



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Parte 1 nomeou o problema: tokenmaxxing, a nova métrica de linhas de código, onde os engenheiros otimizam o volume de uso de IA porque é o número que está sendo medido. Parte 2 prescreveu a cura arquitetônica: identidade, política, segurança e observabilidade anexadas a cada solicitação no gateway. Esta parte final transforma essa arquitetura em algo que uma organização pode realmente operar semana após semana.
A decisão de design mais consequente nesta camada é também a mais facilmente ignorada. O painel que você construir moldará o comportamento. Um placar de líderes cria pressão social para queimar tokens. Uma sala de controle ajuda os líderes de plataforma, segurança, finanças e engenharia a responder a perguntas mais difíceis e a agir com base nas respostas.
As perguntas que realmente importam: Quais fluxos de trabalho criam valor por dólar? Quais agentes estão em loop? Quais equipes estão subutilizando a IA onde ela realmente ajudaria? Qual uso de modelo premium é justificado e qual é decorativo? Quais eventos de guardrail são ruído e quais sinalizam risco real?
Acerte os painéis e estas se tornam perguntas operacionais de rotina respondidas na reunião de segunda-feira. Erre-os e seu painel mais preciso treina silenciosamente o mesmo comportamento manipulável que você se propôs a evitar.
Antes dos painéis, as regras de design. Cada princípio é a resposta direta a um modo de falha que os placares de líderes introduzem.
O painel de adoção responde a uma pergunta enganosamente simples: quantos engenheiros estão realmente usando ferramentas de IA em um determinado dia?
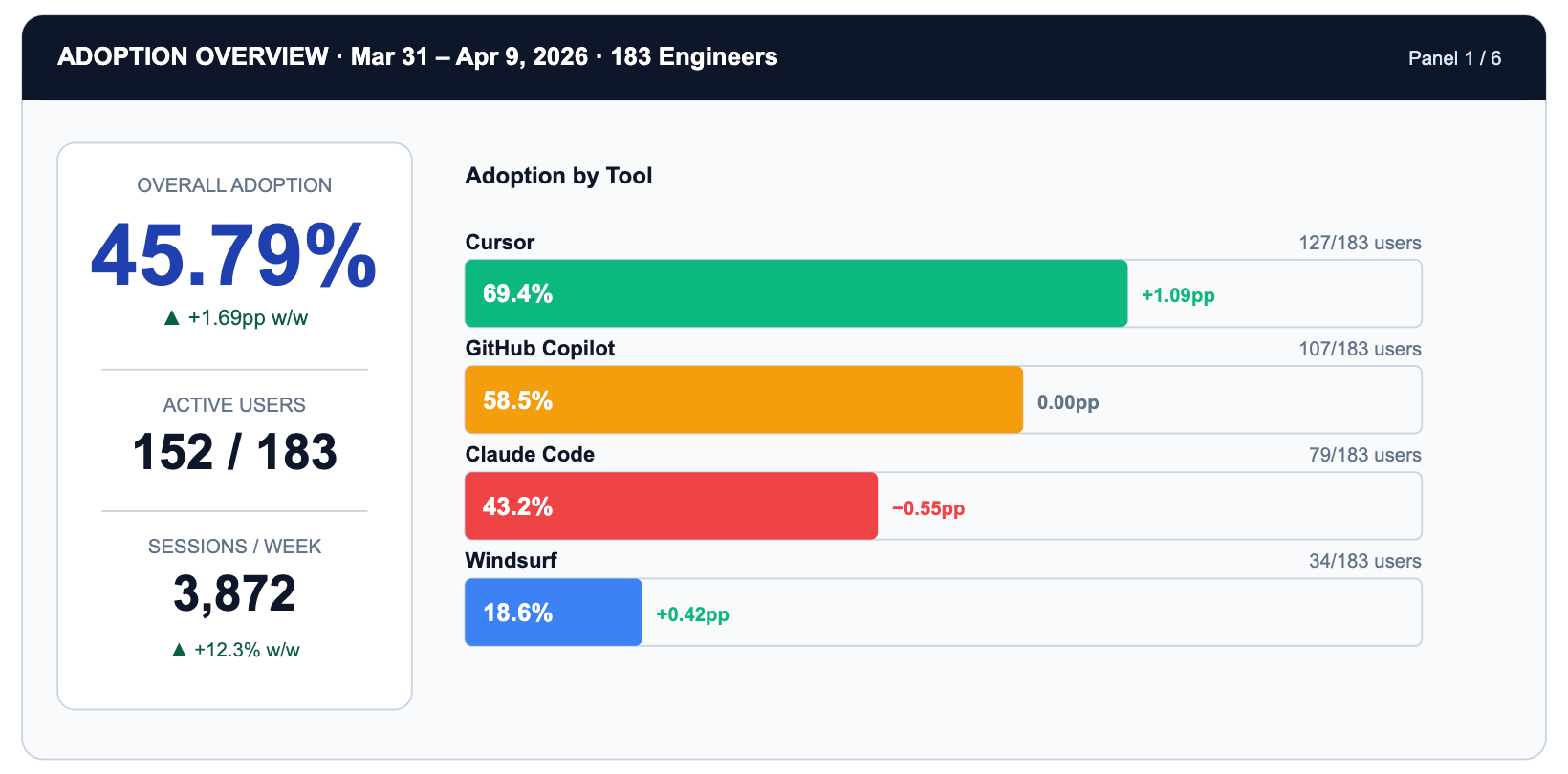
Observe o que o painel não mostra: classificações individuais. A unidade é fornecedor x equipe x dia. A ação que produz não é 'parabenizar Alex', mas 'a adoção do Claude Code está 26 pontos percentuais abaixo do Cursor. É um problema de atrito com a ferramenta ou um problema de adequação ao caso de uso?' Essa é uma pergunta que vale um sprint.
A TrueFoundry torna isso possível através do cabeçalho X-TFY-METADATA anexado a cada solicitação de gateway. O cabeçalho contém um objeto JSON serializado cujos campos incluem identidade do usuário, associação à equipe, nome da ferramenta, tag do projeto e ID da sessão.
→ Referência de Cabeçalhos de Solicitação e Resposta do TrueFoundry
→ Visão Geral do Painel de Análise
A adoção informa quem está usando IA. A taxa de consumo informa para onde o dinheiro está indo. São perguntas diferentes e pertencem a painéis diferentes.
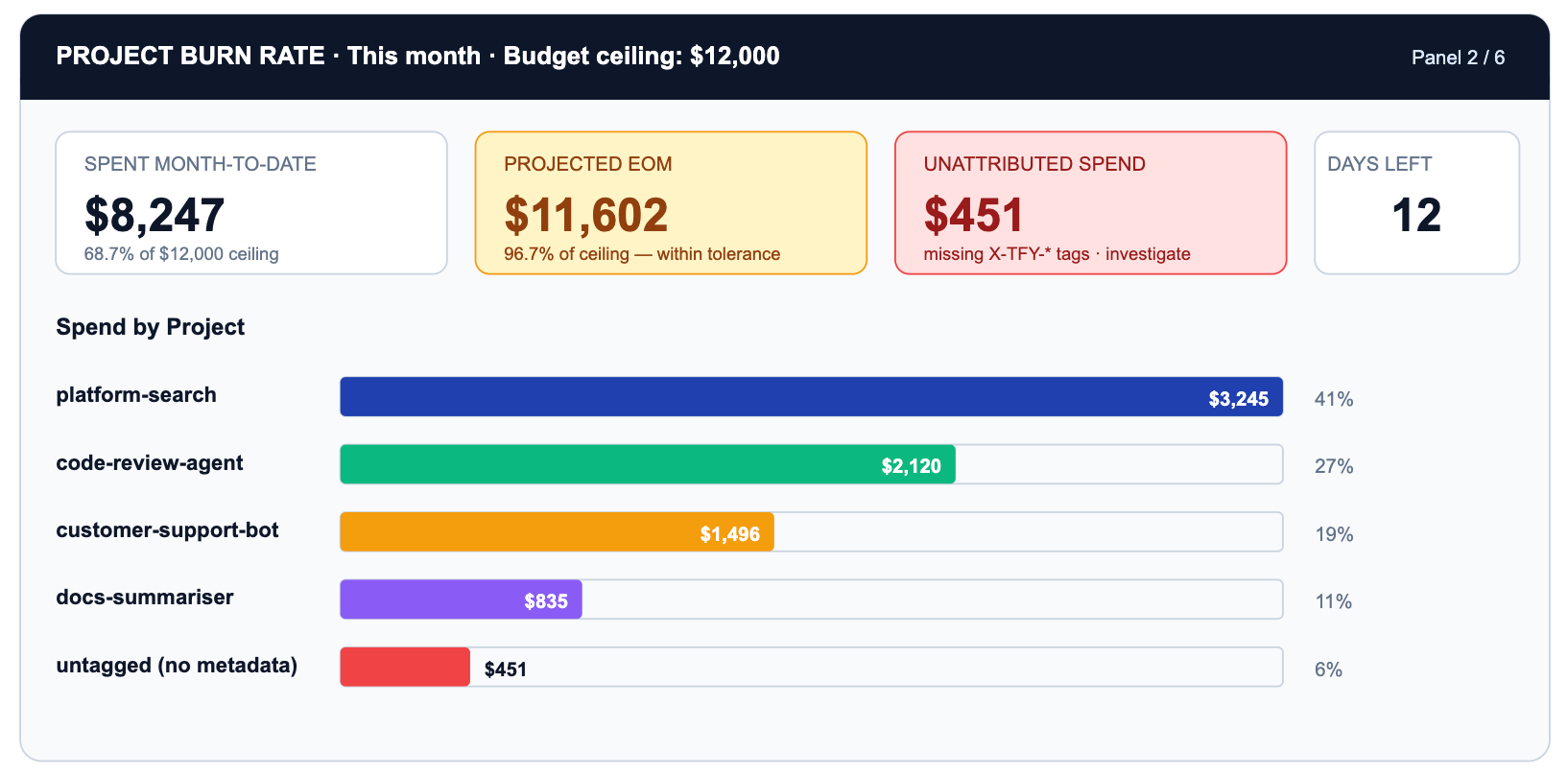
A linha crítica é NÃO MARCADA. $451 de gastos não possuem metadados de projeto. Isso é uma lacuna na configuração do gateway, não um problema de gastos. Cada solicitação não marcada não pode ser atribuída a um resultado de negócio, governada por uma política de orçamento ou aparecer em um gráfico útil de taxa de consumo.
O Limite de Orçamento do TrueFoundry permite definir tetos rígidos por projeto, por equipe, por família de modelo ou por janela de tempo. Quando a pesquisa da plataforma atinge 100% do seu teto mensal de $4.000, as solicitações começam a retornar 429s ou voltam para um modelo mais barato com base na sua política configurada.
→ Limitação de Orçamento — janelas, tetos e alertas
→ Limitação de Taxa — por usuário, por modelo, por tag de metadados
O modo de falha novo mais caro num mundo de agentes é o loop: um agente que tenta novamente indefinidamente porque a sua condição de saída nunca é satisfeita, ou porque a ferramenta que ele chama continua a retornar erros. Um único agente em loop pode consumir tantos tokens numa hora quanto uma equipa de engenheiros consome num dia.
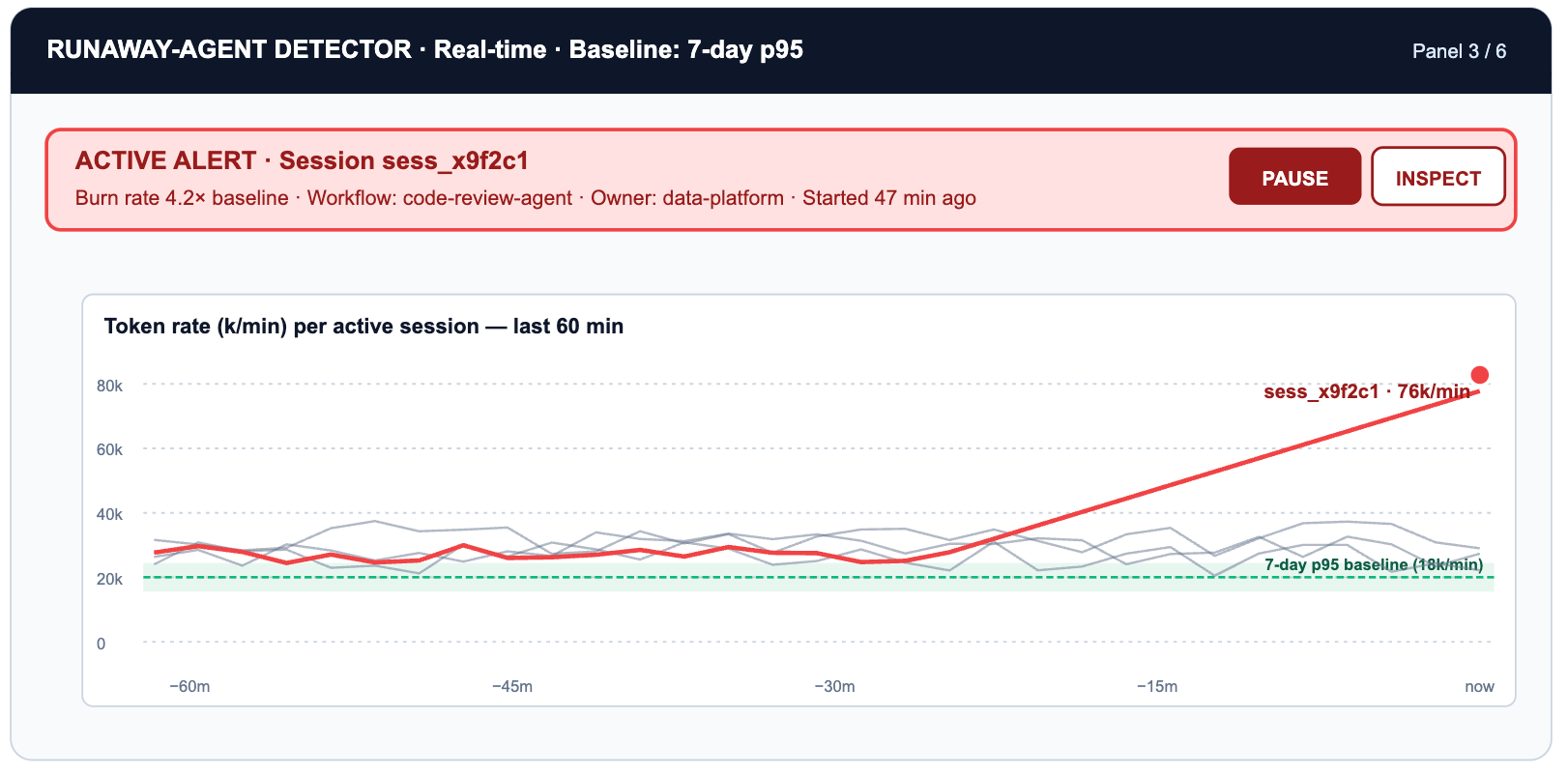
Este painel requer o sinal OTEL que a TrueFoundry exporta: taxa de tokens por sessão ao longo do tempo, não apenas contagens por solicitação. A linha de base p95 é calculada a partir dos sete dias anteriores de sessões para cada tag de fluxo de trabalho. Qualquer coisa que exceda 3x essa linha de base aciona um evento de pager e, opcionalmente, um encerramento de sessão através do caminho de aplicação do limite de taxa.
→ Exportar Dados OpenTelemetry — rastreamentos, spans, contadores de tokens
→ Limitação de Taxa — aplicando limites máximos por sessão
Nem toda tarefa que chega a um modelo de fronteira merece um modelo de fronteira. Encaminhar uma tarefa de 'classificar este e-mail' para o Claude Opus 4.7 a $5/$25 por milhão de tokens, quando o Haiku 4.5 a $1/$5 a trataria com uma diferença de 2pp na mesma precisão, é pagar 5x por uma capacidade que você não usa. A escolha é invisível até ser agregada em milhares de solicitações diárias — o que é exatamente o que este painel faz.
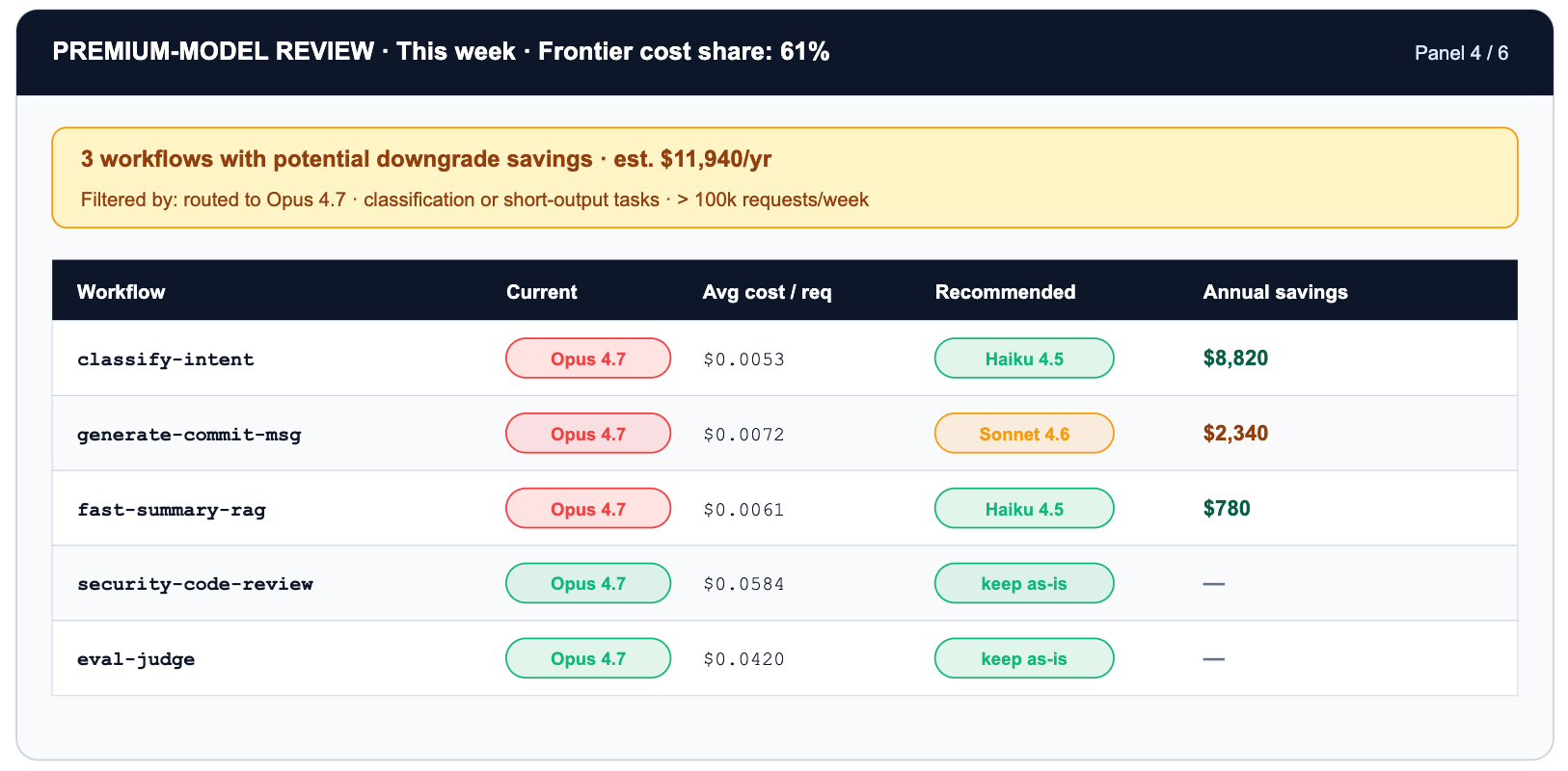
Duas otimizações em camadas se acumulam neste painel. Encaminhar a classificação de intenção do Opus 4.7 para o Haiku 4.5 representa uma redução de 5x no custo por token. Além disso, ativar o cache de prompts no prompt do sistema reduz os tokens de entrada em cache em mais 90% — um desconto acumulado que transforma um fluxo de trabalho de $3.200/mês em aproximadamente $50/mês sem alteração na precisão.
Existe também uma versão oculta deste painel: o desvio do tokenizador. Quando a Anthropic lançou o Opus 4.7, o novo tokenizador produziu até 35% mais tokens para a mesma entrada em comparação com o Opus 4.6. A tabela de preços principal não mudou. O custo efetivo por solicitação, sim. A única forma de ver isso é através da telemetria de tokens por versão de modelo no gateway. A única forma de reagir é reverter o alias do modelo virtual — o que na TrueFoundry é uma diferença YAML, não um sprint.
O roteamento de modelo virtual da TrueFoundry torna a ação neste painel sem atrito. Você configura um nome de modelo lógico como 'code-review-fast' que roteia para diferentes endpoints físicos por tag de fluxo de trabalho, hora do dia ou carga — sem tocar no código da aplicação. Testar A/B um modelo mais barato é uma diferença YAML, não um sprint.
→ Visão Geral do Roteamento — peso, prioridade, fallback, cache de prompts
A função do painel de segurança é a triagem. A maioria dos eventos de guardrail são ruído: tráfego de teste, experimentação de desenvolvedores, casos de uso extremos esperados em produção. Alguns poucos representam risco real: vazamento de PII através de um prompt, um segredo aparecendo em código gerado por agente, uma tentativa de injeção de prompt em entrada fornecida pelo usuário.
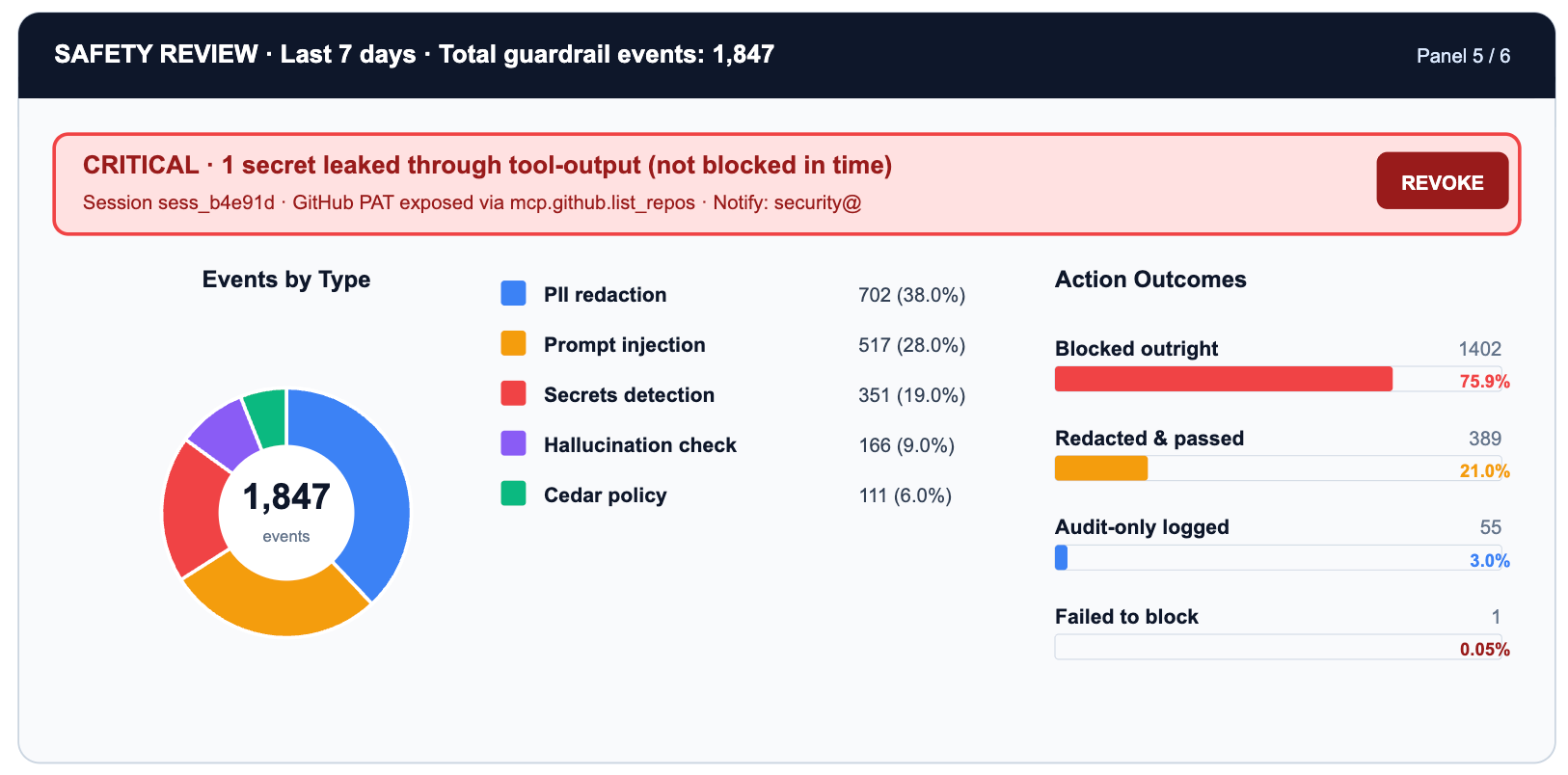
O único segredo vazado na linha de varredura de segredos é a célula que exige ação imediata. Todo o resto é informativo: útil para ajustar a sensibilidade do guardrail, distinguir sinal de ruído e demonstrar a postura de conformidade aos auditores.
O modelo de guardrail de quatro ganchos da TrueFoundry (entrada de solicitação, saída de solicitação, entrada de ferramenta, saída de ferramenta) significa que cada linha de evento mapeia para um ponto de intercepção específico no ciclo de vida da solicitação. A detecção de PII na entrada da solicitação captura dados do usuário antes que cheguem ao modelo. A varredura de segredos na saída da ferramenta captura credenciais antes que cheguem aos sistemas downstream.
→ Visão Geral dos Guardrails — quatro ganchos, decomposição da superfície de ameaça
→ Detecção de PII/PHI — modos de redação e posicionamento de ganchos
→ Detecção de Segredos — modo de validação vs mutação
Este é o painel mais difícil de construir e o mais importante de se ter. Todos os cinco painéis anteriores descrevem o uso de IA. Este responde se o uso produziu algo.
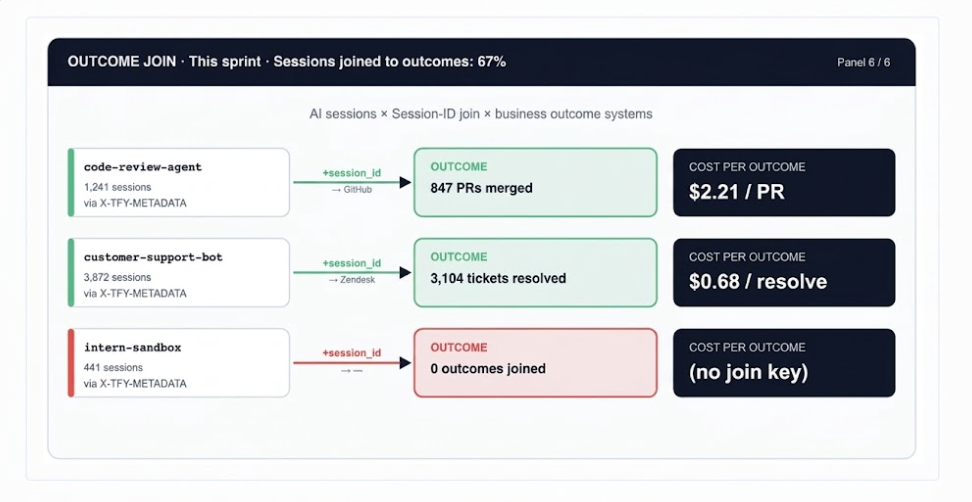
A chave de junção é o campo session_id em X-TFY-METADATA, propagado pela TrueFoundry através de cada requisição em uma sessão de agente multi-turno. Quando o mesmo ID de sessão aparece no seu payload de webhook do GitHub ou nos metadados do Zendesk, você pode fechar o ciclo: esta sessão custou $2,21 e produziu um PR de revisão de código mesclado.
→ Análises — visualizações de custo e uso em nível de sessão
Os seis painéis são baseados em três camadas de métricas distintas. O erro mais comum em dashboards é misturá-las: uma visualização executiva não deve mostrar contagens de tentativas, e uma visualização de plantão não deve mostrar taxas de aprovação de avaliação.
Uma vez que as três camadas estejam implementadas, a tentação é transformá-las em uma pontuação por engenheiro e publicar um ranking. Resista a isso. A função abaixo é explicitamente diagnóstica: uma ferramenta para encontrar padrões de fluxo de trabalho que merecem investimento, redesenho ou novas salvaguardas. Agregue por workflow_tag, não por user_id.
# ai_leverage_score.py
# Per SESSION, not per engineer. Aggregate by workflow_tag.
def ai_leverage_score(session: dict) -> float:
# OUTCOME SIGNALS (weighted heaviest)
outcome_score = (
session.get('incidents_resolved', 0) * 25 +
session.get('prs_merged', 0) * 15 +
session.get('tickets_closed', 0) * 10 +
session.get('eval_pass_rate', 0) * 20 # float 0.0-1.0
)
# GOVERNANCE HITS (small penalty: information, not moral failing)
governance_penalty = (
session.get('budget_limit_hits', 0) * 2 +
session.get('rate_limit_hits', 0) * 1 +
session.get('guardrail_blocks', 0) * 3
)
# WASTE SIGNALS (penalise shape, not raw volume)
retry_tokens = session.get('retry_token_count', 0)
context_waste = session.get('unused_context_ratio', 0.0)
loop_flag = 1 if session.get('tokens_per_hr', 0) > 3 * session.get('p95_baseline', 1) else 0
waste_penalty = (retry_tokens / 10000) + (context_waste * 10) + (loop_flag * 15)
# COST DAMPENER (sub-linear: expensive sessions aren't punished)
cost_usd = session.get('total_cost_usd', 0.01)
cost_dampener = cost_usd ** 0.4
raw = (outcome_score - governance_penalty - waste_penalty) / max(cost_dampener, 0.01)
return max(0.0, min(100.0, raw))
# Weekly report: top-10 workflow PATTERNS, not top-10 humans
# df.groupby('workflow_tag')['score'].mean().nlargest(10)Dashboards não gerenciam organizações. Rituais sim. A cadência operacional mínima viável para o uso de IA governada:
Cada alerta deve mapear para uma etapa de runbook, não apenas para um evento de pager. O YAML abaixo define o conjunto de regras de alerta mínimo viável para a sala de controle, executado contra a exportação OTEL da TrueFoundry:
# tfy-ai-alerts.yaml | tfy apply -f tfy-ai-alerts.yaml
alerts:
- name: runaway_agent
query: rate(tfy_gateway_tokens_total[5m]) > 3 * quantile(0.95, rate(tfy_gateway_tokens_total[7d]))
labels: {severity: critical, team: platform}
runbook: |
1. Identify session_id from alert labels
2. Check the workflow_tag field in the request's X-TFY-METADATA for owning team
3. Confirmed loop: PUT /gateway/sessions/{id}/kill
4. File incident linked to TFY session trace
- name: budget_near_ceiling
query: tfy_budget_used_pct{scope='project'} > 90
labels: {severity: warning, team: finance-ops}
runbook: |
1. Notify project owner (#ai-budget-alerts)
2. Review premium-model panel for quick routing wins
3. Raise ceiling or enable fallback-to-cheaper-model policy
- name: secret_leaked
query: increase(tfy_guardrail_events_total{type='secret',action='allowed'}[1h]) > 0
labels: {severity: critical, team: security}
runbook: |
1. Pull trace from TFY Analytics for the request
2. Identify secret type and downstream model/tool
3. Rotate credential immediately
4. Switch secrets guardrail from validate to mutate mode
- name: untagged_spend_spike
query: sum(tfy_cost_usd_total{project='UNTAGGED'}) > 50
labels: {severity: warning, team: platform}
runbook: |
1. Find callers via the user_id metadata field in Analytics
2. Require a project field in X-TFY-METADATA via gateway config
3. Block untagged traffic after 30-day grace periodVerifique o campo workflow_tag no X-TFY-METADATA da requisição para a equipe responsável
Verifique o campo workflow_tag no X-TFY-METADATA da requisição para a equipe responsável
→ tfy apply — implantação de alertas e políticas estilo GitOps
→ Exportar Dados OpenTelemetry — endpoints de métricas OTEL
Before declaring your AI control room operational, verify these eight conditions. Each maps to a specific TrueFoundry capability:
The Tokenmaxxing Trilogy has built up a three-layer argument. Each layer is necessary; none is sufficient alone.
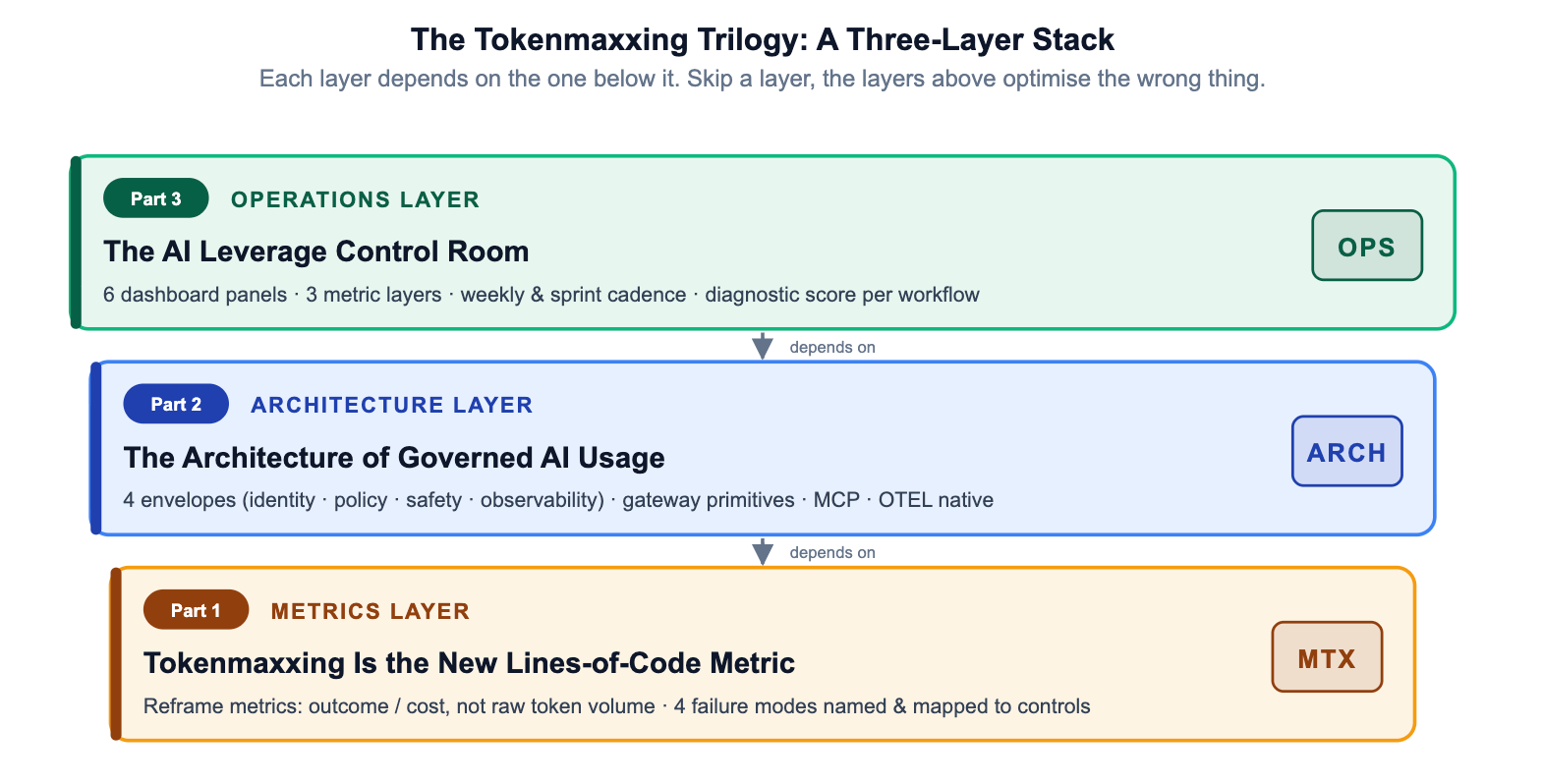
Organizations that stop at Layer 1 have a narrative but no enforcement. Those that stop at Layer 2 have enforcement but no feedback loop. The control room closes the loop — making governed AI usage not a compliance posture but an operational discipline that compounds over time.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




