














October 5, 2023
|
5 min read

Published: July 4, 2026

Blazingly fast way to build, track and deploy your models!
The rise of Agentic AI, where AI systems operate semi-autonomously across workflows, APIs, and data sources—has fundamentally changed the data landscape. Every prompt, response, and contextual action in an AI system is data: data that may reveal intellectual property, customer interactions, or even sensitive corporate strategies. As organizations scale these AI systems globally, a question that once belonged to compliance teams has now become a boardroom concern: where does your data live, and who can access it?
This is the essence of data residency — ensuring that data remains within a defined geographic or legal boundary. What was once a regulatory checkbox has become a strategic necessity in an increasingly geopolitical AI landscape.
In this article, we explore why data residency is gaining urgency in the Agentic AI world, what Gartner calls the emerging trend of geopatriation, and how organizations can build for sovereignty and scale using an AI Gateway architecture, and how TrueFoundry’s AI Gateway delivers flexible, region-aware data control that aligns with these evolving imperatives.
Data residency refers to where organizational data is physically stored and legally governed. In the pre-AI era, this typically applied to structured data—databases, CRMs, analytics systems. Today, in the AI era, this extends far beyond storage. Every AI model interaction generates new forms of data: prompts, completions, embeddings, logs, and contextual memory.
Each of these elements can contain: - Sensitive intellectual property or trade secrets. - Personally identifiable or regulated information (PII). - Confidential business strategies or customer details. Even ephemeral data - stored only for milliseconds during inference can fall under data-sovereignty rules if it crosses borders. AI therefore expands the definition of data residency from “where data rests” to “where it moves
For organizations leveraging third-party LLM APIs or global AI platforms, even transient data may pass through jurisdictions with different privacy laws. Under regulations such as the EU GDPR, India’s Digital Personal Data Protection Act (DPDP), or Australia’s Privacy Act, these cross-border transfers create compliance and reputational risks.
In short: AI isn’t just producing insights - it’s generating new data liabilities. Every inference request is a micro-transaction of sensitive data that needs to be treated with the same rigor as stored information.
Historically, only highly regulated sectors- financial services, healthcare, defense, and government worried about data residency. But in 2025, the trend has gone mainstream. Gartner’s Understanding the Landscape of Cloud Repatriation and Geopatriation (Sept 2025) notes that non-U.S. organizations are increasingly cautious about hosting data with U.S. or China-based cloud hyperscalers. Legislative developments like the U.S. CLOUD Act have intensified these concerns by granting U.S. authorities access to data held by American providers, even if that data resides outside U.S. borders. Major hyperscalers have also responded with sovereign-cloud offerings - AWS European Sovereign Cloud, Google’s EU Sovereign Cloud, and Microsoft Cloud for Sovereignty each designed to reassure enterprises facing rising regulatory fragmentation.
In parallel, global enterprises are facing fragmentation in data regulation: - The EU enforces strict cross-border data transfer limits under GDPR. - India mandates storage of critical personal data within the country. - Australia and the Middle East are introducing region-specific AI governance frameworks.
According to Gartner, inquiries about cloud sovereignty and geopatriation rose 305% in the first half of 2025, signaling that this concern has moved from niche to critical. In other words, organizations no longer view data residency as compliance hygiene—they see it as strategic risk management.
This shift is particularly pronounced for AI-first companies and SaaS providers. Their products often rely on user prompts, inference logs, and AI model telemetry that might traverse global infrastructure. For them, ensuring jurisdictional control isn’t optional—it’s foundational to customer trust and regulatory continuity.
In its Top Strategic Technology Trends for 2026 report (Oct 2025), Gartner introduced a pivotal concept: Geopatriation. Defined as the relocation of workloads from hosting environments perceived to carry geopolitical risks to those offering greater sovereignty, geopatriation is expected to reshape how enterprises design their digital stacks.
Gartner predicts that by 2030, more than 75% of European and Middle Eastern enterprises will geopatriate their workloads into solutions that mitigate geopolitical exposure—up from less than 5% in 2025. This is a staggering projection, underscoring that sovereignty is becoming as important as scalability.
Gartner also positions Geopatriation within its Vanguard theme—alongside Preemptive Cybersecurity, Digital Provenance, and AI Security Platforms—indicating that data sovereignty is now core to digital trust. In an AI-driven enterprise, digital trust directly correlates with adoption, customer confidence, and regulatory resilience.
In essence, data sovereignty has become a board-level technology strategy, not merely a compliance checkbox.
As organizations embrace agentic AI systems, the AI stack must evolve to embed residency controls at every layer—from inference to observability. Here are five design principles for AI architectures that respect jurisdictional data boundaries:
These design principles ensure not just compliance, but also operational agility. Sovereign-by-design systems are inherently more adaptable to evolving data laws.
In an AI-first enterprise, the AI Gateway becomes the nexus for enforcing sovereignty. Sitting between applications, users, and AI models, the gateway centralizes all AI traffic, providing a single point to apply residency and governance policies. This is also why modern AI gateways are increasingly being viewed as part of broader AI security platforms, because they combine routing, policy enforcement, auditability, and data-sovereignty controls in one operational layer.
要するに、AIゲートウェイは トラフィックコントローラーとコンプライアンスファイアウォールの両方の役割を果たし、イノベーションが主権を犠牲にすることなく実現されることを保証します。
TrueFoundryの AIゲートウェイ は、データレジデンシーと主権を核として構築されました。これにより、組織は厳格な地域管理を維持しながら、AIワークロードをグローバルに拡張できます。
このアーキテクチャにより、企業はスケーラビリティ、レイテンシー、開発者の生産性を犠牲にすることなく、データ主権の要件を満たすことができます。
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

以下は、マルチリージョン企業がTrueFoundryのAIゲートウェイを通じてAIデータフローを管理する方法の概念図です。
この設定では: - プロンプトと応答 各地域のユーザーからのものは、それぞれのローカルAIゲートウェイエンドポイントによって処理されます。
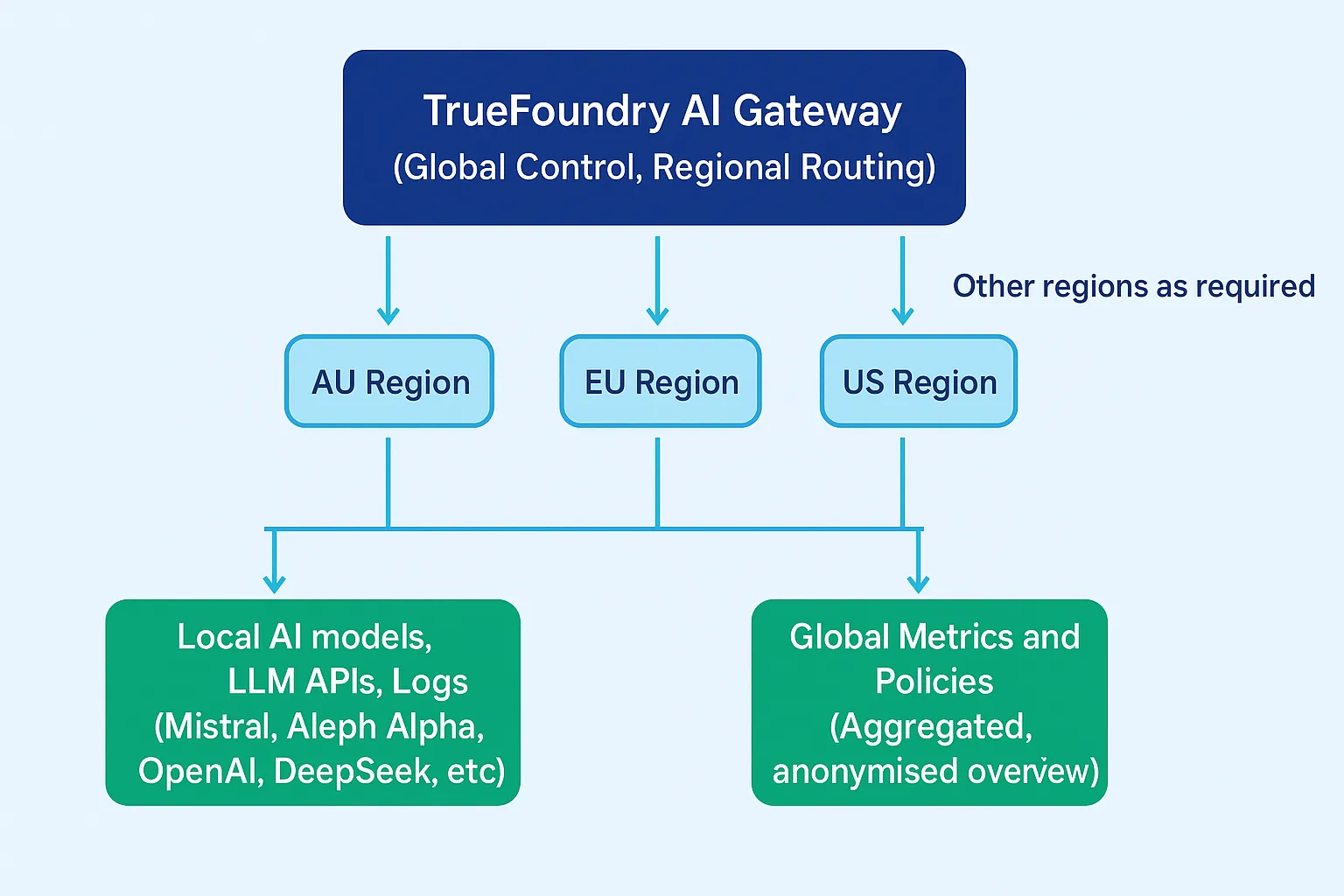
- ログ は地域ごとに保存され、管轄区域を越えることはありません。
- グローバル管理者 生データにアクセスすることなく、パフォーマンスと使用状況のメトリクスを把握できます。
このアーキテクチャは 断片化することなくデータ主権を実現します—国境を尊重しつつ一貫性を保つ、統一されたAIレイヤーです。
エージェントAIシステムがワークフローを自動化し、ますます自律的な意思決定を行うようになるにつれて、組織とAIモデル間の信頼の境界線は拡大しています。この新しい時代で成功を収める組織は、俊敏性と主権のバランスを取れる組織となるでしょう。
データレジデンシーはもはやコンプライアンスのチェックリストではなく、 AIインフラ戦略の中核をなす柱です。ガートナーがジオパトリエーションを2026年の主要テクノロジートレンドとして特定したことは、この方向性を裏付けています。企業は、データの所在が、いかに安全かつ責任を持ってイノベーションを起こせるかに直接影響することを認識しているのです。
AIゲートウェイは、 TrueFoundryの エンタープライズAIインフラストラクチャにおける次の進化形です。 これらは、組織がグローバルに規模を拡大し、ローカルで運用し、容易にコンプライアンスを維持することを可能にします。AIが遍在する世界において、 データの所在地の管理は、運命の管理に等しいのです。
参考文献:
ガートナー 2026年の主要テクノロジートレンド トップ10
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








最新のニュース、記事、リソースをメールでお届けします
© 2026 無断複写・転載を禁じます。






.webp)





.png)








.webp)
.webp)


