




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 29, 2026
Blazingly fast way to build, track and deploy your models!
Grandes modelos de linguagem como o ChatGPT e modelos de difusão como o Stable Diffusion conquistaram o mundo em pouco menos de um ano. Cada vez mais organizações estão começando a aproveitar a IA Generativa para seus casos de uso existentes e novos e empolgantes. Embora a maioria das empresas possa começar a usar diretamente as APIs fornecidas por empresas como OpenAI, Anthropic, Cohere, etc., essas APIs também vêm com um custo elevado. A longo prazo, muitas empresas gostariam de ajustar versões de pequeno a médio porte de LLMs de código aberto equivalentes, como Llama, Flan-T5, Flan-UL2, GTP-Neo, OPT, Bloom, etc., como Alpaca e GPT4All fizeram os projetos.
O ajuste fino de modelos menores com saídas de modelos maiores pode ser útil de várias maneiras:
Para viabilizar tudo isso, as GPUs se tornaram uma ferramenta essencial em qualquer empresa que trabalhe com esses modelos fundamentais. Com o tamanho dos modelos crescendo e atingindo trilhões de parâmetros, o treinamento distribuído em múltiplas GPUs está se tornando lentamente a nova norma. A Nvidia está liderando o espaço de hardware com suas placas mais recentes das séries Ampere e Hopper. Interconexões de alta velocidade NVLink e Infiniband permitem conectar até 256 Nvidia A100 ou Nvidia H100 (e ~4k em clusters super pod) para treinar e inferir com modelos cada vez maiores em tempos recordes.
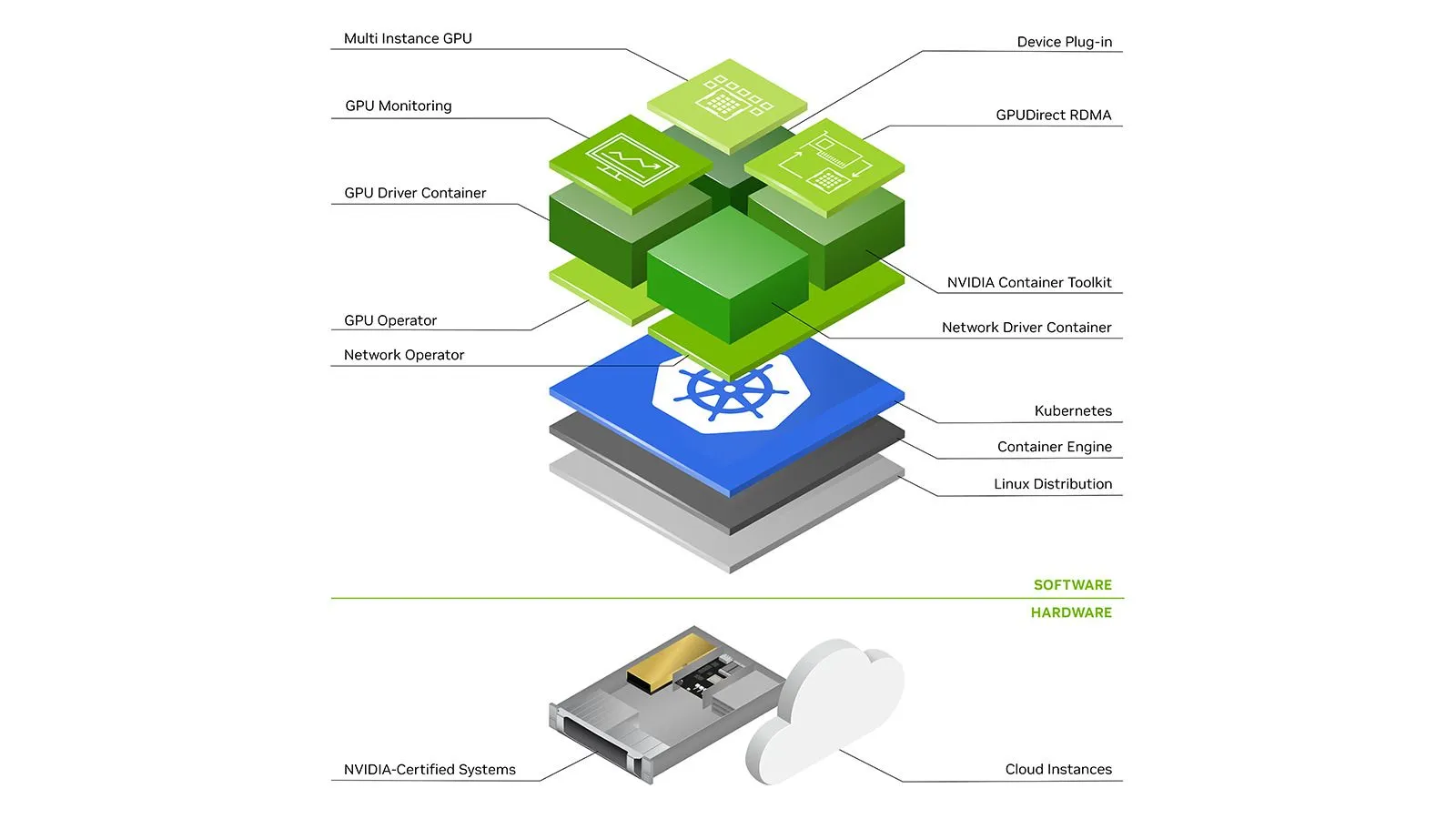
Vamos agora abordar os componentes necessários para usar GPUs com Kubernetes – principalmente no AWS EKS e GCP GKE (Standard ou Autopilot), mas os componentes mencionados são essenciais em qualquer cluster K8s.
Seu provedor de nuvem possui VMs de GPU, como os trazemos para o cluster K8s? Uma maneira é configurar manualmente Nodepools de GPU de tamanho fixo ou com autoescalador de cluster que pode adicionar nós de GPU quando necessário e liberá-los quando não forem mais precisos. No entanto, isso ainda exige a configuração manual de vários pools de nós diferentes. Uma solução ainda melhor é configurar sistemas de provisionamento automático como AWS Karpenter ou GCP Node Auto Provisioners. Falamos sobre isso em nosso artigo anterior: Autoescalonamento de Cluster para as 3 Maiores Nuvens ☁️
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu-provisioner
namespace: karpenter
spec:
weight: 10
kubeletConfiguration:
maxPods: 110
limits:
resources:
cpu: "500"
requisitos:
- chave: karpenter.sh/capacity-type
operador: In
valores:
- spot
- on-demand
- chave: topology.kubernetes.io/zone
operador: In
valores:
- ap-south-1
- chave: karpenter.k8s.aws/instance-family
operador: In
valores:
- p3
- p4
- p5
- g4dn
- g5
taints:
- chave: "nvidia.com/gpu"
efeito: "NoSchedule"
providerRef:
nome: padrão
ttlSecondsAfterEmpty: 30
Exemplo de configuração do Provisionador Automático de Nós do GCP
limitesDeRecursos:
- tipoDeRecurso: 'cpu'
mínimo: 0
máximo: 1000
- tipoDeRecurso: 'memória'
mínimo: 0
máximo: 10000
- tipoDeRecurso: 'nvidia-tesla-v100'
mínimo: 0
máximo: 4
- tipoDeRecurso: 'nvidia-tesla-t4'
mínimo: 0
máximo: 4
- tipoDeRecurso: 'nvidia-tesla-a100'
mínimo: 0
máximo: 4
autoprovisioningLocations:
- us-central1-c
management:
autoRepair: true
autoUpgrade: true
shieldedInstanceConfig:
enableSecureBoot: true
enableIntegrityMonitoring: true
diskSizeGb: 100
Note que aqui também podemos configurar nossos provisionadores para usar spot instâncias para obter de 30 a 90% de economia de custos para aplicativos sem estado.
Para que qualquer máquina virtual utilize GPUs, seus drivers precisam ser instalados no host. Felizmente, tanto nos nós AWS EKS quanto GCP GKE, os nós vêm pré-configurados com certas versões de Drivers Nvidia.
Como cada versão mais recente do CUDA requer uma versão mínima de driver mais alta, você pode até querer controlar a versão do driver para todos os nós. Isso pode ser feito provisionando nós com imagens personalizadas que não possuem o driver e permitindo que o gpu-operator instalar uma versão específica. No entanto, isso pode não ser permitido em todos os provedores de nuvem, portanto, esteja ciente das versões dos drivers em seus nós para evitar problemas de compatibilidade.
Falaremos sobre o gpu-operator mais adiante.
No Kubernetes, como tudo é executado dentro de pods (um conjunto de contêineres), apenas instalar drivers no host não é suficiente. A Nvidia fornece um componente autônomo chamado nvidia-container-toolkit que instala hooks para containerd runC para disponibilizar os drivers e dispositivos de GPU do host aos contêineres em execução no nó. Consulte este artigo para uma explicação mais detalhada.
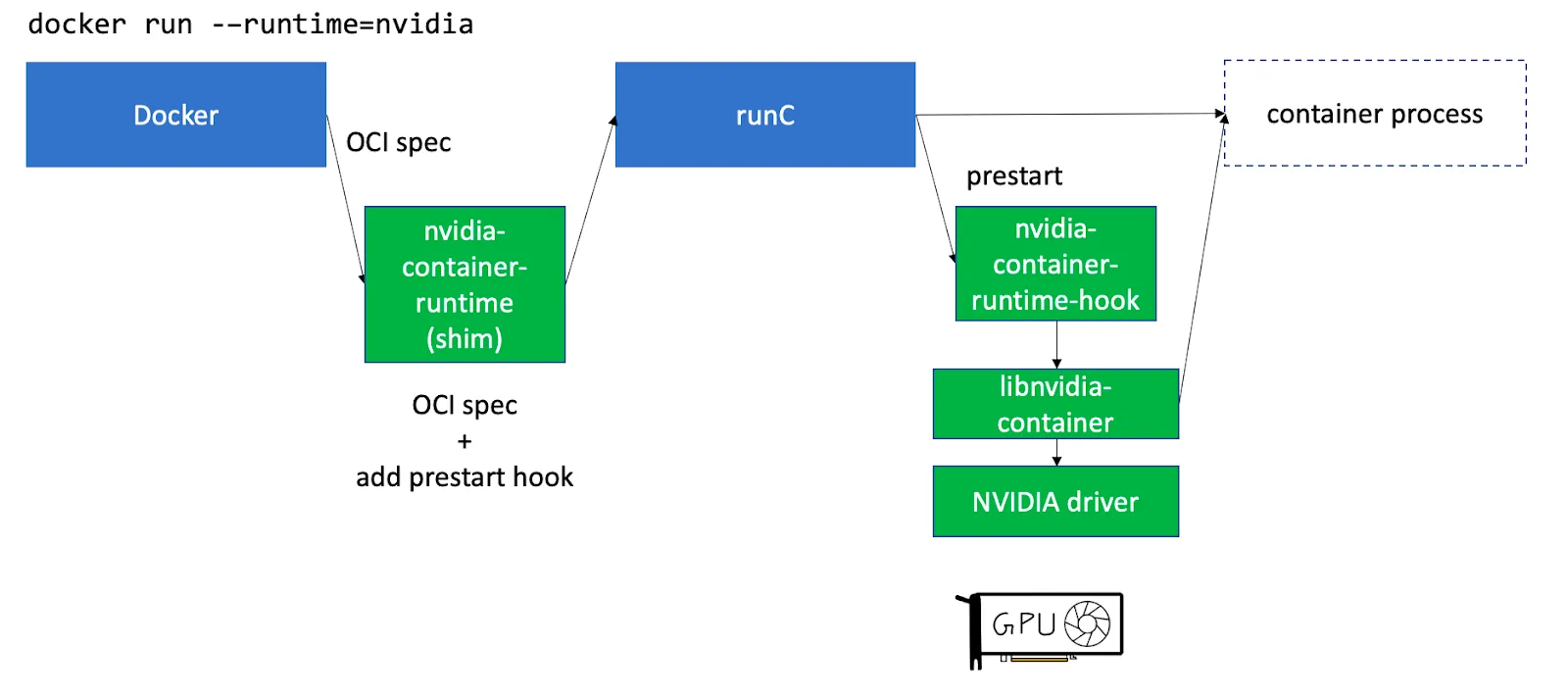
nvidia-container-toolkit pode ser instalado para ser executado como Daemonset nos nós de GPU.
Ter GPUs no nó não é suficiente; o agendador do Kubernetes precisa saber qual nó tem quantas GPUs disponíveis. Isso pode ser feito usando um Device Plugin. Um plugin de dispositivo permite anunciar recursos de hardware personalizados para o plano de controle, por exemplo, nvidia.com/gpu . A Nvidia publicou um plugin de dispositivo que anuncia GPUs alocáveis em um nó. Este plugin, novamente, pode ser executado como um Daemonset.
Uma vez que os componentes acima estejam configurados, precisamos adicionar algumas coisas à especificação do pod para agendá-lo no nó de GPU - principalmente recursos , afinidade e tolerâncias
Por exemplo, no GCP GKE podemos fazer:
spec:
# Definimos quantas GPUs queremos para o pod
resources:
limits:
nvidia.com/gpu: 2
# afinidades nos ajudam a colocar o pod nos nós de GPU
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
# Especificar qual família de instância queremos
- operator: In
key: cloud.google.com/machine-family
values:
- a2
# Especificar qual tipo de GPU queremos
- operator: In
key: cloud.google.com/gke-accelerator
values:
- nvidia-tesla-a100
# Especificar que queremos uma VM spot
- operator: In
key: cloud.google.com/gke-spot
values:
- "true"
tolerations:
# VMs spot têm um taint, então mencionamos uma tolerância para ele
- key: cloud.google.com/gke-spot
operador: Igual
valor: "true"
efeito: NoSchedule
# Marcamos os nós de GPU, então mencionamos uma tolerância para isso
- chave: nvidia.com/gpu
operador: Exists
efeito: NoSchedule
resources.limits seçãoObserve que essas configurações variarão dependendo dos métodos de provisionamento e provedores de nuvem que você usa (por exemplo, Karpenter na AWS vs NAP no GKE)
Monitorar métricas de GPU como Utilização, Uso de Memória, Consumo de Energia, Temperatura, etc., é importante para garantir que as coisas estejam funcionando sem problemas, bem como para realizar otimizações adicionais.
Felizmente, a Nvidia possui um componente chamado dcgm-exporter que pode ser executado como Daemonset em nós de GPU e publicar métricas em um endpoint. Essas métricas podem então ser coletadas com Prometheus e consumidas. Aqui está um exemplo de configuração de coleta:
- job_name: gpu-metrics
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: endpoints
namespaces:
names:
- <dcgm-exporter-namespace-here>
relabel_configs:
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: kubernetes_node
No entanto, observe que dcgm-exporter precisa ser executado com hostIPC: true e privilegiado securityContext. Isso é aceitável para EKS e GKE Standard. No entanto, o GKE Autopilot não permite tal acesso; em vez disso, O GKE publica métricas nos Daemonsets nvidia-device-plugin pré-configurados, que podem ser coletadas ou visualizadas no GCP Cloud Monitoring.
AWS EKSGCP GKE StandardGCP GKE AutopilotProvisionamentoKarpenter / ManualProvisionador Automático de Nós GCP / ManualProvisionamento AutomáticoDriversPré-instalado/Instalar via gpu-operatorPré-instaladoPré-instaladoContainer Toolkitnvidia-container-toolkitvia gpu-operatorPré-configuradoPré-configuradoDevice Pluginnvidia-device-pluginvia gpu-operatorDaemonset Pré-configuradoDaemonset Pré-configuradoMétricasnvidia-dcgm-exportervia gpu-operatorAutônomo nvidia-dcgm-exporter / Raspagem PersonalizadaRaspagem Personalizada
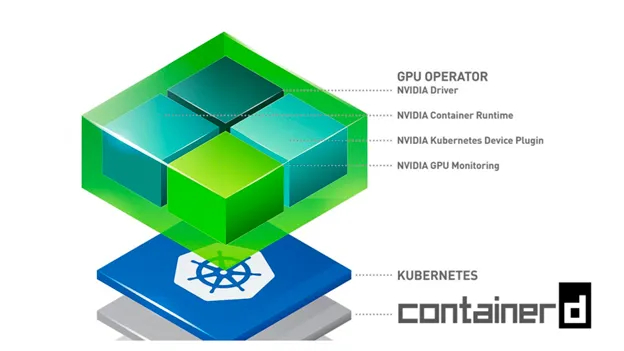
O gpu-operator mencionado acima, na maioria das partes no AWS EKS, é um conjunto de componentes Nvidia autônomos, como drivers, container-toolkit, device-plugin e exportador de métricas, entre outros, todos combinados e configurados para serem usados juntos por meio de um único helm chart. O gpu-operator executa um pod mestre no plano de controle que pode detectar nós de GPU no cluster. Ao detectar um nó de GPU, ele implanta um Daemonset de worker que, por sua vez, agenda pods para instalar opcionalmente drivers, container toolkit, device-plugin, CUDA toolkit, exportador de métricas e validadores. Você pode ler mais sobre isso
[SEG 10]
aqui .Uma observação sobre o CUDA Toolkit
PATH e LD_LIBRARY_PATH variáveis. Além disso, todos os pods no mesmo nó precisam usar a mesma versão do CUDA toolkit, o que pode ser bastante restritivo. Portanto, é melhor colocar o CUDA toolkit (ou apenas partes dele) dentro da imagem do contêiner. CUDA Toolkit
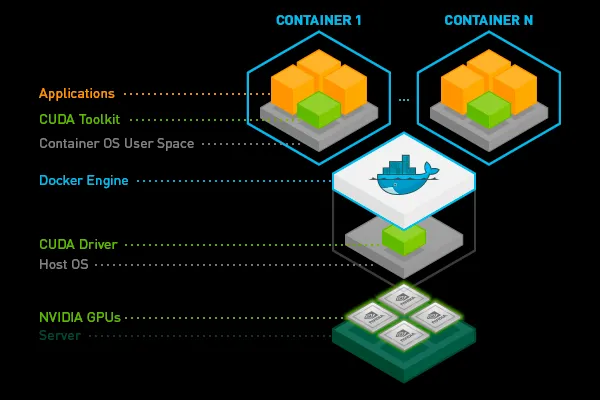
Nvidia ou o seu de deep learning favorito framework ou adicione-o com uma única linha na plataforma Truefoundry
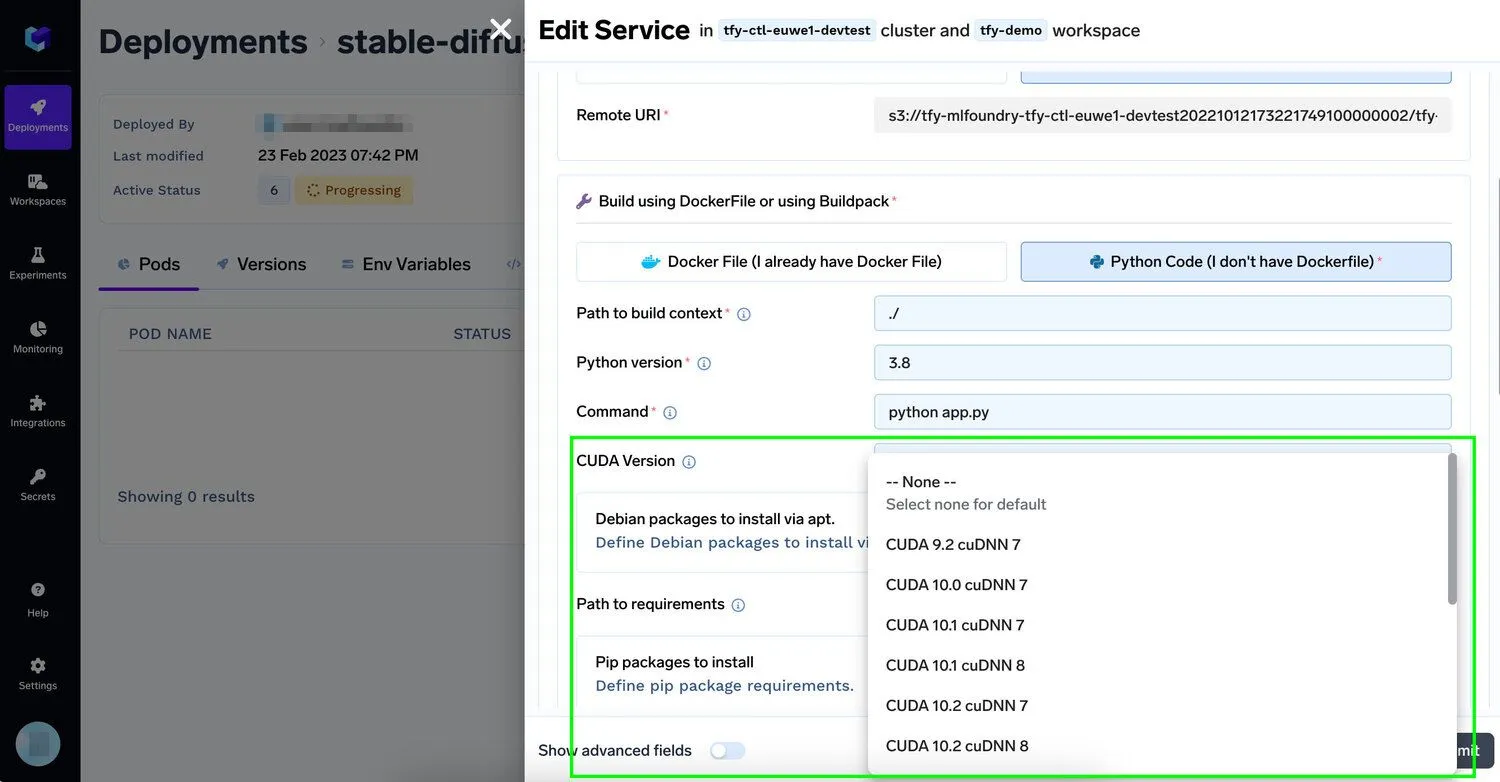
Para permitir que as organizações ajustem e implementem seus modelos de IA Generativa mais rapidamente em sua infraestrutura existente, a plataforma TrueFoundry permite que os desenvolvedores adicionem uma ou mais GPUs Nvidia às suas aplicações com esforço mínimo, ao mesmo tempo em que suporta fluxos de trabalho usados em conjunto com as melhores ferramentas de engenharia de prompt. Os desenvolvedores só precisam especificar quantas instâncias de algumas das melhores GPUs para Machine Learning, como V100, P100, A100 40GB, A100 80GB (ideais para treinamento) ou T4, A10 (ideais para inferência), eles precisam, e nós fazemos o resto. Leia mais em nossa documentação. À medida que as cargas de trabalho de IA baseadas em GPU entram em produção, esse tipo de controle de infraestrutura também se torna importante para plataformas mais amplas de segurança de IA, onde o isolamento de computação, a governança de acesso e a observabilidade da carga de trabalho devem funcionar em conjunto.
GPUs são uma tecnologia fantástica e este é apenas o começo para nós. Estamos trabalhando ativamente nos seguintes problemas:
Se algo disso lhe parece interessante, por favor, entre em contato para trabalhar conosco para construir a melhor plataforma MLOps.
TrueFoundry é uma PaaS de implantação de ML sobre Kubernetes para acelerar os fluxos de trabalho dos desenvolvedores, ao mesmo tempo que lhes permite total flexibilidade no teste e implantação de modelos, garantindo total segurança e controle para a equipe de Infraestrutura. Através da nossa plataforma, capacitamos as equipes de Machine Learning a implantar e monitorar modelos em 15 minutos com 100% de confiabilidade, escalabilidade e a capacidade de reverter em segundos – permitindo-lhes economizar custos e lançar Modelos em produção mais rapidamente, possibilitando a realização de valor de negócio real.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




