

July 22, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 8, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
A 2026 application doesn't talk to one model — it talks to a menu of them, spanning frontier, mid-tier, cheap, and self-hosted. Routing is the policy that picks one per request, navigating three goals that pull against each other: cost, latency, and quality. This post walks the routing strategies from static rules to semantic routing and model cascades, the hard problem of measuring the quality you want to route on, why routing is not failover, and the instrumentation that keeps a router from quietly betraying you.
Tuesday at Northwind. Omar, a platform engineer, had spent the quarter proud of one number: a 41% drop in the company's LLM bill. He'd built a router. Simple classification and intent-detection calls went to a cheap model; only the genuinely hard requests — multi-step reasoning, code generation — reached the frontier model. It worked. Finance noticed.
Then the second week's bill came in at three times the first week's, with no traffic increase. Omar traced it. His cascade had a verifier — the cheap model's output was schema-checked, and on a failed check the request escalated to the frontier model. A provider-side update had subtly changed the cheap model's output formatting, the schema check started failing on most responses, and the router had quietly escalated about 90% of traffic to the most expensive model. Nothing errored. Nothing alerted. The router did exactly what it was told; it just stopped doing what Omar meant. The escalation rate had been climbing for nine days, and nobody was watching it.
Routing is often one of the highest-leverage cost levers in an LLM stack and one of the easiest to get quietly wrong. This post is the strategies, their tradeoffs, and the instrumentation that keeps a router honest.
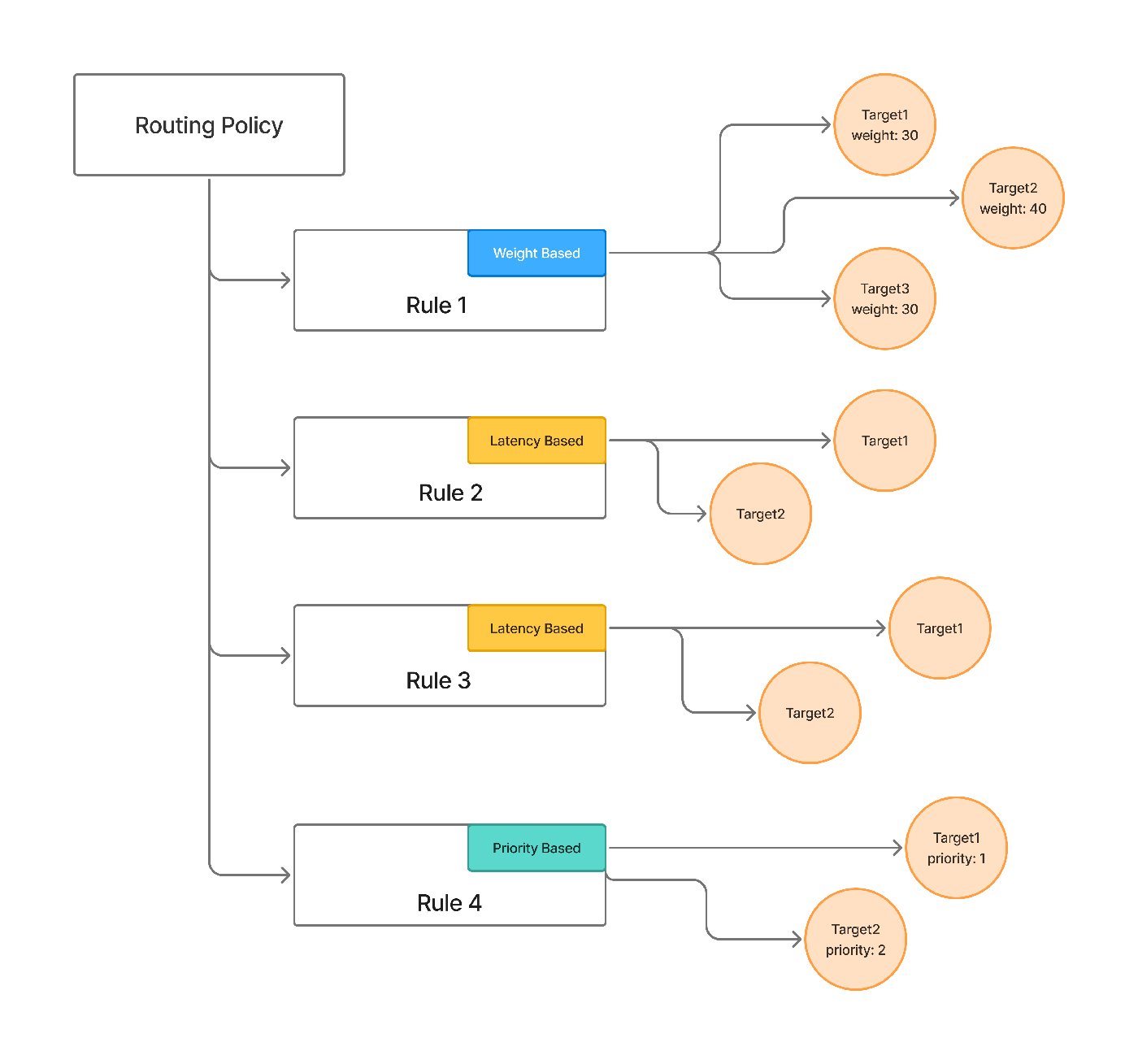
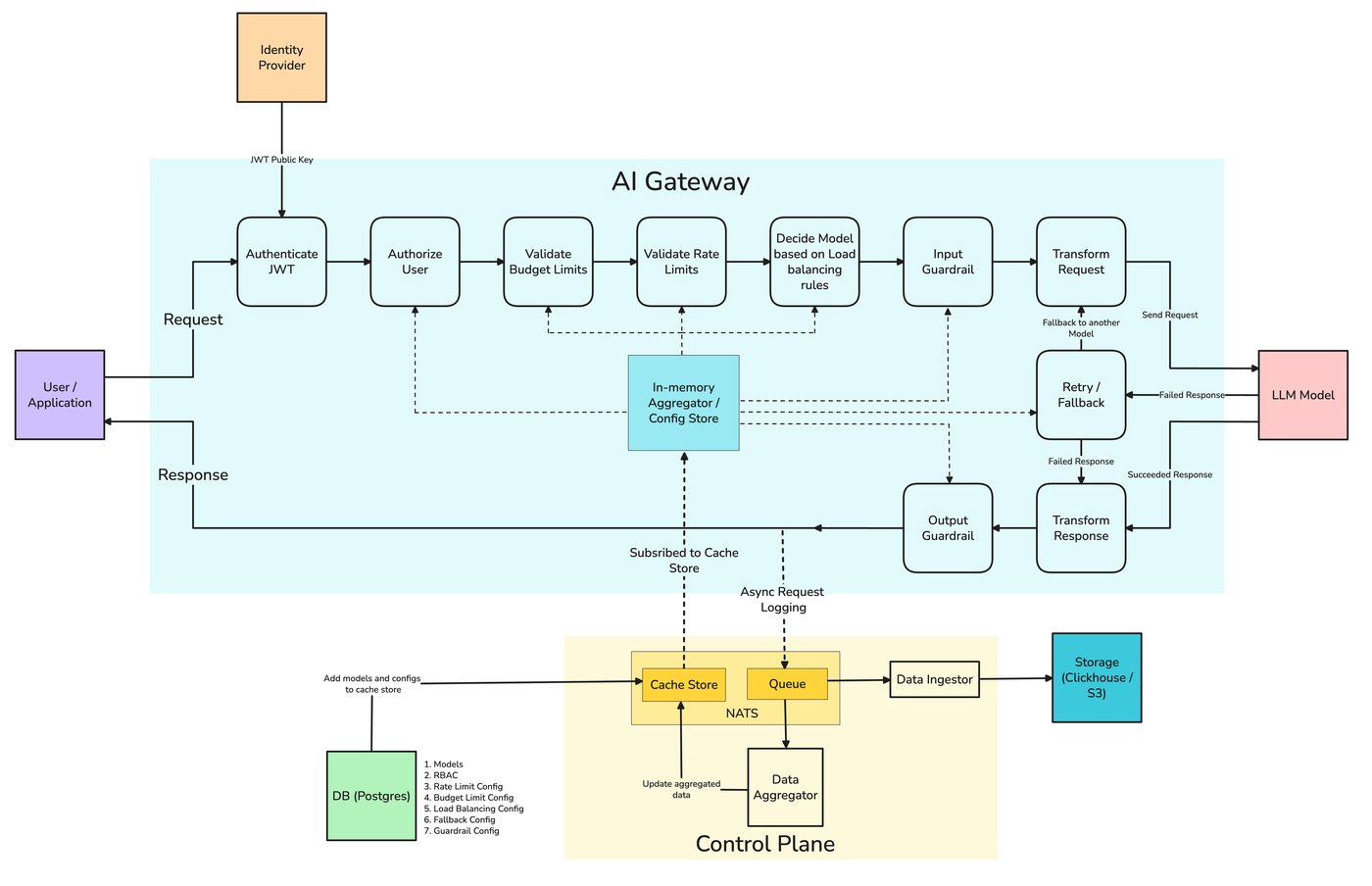
The routing strategies in this post aren't abstractions — they're how TrueFoundry's AI Gateway is configured. Its routing configuration matches each request by model, by subject (user, team, or virtual account), or by an X-TFY-METADATA header, evaluates rules top-to-bottom with first-match-wins, and sends the request to a target model — all as YAML applied at the gateway rather than branching logic in the app.
The three strategies map onto the ladder in section 2: weight-based for splits and canaries, latency-based to favor the lowest-latency healthy target, and priority-based for ordered preference with fallback. Per-target overrides also cover the model-specific-prompt problem this post raises — you can attach a different prompt_version_fqn per target so each model gets a prompt tuned for it — alongside per-target retries and fallback. (For new setups the docs recommend Virtual Models, which package the same strategies, retries, and fallbacks with clearer per-model ownership and access control.)
Calling the gateway from an application is a one-line change for anything already using the OpenAI SDK — same client, different base URL and key — and the routing decision happens at the gateway, not in your code. The application can also pass an X-TFY-METADATA header so the gateway routes by task, environment, or tenant without conditional code paths:
Calling the gateway from Python (OpenAI-compatible API)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-personal-access-token>", # Bearer-auth'd JWT
)
resp = client.chat.completions.create(
model="assistant", # logical/virtual model — gateway picks the target
extra_headers={"X-TFY-METADATA": '{"task": "classify"}'}, # drives the matching rule
messages=[{"role": "user", "content": "..."}],
)An enterprise app in 2026 has a menu of models with very different economics. Cheap models (Claude Haiku 4.5 at roughly $1 per million input tokens) are several times less expensive than frontier models on current standard rates, and often lower-latency in practice. Mid-tier models (Sonnet 4.6 at $3 per million input) sit in between. Self-hosted open-weight models (Llama, Mistral) trade per-token pricing for fixed GPU capacity and data control — cheaper at sustained high utilization, but expensive when utilization is low. Each model also has a different quality profile per task: a model that's excellent at code may be mediocre at extraction, and vice versa.
Routing is the policy that maps each incoming request to one of these models. The three goals pull against each other: the cheapest model is rarely the highest-quality, the fastest is not always the cheapest, and the best-quality model for a hard task is wasted on an easy one. The naive default — send everything to the best frontier model — maximizes quality but is the most expensive option and frequently the slowest, applying a multi-step reasoning model to requests a cheap model would answer correctly in a fraction of the time and cost. Routing is where that cost/quality frontier gets navigated, one request at a time.
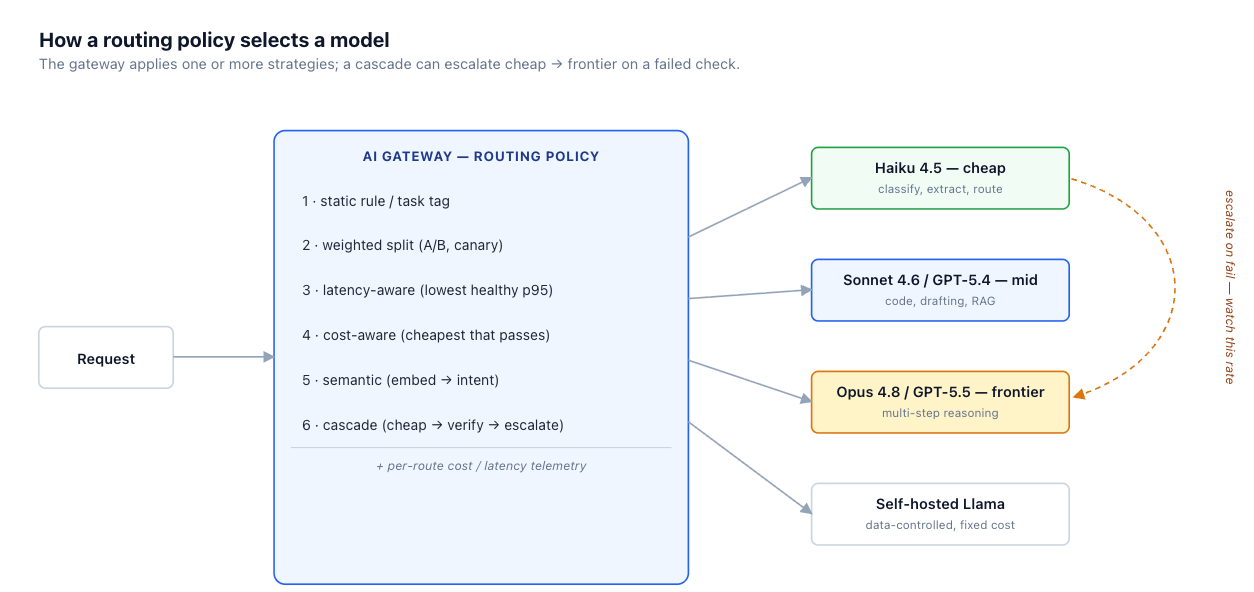
Routing strategies form a ladder. Each rung adds capability and cost, and the right place to stop is wherever the measured benefit stops justifying the added complexity.
Static / rule-based. Route by endpoint, header, or a task tag the caller sets — classification goes to the cheap model, code generation to the mid-tier. Sub-millisecond, deterministic, and trivially debuggable. This works whenever the caller already knows the task type, which is more often than teams assume.
Weighted / load-balanced. Split traffic by percentage across models. This is the basis for A/B testing a new model and for canary rollouts — send 5% of traffic to the new model, watch the metrics, ramp if they hold.
Latency-aware. When several models are acceptable for a request, route to the one with the lowest healthy p95 right now. Useful for latency-sensitive paths where any of a few models would do.
Cost-aware. Pick the cheapest model that clears a quality bar for the task. This requires knowing the quality bar per task (section 5), which is the hard part.
Be careful what "cheapest" means: route on total request cost, not the nominal input-token rate. The real figure is expected input tokens plus expected output tokens, adjusted for cache-hit rate, retry and hedge probability, cascade escalation probability, and any regional, priority, or fast-mode multiplier. Tokenizers differ across families too — Anthropic notes that Opus 4.7 and later can emit up to 35% more tokens for the same text — so an identical prompt produces different billable counts on different models. Estimate route cost from real traces, not by copying a rate card into a static table.
The last two rungs — semantic routing and model cascades — get their own sections. Most production routers are a blend: static rules for known task tags, a cost- or latency-aware default for everything else, and a separate fallback list for availability. The config below is illustrative; the exact schema is gateway-specific.
Illustrative routing policy (conceptual — exact schema is gateway-specific)
routes:
- match: { header: "x-task", equals: "classify" }
target: claude-haiku-4-5 # cheap tier
- match: { header: "x-task", equals: "code" }
target: claude-sonnet-4-6
- default:
strategy: cost_aware # cheapest model that passes the task's quality bar
candidates: [claude-sonnet-4-6, gpt-5.4]
fallback: [gpt-5.5] # availability, NOT optimization — see section 6Here's how the ladder above looks in TrueFoundry's AI Gateway, which is where these strategies actually run. Routing is a YAML gateway-load-balancing-config: each rule matches a slice of traffic — by model, team, or an X-TFY-METADATA header — and routes across its targets using weight-based, latency-based, or priority-based selection. Adding a model or shifting a split is a config change, not a redeploy:
How TrueFoundry expresses these strategies (gateway-load-balancing-config)
name: routing-config
type: gateway-load-balancing-config
rules:
- id: classify-to-cheap # static task tag -> cheap tier
type: weight-based-routing
when:
models: [assistant]
metadata: { task: classify }
load_balance_targets:
- target: anthropic/claude-haiku-4-5
weight: 100
- id: default-lowest-latency # everything else -> fastest healthy target
type: latency-based-routing
when:
models: [assistant]
load_balance_targets:
- target: anthropic/claude-sonnet-4-6
- target: openai/gpt-5.4Each target can also carry retries, a fallback list, and even a per-target prompt (prompt_version_fqn) so each model gets a prompt tuned for it. Because one file expresses both the routing policy and the fallback chain, the two stay distinct and separately observable — the line section 6 draws. The full schema is in the routing config docs.
The same file handles a canary rollout — the weighted-split pattern this post recommends for A/B-ing a new model — with no app-side branching:
Canary rollout with weight-based routing (from the docs)
name: loadbalancing-config
type: gateway-load-balancing-config
rules:
- id: gpt4-canary
type: weight-based-routing
when:
models: [gpt-4]
load_balance_targets:
- target: azure/gpt4-v1
weight: 90
- target: azure/gpt4-v2
weight: 10A few TrueFoundry-specific levers worth flagging for the routing decisions in this post: Virtual Models are the gateway's recommended replacement for the global routing config — they package the same weight/latency/priority strategies, retries, and fallbacks behind a single logical model name with its own access control, so a route can be promoted or swapped without changing every caller. Exact and semantic caching sit in front of the routing decision and return a stored response for repeat queries, cutting both cost and tail latency on read-heavy workloads. And the same routing config matches on X-TFY-METADATA, so one rule file can serve dev/prod and per-tenant routing — the routing layer reads what the client sent rather than the client encoding the route choice.
Static tags assume the caller knows the task. Sometimes it doesn't — a general assistant exposes one endpoint and everything arrives there. Semantic routing infers the task from the request itself: embed the prompt, find the nearest intent centroid (or run a small classifier), and route by the inferred intent.
Semantic routing — embed the request, route by nearest intent
emb = embed(req.text) # ~5–20 ms, small per-call cost
intent = nearest_centroid(emb, centroids) # e.g. "sql", "summarize", "chat", "reason"
model = ROUTING_TABLE.get(intent, DEFAULT) # intent -> specialized modelThe cost is an embedding call (roughly 5–20 ms and a small per-token charge) plus a cheap classifier step. The thing to be honest about is when this earns its keep: only when intent isn't already known at the call site. If the calling code can set a header like x-task=classify, that is free, deterministic, and better. Semantic routing belongs at the front door of a general assistant where requests are unlabeled — not bolted onto an internal pipeline that already knows what each call is for. The downsides: centroids and classifiers drift as the product's intents change and need maintenance, and a misclassification routes to the wrong model — so a semantic router still needs a sane default and a fallback. Wherever the embed-and-classify step runs, the gateway is the natural place to record the inferred intent and the model it selected on the trace, which is the per-route visibility TrueFoundry's AI Gateway already provides for the simpler strategies — and what turns a misroute into something debuggable rather than invisible.
A cascade tries a cheap model first, checks the result, and escalates to a stronger model only if the check fails. The check can be schema validation (does the output parse against the expected structure?), a confidence or self-consistency signal, or a judge model.
Cheap-first cascade with schema verification
def answer(req):
draft = call_model("claude-haiku-4-5", req)
if schema_ok(draft) and confident(draft):
return draft, "haiku"
# Escalate — but COUNT it. A rising escalation rate is a cost incident.
metrics.incr("router.escalation")
return call_model("gpt-5.5", req), "gpt-5.5"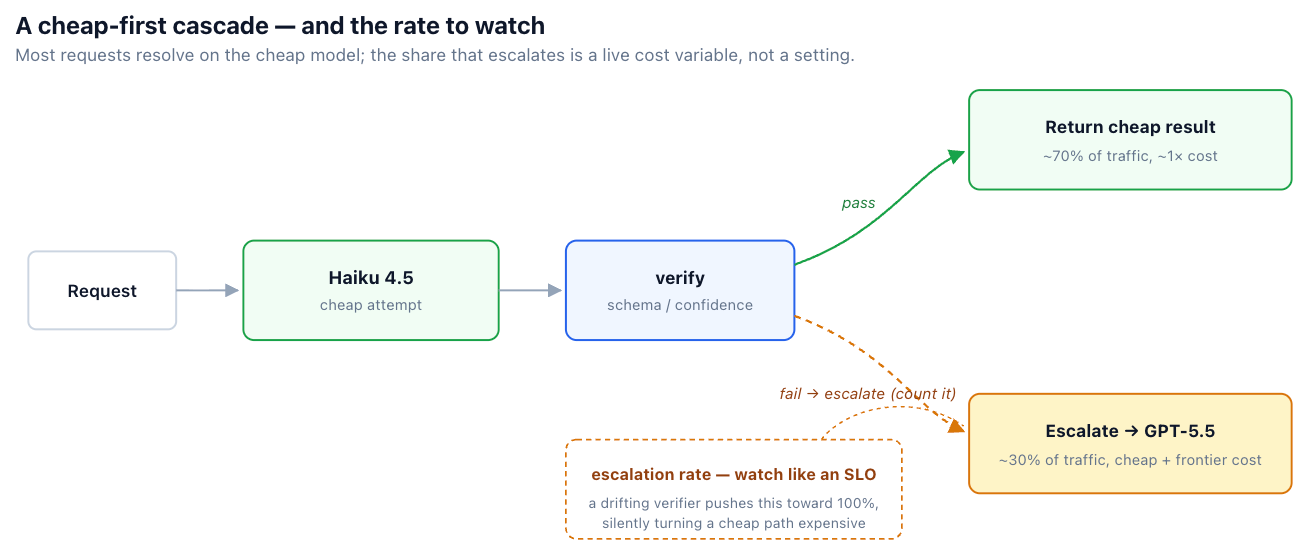
The economics can be compelling. If the cheap tier resolves most requests, blended cost falls toward the cheap tier's price. As an illustrative model: at the roughly 5× standard-rate gap between Haiku and the named frontier models, a 70% cheap-resolution rate brings blended cost to about half of frontier-everywhere — even after paying for the cheap attempt on the 30% that escalate. (Widen the gap to 10×, as some premium, pro, or priority tiers do, and the same cascade lands nearer 40%.) The exact savings depend on your resolution rate and the real price gap, so measure them rather than assuming them.
A cascade also adds the cheap model's latency to every escalated request — you pay the cheap call's time, then the frontier call's time. For interactive, latency-sensitive paths that double hop can be the wrong tradeoff; cascades shine on throughput-oriented or asynchronous workloads where the blended-cost win outweighs the tail latency on escalations.
Routing on cost or latency is straightforward because both are directly observable. Routing on quality is harder, because quality has to be measured before it can be optimized. Three approaches, in increasing order of fidelity and cost:
Offline eval sets. A curated, labeled set per task type. Run each candidate model against it and build the routing table from the results — this model for SQL, that one for summarization. Cheap to run repeatedly, but only as representative as the eval set.
Online LLM-as-judge. Sample production traffic and score responses with a judge model. Closer to real distribution, but it adds cost and latency, and the judge is itself fallible — a judge that shares the generator's blind spots will rubber-stamp them.
A/B against business metrics. The gold standard: route a slice of traffic to a candidate and measure the metric you actually care about — resolution rate, thumbs-up, downstream conversion. Slow and high-effort, but it measures the thing instead of a proxy.
The caution that ties these together: don't route on vibes. A cheap model that "seems fine" in a demo can quietly degrade a downstream metric for weeks. Tie every routing change to a measured quality gate, and remember that quality is task-specific — a single leaderboard rank is not a routing table, because the model that tops a general benchmark may be middling at your extraction task. The production signal all three methods need — which model handled which request, and what happened next — is what the gateway already records; TrueFoundry's per-route traces are a natural feed for the offline eval sets and online sampling above.
One thing all three methods have to reckon with: a production router only ever sees the model it picked. Route a request to Haiku and you never learn whether Sonnet, Opus, or GPT-5.5 would have done better — the counterfactual is invisible. To keep the routing table honest, sample a slice of traffic for shadow evaluation, replay real requests through the other candidates offline, or run periodic champion/challenger tests. Without that, a router quietly exploits a stale policy and stops noticing when another model has become better, cheaper, or safer for a task.
Routing and failover share machinery — a list of candidate models and a policy for choosing among them — which makes them easy to conflate. They are different goals, and merging them causes incidents.
Routing is optimization: when all candidates are healthy, pick the best one for cost, latency, or quality. Failover is availability: when the chosen model is down or timing out, fall back to another so the request still succeeds (the subject of the next post in this series). The distinction matters operationally. A fallback to a cheaper model triggered by an outage may silently degrade quality, and you want that recorded as "we fell back because the primary was down," not misread as a deliberate cost decision. Conversely, a transient 500 should trigger failover, not a permanent routing change. Keep the two policies separate and separately observable: "routed to X for cost" and "fell back to Y because X was unhealthy" are different events that should look different in your traces. A gateway like TrueFoundry's is where both live side by side without blurring — the routing policy and the fallback chain are configured and traced as distinct things.
Routing logic can live in the application, but the gateway is the more natural home for two reasons. First, it already normalizes the provider APIs, so switching a route from one model to another is a configuration change rather than a code change — and switching between, say, an OpenAI model and an Anthropic model doesn't mean rewriting request construction. Second, it already holds the cost and latency telemetry that routing decisions depend on; the data you need to route well is the data the gateway is already collecting.
Centralizing routing at TrueFoundry's AI Gateway means one policy applied across services, one place to A/B a new model, and one place to watch the blended cost and the cascade escalation rate that the cold open turned on. The gateway exposes routing rules, weighted load balancing, and fallback chains across both hosted and self-hosted models through a unified, OpenAI-compatible API, and the per-route cost and latency land in the same attribution view from the cost-attribution post. The division of labor is worth stating plainly: the gateway routes and gives you the numbers; the application still owns the definition of quality and the eval sets that decide which model wins each task.
Routing is not free, and the overhead differs by strategy. A static rule evaluates in well under a millisecond. Latency-aware routing needs live p95 telemetry, which is cheap to read. Semantic routing adds the embedding call — roughly 5–20 ms — plus a lightweight classifier. A cascade adds the full latency of the cheap model on every request that escalates.
The design principle is to keep the routing decision cheap relative to the model call it precedes. A sub-millisecond rule is noise against a 500 ms-plus generation; a semantic step is comfortably affordable at the front door of an assistant; a cascade's double-latency on escalations is the one to scrutinize on interactive paths. And don't add a judge-model call to every route for quality measurement unless the cascade or quality gain clearly justifies paying for a second model call on each request — sampling a fraction of traffic for online evaluation usually gets you the signal without the per-request tax. Because the routing decision and the model call sit on the same trace, the decision's own overhead is measurable rather than assumed: TrueFoundry's AI Gateway records per-route latency, so you can confirm the semantic step or the cascade hop is actually as cheap as you expect.
Should routing live in the gateway or the application?
The mechanics belong in the gateway — it normalizes provider APIs and holds the cost/latency telemetry, so routing becomes configuration rather than code. The application still owns the definition of quality and the eval sets that determine which model is best per task. Think of it as: the gateway decides where to send the request given a policy; the app decides what the policy should be.
Won't routing to cheaper models hurt quality?
Only if you route on vibes. The whole point of section 5 is that a routing change should pass a measured quality gate per task before it ships. A cheap model that meets the bar for classification is not a quality regression; a cheap model assumed to be "good enough" without measurement is how one happens.
How do I choose a cascade verifier?
Schema validation is the cheapest and most reliable verifier when the output is structured — it's deterministic and adds no model call. For open-ended outputs, a judge model is more capable but costs a second call and can be wrong. Whichever you pick, instrument the escalation rate and alert on it, because a drifting verifier is a common way a cascade quietly becomes a cost problem.
Does semantic routing add too much latency?
It adds roughly 5–20 ms for the embedding plus a cheap classification step — usually acceptable against a multi-hundred-millisecond generation, though not free for sub-100 ms classification or high-QPS internal paths, so measure it in your own path rather than assuming it's noise. The real question isn't latency, it's whether you need it at all: if the caller can label the task with a header, that's free and deterministic, and semantic routing only earns its place when requests arrive unlabeled.
How does this interact with cost attribution and failover?
Routing decisions and the resulting blended cost attach to the same per-trace attribution covered in the cost post, so you can see which routes drive spend. Failover is a separate concern — availability, not optimization — covered in the next post; keep the two as distinct, separately-logged events so an outage-driven fallback never looks like a cost decision.
Omar's router wasn't wrong; it was unobserved. The strategies in this post are only as safe as the numbers you watch alongside them — the escalation rate, the blended cost per route, the quality gate on each model change. Route aggressively, but instrument first.
TrueFoundry's AI Gateway is an enterprise-grade control plane that sits between your applications and 1,600+ models — across OpenAI, Anthropic, Google, AWS Bedrock, Azure OpenAI, and your own self-hosted models — behind a single OpenAI-compatible API. It turns the routing strategies in this post into configuration rather than code: weight-based, latency-based, and priority-based routing, model cascades, fallbacks, and per-target prompt overrides, all expressed as YAML and applied per route.
Because the gateway already normalizes every provider and records per-route cost, latency, and request/routing metadata, it is also where routing becomes measurable — one place to A/B a model, watch a cascade's escalation rate, and attribute blended cost. Join those traces with the eval and feedback signals you collect elsewhere and the same view becomes a quality view too. It adds exact and semantic caching, RBAC, budgets, rate limits, and guardrails, deploys as SaaS, in your VPC, on-prem, or air-gapped with SOC 2, HIPAA, and ITAR compliance, and is recognized in Gartner's Market Guide for AI Gateways. See the routing and load-balancing docs or the AI Gateway overview to go deeper.
Northwind and Omar are illustrative. Model names and per-token prices reflect the providers' public rate cards as of June 2026 and change over time. Cost and latency figures — the ~5× price gap, the 70% cheap-resolution example, the 5–20 ms embedding overhead — are representative assumptions to illustrate the tradeoffs, not measurements; benchmark routing strategies against your own traffic and eval sets before setting production policy.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet







.png)

.webp)
.webp)
.webp)




