



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Setores de saúde, financeiro e alguns outros estão implementando IA generativa sem nunca tocar a internet pública. Isolamento de rede não é um sinalizador de configuração — é uma arquitetura onde cada dependência que o sistema precisa em tempo de execução já está dentro do enclave.
"Air-gapped" não é uma alegação de marketing sobre o formato da implantação. É a restrição fundamental do formato de implantação. Todo o resto decorre de "nenhuma rota para o exterior".
Em uma implantação empresarial típica, "isolado" significa uma VPC privada, um gateway NAT, egresso restrito e uma lista de permissões de endpoints externos aprovados — registros de pacotes, APIs de modelo, endpoints de telemetria, provedores de identidade. O sistema é segregado; não é isolado. O egresso existe, controlado mas presente. Um auditor perguntando "para onde o sistema se conecta?" recebe uma lista de destinos permitidos, não silêncio.
Isolamento de rede é uma afirmação mais forte. Não há gateway NAT. Não há servidor DNS que resolva nomes de host externos. Não há cadeia de autoridade de certificação que confie em algo fora do enclave. Existe — dependendo do regime — ou nenhuma conexão de rede com o exterior, ou apenas um diodo de dados unidirecional para exportação de telemetria. Código, dados e dependências entram via mídia física assinada; nada entra pela rede. O auditor fazendo a mesma pergunta obtém uma resposta definitiva: nada sai, nada entra, exceto na cadência controlada para a qual a implantação foi certificada.
Esta é a postura de implantação para cargas de trabalho de defesa classificadas (estruturas de acreditação típicas: DoD IL5 e IL6, FedRAMP High, às vezes CMMC Nível 2 ou Nível 3 para a base industrial de defesa), para sistemas de saúde que lidam com dados clínicos controlados (HIPAA com HITRUST CSF atestação, às vezes requisitos adicionais em nível estadual), para sistemas financeiros sob regimes regulatórios mais rigorosos (FFIEC e SR 11-7 para o risco de modelo bancário, NYDFS Parte 500 para cibersegurança), e para ambientes de controle industrial onde qualquer tráfego de saída é proibido por política. A distinção é importante legalmente, não apenas operacionalmente: uma implantação "isolada" ainda pode constituir uma transferência de dados para um fornecedor sob algumas estruturas regulatórias; uma implantação air-gapped, por construção, não pode.
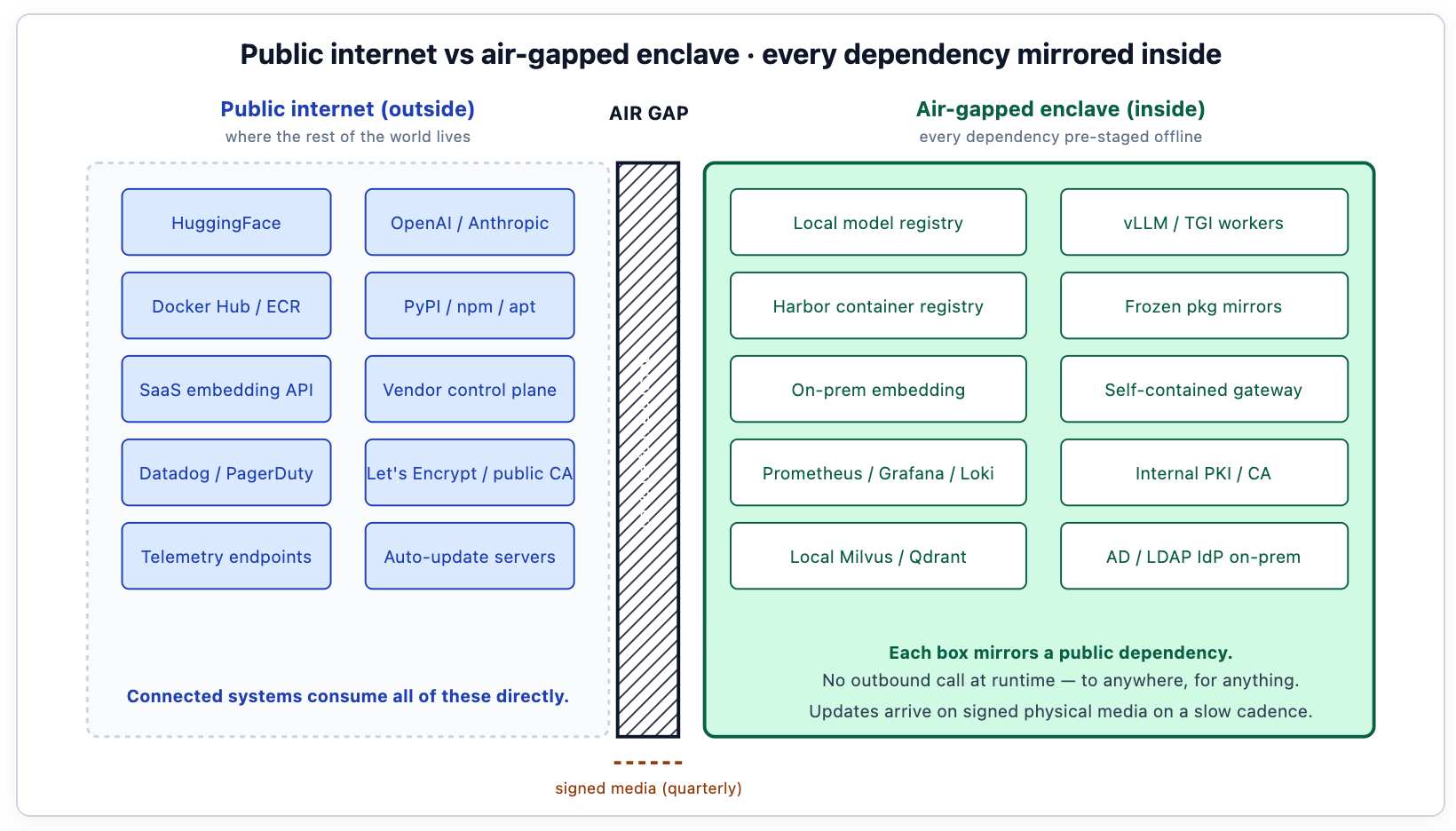
O diagrama é a arquitetura. Cada componente que uma implantação conectada à internet consumiria de algum lugar externo precisa ter um espelho dentro do enclave. O espelho existe; o consumo é local. A integridade da implantação depende de cada byte de cada dependência ser auditável — versionado, assinado, escaneado e congelado no momento da preparação. O lado direito do diagrama é o que uma instalação baseada em Helm de uma plataforma de IA como TrueFoundry preenche dentro do enclave: o plano de dados do gateway, o registro de modelos, os workers de serviço, o armazenamento de vetores, a pilha de observabilidade, o motor de políticas — tudo conectado ao IdP on-premise do cliente, CA interna e SIEM via valores Helm, em vez de endpoints de fornecedores.
Os pesos do modelo são importados uma vez via pacote assinado, verificados com SHA-256 contra o hash publicado pelo autor do modelo e, em seguida, selados dentro do enclave. Os workers de inferência subsequentes puxam do registro local, nunca do HuggingFace. As atualizações seguem o mesmo caminho: uma nova versão do modelo chega em mídia física, tem sua assinatura verificada e é preparada no registro sob um novo rótulo de versão.
Isso parece oneroso para equipes acostumadas a pip install, e de fato é. A razão pela qual vale a pena é que a integridade da implantação depende de cada byte de cada peso ser auditável. O processo de importação assinado é o rastro de auditoria. Quando o auditor pergunta "de onde veio este modelo e como você sabe que ele não foi adulterado?", a implantação responde com uma cadeia de assinaturas: o autor do modelo assinou o lançamento, a equipe de segurança verificou a assinatura na importação, o registro gravou a versão sob um processo de custódia. Essa cadeia é o que torna o modelo utilizável em um contexto regulamentado.
O esquema de metadados do registro é tão importante quanto o armazenamento. Cada versão do modelo é registrada com sua origem, seu hash, sua data de importação, seu engenheiro responsável e os resultados de avaliação que a qualificaram para produção. Esta é a mesma disciplina de artefatos versionados que a equipe aplica ao código, aplicada aos pesos do modelo. No TrueFoundry, o Registro de Modelos mantém esses campos como metadados de primeira classe, então a pergunta do auditor tem uma resposta estruturada na própria plataforma, em vez de estar em uma planilha de propriedade de uma única pessoa. Equipes que tratam modelos como arquivos ad-hoc têm dificuldades em auditorias; equipes que os tratam como artefatos de classe de código têm as respostas prontas.
A geração de tokens acontece inteiramente dentro do enclave, no cluster H100, A100 ou MI300 do cliente (ou o que o regime permitir; alguns ambientes classificados restringem a escolha de hardware como parte dos controles da cadeia de suprimentos). Nenhuma chamada de API de provedor jamais sai do limite. A pilha de serviço é a mesma vLLM, TGI ou SGLang que o resto do mundo usa; o que muda é que ela roda em um ambiente onde não pode "telefonar para casa" para telemetria, atualizações automáticas de modelo ou serviços de embedding externos.
Os próprios motores de serviço geralmente precisam de patches para operação air-gapped. Por padrão, o vLLM verifica o HuggingFace em busca de arquivos de tokenizador se eles não estiverem pré-preparados; essa verificação deve ser desativada, ou o tokenizador deve estar no caminho do registro local. Alguns motores buscam servidores de telemetria na inicialização; essas chamadas devem ser desativadas ou apontadas para um coletor local. A aplicação de patches é um trabalho único, mas é importante: equipes que a ignoram descobrem os modos de falha em tempo de execução, quando um pod de worker se recusa a iniciar porque não consegue acessar a internet para uma verificação de metadados. A pilha de serviço do TrueFoundry é fornecida com esses patches air-gapped implementados — as fontes do tokenizador apontam para caminhos de registro locais, os endpoints de telemetria apontam para a pilha de observabilidade on-premise, e a atualização automática está desativada por padrão nos valores Helm air-gapped. Os mesmos backends vLLM, TGI e SGLang que as equipes usam em implantações conectadas rodam no enclave; a diferença é qual arquivo de valores a implantação carrega.
RAG sobre documentos classificados exige que o modelo de embedding também seja executado dentro do enclave. Enviar texto para uma API de embedding remota, mesmo uma fornecida por uma grande nuvem, é a ação que mais frequentemente quebra o air gap (isolamento físico) na prática. As equipes descobrem o vazamento quando o monitoramento de rede mostra consultas DNS para api.openai.com originado da pipeline de recuperação supostamente isolada (air-gapped); a etapa de embedding estava usando um SDK que por padrão apontava para o provedor de nuvem.
A implantação utiliza um modelo de embedding on-premise — tipicamente um modelo de código aberto menor que é rápido em CPU ou executa eficientemente nas mesmas GPUs que os workers de serviço. Escolhas comuns: um modelo de embedding de 384 ou 768 dimensões, como bge-small, nomic-embed, ou uma variante ajustada para domínio para conteúdo especializado. O índice vetorial é criptografado em repouso com chaves gerenciadas pelo cliente, acessado apenas de dentro do enclave, e tem backup feito para o mesmo regime de mídia que o restante da implantação utiliza.
A escolha do armazenamento vetorial — Milvus, Qdrant, pgvector — importa menos do que a higiene da implantação em torno dele. O armazenamento precisa do mesmo tratamento de artefato versionado que o registro de modelos: os snapshots do corpus são registrados, a versão do modelo de embedding é registrada, o processo de construção do índice é reproduzível. Quando o corpus muda, o trabalho de re-embedding é executado em uma cadência controlada e o auditor pode rastrear qualquer resultado de recuperação até um snapshot específico do corpus. O manifesto de implantação da TrueFoundry fixa o modelo de embedding on-premise e o armazenamento vetorial como parte da mesma instalação Helm, para que a equipe não os obtenha separadamente no momento do staging — a escolha do modelo de embedding e do backend vetorial é um parâmetro configurável via arquivo de valores; a postura de isolamento (air-gap) não é.
O AI Gateway da TrueFoundry, em implantações isoladas (air-gapped), é executado como uma carga de trabalho conteinerizada implantada via Helm no cluster Kubernetes do cliente dentro do enclave. Não há dependências de rede de saída para nenhuma de suas operações em tempo de execução: a identidade vem do IdP local (geralmente Active Directory ou LDAP, às vezes um provedor SAML operado pelo cliente), a política reside em disco local sob controle de versão, os logs de auditoria vão para o SIEM local (Splunk on-prem na maioria das implantações de defesa, às vezes um equivalente construído pelo cliente). Não há telemetria para um plano de controle de fornecedor; métricas de saúde agregadas, se exportadas, passam por um diodo de dados unidirecional para um ambiente de monitoramento separadamente credenciado.
O conjunto de recursos do gateway é o mesmo em implantações isoladas (air-gapped) e conectadas. A mesma limitação de taxa de tokens por hora por projeto, equipe ou fluxo de trabalho. A mesma aplicação de orçamento por projeto com limites rígidos que bloqueiam novas solicitações quando um orçamento é atingido. O mesmo roteamento de fallback baseado em prioridade entre alvos de modelo locais. As mesmas barreiras de proteção de entrada e saída — anonimização de PII / PHI em entradas antes que o modelo as veja, detecção de segredos em saídas antes que cheguem ao cliente, detecção de injeção de prompt para cargas de trabalho com formato de agente. As funcionalidades são executadas; elas emitem sua telemetria para a pilha local em vez de para a nuvem de observabilidade de um fornecedor. A configuração que as impulsiona é o mesmo YAML.
Isso é relevante na prática porque uma equipe de plataforma que opera um ambiente de desenvolvimento conectado e um ambiente de produção isolado (air-gapped) não está operando duas plataformas — está operando uma plataforma com dois arquivos de valores. A imagem do gateway é a mesma; o gráfico é o mesmo; a superfície da API é a mesma. O investimento em engenharia no gateway compensa em todas as formas de implantação simultaneamente.
Toda imagem de contêiner que a implantação utiliza precisa vir de algum lugar. Em um ambiente conectado, esse lugar é o Docker Hub ou o ECR. Dentro do enclave, é um Harbor local ou um registro equivalente, populado no momento do staging a partir de espelhos externos e depois congelado. O mesmo se aplica a PyPI, npm, apt e qualquer outro gerenciador de pacotes de linguagem do qual o sistema dependa. Os snapshots são verificados quanto a vulnerabilidades no staging e depois fixados.
A disciplina é que nada que o sistema precise em tempo de execução pode ser algo em constante mudança. O mundo exterior muda; o interior do enclave não, exceto em uma cadência controlada. Uma CVE publicada ontem em uma dependência Python não se propaga automaticamente para o enclave; ela se propaga na próxima atualização programada, após a equipe de segurança tê-la revisado. Isso às vezes é desconfortável para equipes acostumadas a apt-get upgrade; é a troca que a postura de implantação exige.
O fluxo de trabalho de instalação isolada (air-gapped) da TrueFoundry publica todas as imagens de contêiner e gráficos Helm em um registro compatível com OCI sob o controle do cliente. O cliente replica a partir do registro upstream da TrueFoundry (tfy.jfrog.io/tfy-images para as imagens de contêiner, tfy.jfrog.io/tfy-helm para os gráficos Helm) no momento do staging, ou trabalha a partir do Harbor ou Artifactory existente do cliente se a equipe de engenharia de lançamento do cliente já domina a disciplina de espelhamento upstream. O catálogo do registro de contêineres torna-se o inventário de dependências — quando um auditor pergunta "qual software está sendo executado neste enclave?", a resposta é o manifesto do registro. Equipes que não mantêm seu registro organizado falham nesta pergunta; equipes que tratam o registro como um inventário curado e responsável passam no teste.
Prometheus, Grafana e Loki cobrem a maioria das métricas, painéis e logs. Tudo local. Os painéis exportam para um console SOC local, não para um fornecedor SaaS. O roteamento de alertas passa por e-mail interno ou equivalentes de Slack on-premise, não por Twilio ou PagerDuty. A própria pilha de observabilidade é uma das maiores cargas de trabalho dentro do enclave; não é incomum que a infraestrutura de monitoramento consuma mais capacidade de computação do que as cargas de trabalho de IA que monitora durante períodos de baixa atividade.
O gateway da TrueFoundry é nativo de OpenTelemetry; em implantações isoladas (air-gapped), o pipeline OTEL emite para o Prometheus e Loki locais em vez de para a nuvem de observabilidade de um fornecedor. Mesma instrumentação, mesmo esquema de rastreamento, destino diferente. A observabilidade por solicitação inclui a identidade, a tag da carga de trabalho, o modelo resolvido, as decisões de política aplicadas, os veredictos dos guardrails e o ID de rastreamento — tudo o que a auditoria precisa para reconstruir quem perguntou o quê, de qual modelo, sob qual política e como o gateway respondeu. A retenção de logs de auditoria é configurável para os longos períodos de retenção (sete anos é comum em ambientes de defesa e finanças regulamentadas) que os regimes de auditoria exigem.
O roteamento de alertas é o ponto onde a maioria das equipes descobre que suas suposições on-premise estão erradas. Enviar um SMS via Twilio quando o gateway satura é o comportamento correto em uma implantação conectada e uma violação do isolamento (air gap) em uma implantação enclausurada. O runbook de resposta a incidentes da equipe precisa ser reescrito para o enclave: o plantonista recebe o alerta por canais internos, o SOC recebe uma notificação paralela por meio de escalonamento interno, o escalonamento de suporte de fornecedor externo (se houver) ocorre por um canal diferente e credenciado.
CAs públicas (Let's Encrypt, DigiCert) não são acessíveis. A implantação usa a PKI interna do cliente, com âncoras de confiança carregadas no momento da instalação. mTLS entre gateway e workers, entre gateway e IdP, entre cada serviço interno: tudo verificado contra a CA interna. Isso parece uma nota de rodapé; é a razão pela qual a maioria das implantações "isoladas" na verdade não são air-gapped, porque alguém deixou certbot acessando um endpoint público para renovar um certificado.
A CA interna é responsabilidade do cliente, não da plataforma. A plataforma consome os âncoras de confiança da CA no momento da instalação — para o TrueFoundry, via valores Helm que apontam para o arquivo de âncora de confiança montado nos pods do gateway. A equipe de PKI do cliente executa a CA, emite certificados e os rotaciona. O ciclo de vida do certificado é uma das cargas operacionais para as quais a equipe de PKI do cliente precisa planejar. Certificados de curta duração (90 dias ou menos) são uma boa prática, mas exigem automação que a equipe precisa provisionar antes que a implantação entre em produção.
As atualizações são a realidade operacional que distingue o air-gapped do teoricamente air-gapped. O modelo melhora; o gateway recebe novos recursos; o vLLM lança uma correção crítica. Nada disso pode ser aplicado via git pull.
A disciplina é um fluxo de trabalho de pacote assinado. O fornecedor publica um lançamento como um tarball assinado — manifestos, imagens de contêiner, gráfico Helm e (se aplicável) artefatos de peso, com um hash de integridade. O pacote é carregado em mídia física (tipicamente um pendrive ou disco rígido removível, dependendo da política de mídia do regime), transportado através da lacuna de ar e preparado em um servidor de retenção dentro do enclave. A integridade é verificada, as assinaturas são checadas contra chaves públicas do fornecedor pré-carregadas, e o pacote é instalado sob um novo rótulo de versão. A versão anterior permanece disponível para rollback por uma janela configurável — tipicamente 30 dias — para que uma atualização problemática possa ser revertida sem outro ciclo de importação de pacote.
Os lançamentos air-gapped do TrueFoundry são entregues exatamente neste formato: pacotes assinados contendo o gráfico, os manifestos, as imagens do gateway e dos workers, e os hashes de integridade. A verificação ocorre contra chaves públicas do TrueFoundry pré-carregadas; o pacote é preparado no registro do cliente sob um novo rótulo de versão; o rollback é um rollback Helm para a revisão anterior do gráfico. A revisão de acreditação do cliente se aplica ao pacote, não a um fluxo contínuo de mudanças — cada atualização é um evento de acreditação discreto com um claro antes e depois, que é a propriedade que o fluxo de trabalho de pacote existe para fornecer.
A cadência depende do regime. Alguns ambientes de defesa aceitam atualizações trimestrais; alguns ambientes de saúde permitem mensais. Alguns ambientes não aceitam nada sem uma revisão de acreditação separada por lançamento — cada pacote é um novo evento de acreditação. A plataforma tem que suportar tudo isso sem mudar de forma; a configuração de "com que frequência atualizamos" é do cliente, não do fornecedor.

Os quatro níveis representam um contínuo de confiança entre a implantação e o mundo exterior. O nível conectado (a maioria das cargas de trabalho, a maioria das empresas) aceita a conectividade do fornecedor como parte rotineira da operação. O nível BYOC aceita a conectividade do fornecedor para o plano de controle, mas não para os dados — os payloads permanecem dentro da conta de nuvem do cliente. O nível air-gapped + diodo aceita apenas exportação unidirecional, tipicamente para monitoramento SOC de métricas de saúde agregadas. O nível totalmente air-gapped não aceita nenhuma conectividade de rede de qualquer tipo. A maioria do trabalho de defesa classificado é executada nos dois níveis inferiores; a maioria do trabalho de saúde e finanças é executada em BYOC; a maioria do trabalho empresarial geral é executada em conectado.
O TrueFoundry suporta todos os quatro níveis a partir da mesma base de código — a mesma imagem de gateway, o mesmo gráfico Helm, o mesmo esquema de configuração. Os valores Helm mudam entre os níveis; as primitivas do gateway não. O plano de controle e o plano de dados do gateway são implantáveis independentemente, o que torna isso possível: em SaaS conectado, ambos os planos são executados no ambiente do TrueFoundry; em BYOC, o plano de controle é SaaS e o plano de dados é executado na VPC do cliente; em air-gapped, ambos os planos são executados dentro do enclave do cliente. Uma equipe de plataforma que executa SaaS em desenvolvimento e air-gapped em produção classificada não opera duas plataformas — ela opera uma plataforma configurada de forma diferente. O investimento em engenharia no gateway compensa em todas as formas de implantação simultaneamente.
A maioria das implantações "air-gapped" que falham em sua primeira auditoria falham não porque a arquitetura estava errada, mas porque uma dependência específica vazou a lacuna. Cinco padrões se repetem nas primeiras tentativas das equipes; conhecê-los antecipadamente é o que produz implantações que passam na revisão.
Telemetria padrão do SDK. SDKs de provedores de nuvem (boto3, google-cloud, azure-sdk) rotineiramente emitem telemetria para endpoints de fornecedores na inicialização. O código do aplicativo parece inocente — ele importa uma biblioteca, instancia um cliente — e a biblioteca "chama para casa" antes que o código da equipe faça qualquer coisa. A solução é auditar o comportamento de rede de cada dependência durante a fase de staging, desabilitar a telemetria via configuração onde o SDK suporta, e aplicar patches onde não suporta. O monitoramento de saída durante o staging é o que revela essas chamadas antes da produção.
Download automático de tokenizador. Muitas bibliotecas de ML baixam arquivos de tokenizador do HuggingFace por padrão no primeiro uso. O motor de serviço que carregou o modelo com sucesso falha três semanas depois, quando um pod de worker reinicia e o tokenizador em cache desaparece. A solução é pré-preparar os tokenizadores no registro local e apontar o motor para o caminho local via configuração, em vez de depender do seu comportamento de download padrão.
Pulls de imagem de contêiner em tempo de execução. Um deployment Kubernetes que referencia image: vllm/vllm:latest em vez de image: harbor.internal.example.mil/vllm/vllm:v0.6.3 falhará em tempo de execução em um ambiente air-gapped. A solução é a política de espelhamento de registro: cada referência de imagem em cada manifesto aponta para o Harbor local; nenhum manifesto referencia um registro externo, ponto final. Controladores de admissão podem impor isso no momento da implantação.
Renovação de certificado acessando o exterior. O deployment foi instalado com certificados internos; a automação de renovação padroniza para Let's Encrypt ou uma CA pública similar. Três meses depois, a tarefa de renovação é executada e falha — ou pior, consegue alcançar o endpoint público, comprometendo a postura de auditoria. A solução é conectar a renovação de certificados à PKI interna do cliente desde o primeiro dia, e não como uma reflexão tardia.
NTP e DNS pela rede. A sincronização de tempo padroniza para pools NTP públicos; a resolução de DNS padroniza para servidores públicos. A rede do deployment é "isolada", mas de alguma forma os pods de worker ainda estão se comunicando com pool.ntp.org. A solução é a infraestrutura interna de NTP e DNS do cliente, configurada no nível do cluster para que nenhum pod possa acidentalmente acessar o exterior, mesmo que o código de sua aplicação não tivesse essa intenção.
O padrão comum: a falha está na camada da plataforma abaixo da carga de trabalho de IA, e não na própria carga de trabalho de IA. A equipe escreve seu pipeline RAG corretamente, mas uma dependência transitiva faz uma chamada externa. A defesa é o monitoramento de saída em etapas — executando o deployment em um sandbox conectado com registro completo de saída, tratando qualquer conexão externa inesperada como uma descoberta, e prosseguindo para a instalação air-gapped somente depois que o sandbox estiver limpo. O ambiente de staging em modo conectado da TrueFoundry existe precisamente para isso: a mesma imagem de gateway e o mesmo Helm chart que serão executados no enclave são executados primeiro em um sandbox onde cada conexão de saída é observável, para que os modos de falha sejam identificados antes de chegarem a um ambiente regulamentado. A integridade do deployment air-gapped é amplamente garantida na fase de staging.
As implementações air-gapped são mais lentas do que as implementações BYOC, que são mais lentas do que as adoções de SaaS. A sequência abaixo é o plano típico de vários meses; apressá-lo produz deployments que falham na revisão de acreditação.
Meses 1-2 — Engajamento de acreditação. A equipe de segurança do cliente e a autoridade de acreditação revisam a documentação da plataforma, o inventário de dados, o fluxo de trabalho de atualização e a postura criptográfica. O resultado é um pacote de acreditação que define exatamente como o deployment será e quais controles se aplicam. Este é o artefato contra o qual o deployment será medido posteriormente; acertar isso economiza semanas de remediação. A equipe de engenharia de deployment da TrueFoundry geralmente participa desta fase, fornecendo a documentação de arquitetura, a postura de cifra FIPS 140-3 (onde o deployment é executado dentro AWS GovCloud or Azure Government), e o processo de assinatura de pacote que a autoridade de acreditação revisará.
Meses 3-4 — Ambiente de staging. O cliente constrói um enclave de staging que espelha a topologia de produção, mas não contém dados classificados. A plataforma é instalada via Helm contra o espelho de registro local; as integrações (IdP, SIEM, CA interna, observabilidade on-premise) são configuradas; o fluxo de trabalho de atualização é exercitado com um pacote assinado de amostra. O deployment de staging é executado por pelo menos um mês sob carga simulada, com registro completo de saída habilitado para que qualquer conexão externa inesperada seja identificada como uma descoberta antes da produção.
Meses 5-6 — Instalação em produção e acreditação. A plataforma é instalada no enclave de produção. A autoridade de acreditação realiza a revisão formal em relação ao pacote previamente acordado. As constatações são corrigidas; a implantação é acreditada sob a estrutura de autorização apropriada (DoD IL5/IL6 para defesa classificada, FedRAMP High para civis federais, estruturas específicas do setor para saúde e finanças).
Meses 7+ — Operação em estado estável. A plataforma atende cargas de trabalho regulamentadas. O fluxo de trabalho de atualização é executado em sua cadência certificada (trimestral, mensal ou por evento de acreditação). A equipe de segurança do cliente é responsável pela postura de conformidade operacional; a equipe SRE do cliente é responsável pela operação diária. A TrueFoundry se limita ao canal de escalonamento acreditado para suporte a incidentes e à cadência de lançamento trimestral — a implantação é do cliente, não do fornecedor, neste ponto.
Air-gapped não é o mesmo que apenas rodar on-premise. Uma implantação on-premise típica ainda se conecta a gerenciadores de pacotes, puxa imagens de contêiner de registros externos e envia telemetria para um fornecedor de observabilidade SaaS. Essa implantação reside no data center da empresa. Não é air-gapped. Os dois são rotineiramente confundidos, e a confusão é exatamente o que os reguladores procuram durante as auditorias.
Também não está isento de custo operacional. Manter registros espelhados, operar uma PKI interna, realizar engenharia de lançamento em uma cadência trimestral — estas são cargas de engenharia reais que não existem em implantações conectadas. As equipes que operam sistemas air-gapped sabem disso; as equipes que estão prestes a herdar um geralmente não sabem, e a lacuna entre as duas é onde a maioria das implantações falhas se origina. As revisões de aquisição para plataformas air-gapped frequentemente subestimam a carga operacional contínua do cliente por um fator de dois ou três.
E não é um substituto para a prática de conformidade. A arquitetura remove os riscos baseados em rede; não remove os riscos humanos. Ameaças internas, má configuração, violação de política e erro operacional ainda são riscos que a equipe de segurança do cliente precisa gerenciar. O air gap é um controle físico forte; não é um substituto para o restante de uma postura de defesa em profundidade.
E não é a resposta certa para todas as equipes. Organizações cujas cargas de trabalho não exigem de fato uma postura air-gapped pagam o custo operacional sem obter o benefício regulatório; para essas cargas de trabalho, o BYOC oferece a maior parte do benefício de soberania de dados a uma fração do custo operacional, e a camada conectada é materialmente ainda mais fácil. Organizações que já construíram plataformas air-gapped maduras com seu próprio histórico de acreditação enfrentam um custo de migração em um ambiente acreditado que pode ser difícil de justificar. Air-gapped é o formato de implantação para cargas de trabalho onde o regime regulatório exige nenhuma conectividade externa; para todo o resto, as camadas mais simples existem por uma razão.
O trabalho da plataforma é tornar a carga operacional gerenciável, não fingir que ela não existe.
O cliente provisiona um registro compatível com OCI dentro do enclave (tipicamente Harbor, às vezes JFrog Artifactory ou o equivalente em nuvem). A equipe de engenharia de lançamento espelha as imagens de contêiner e os gráficos Helm da TrueFoundry — por exemplo, obtidos de tfy.jfrog.io/tfy-images e tfy.jfrog.io/tfy-helm — para o registro, seja por replicação direta de um ambiente de staging conectado ou por meio de um pacote assinado transportado através do air gap em mídia física. A instalação do Helm então é executada contra o registro local, os manifestos de imagem locais e o cluster Kubernetes do cliente. Os valores do Helm apontam para o IdP do cliente, CA interna, SIEM e pilha de observabilidade. O mesmo gráfico que é instalado em um ambiente de desenvolvimento conectado é instalado no ambiente de produção air-gapped; apenas o arquivo de valores difere.
Através do fluxo de trabalho de pacote assinado. O autor do modelo publica um lançamento; a equipe de engenharia de lançamento do cliente o importa na cadência certificada (trimestral, mensal ou por evento de acreditação). O pacote é verificado por assinatura, preparado no registro local, implantado em um subconjunto canary e promovido para produção após observação. A versão anterior permanece disponível para rollback dentro de uma janela configurável.
Não — modelos de ponta hospedados vivem fora do enclave por definição; chamá-los quebraria o isolamento físico. Implantações com isolamento físico usam modelos de código aberto auto-hospedados (Llama, Mistral, Qwen, Phi-3) em GPUs locais. A qualidade é frequentemente suficiente para a classe de carga de trabalho (extração, sumarização, classificação, RAG sobre corpora internos); cargas de trabalho que realmente exigem raciocínio de ponta tipicamente não se encaixam na postura de isolamento físico e precisam ser projetadas para um nível menos restrito.
Atualizações de segurança críticas têm um caminho fora da banda: um pacote de emergência assinado, certificado mais rapidamente do que a cadência padrão, distribuído através do mesmo fluxo de trabalho de mídia física. A equipe de segurança do cliente decide se um CVE se qualifica como emergencial; o processo de lançamento da plataforma suporta a cadência mais rápida para os casos que precisam. A desvantagem é que os pacotes de emergência ignoram partes da revisão de acreditação normal e exigem validação posterior.
Maior do que para uma implantação conectada da mesma carga de trabalho — em média, cerca de 2 a 3 vezes maior. O cliente precisa de operações de PKI, manutenção de espelhos, engenharia de lançamento, ligação de acreditação e a rotação usual de SRE. Para uma única carga de trabalho, isso pode significar 3 a 5 engenheiros dedicados; para uma implantação que hospeda múltiplas cargas de trabalho, o custo marginal por carga de trabalho é menor porque a infraestrutura operacional é compartilhada.
As próprias GPUs são as mesmas; o que muda é a cadeia de suprimentos e a política de firmware. Ambientes classificados podem restringir quais hardwares de fornecedores são aceitáveis, exigir versões específicas de firmware e requerer proveniência validada da cadeia de suprimentos. A plataforma funciona com o que a política de hardware do regime permitir; a equipe de compras do cliente lida com a aquisição do hardware.
Para o nível do diodo, sim — a telemetria pode ser exportada continuamente, mas apenas em sentido único. O diodo é uma garantia física de que nenhum dado pode entrar no enclave através do canal de exportação. O que sai é o que a acreditação do cliente aprovou: métricas agregadas, telemetria operacional estruturada, possivelmente dados de desempenho anonimizados. Cargas úteis por solicitação não saem sob nenhuma condição.
Idêntico a uma implantação conectada, mas com tudo local. O conjunto de ouro reside no armazenamento local. O trabalho de replay é executado contra a frota de serviço local. O modelo de juiz é um dos modelos de código aberto implantados localmente. Os painéis de fatiamento residem no Grafana on-premise. O auto-rollback se conecta ao registro local de versões de prompt. A disciplina de avaliação é a mesma; apenas os destinos diferem.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




