














August 27, 2025
|
5 min read

Published: June 8, 2026
Blazingly fast way to build, track and deploy your models!
Every model provider has bad days — regional outages, rate-limit storms under load, latency that degrades without quite failing. If your application calls one provider directly, that provider's worst day is your worst day. This post is the reliability layer that prevents it: a taxonomy of how LLM calls fail, retries that don't make things worse, fallback chains across providers, health-aware load balancing, circuit breakers that fail fast, and the genuinely hard case of failing over mid-stream.
2:14 a.m. at Northwind. Nadia, an SRE, woke to a page: the customer-facing support agent was returning errors to every user. Not some users — every user. Northwind's own services were healthy; CPU, memory, and queues were all nominal. The errors were identical: 503 from the model provider. A regional incident on the provider's side had taken its inference endpoint down, and Northwind's agent called that endpoint directly. Every request hit the dead endpoint, failed, and returned an error to the customer. For forty minutes, until the provider recovered, there was nothing to do but wait — the agent had exactly one way to get a completion, and it was down.
The postmortem's action item wasn't "pick a more reliable provider." Every provider has incidents. It was "never depend on a single provider for a request that has to succeed." That is a gateway problem, and this post is how to solve it: retries that don't make things worse, fallback chains across providers, health-aware load balancing, and circuit breakers that fail fast instead of dragging your whole system down with the provider.
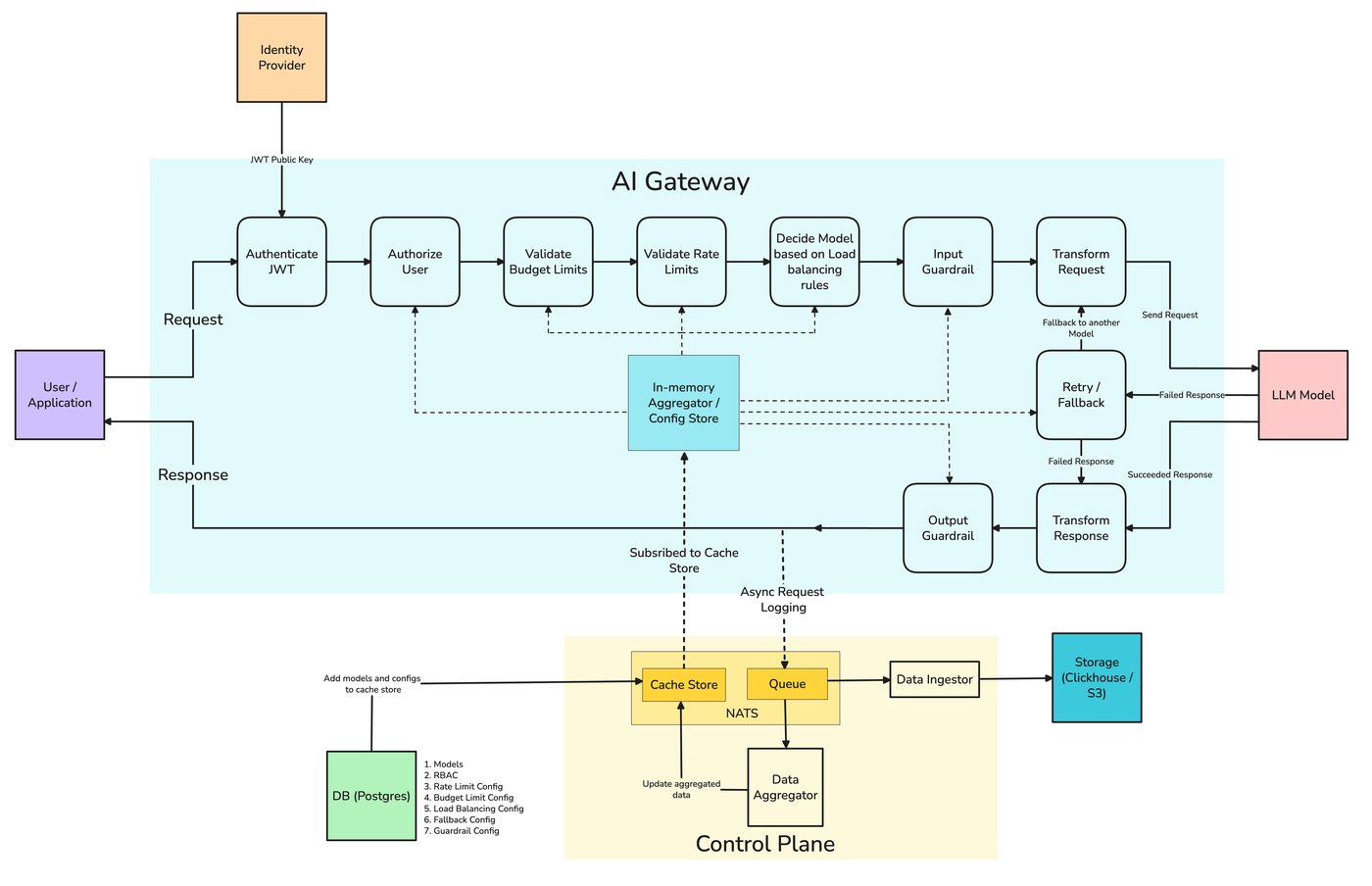
Everything in this post — retries, fallback chains, health-aware load balancing — is something TrueFoundry's AI Gateway expresses as configuration rather than per-service code. Its routing configuration defines load-balancing, fallback, and retry rules in YAML, evaluates them in order so the first matching rule wins, and applies them centrally to every request instead of being reimplemented in each app.
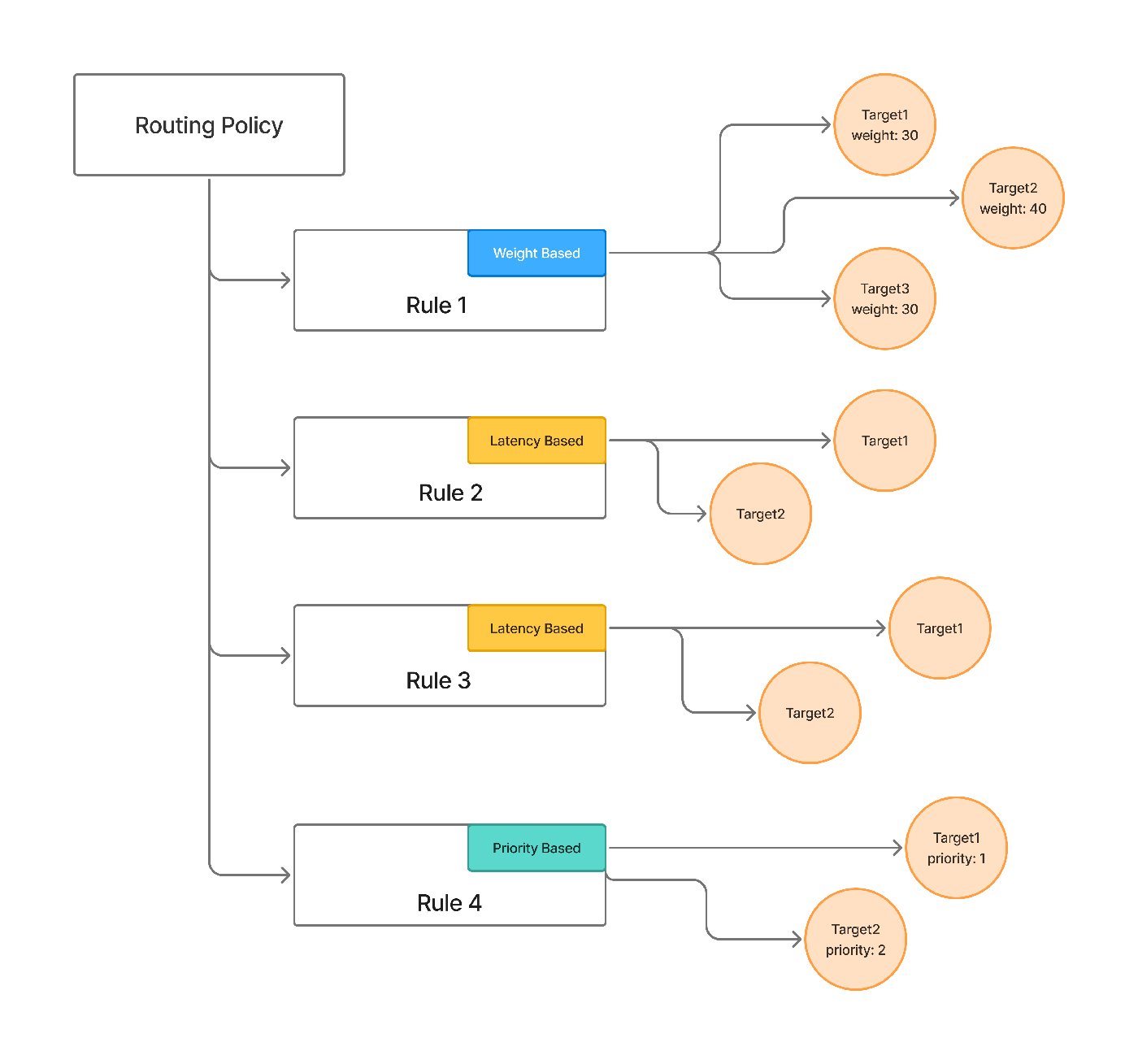
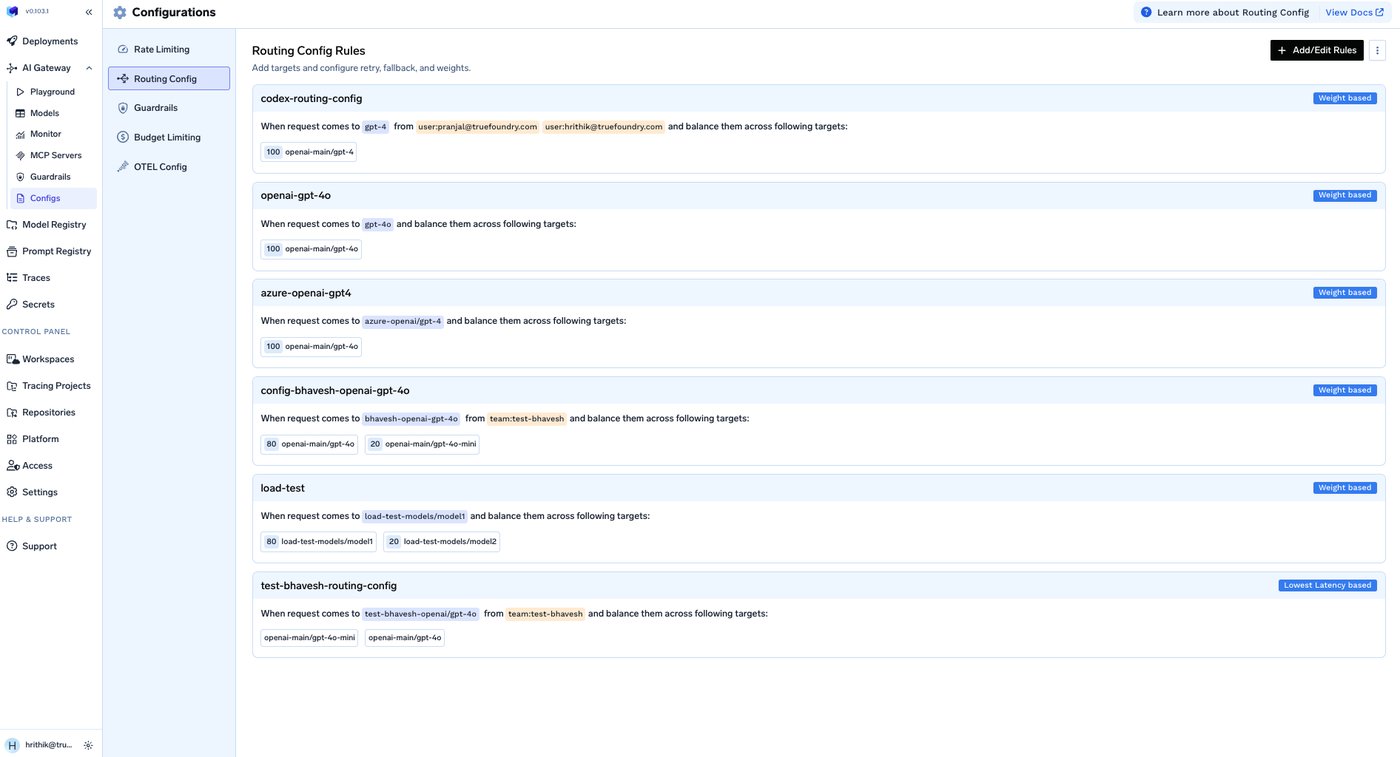
The pieces map onto the failure taxonomy below. Each target carries its own retry_config — attempts, delay, and the status codes worth retrying (429/500/502/503 by default) — and a separate fallback_status_codes list moves the request to the next target when retries won't help. Priority-based routing gives an ordered failover chain; latency-based routing favors the lowest-latency healthy target; and an unhealthy target is detected from its requests-, tokens-, and failures-per-minute and sidelined for a cooldown. The docs even cover the hard streaming case from section 8 — provider-specific stream-overload handling so a fall-through can happen before any user-visible tokens are emitted.
Calling the gateway from an application is a one-line change for anything already using the OpenAI SDK — same client, different base URL and key — so the reliability policy lives in config, not code:
# Calling the gateway from Python (OpenAI-compatible API)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-personal-access-token>", # Bearer-auth'd JWT
)
resp = client.chat.completions.create(
model="gpt-5.5", # the gateway resolves retries + fallback per the config
messages=[{"role": "user", "content": "Summarize the document."}],
)
print(resp.choices[0].message.content)Production LLM applications depend on infrastructure they don't control. Providers have regional and global outages, they return 429s when you exceed a rate limit (and sometimes when they're simply overloaded), and their latency degrades under load without returning an error at all. A direct integration makes the provider a single point of failure: there is no path to a completion except the one that's down.
The work that fixes this — retries, fallback, load balancing, circuit breaking — is cross-cutting. Every service that calls a model needs it, and implementing it per service means each one reimplements the same logic and drifts from the others, so the agent team's retry policy and the search team's are subtly different and both are subtly wrong. The gateway is the one component that sees every provider, holds every key, and normalizes the API to a single shape — which is exactly what failing over from one provider to another requires. Centralizing reliability at TrueFoundry's AI Gateway means one policy, applied uniformly, with the failover events landing on the same request traces as the rest of your telemetry.
The most common reliability mistake is treating every failure as "error, retry." Different failures want different responses, and the table below is the map. Getting this wrong is how a rate limit becomes an outage.
The last row is the one teams get wrong most often: a content-filter rejection is a property of the request, not a transient fault. Retrying it wastes time and money, and failing over to another provider often just produces the same rejection — so it should be classified as non-retryable and surfaced, not silently looped. A separate remediation path may rewrite the prompt, ask the user to clarify, or route to a safer workflow, but that is a policy flow, not failover. Encoding this table once at the gateway — which signal maps to retry, fall back, or surface — means every service inherits the same classification rather than reinventing it; applying that mapping uniformly is part of what TrueFoundry's AI Gateway centralizes.
Retries are the first line of defense and the easiest to weaponize against yourself. Three rules make them safe: exponential backoff (wait longer after each failure), jitter (randomize the wait so clients don't retry in lockstep), and honoring the provider's rate-limit headers — Retry-After where it's sent, or remaining/reset headers like x-ratelimit-* where that's the provider's contract (when the server tells you when to come back, listen).
The failure they prevent is the thundering herd. When a provider starts returning 429s under load and every client retries immediately and in sync, the retries themselves sustain the overload — a self-inflicted denial of service that keeps the provider pinned exactly when you need it to recover. Jitter de-synchronizes the retries, backoff reduces the pressure over time, and Retry-After respects the provider's own signal about when capacity will return. Equally important is not retrying what won't succeed: a malformed request or a content-filter rejection is a 4xx that will fail identically on the next attempt, so retrying it just adds latency and cost.
# Exponential backoff with jitter; honor Retry-After; cap attempts
for attempt in range(MAX_ATTEMPTS): # keep MAX small — 2–3 — then fall back
resp = call(provider, req)
if resp.ok:
return resp
if resp.status == 429 and resp.retry_after:
sleep(resp.retry_after) # respect the server's hint
elif resp.retryable: # 5xx, timeout
sleep(min(CAP, BASE * 2 ** attempt) * random.uniform(0.5, 1.0))
else:
break # non-retryable (4xx, content filter) — stop
raise Exhausted(provider) # hand off to the fallback chain
A consistent retry policy is exactly the kind of thing that drifts when each service owns its own. Applied at TrueFoundry's AI Gateway, the backoff, jitter, and Retry-After handling are uniform across every service that routes through it, and the retry-then-fall-back boundary is one configured behavior rather than five slightly different ones.
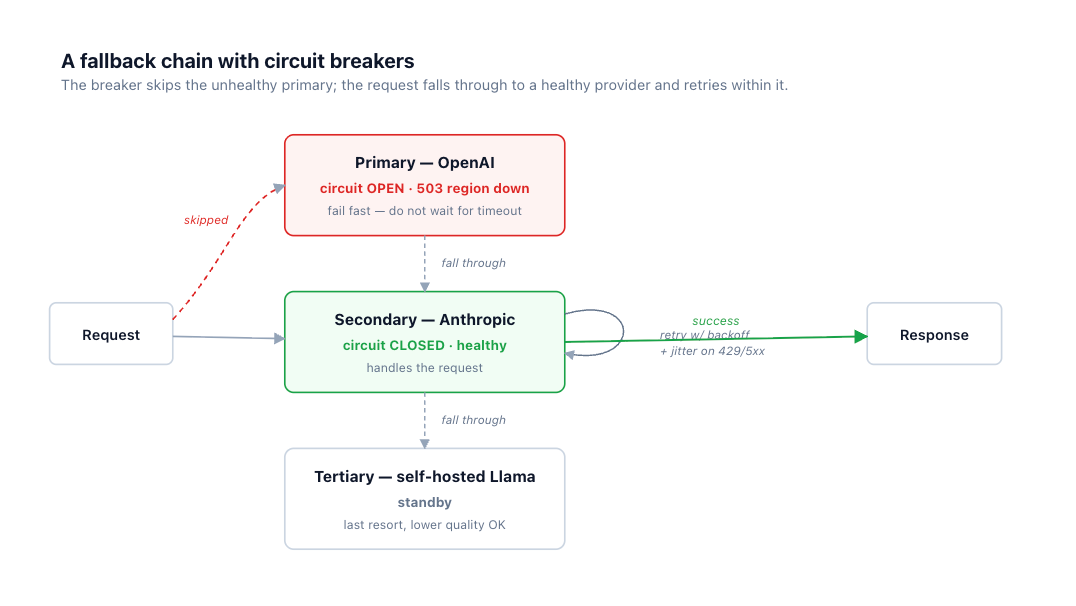
When retries against the primary are exhausted, a fallback chain keeps the request alive: primary, then secondary, then tertiary. There are two axes. Across providers (Claude, then GPT, then Gemini) gives independent failure domains — different infrastructure, different incidents, so the secondary is unlikely to be down for the same reason as the primary. Within a provider (an alternate region or deployment) is cheaper to set up but shares a failure domain, so it protects against a localized issue rather than a provider-wide one.
Illustrative fallback chain (conceptual — exact schema is gateway-specific)
fallbacks:
- provider: openai/gpt-5.5
- provider: anthropic/claude-sonnet-4-6 # different vendor = independent failure domain
- provider: self-hosted/llama-3.x # last resort; lower quality acceptable to stay up
trigger_on: [5xx, timeout, circuit_open] # NOT content-filter rejections
This isn't only a pattern — it's how TrueFoundry's AI Gateway is configured. A fallback chain is a priority-based routing rule: each target gets a priority, its own retry policy, and the status codes that should trigger a fall-through to the next target — spanning hosted and self-hosted models behind one OpenAI-compatible API, so the fallback can be a different vendor or your own model without the application knowing:
How TrueFoundry expresses the same chain (gateway-load-balancing-config)
name: reliability-config
type: gateway-load-balancing-config
rules:
- id: chat-failover
type: priority-based-routing # ordered chain: priority 0, then 1, then 2
when:
models: [gpt-5.5]
load_balance_targets:
- target: openai/gpt-5.5
priority: 0
retry_config: { attempts: 2, on_status_codes: ["429","500","502","503"] }
fallback_status_codes: ["429","500","502","503"]
- target: anthropic/claude-sonnet-4-6 # different vendor = independent failure domain
priority: 1
- target: self-hosted/llama-3.x # last resort; lower quality OK
priority: 2Retries happen within a target via retry_config; fallback_status_codes decide when to give up and move to the next. The gateway's request-level view records which targets were tried and why a fall-through happened, so failover is debuggable rather than inferred — and the full schema, including weight- and latency-based strategies, is in the routing config docs.
A second pattern worth seeing — an on-prem primary with a cloud fallback, the layout most regulated workloads land on — drops in the same way:
On-prem primary with cloud fallback (from the docs)
name: loadbalancing-config
type: gateway-load-balancing-config
rules:
- id: priority-failover
type: priority-based-routing
when:
models: [gpt-4]
load_balance_targets:
- target: onprem/llama
priority: 0
fallback_status_codes: ["429", "500", "502", "503"]
- target: bedrock/llama
priority: 1
retry_config:
attempts: 2
delay: 100Under the hood, the failover system has to be more reliable than what it protects — so the gateway runs every rate-limit, load-balancing, and auth check in memory, with no external hop on the request path, and ships logs and metrics asynchronously through a NATS queue so a downed log pipeline never fails a live request. The published benchmark is 350 RPS on 1 vCPU / 1 GB RAM with ~7 ms overhead at 200 RPS even with tracing on. The gateway plane is also stateless and keeps serving traffic from its last synced config if the control plane is briefly unavailable — useful precisely when an incident is in progress. TrueFoundry packages these properties into truefailover™, an outage-resilience product layered on the gateway that adds multi-region, multi-cloud, and degradation-aware routing on top of the multi-model failover above.
Load balancing does two jobs: spread traffic so no single backend or key becomes the bottleneck, and keep traffic off backends that are unhealthy. The common strategies are weighted round-robin (split by capacity), least-latency (favor the fastest healthy backend), and least-loaded (favor the one with the fewest in-flight requests).
There's a throughput point worth getting right: headroom comes from independent quota pools, not from extra keys. Separate providers, deployments, regions, or separately provisioned projects and accounts each carry their own limits, so distributing load across them genuinely adds capacity. What does not work is assuming more API keys inside the same organization multiply your quota — most providers enforce rate limits at the organization, project, or model-family level, so keys under one org share one pool. (OpenAI, for instance, states that additional keys under the same organization do not raise your limits, and some model families share a pool.) The balancer should route against the real remaining capacity reported in provider rate-limit headers, not a per-key assumption. Health checks come in two flavors: active (periodically probe each backend) and passive (watch real traffic and mark a backend unhealthy when its error rate crosses a threshold — which is circuit breaking, the next section). Passive is cheaper and reflects the conditions your actual requests are hitting. Balancing across providers and keys is a core function of TrueFoundry's AI Gateway, which is the natural place to do it because it already holds the keys and sees the per-backend latency and error rates the balancer needs.
When a provider is down, continuing to send it traffic is actively harmful. Every request waits for a timeout before failing, those waiting requests pile up, your queues back up, and the provider's outage cascades into your own latency and resource exhaustion. A circuit breaker stops this by failing fast.
It's a small state machine. Closed is normal operation. After errors cross a threshold — a high error rate over a window, or N consecutive failures — the breaker trips to open: requests to that provider fail immediately (or skip straight to the fallback) without waiting for a timeout. After a cooldown, it moves to half-open and lets a single probe request through; if the probe succeeds, the breaker closes and normal traffic resumes, and if it fails, the breaker re-opens for another cooldown. The effect is that a dead provider costs you one fast rejection per request instead of one full timeout, which is the difference between a clean failover and a cascading slowdown.
Circuit breaker — stop sending to a provider that's failing
if breaker.state == "open":
if breaker.cooldown_elapsed():
breaker.state = "half_open" # probe with one request
else:
raise SkipProvider # fail fast → fall through to the chain
resp = call(provider, req)
breaker.record(resp) # closes on success, re-opens on failed probe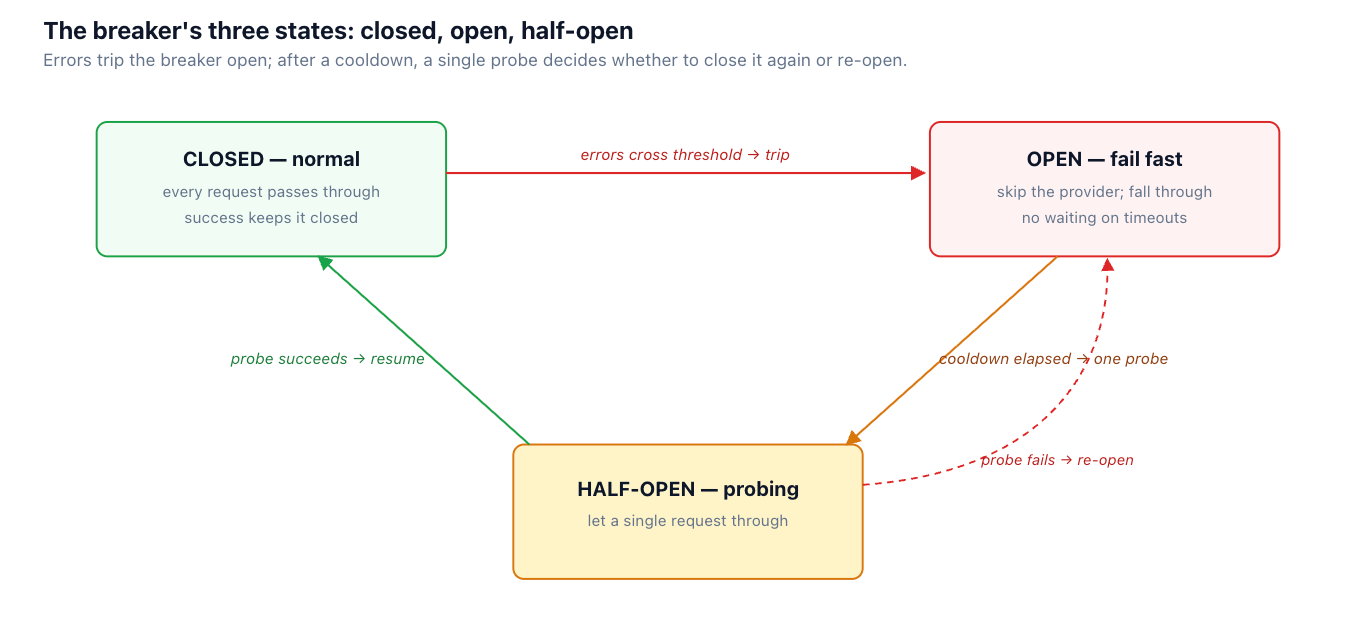
As in the fallback diagram earlier, the primary's breaker is open after a run of 503s, which is why the request skips it without waiting. Health-aware routing at TrueFoundry's AI Gateway applies this across providers so an unhealthy backend is bypassed at the gateway rather than rediscovered, request by request, inside every service.
Some reliability problems aren't outages — they're the tail. Most requests are fast, but p99 is slow because a few of them happen to hit a provider during a slow moment. Hedging attacks the tail: after a short delay, send the same request to a second provider and take whichever response comes back first. The slow tail gets cut because you're no longer hostage to one provider's worst-case latency on any given call.
The cost is real and worth stating plainly: when the hedge fires, you pay for two calls. Cancel the loser once the winner returns, but don't assume cancellation makes it free — depending on the provider and how far generation progressed, the cancelled call can still bill for partial tokens, so track both attempts. The way to keep that affordable is to fire the hedge only after a delay tuned to your latency profile — say, around the p95 — so you hedge only the slow tail rather than every request. Two caveats: hedging duplicates any side effects if the call isn't idempotent (a non-issue for pure completions, something to think about for tool-calling agents), and it adds load to providers, so it's a tail-latency tool, not a default. Hedging is naturally a gateway concern for the same reason load balancing is — the gateway already sees both providers and can fire and reconcile the second call — so it belongs as a per-route policy alongside the fallback and load-balancing controls TrueFoundry's AI Gateway already centralizes, rather than as bespoke per-service code.
None of these controls has a universal value, but here are defensible starting points to tune from — not settings to copy blindly:
Everything above assumes you can cleanly retry or redirect a request. Streaming breaks that assumption. If you've already streamed two hundred tokens to the user and the stream dies, you can't transparently switch providers — the new provider starts from the beginning, so you either restart the visible output (jarring) or try to stitch two models' outputs together (inconsistent). There is no clean universal answer.
The practical options are a set of tradeoffs. You can buffer the stream server-side and release it only once it's complete or validated, which makes failover clean but gives up the perceived-latency benefit that made you stream in the first place. You can accept that mid-stream failures restart and design the UX to tolerate it. Or, on critical paths, you can confirm the provider is alive with a non-streamed first token before committing to a stream. This is the same tension the streaming discussion in the context-engineering and PII posts raised from the other direction: streaming trades recoverability and post-hoc control for latency. Treat streaming failover as a deliberate per-path decision, not a global setting — the right answer for an internal batch agent is different from the one for a customer-facing chat. Because that choice is per-path, it belongs where the other per-route policies live: the kind of per-route configuration TrueFoundry's AI Gateway centralizes, so a chat path and a batch path can make opposite buffering choices under one configuration.
Cross-provider or within-provider fallback?
Both, in order. Within-provider (alternate region/deployment) is cheap and handles localized issues, but it shares a failure domain, so a provider-wide incident takes out the whole tier. Cross-provider gives independent failure domains and is what saves you in an outage like the cold open's — at the cost of more output variance, since you're now serving from a different model. A robust chain usually tries an alternate deployment first, then crosses to a different vendor.
Won't falling over to another model change my output?
Yes — that's the tradeoff in section 4. Failover buys availability at the cost of fidelity, because the fallback model formats, refuses, and reasons differently. Validate fallback outputs against the same schema as the primary, especially for structured responses, and keep prompts portable so the fallback isn't starting from a prompt tuned only for the primary.
How many retries should I configure?
Few — typically two or three — with exponential backoff, jitter, and Retry-After honored. More retries against a provider that's actually down just delay the fallback that would have succeeded, and they add load during exactly the moment the provider is struggling. The goal is to ride out a brief blip, then hand off, not to hammer a dead endpoint.
Should I hedge every request?
No. Hedging everything doubles your provider cost and load. Fire the hedge only after a delay tuned near your p95 so it targets the slow tail, and only on paths where tail latency actually matters. For non-idempotent calls, be careful — a hedge can duplicate side effects.
Should this live in the app or the gateway?
The gateway. It sees every provider and key, normalizes the API so a fallback target can be a different vendor without app changes, and can apply one consistent retry/fallback/circuit-breaker policy across all services. Per-service implementations drift and duplicate the same logic. The gateway also traces failover events, so "we fell back because the primary was open" is visible rather than inferred — which ties into the cost and observability work earlier in this series.
Nadia's outage didn't need a better provider; it needed a second one and a policy for using it. Reliability for LLM traffic is the same discipline as for any other dependency — retries that respect the server, fallbacks across independent failure domains, circuit breakers that fail fast — applied at the layer that sees every provider at once.
TrueFoundry's AI Gateway is an enterprise-grade control plane that sits between your applications and 1,600+ models — across OpenAI, Anthropic, Google, AWS Bedrock, Azure OpenAI, and your own self-hosted models — behind a single OpenAI-compatible API. It turns the reliability patterns in this post into configuration rather than per-service code: fallback chains, weighted and latency-based load balancing, retries, and health-aware routing, all defined once and applied to every request.
Because the gateway holds the keys, normalizes every provider, and records per-request cost, latency, error, and fallback telemetry, it is the natural place to make failover both automatic and observable. It deploys as SaaS, in your VPC, on-prem, or air-gapped, with RBAC, budgets, rate limits, and guardrails built in, and carries SOC 2, HIPAA, and ITAR compliance — and it's recognized in Gartner's Market Guide for AI Gateways. You can explore the reliability features in the load-balancing and fallback docs or see the AI Gateway overview.
Northwind and Nadia are illustrative. The failure-mode taxonomy and the retry, fallback, load-balancing, and circuit-breaker patterns are standard reliability engineering applied to LLM traffic. Specific numbers — two-to-three retries, hedging near p95 — are representative starting points, not universal settings; tune them to your own traffic, SLOs, and provider limits. Rate-limit headroom comes from independent quota pools (separate providers, projects, or accounts), not from extra keys under a single organization.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox










.png)

.webp)
.webp)
.webp)



.webp)


