

July 23, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 23, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
When LLMs move from a pilot to production across many teams, governance stops being optional. Someone will ask who can call which model, with what budget, on whose data — and whether every call can be reconstructed for an audit. This post is the control plane that answers those questions: virtual keys that decouple access from provider credentials, RBAC and policy-as-code, budgets and quotas as governance, compliance-grade audit logs, data residency, and how these gateway controls map to obligations like the EU AI Act — framed as what they help satisfy, not as a compliance guarantee.
Quarter-end at Northwind. Mei, the platform lead, got a question from the security and compliance team she couldn't answer: which teams had sent customer data to which model providers over the last quarter, and could she produce the records. She couldn't. Every service called the model providers through one shared API key, checked into a config years ago. There was no per-team attribution, no record of which requests carried customer data, no way to revoke one team's access without rotating the key for everyone, and no audit trail beyond the providers' own opaque billing. The LLM usage had grown from one prototype to a dozen production services, and the governance had not grown with it.
Nothing had gone wrong, exactly — no breach, no overspend anyone had caught. But "we can't answer the question" is its own finding, and it's the one that turns a routine audit into a project. This post is the control plane that makes the question answerable before someone asks it.
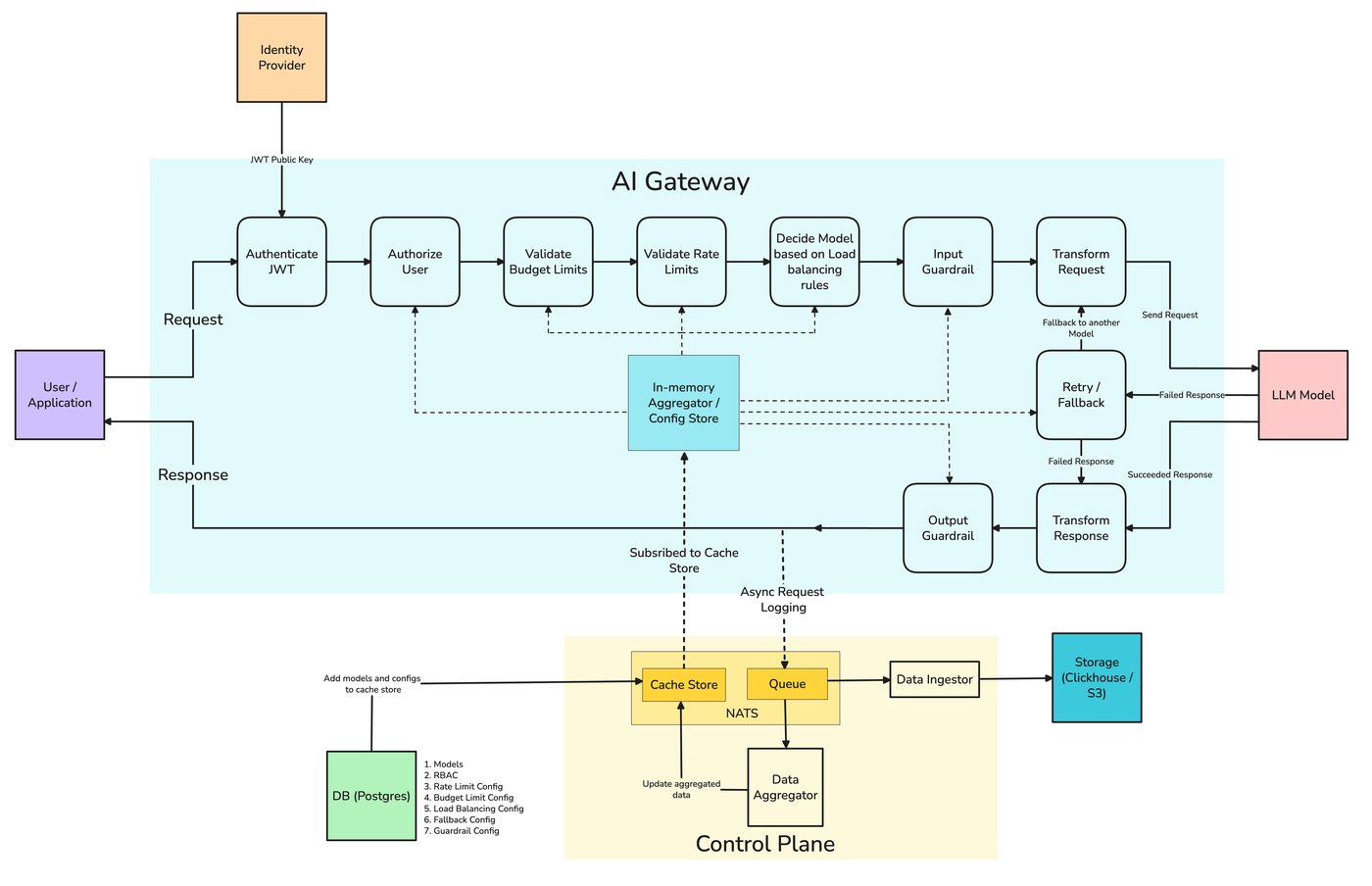
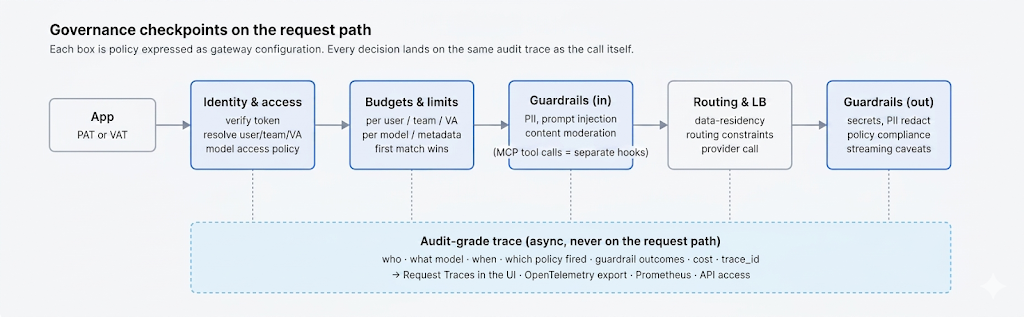
Everything in this post — virtual keys, RBAC, budgets, rate limits, audit logs, residency rules, and guardrails as enforced policy — is something TrueFoundry's AI Gateway expresses as configuration in one control plane. Access control defines who (users, teams, virtual accounts) may call which provider accounts and models; Personal Access Tokens and Virtual Account Tokens are how applications authenticate to the gateway instead of holding raw provider keys; rate-limit and budget configs apply per user, team, virtual account, model, or any custom metadata key; and guardrails — including Cedar and OPA as policy-as-code at the MCP-tool boundary — run as enforced rules at four lifecycle hooks.
Every request crosses the same path: authenticate, resolve the calling identity, evaluate access policy and per-key budgets, evaluate rate-limit rules in order (first match wins), run input guardrails, route to a provider, emit an audit-grade trace, then run output guardrails. The same view becomes the record an auditor needs: who called what, when, against which policy, with which guardrail outcomes. Request Traces and OpenTelemetry export let the trail land in your SIEM rather than a vendor dashboard you cannot query.
The application code is unchanged from any OpenAI-style call — the governance is in the bearer token and the metadata header, not in client logic. A Personal Access Token resolves to a user; a Virtual Account Token resolves to a non-human identity for production services. The X-TFY-METADATA header carries the structured fields (team, project, cost_center, environment) that policies, budgets, and audit logs match against:
Calling the gateway with an identity and audit metadata (Python, OpenAI-compatible)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-virtual-account-token>", # VAT for production; PAT in dev
)
resp = client.chat.completions.create(
model="openai-main/gpt-5.5",
messages=[{"role": "user", "content": "Summarize this document."}],
extra_headers={
# Structured identity for audit, attribution, and policy matching.
"X-TFY-METADATA": '{"team":"support-ai","project":"helpdesk","cost_center":"cc-203","environment":"production"}',
},
)
print(resp.choices[0].message.content)A single prototype calling one model on one key needs no governance. A dozen services across several teams, calling several providers, on data of varying sensitivity, needs a control plane — because the failure modes are no longer hypothetical. A shared key means no usage attribution, so you can't tell finance which team is driving spend or tell security which team touched customer data. No spend limits means one runaway agent (recall the routing post's silent escalation) can burn the budget before anyone notices. No audit trail means you can't reconstruct what happened for an incident or an auditor. And no access control means shadow AI: teams wiring up models without anyone tracking it.
On top of the operational pressure sits regulatory pressure. The EU AI Act is phasing in obligations around record-keeping, transparency, and human oversight (section 7), and sector regimes — SOC 2, HIPAA, financial rules — have long expected access control and audit. The common thread is that they all assume you can answer Mei's question. Governance is the work of being able to.

TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet







.png)

.webp)
.webp)
.webp)




