Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
Volumes fornecem armazenamento persistente para contêineres dentro de pods, para que possam ler e gravar dados em um disco central em vários pods. Eles são especialmente úteis em aprendizado de máquina quando você precisa armazenar e acessar dados, modelos e outros artefatos necessários para tarefas de treinamento, serviço e inferência.
Neste blog, discutiremos como utilizar volumes e as opções disponíveis em cada nuvem.
Quando usar volumes Kubernetes?
Alguns casos de uso onde volumes se mostram muito úteis:
Compartilhar dados de treinamento: É possível que vários cientistas de dados estejam treinando com os mesmos dados, ou que estejamos executando vários experimentos em paralelo no mesmo conjunto de dados. A maneira ingênua seria duplicar os dados para vários cientistas de dados — no entanto, isso acabaria nos custando muito mais. Uma maneira mais eficiente aqui seria armazenar os dados de treinamento em um volume e montar o volume nos notebooks de diferentes cientistas de dados.
Armazenamento de Modelos: Se estivermos hospedando modelos como APIs em tempo real, haverá várias réplicas do servidor de API para lidar com o tráfego. Aqui, cada réplica deve baixar o modelo do registro de modelos (por exemplo, S3) para o disco local. Se cada réplica fizer isso repetidamente, levará mais tempo para iniciar e também incorrerá em mais custos de acesso ao S3. Usando volumes, você pode armazenar seus modelos treinados externamente e montá-los no servidor de inferência. Não há necessidade de baixar o modelo; o servidor de API pode simplesmente encontrar o modelo no disco no caminho montado.
Compartilhamento de Artefatos: Podemos ter um caso de uso em que a saída de uma etapa do pipeline precisa ser consumida pela próxima etapa. Por exemplo, após o ajuste fino de um modelo, podemos precisar hospedá-lo como uma API apenas para experimentação. Embora possamos gravar o modelo no S3 e depois baixá-lo do S3, isso levará muito tempo apenas para o processo de upload/download do modelo. Em vez disso, para uma experimentação mais rápida, o trabalho de ajuste fino pode simplesmente gravar o modelo em um volume, e o serviço de inferência pode então montar o volume com o modelo.
Criação de Checkpoints: Durante o treinamento de modelos de aprendizado de máquina, é comum salvar checkpoints periodicamente para retomar o treinamento em caso de falha ou para ajustar modelos. Volumes podem ser usados para armazenar esses arquivos de checkpoint, garantindo que o progresso do treinamento não seja perdido quando um trabalho é reiniciado após uma falha. Isso também permite executar o treinamento em instâncias spot, economizando muitos custos.
Agora, falando sobre casos de uso de ML. Na maioria dos casos, os Engenheiros de ML obtêm os dados em buckets S3, buckets GCS ou Azure Blob Storage. Agora, se eles quiserem treinar modelos com esses dados, precisam baixar os dados para sua carga de trabalho de treinamento (job implantado ou notebook) ou montar o conteúdo de seu bucket diretamente na carga de trabalho.
Quando usar Volume vs. armazenamento de objetos como S3 / GCS / Azure Container?
Escolher quando usar armazenamento de objetos como S3 vs. volume é importante do ponto de vista de desempenho, confiabilidade e custo.
Desempenho
Na maioria dos casos, a leitura de dados do S3 será mais lenta do que a leitura direta de um volume. Portanto, se a velocidade de carregamento for crucial para você, o volume é a escolha certa. Um excelente exemplo disso é o download e carregamento do modelo no momento da inferência em várias réplicas do serviço. Um volume é uma escolha melhor, pois você não incorre no tempo de download repetido do modelo e pode carregar o modelo na memória a partir do volume muito mais rapidamente.
Confiabilidade
Armazenamentos de blob como S3/GCS/ACS geralmente serão mais confiáveis do que volumes. Portanto, o ideal é sempre fazer backup dos dados brutos em um dos armazenamentos de blob e usar volumes apenas para dados intermediários. Você também deve salvar permanentemente uma cópia dos modelos no S3.
Custo
O acesso a volumes como EFS é um pouco mais barato do que usar S3 — então, se você lê os mesmos dados com bastante frequência, pode ser útil armazená-los em um volume. Se você está lendo ou escrevendo com pouca frequência, o S3 deve ser perfeitamente adequado.
Restrições de Acesso
Os dados em volumes devem, idealmente, ser acessados apenas por cargas de trabalho dentro da mesma região e cluster. O S3 é projetado para ser acessado globalmente e entre ambientes de nuvem, portanto, volumes não são uma ótima escolha se você deseja acessar os dados em uma região ou provedor de nuvem diferente.
Modos de Provisionamento de Volume
Para suportar todos os tipos de volumes, a TrueFoundry oferece dois modos de provisionamento de volume, atendendo a diferentes casos de uso:
Dinâmico
São volumes que são criados e provisionados dinamicamente à medida que você implanta um volume na Truefoundry. Por exemplo, EBS, EFS na AWS e AzureFiles no Azure podem ser provisionados dinamicamente na Truefoundry.
Estático
São volumes para os quais um volume de armazenamento já existe e queremos montar os dados desse volume de armazenamento em nosso serviço/tarefa. Exemplos incluem a montagem de buckets S3 e buckets GCS nas cargas de trabalho implantadas na plataforma.
Então, vamos entender como esses dois funcionam e quais opções estão disponíveis em cada nuvem:
Volumes Provisionados Dinamicamente
Volumes Provisionados Dinamicamente exigem que você especifique uma classe de armazenamento. Um volume é provisionado dinamicamente de acordo com a classe de armazenamento e o tamanho fornecidos pelo usuário.
Então, vamos entender o que é uma classe de armazenamento e as diferentes classes de armazenamento disponíveis em cada nuvem:
Classes de Armazenamento
As classes de armazenamento fornecem uma maneira de especificar o tipo de armazenamento que deve ser provisionado para um Volume. Essas classes de armazenamento diferem em suas características, como desempenho, durabilidade e custo. Você pode selecionar a classe de armazenamento apropriada para o seu Volume no menu suspenso Classe de Armazenamento ao criá-lo.
As classes de armazenamento específicas disponíveis dependerão do provedor de nuvem que você está usando e do que é pré-configurado pela equipe de Infraestrutura. Você geralmente verá as seguintes opções nas classes de armazenamento com base no provedor de nuvem:
Classes de Armazenamento AWS
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
efs-sc
Elastic File System (EFS)
efs.csi.aws.com
A fully managed, scalable, and highly durable elastic file system that offers high availability, automatic scaling, and cost-effective general file sharing. It's suitable for workloads with varying capacity needs.
Classes de Armazenamento GCP
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
standard-rwx
Google Basic HDD Filestore
filestore.csi.storage.gke.io
A cost-effective and scalable file storage solution ideal for general-purpose file storage and cost-sensitive workloads. It offers lower cost but also lower performance due to its HDD-based nature.
premium-rwx
Google Premium Filestore
filestore.csi.storage.gke.io
Provides higher performance and throughput compared to Basic HDD, making it suitable for I/O-intensive file operations and demanding workloads. It's SSD-based, offering higher performance at a higher cost.
enterprise-rwx
Google Enterprise Filestore
filestore.csi.storage.gke.io
Delivers the highest performance, throughput, advanced features, multi-zone support, and high availability, making it ideal for mission-critical workloads and applications with strict availability requirements. It comes with the highest cost.
Classes de Armazenamento Azure
TrueFoundry Storage Name
Cloud Provider Storage Name
Storage Class
Description
azurefile
Azure File Storage (Standard)
file.csi.azure.com
Uses Azure Standard storage to create file shares for general file sharing across VMs or containers, including Windows apps. It offers cost-effective performance.
azurefile-premium
Azure File Storage (Premium)
file.csi.azure.com
Uses Azure Premium storage for higher performance, making it suitable for I/O-intensive file operations.
azurefile-csi
Azure File Storage (StandardCSI)
file.csi.azure.com
Leverages Azure Standard storage with CSI for dynamic provisioning, potentially offering better performance and CSI features.
azurefile-csi-premium
Azure File Storage (PremiumCSI)
file.csi.azure.com
Combines Azure Premium storage with CSI for dynamic provisioning and high-performance file operations.
azureblob-nfs-premium
Azure Blob Storage (NFS Premium)
blob.csi.azure.com
Uses Azure Premium storage with NFS v3 protocol for accessing large amounts of unstructured data and object storage, catering to demanding workloads with NFS access.
azureblob-fuse-premium
Azure Blob Storage (Fuse Premium)
blob.csi.azure.com
Uses Azure Premium storage with BlobFuse for accessing large amounts of unstructured data and object storage, suitable for workloads that require BlobFuse access.
Volumes Provisionados Estaticamente
Volumes provisionados estaticamente permitem montar o seguinte como um volume:
Bucket GCS
Bucket S3
EFS Existente
Qualquer volume geral no Kubernetes
Para usar volumes provisionados estaticamente, você precisa criar um “PersistentVolume” que se refere ao seu armazenamento (S3/GCS etc). Isso exigirá que você instale os drivers CSI necessários no cluster e/ou configure as serviceaccounts relevantes para as permissões. Na próxima seção, discutiremos como você pode criar volumes provisionados estaticamente.
Montar um bucket GCS como volume
Para montar um bucket GCS como um volume no truefoundry, você precisa seguir os seguintes passos. Você pode consultar este documento para mais detalhes:
Criar um bucket GCS
Crie um bucket GCS e garanta o seguinte:
Deve ser de região única (multi-região funcionará, mas a velocidade será menor e os custos serão maiores)
A região deve ser a mesma do seu Cluster Kubernetes
Crie uma conta de serviço e Conceda as permissões relevantes
É necessário executar o seguinte script. Ele faz o seguinte:
Habilita o Driver GCS Fuse no cluster
Crie uma Política IAM para acessar seu bucket
Crie uma conta de serviço K8s e adicione a política a esta conta de serviço
Habilita a vinculação de função da conta de serviço ao namespace K8s desejado.
Crie uma Conta de Serviço no Workspace a partir da interface do Truefoundry
Agora precisamos criar uma conta de serviço no TrueFoundry no mesmo workspace com o nome: TARGET_NAMESPACE e a conta de serviço deve ter o nome GCP_SA_NAME.
Vá para Workspaces -> Escolha Seu Workspace e clique nos três pontos à direita e clique em Editar:
Abra as Opções Avançadas no canto inferior esquerdo do formulário e preencha a Conta de serviço seção:
Observação
O nome da conta de serviço e o workspace devem ser exatamente os mesmos da etapa anterior.
Crie um objeto PersistentVolume
Crie um objeto de volume persistente seguindo a etapa abaixo. (executando um kubectl apply)
Para montar um bucket S3 como um volume no Truefoundry, você precisa seguir os seguintes passos:
Configurando Políticas IAM e Funções Relevantes
Siga este documento da AWS para configurar o ponto de montagem do S3 em um cluster EKS.
Isto irá guiá-lo a fazer o seguinte:
Crie uma política IAM para conceder permissões para o ponto de montagem acessar o bucket S3
Crie uma função IAM.
Instale o driver CSI mountpoint para Amazon S3 e anexe a função que foi criada acima.
Criando um Volume Persistente no Cluster Kubernetes
Crie um PV com a seguinte especificação (executando um kubectl apply):
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 100Gi
csi:
driver: s3.csi.aws.com
volumeHandle: s3-csi-driver-volume # must be unique
volumeAttributes:
bucketName:
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: s3-test # put any value here
mountOptions:
- allow-delete
- region
- allow-other
- uid=1000
volumeMode: Filesystem
Monte um EFS Existente como um Volume
Para montar um bucket S3 como um volume no TrueFoundry, você precisa seguir os seguintes passos:
Instale o driver CSI EFS no seu cluster
Para instalar o driver CSI EFS no seu cluster, vá para a UI do Truefoundry -> Clusters-> Aplicativos Instalados-> Gerenciar
A partir dos Volumesseção, clique em instalar o driver CSI do AWS EFS e clique em Instalar.
Crie um Ponto de Acesso para o seu EFS
Localize seu EFS no console da AWS e abra-o. Certifique-se de que o EFS e o cluster K8S estejam na mesma VPC. Clique em "Criar ponto de acesso"
Insira detalhes como nome, caminho do diretório raiz (certifique-se de preencher a seção de permissões de criação do diretório raiz; você pode preencher com UID:1000 GID:1000 se quiser anexá-lo ao notebook)
Clique em criar.
Crie um PersistentVolume no cluster
Crie um PV com a seguinte especificação (executando um kubectl apply):
YAML
apiVersion: v1
kind: PersistentVolume
metadata:
name:
spec:
capacity:
storage: 5Gi # this number doesn't matter for EFS, any number will work
csi:
driver: efs.csi.aws.com
volumeHandle: :: # e.g. fs-036e93cbb1fabcdef::fsap-0923ac354cqwerty
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: efs-sc
volumeMode: Filesystem
Crie um Volume no TrueFoundry
Siga este seção para criar um volume no TrueFoundry
Usando Volumes no TrueFoundry
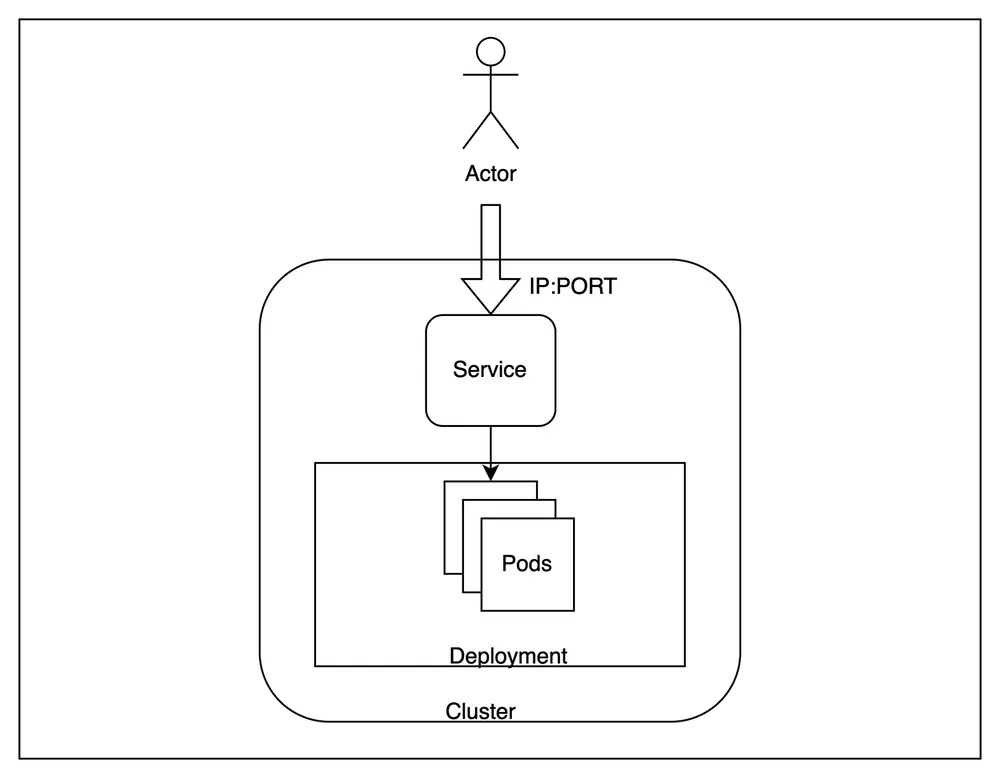
Com os guias acima, você pode provisionar volumes facilmente ou usar contêineres de armazenamento existentes como volumes. Agora, esses volumes podem ser montados em qualquer carga de trabalho no Kubernetes. Se você estiver usando isso, poderá montar seu volume facilmente em qualquer carga de trabalho no TrueFoundry. Você pode montá-lo facilmente em um serviço ou, de forma similar, em qualquer carga de trabalho implantada no TrueFoundry. Você também pode habilitar um navegador de arquivos para navegar pelo conteúdo do volume em apenas alguns cliques usando nosso navegador de volumes.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.




































.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




