




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026
.webp)
Blazingly fast way to build, track and deploy your models!
À medida que as empresas implementam IA generativa e grandes modelos de linguagem (LLMs) em produção, o gerenciamento de custos torna-se crucial. A precificação baseada em tokens, comum entre os provedores de LLM, traz uma complexidade única:
Sem uma solução dedicada de rastreamento de custos de LLM, as equipes carecem de visibilidade até que os custos aumentem inesperadamente. Isso ameaça orçamentos e impede esforços de escalonamento.
Veja como abordar o rastreamento, a governança e a otimização de ponta a ponta — juntamente com links diretos e naturais para a documentação da TrueFoundry para cada elemento central.
Construir um rastreamento de custos robusto começa pela captura de dados abrangentes e estruturados para cada solicitação de LLM. Usando o TrueFoundry AI Gateway, você pode rotear todo o tráfego de inferência, seja para um modelo de API (como OpenAI, Claude ou Mistral) ou para um modelo auto-hospedado que você opera. Este gateway atua como seu "painel único" para observabilidade e atribuição de custos.
A cada solicitação, você deve:
Uma solução abrangente de rastreamento de custos de LLM deve permitir que você imponha limites antes que os orçamentos sejam excedidos.
Juntas, essas capacidades de governança transformam o registro em uma solução de rastreamento de custos em tempo real e aplicável que evita excessos por design — e não apenas por relatórios retroativos.
Após a observabilidade e a governança, a otimização é o processo contínuo de redução de gastos sem sacrificar o desempenho ou a qualidade.
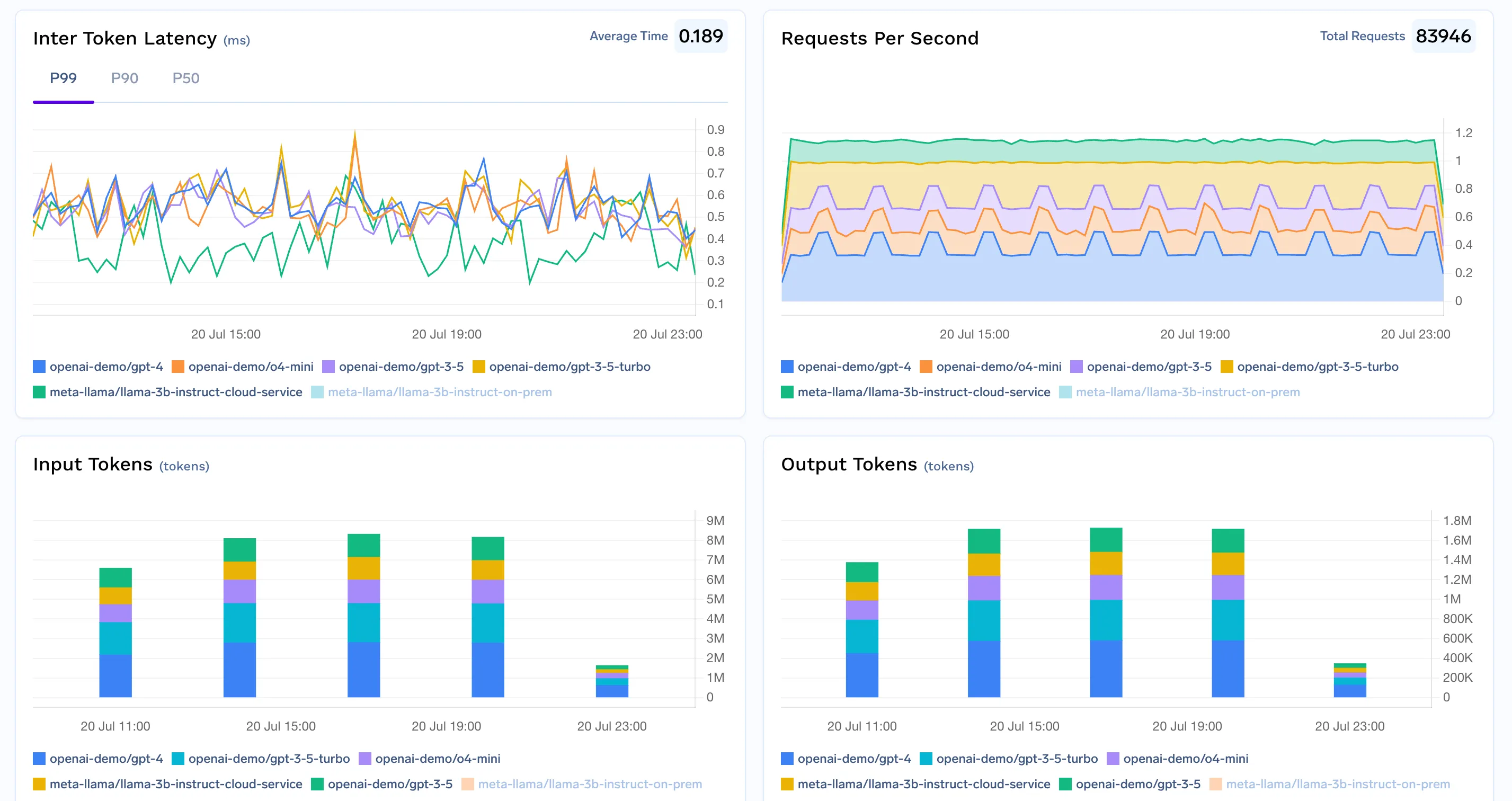
A otimização de custos bem-sucedida exige monitoramento constante. Os seguintes são vitais para acompanhar em todo o seu stack:
Uma moderna solução de rastreamento de custos de LLM é mais do que apenas relatórios pós-fato — é um plano de controle estratégico para cada fase da implantação de IA, desde a governança diária até a otimização contínua. Ao aproveitar os recursos abrangentes oferecidos por o Gateway de IA da TrueFoundry, as equipes obtêm visibilidade granular, controles proativos de gastos e roteamento consciente de custos para cada LLM que utilizam, seja via API ou clusters auto-hospedados.
Para uma análise técnica aprofundada passo a passo, veja:
Uma solução de rastreamento de custos de LLM é um plano de controle estratégico projetado para monitorar, gerenciar e otimizar as despesas únicas associadas às operações de Modelos de Linguagem Grandes. Ao contrário da infraestrutura de nuvem tradicional, ela rastreia especificamente preços baseados em tokens, cargas de inferência variáveis e recursos computacionalmente intensivos. Essas plataformas fornecem visibilidade em tempo real dos gastos em vários provedores, modelos e equipes.
Rastrear os custos de uso de LLM é fundamental porque os custos da infraestrutura de IA podem crescer exponencialmente e silenciosamente devido à precificação de tokens baseada no consumo. Sem monitoramento granular, as organizações enfrentam estouros orçamentários massivos, faturamento mensal imprevisível e falta de responsabilidade financeira. O rastreamento eficaz garante um crescimento sustentável ao vincular cada dólar gasto a um valor de negócio mensurável e ROI.
Existem várias ferramentas e plataformas especializadas que atualmente lideram o mercado no gerenciamento e rastreamento de custos de LLM. A TrueFoundry oferece um Gateway de IA unificado para gerenciamento de gastos e governança de múltiplos modelos. Outras soluções proeminentes incluem LiteLLM, que fornece um proxy leve para visibilidade de gastos em tempo real, e Portkey, que se concentra na atribuição detalhada de custos para aplicações de IA generativa.
Sim, a maioria das plataformas LLMOps avançadas integra nativamente uma solução de rastreamento de custos de LLM para gerenciar todo o ciclo de vida do modelo. Plataformas como TrueFoundry e Weights & Biases capturam dados de telemetria detalhados em ambientes de produção, exibindo os custos de token juntamente com as métricas de desempenho. Essa integração nativa permite que os desenvolvedores otimizem tanto a precisão quanto a eficiência financeira dentro de um fluxo de trabalho único e unificado.
As soluções de rastreamento de custos de LLM utilizam monitoramento em tempo real para disparar notificações automatizadas por e-mail, Slack ou webhooks quando o uso atinge porcentagens predefinidas de um orçamento. Esses sistemas podem ser configurados com regras de aplicação automatizadas que limitam o tráfego ou bloqueiam solicitações assim que um limite máximo é atingido. Esse alerta proativo evita cargas de trabalho "descontroladas" e garante que as salvaguardas financeiras permaneçam em vigor.
A TrueFoundry é uma solução ideal para rastreamento de custos de LLM porque combina atribuição de custos em tempo real com um contexto profundo baseado em metadados. Ela permite que as empresas definam preços personalizados por modelo e estabeleçam limites orçamentários granulares para equipes, projetos ou ambientes específicos. Seu AI Gateway otimiza ainda mais os gastos através de roteamento inteligente, cache semântico e fallbacks automáticos de modelos, garantindo alto desempenho ao menor preço possível.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




