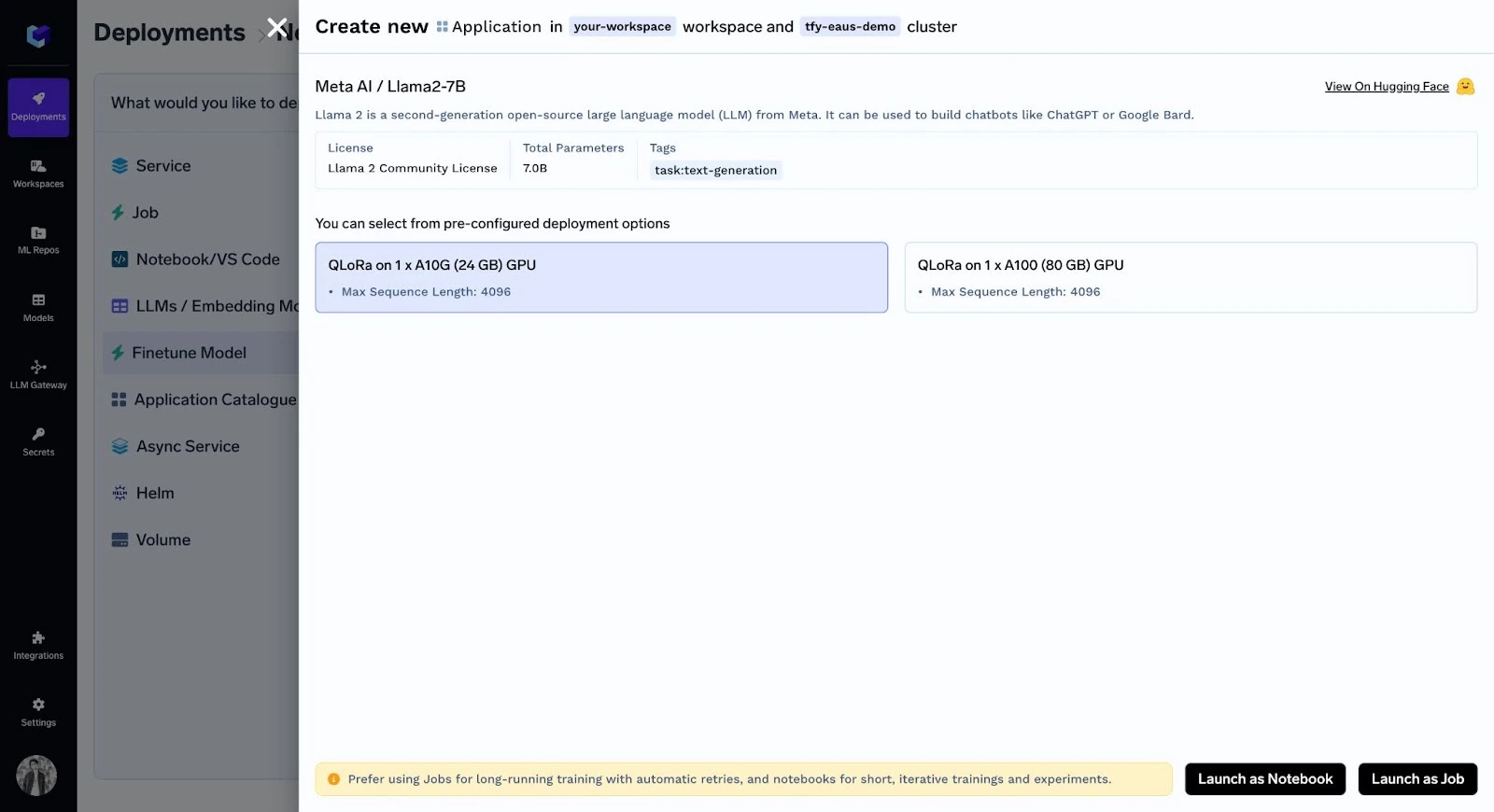
llama-2bのファインチューニング手順:
トレーニングデータを準備する
トレーニングデータはJSONL形式である必要があります。以下に、このファイルの構造例を示します。
{"prompt": "What's the weather like?", "completion": "The weather is sunny."}
{"prompt": "Tell me a joke.", "completion": "Why don't scientists trust atoms? Because they make up everything!"}
import replicate
training = replicate.trainings.create(
version="meta/llama-2-7b:version-id", # Replace "version-id" with the actual version ID of the model you chose
input={
"train_data": "https://yourdata.com/data.jsonl", # Use your actual data URL here
"num_train_epochs": 3
},
destination="your-username/your-model-name" # Use your actual username and model name here
)
print(training)
トレーニングの進捗を監視する
プログラムで進捗を監視するには、以下を使用できます。
training.reload()
print(training.status)
ファインチューニング済みモデルを実行する
トレーニングが完了したら、APIでモデルを実行できます。
output = replicate.predictions.create(
version=training.output["version"], # Use the version output from your training
input={"prompt": "Your prompt here"}
)
print(output)
import sagemaker
from sagemaker.huggingface import HuggingFace
# Initialize a sagemaker session
sagemaker_session = sagemaker.Session()
# Set up the role for SageMaker
role = sagemaker.get_execution_role()
ファインチューニングスクリプトの準備:
Typically, you create a fine-tuning script (train.py) to pass to the estimator. This script should include the logic for loading, fine-tuning, and saving the model.
# Define hyperparameters (if any), model name, and fine-tuning script
hyperparameters = {'epochs': 3, 'train_batch_size': 16, 'model_name': 'distilbert-base-uncased'}
huggingface_estimator = HuggingFace(
entry_point='train.py', # Your script name
instance_type='ml.p3.2xlarge', # Training instance type
instance_count=1, # Number of instances
role=role, # IAM role with permissions
transformers_version='4.6.1', # Transformers library version
pytorch_version='1.7.1', # PyTorch library version
py_version='py36', # Python version
hyperparameters=hyperparameters)
Create a Hugging Face Estimator:
# Define hyperparameters (if any), model name, and fine-tuning script
hyperparameters = {'epochs': 3, 'train_batch_size': 16, 'model_name': 'distilbert-base-uncased'}
huggingface_estimator = HuggingFace(
entry_point='train.py', # Your script name
instance_type='ml.p3.2xlarge', # Training instance type
instance_count=1, # Number of instances
role=role, # IAM role with permissions
transformers_version='4.6.1', # Transformers library version
pytorch_version='1.7.1', # PyTorch library version
py_version='py36', # Python version
hyperparameters=hyperparameters
)
Start the training job:
# Assuming you have your training data in an S3 bucket
data = {'train': 's3://your-bucket/train-dataset/', 'test': 's3://your-bucket/test-dataset/'}
# Fit the model
huggingface_estimator.fit(data)
Key Features:
Support for Built-in Algorithms and Major Frameworks: SageMaker supports TensorFlow, PyTorch, Hugging Face, and more, making it easy to fine-tune LLMs with custom datasets.
Managed Spot Training: Reduce model training costs by using Amazon EC2 Spot Instances.
Distributed Training: SageMaker simplifies faster and more cost-effective model training by distributing training jobs across multiple GPUs or instances.
2. Google Colab:
Google Colab is a popular cloud-based Jupyter Notebook service that provides free access to computing resources, including GPUs and TPUs, making it an ideal platform for fine-tuning Large Language Models (LLMs).
Especially for beginners. Colab notebooks run directly in the cloud from your browser, without requiring any local setup.
Below is a simple code snippet for fine-tuning a Transformer model using Hugging Face Transformers and PyTorch in Google Colab.
Environment Setup:
!pip install torch torchvision transformers
Load Pre-trained Model and Tokenizer:
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import AdamW
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# Prepare the model for training
model.train()
Fine-tuning the Model: (Assuming the dataset is loaded into variables input_ids, attention_masks, and labels)
from torch.utils.data import DataLoader, RandomSampler, TensorDataset
# Create a data loader
dataset = TensorDataset(input_ids, attention_masks, labels)
dataloader = DataLoader(dataset, sampler=RandomSampler(dataset), batch_size=32)
optimizer = AdamW(model.parameters(), lr=2e-5)
# Example training loop
for epoch in range(4): # loop over the dataset multiple times
for step, batch in enumerate(dataloader):
batch = [r.to('cuda') for r in batch] # Move batch to GPU
b_input_ids, b_input_mask, b_labels = batch
# Forward + backward + optimize
outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels)
loss = outputs[0]
loss.backward()
optimizer.step()
optimizer.zero_grad()
Free Access to GPUs/TPUs: Colab provides free access to NVIDIA GPUs and Google TPUs, which can significantly accelerate the training and fine-tuning of machine learning models.
Google Driveとの連携:データセットやモデルをGoogle Driveから直接、簡単に保存・アクセスでき、データ処理やモデルの保存がスムーズになります。
プリインストールされたライブラリ:Colabには、TensorFlow、PyTorch、Hugging Face Transformersなど、データサイエンスや機械学習の主要なライブラリのほとんどがプリインストールされており、すぐにモデルのファインチューニングを開始できます。
from torch.utils.data import DataLoader
from transformers import AdamW
dataloader = DataLoader(dataset, shuffle=True, batch_size=8)
optimizer = AdamW(model.parameters(), lr=1e-5)
model.train()
for epoch in range(3): # Loop over the dataset multiple times
for batch in dataloader:
optimizer.zero_grad()
inputs, labels = batch['input_ids'], batch['labels']
outputs = model(inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
train.pyスクリプトには、LLaMA-2(または選択したモデル)の読み込み、データセットの読み込み、およびファインチューニングプロセスを実行するためのロジックを含める必要があります。これには、モデルの読み込みにHugging Face Transformers、トレーニングループにTensorFlowまたはPyTorchなどのライブラリを使用することが含まれる場合があります。
from transformers import LlamaForConditionalGeneration, LlamaTokenizer
# Load model and tokenizer
model = LlamaForConditionalGeneration.from_pretrained('Llama-2-model-name')
tokenizer = LlamaTokenizer.from_pretrained('Llama-2-tokenizer-name')
# Load your dataset, prepare data loaders, define your training loop here #
model.train()
for epoch in range(num_epochs):
for batch in dataloader:
# Training loop logic
pass
# Save your fine-tuned model
model.save_pretrained('./fine-tuned-model')
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.
































.webp)




%20(11).webp)


.png)








.webp)
.webp)


