








October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Neste blog, vamos apresentar a você o treinamento de modelos de machine learning na Plataforma TrueFoundry. Discutiremos como podemos executar jobs de treinamento na TrueFoundry. Também veremos como você pode realizar o ajuste de hiperparâmetros facilmente para seus modelos de machine learning e executar seus jobs em GPUs.
Vamos começar com uma declaração do problema: digamos que queremos ver como a doença de diabetes progredirá em um paciente com base em várias características como idade, IMC, pressão arterial, etc. Neste blog, treinaremos o Dataset de Diabetes modelo de machine learning no scikit-learn.
Falando em treinar modelos de machine learning, existem várias maneiras de fazer isso, como treinar localmente na sua máquina, treinar em Jupyter Notebooks, etc. No entanto, o processo de treinamento pode exigir mais recursos do que os disponíveis em uma máquina local.
É aqui que os Jobs da TrueFoundry permitem que você implante o código de treinamento para ser executado em uma máquina remota e você pode rastrear os logs e métricas.
Nota: Embora estejamos usando este dataset de diabetes, as instruções mencionadas neste blog se aplicam a outros modelos de machine learning / deep learning também.
Jobs fornecem uma maneira de executar tarefas em lote de curta duração, paralelas ou sequenciais dentro do cluster. Jobs são projetados para serem executados até a conclusão, em vez de serem serviços de longa duração ou aplicações em execução contínua. Uma vez que um job é concluído, os recursos de computação e memória são liberados, portanto, não incorremos em custos extras.
Como dito antes, usaremos o Conjunto de Dados de Diabetes no scikit-learn. O conjunto de dados contém 442 amostras (pacientes) e 10 características, todas numéricas. As características representam vários fatores que podem afetar a progressão do diabetes em pacientes. A variável alvo também é numérica e representa uma medida quantitativa da progressão da doença um ano após a linha de base para cada paciente.
Antes de prosseguirmos para o treinamento de modelos de machine learning, vamos revisar as instruções de configuração:
Vá para o Painel do TrueFoundry e crie uma conta. Assim que fizer login, será solicitado que você crie um espaço de trabalho. Você implantará seus trabalhos neste espaço de trabalho.

Depois de criar seu espaço de trabalho, prossiga e crie um Repositório ML a partir do painel.
Um Repositório ML é uma coleção de execuções, modelos e artefatos que representa um projeto de Machine Learning. Você pode pensar nele como um repositório git, exceto que ele abriga artefatos, modelos e metadados. Todos os controles de acesso podem ser configurados no nível do repositório ML.
Uma vez criado o Repositório ML, vá para os espaços de trabalho, edite seu espaço de trabalho e ative 'Acesso ao Repositório ML'. Clique em 'Adicionar Acesso ao Repositório ML' para adicionar seu Repositório ML a este espaço de trabalho. Isso concederá ao trabalho em execução no espaço de trabalho permissão para escrever e ler do repositório ML.
pip install servicefoundry
--host: Insira o URL do seu Painel TrueFoundry aqui
sfy login --host <YOUR-HOST-URL-HERE>
Depois de concluídas as instruções de configuração acima, podemos prosseguir para a seção de implementação.
Estrutura de Diretórios
Neste blog, seguiremos a seguinte estrutura de diretórios onde:
❯ tree
.
├── deploy.py
├── requirements.txt
└── train.py
Agora, vamos analisar o código de treinamento do modelo de diabetes:
Etapas de Treinamento do Modelo
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.compose import TransformedTargetRegressor
from sklearn.preprocessing import QuantileTransformer
from sklearn.svm import SVR
X, y = load_diabetes(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
regressor = SVR(kernel=kernel)
model = TransformedTargetRegressor(
regressor=regressor,
transformer=QuantileTransformer(n_quantiles=n_quantiles, output_distribution="normal"),
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
Código Completo de Treinamento do Modelo
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.compose import TransformedTargetRegressor
from sklearn.preprocessing import QuantileTransformer
from sklearn.svm import SVR
def train(kernel: str, n_quantiles: int):
# carregar o conjunto de dados e criar conjuntos de treino e teste
X, y = load_diabetes(as_frame=True, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# inicializar o modelo
regressor = SVR(kernel=kernel)
model = TransformedTargetRegressor(
regressor=regressor,
transformer=QuantileTransformer(n_quantiles=n_quantiles, output_distribution="normal"),
)
# treinar e testar o modelo
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Precisão: {accuracy:.2f}"
return regressor, model, X_test, y_test
Agora que vimos o código para treinar um modelo de machine learning, podemos prosseguir e aprender sobre como salvar (ou registrar) esses modelos para uso futuro.
Um Modelo é composto por um arquivo de modelo e alguns metadados. Cada Modelo pode ter múltiplas versões. Podemos serializar, salvar e versionar objetos de modelo automaticamente usando o save_model_metadata método e os seguintes são os passos para fazê-lo:
Etapas de Registro de Modelo
import mlfoundry
run = mlfoundry.get_client().create_run(ml_repo=ml_repo, run_name="SVR-with-QT")
Uma Execução representa um único experimento que, no contexto de Machine Learning, é um modelo específico (por exemplo, Regressão Logística), com um conjunto fixo de hiperparâmetros. Métricas e parâmetros (detalhes abaixo) são todos registrados sob uma execução específica.
run.log_params(regressor.get_params())
run.log_metrics({"score": model.score(X_test, y_test)})
model_version = run.log_model(name="diabetes-regression", model=model, framework="sklearn")
print("model_version =", model_version.version, "model_fqn =", model_version.model_fqn)
Cada modelo registrado gera uma nova versão associada ao nome e vinculada à execução atual. Múltiplas versões do modelo podem ser registradas como versões separadas sob o mesmo nome.
Código Completo de Registro de Modelo
import mlfoundry
def save_model_metadata(regressor, model, X_test, y_test, ml_repo):
# cria uma execução no ml_repo do truefoundry
run = mlfoundry.get_client().create_run(ml_repo=ml_repo, run_name="SVR-with-QT")
# registra os hiperparâmetros do modelo
run.log_params(regressor.get_params())
# registra as métricas do modelo
run.log_metrics({"score": model.score(X_test, y_test)})
# registra o modelo
model_version = run.log_model(name="diabetes-regression", model=model, framework="sklearn")
print("model_version =", model_version.version, "model_fqn =", model_version.model_fqn)
Agora que vimos o processo de treinamento e registro de modelos, podemos compilá-lo em um único train.py arquivo. O conteúdo final do train.py arquivo deve ser assim:
train.py
# imports necessários para ambas as funções
def train(kernel, n_quantiles):
...
def save_model_metadata(regressor, model, X_test, y_test, ml_repo):
...
regressor, model, X_test, y_test = train(kernel="linear", n_quantiles=100)
save_model_metadata(regressor, model, X_test, y_test, ml_repo="YOUR ML REPO NAME")
Isso completa nosso código para treinamento e registro do modelo. Agora precisamos implantar o código de treinamento do modelo como um job. O deploy.py contém o código para implantar o código de treinamento do modelo acima, conforme mostrado abaixo:
deploy.py
from servicefoundry import Build, Job, PythonBuild, LocalSource
# definindo as especificações do job
job = Job(
name="diabetes-train-job",
image=Build(
build_spec=PythonBuild(command="python train.py", requirements_path="requirements.txt"),
build_source=LocalSource(local_build=False)
),
)
deployment = job.deploy(workspace_fqn="YOUR WORKSPACE FQN HERE")
O requirements.txt deve conter os seguintes pacotes:
requirements.txt
pandas==1.3.5
scikit-learn==1.2.1
mlfoundry>=0.7.2,<0.8.0
No deploy.py código, uma tarefa é implantada que exibe a pontuação de precisão do modelo treinado nos logs quando é invocada. Ele também registra o modelo de machine learning treinado. Para fazer isso, um objeto de tarefa é criado usando a servicefoundry.Job classe. O nome da tarefa é mantido como diabetes-train-job aqui.
NOTA: Certifique-se de substituir "YOUR ML REPO NAME" pelo nome do seu Repositório ML em train.py e "YOUR WORKSPACE FQN HERE" com o FQN do seu espaço de trabalho em deploy.py arquivo.
No arquivo train.py , você precisa passar o Nome do Repositório de ML que você criou para a função save_model_metadata() . No arquivo deploy.py , você precisa passar o FQN do espaço de trabalho que você criou para a função job.deploy() . Agora execute o seguinte comando para implantar o trabalho:
python deploy.py
Após implantar o trabalho de treinamento, vá para a subseção "Trabalhos" na seção "Implantações"; deve ser semelhante a isto:
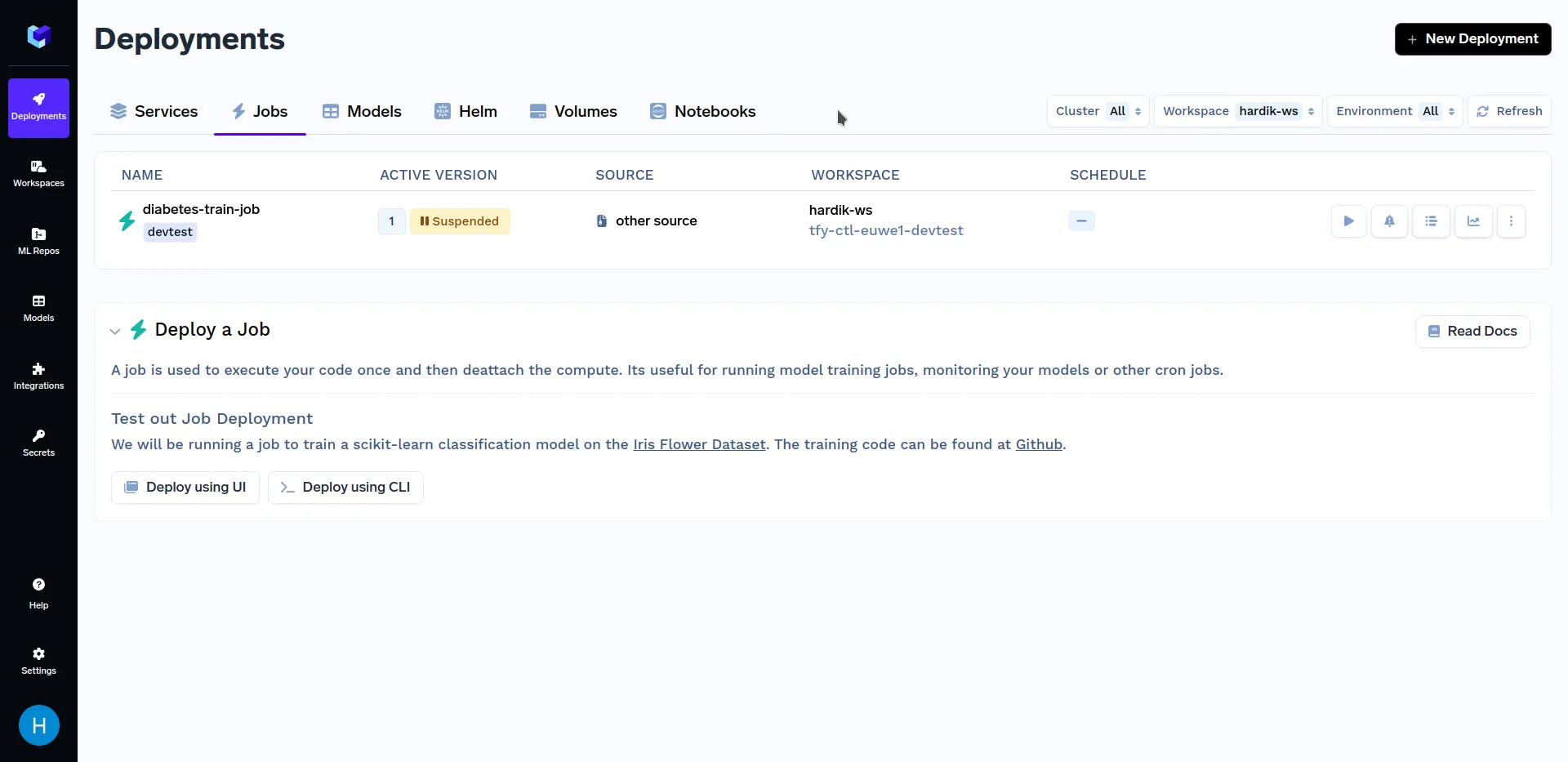
Agora que terminamos de implantar nosso trabalho, vamos querer acioná-lo. Você pode fazer isso usando tanto nosso SDK Python ou o Dashboard TrueFoundry. Primeiramente, falaremos sobre como disparar tarefas a partir do Dashboard TrueFoundry. Para conhecer outros métodos de disparo de tarefas, consulte a seção Disparando Tarefas a partir do SDK Python .
Depois que a tarefa de treinamento acima tiver concluído a implantação, vá para a subseção "Tarefas" na seção "Implantações", clique em "diabetes-train-job"e clique em "Executar Tarefa" para configurar a tarefa antes de dispará-la. Deve ser parecido com isto:
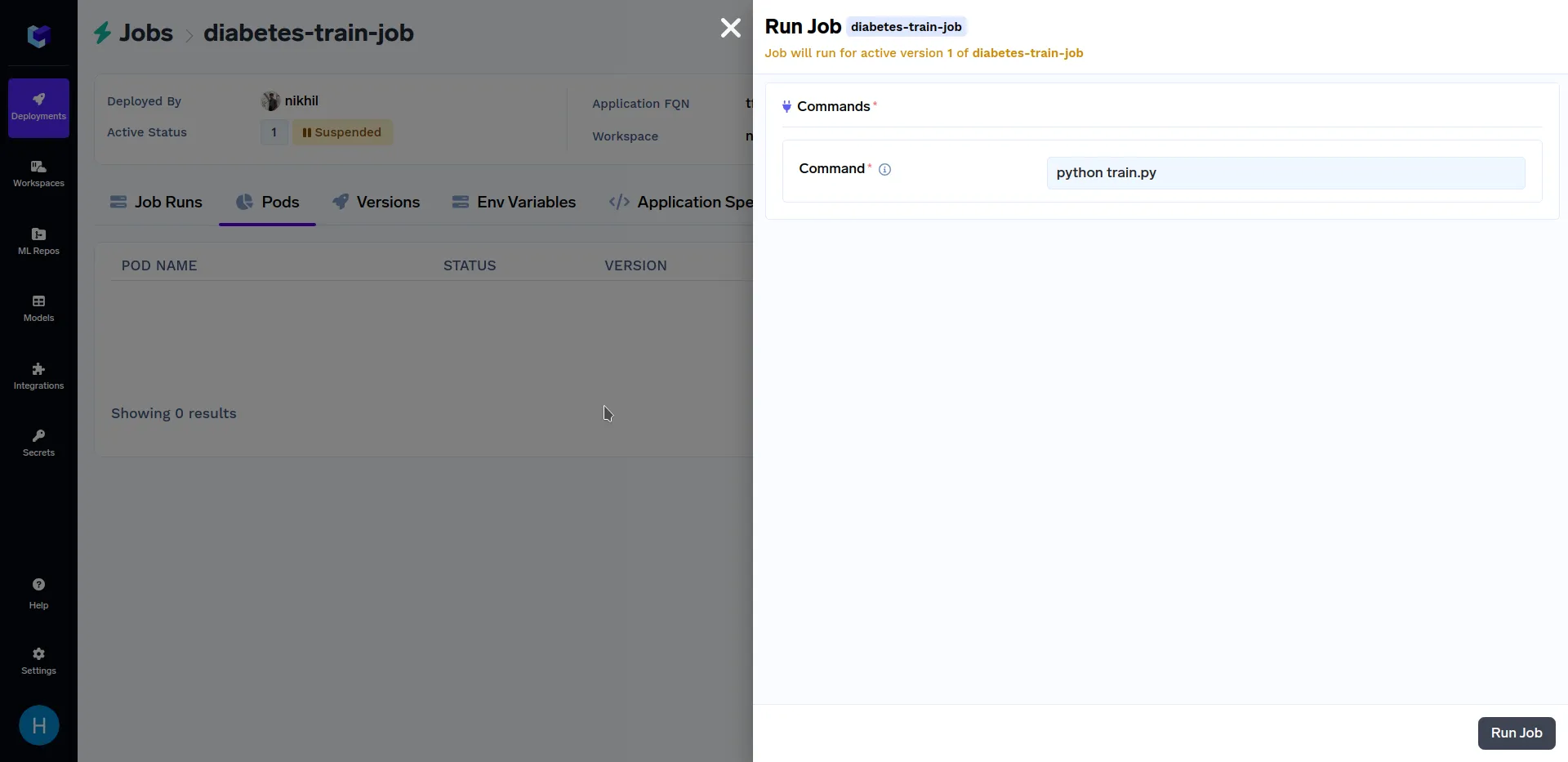
Quando estiver na tela acima, clique em "Executar Tarefa" no canto inferior direito para disparar esta tarefa. Depois que a tarefa de treinamento tiver concluído a execução, vá para a subseção "Tarefas" na seção "Implantações" e clique em "diabetes-train-job", deve ser parecido com isto:
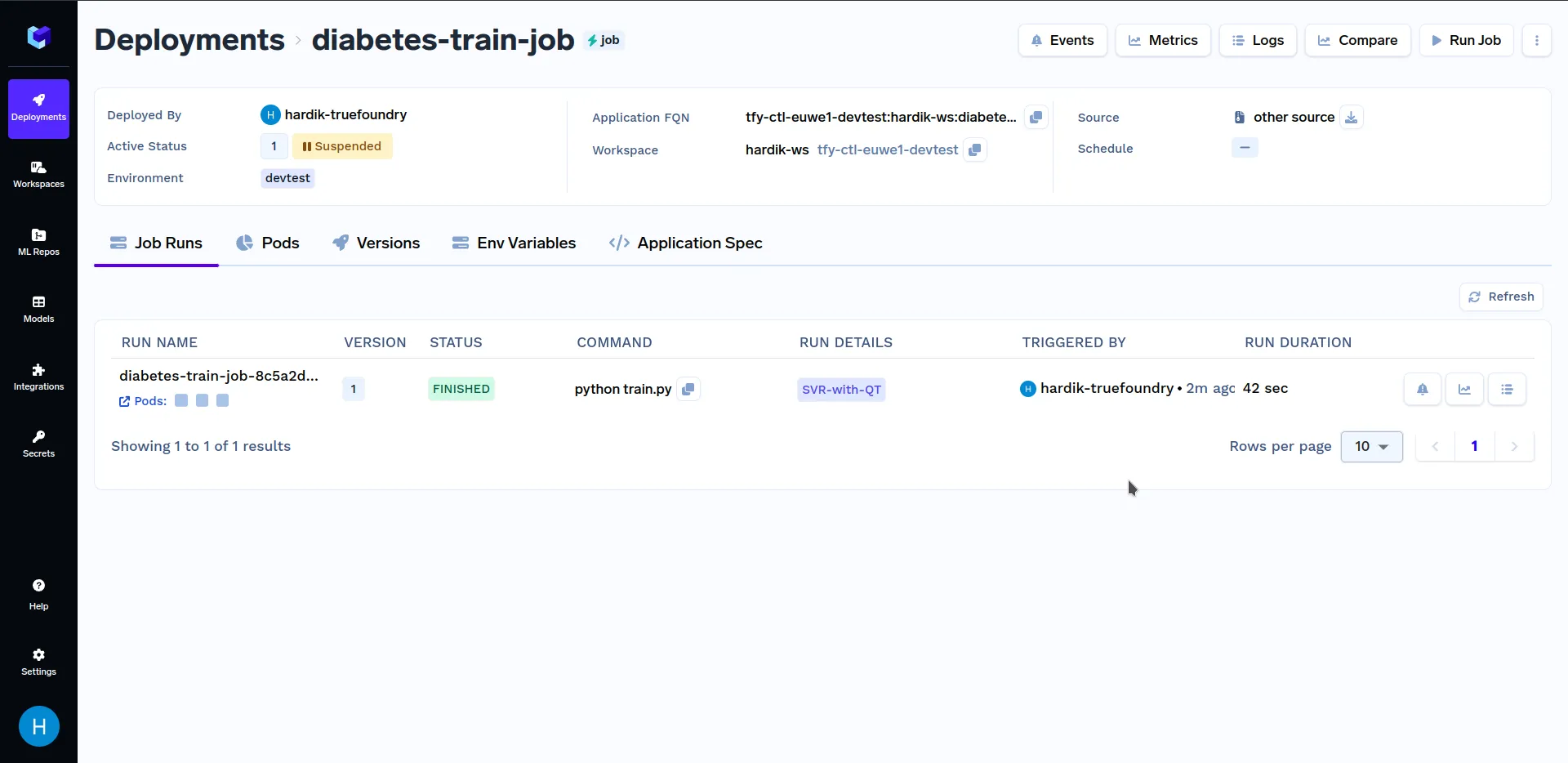
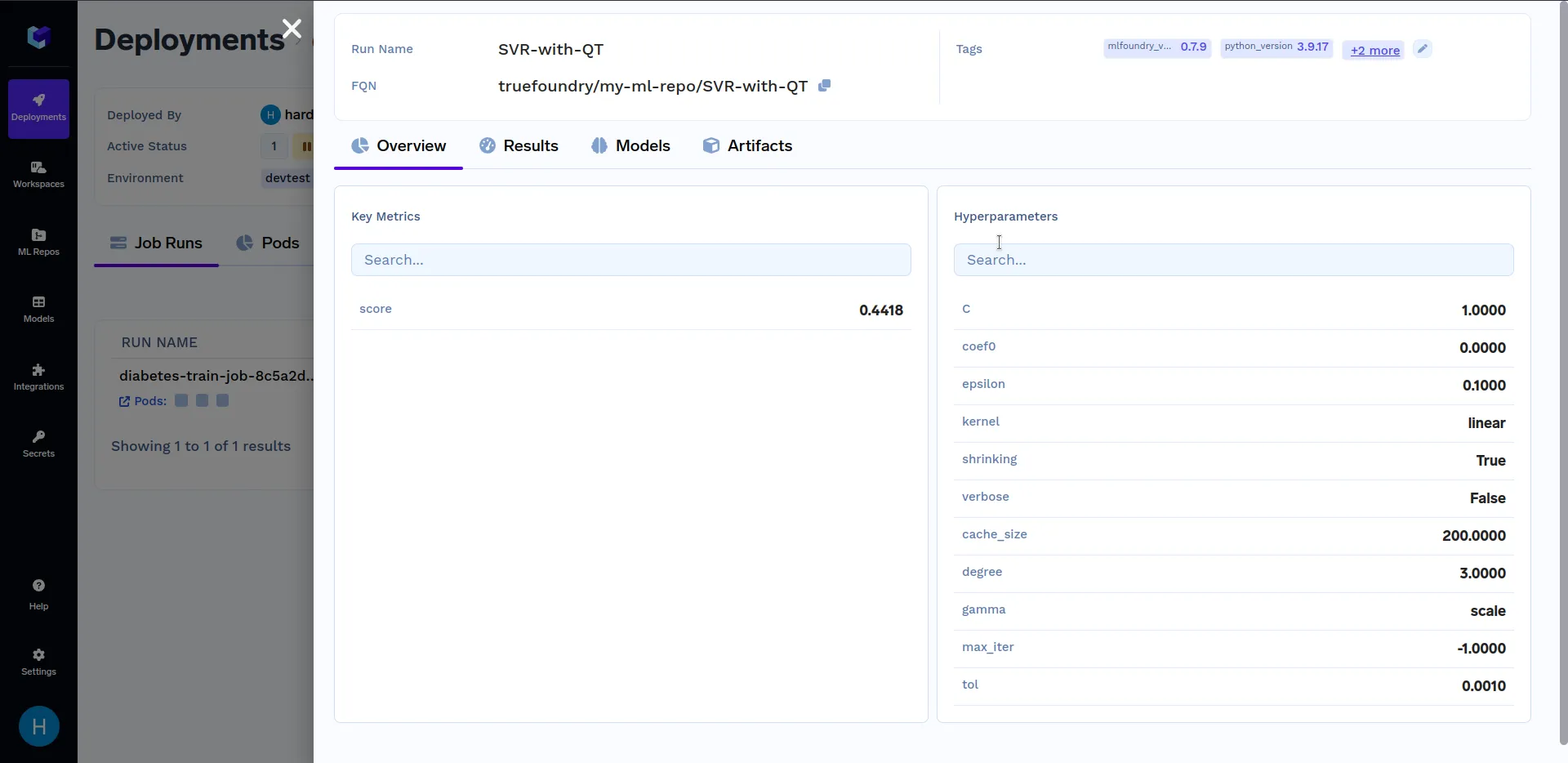
Em "Detalhes da Execução", clique em SVR-with-QT para ver as métricas chave e os hiperparâmetros que foram registados no train.py ficheiro. Deve ser semelhante a isto:
Imagine que tem tarefas de processamento de dados em larga escala ou processamento em lote, onde executar uma única tarefa com diferentes configurações é essencial não só para otimizar o seu fluxo de trabalho, mas também para garantir a consistência na execução das tarefas. Nesses casos, uma tarefa parametrizada será muito útil.
Uma Tarefa Parametrizada é um tipo de tarefa que lhe permite criar múltiplas instâncias (pods) com diferentes parâmetros ou entradas. O objetivo principal de uma Tarefa Parametrizada é proporcionar flexibilidade na execução da tarefa, personalizando o seu comportamento para diferentes cenários.
Por exemplo, uma tarefa com o comando python main.py --n_quantiles {{n_quantiles}} é uma tarefa parametrizada pois recebe n_quantiles como entrada antes da execução. Podemos simplificar a tarefa implementada acima usando parâmetros.
Para analisar os argumentos da linha de comando, usaremos o argparse módulo. O código seguinte mostra o código atualizado para o train.py e deploy.py arquivos, onde os valores padrão de kernel e n_quantiles são linear e 100 respectivamente:
train.py
import os, argparse
def train(kernel, n_quantiles):
...
def log_model(regressor, model, X_test, y_test, ml_repo):
...
parser = argparse.ArgumentParser()
parser.add_argument("--kernel", default="linear", type=str)
parser.add_argument("--n_quantiles", default=100, type=int)
args = parser.parse_args()
regressor, model, X_test, y_test = train(kernel=args.kernel, n_quantiles=args.n_quantiles)
log_model(regressor, model, X_test, y_test, ml_repo=os.environ.get("ML_REPO_NAME"))
deploy.py
import argparse
from servicefoundry import Build, Job, PythonBuild, Param, LocalSource
parser = argparse.ArgumentParser()
parser.add_argument("--workspace_fqn", type=str, required=True)
parser.add_argument("--ml_repo", type=str, required=True)
args = parser.parse_args()
cmd = "python train.py --kernel {{kernel}} --n_quantiles {{n_quantiles}}"
# Definindo as especificações do job
# Apenas o comando muda no atributo 'image'
job = Job(
...
image=Build(build_spec=PythonBuild(command=cmd, ...), ...),
params=[
Param(name="n_quantiles", default='100'),
Param(name="kernel", default='linear', description="svm kernel"),
],
env={ "ML_REPO_NAME": args.ml_repo }
)
deployment = job.deploy(workspace_fqn=args.workspace_fqn)
NOTA: Certifique-se de substituir "YOUR ML REPO NAME" pelo nome do seu Repositório ML e "YOUR WORKSPACE FQN HERE" pelo FQN do seu workspace no comando abaixo.
Agora execute o seguinte comando para implantar o job parametrizado:
python deploy.py --workspace_fqn "YOUR WORKSPACE FQN HERE" --ml_repo "YOUR ML REPO NAME"
Alternativamente, você pode executar diretamente do nosso repositório do Github.
git clone https://github.com/truefoundry/truefoundry-examples.git
cd training-job-example
python deploy.py --workspace_fqn "YOUR WORKSPACE FQN HERE" --ml_repo "YOUR ML REPO NAME"
A Versão 2 do Job será criada após a conclusão da implantação. Depois que o job de treinamento tiver concluído a implantação, o próximo passo é acionar este job.
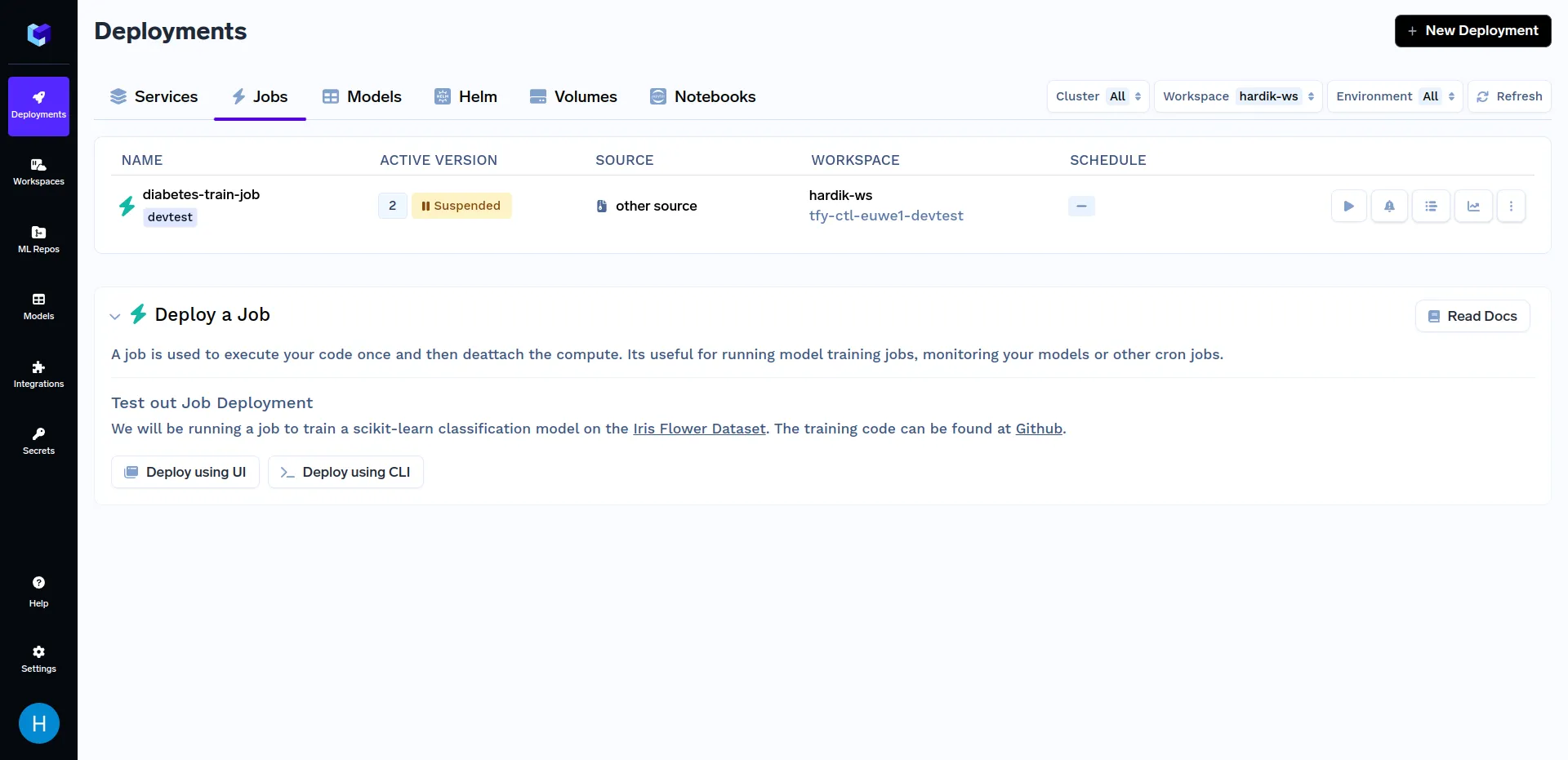
Clique em "diabetes-train-job", e clique em "Run Job" para configurar o job antes de acionar. Agora você pode alterar os n_quantiles e kernel parâmetros. Deve ser semelhante a isto:
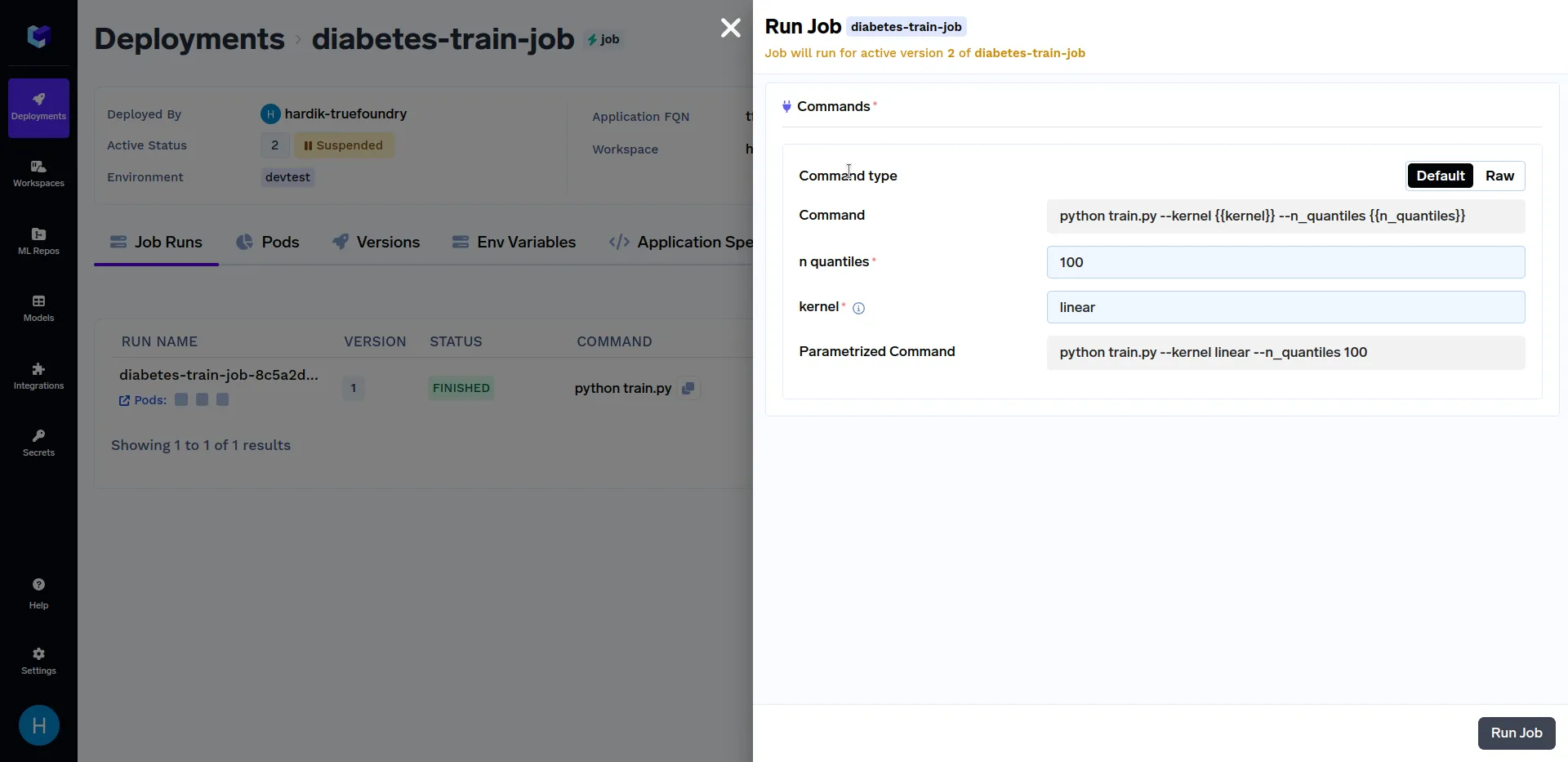
Tente acionar execuções do job com valores diferentes para o kernel parâmetro como linear, sigmoid, poly e rbf. Da mesma forma, você pode usar diferentes valores de n_quantiles parâmetros como 50, 80, 100, etc. Várias execuções de job devem ser semelhantes a isto:
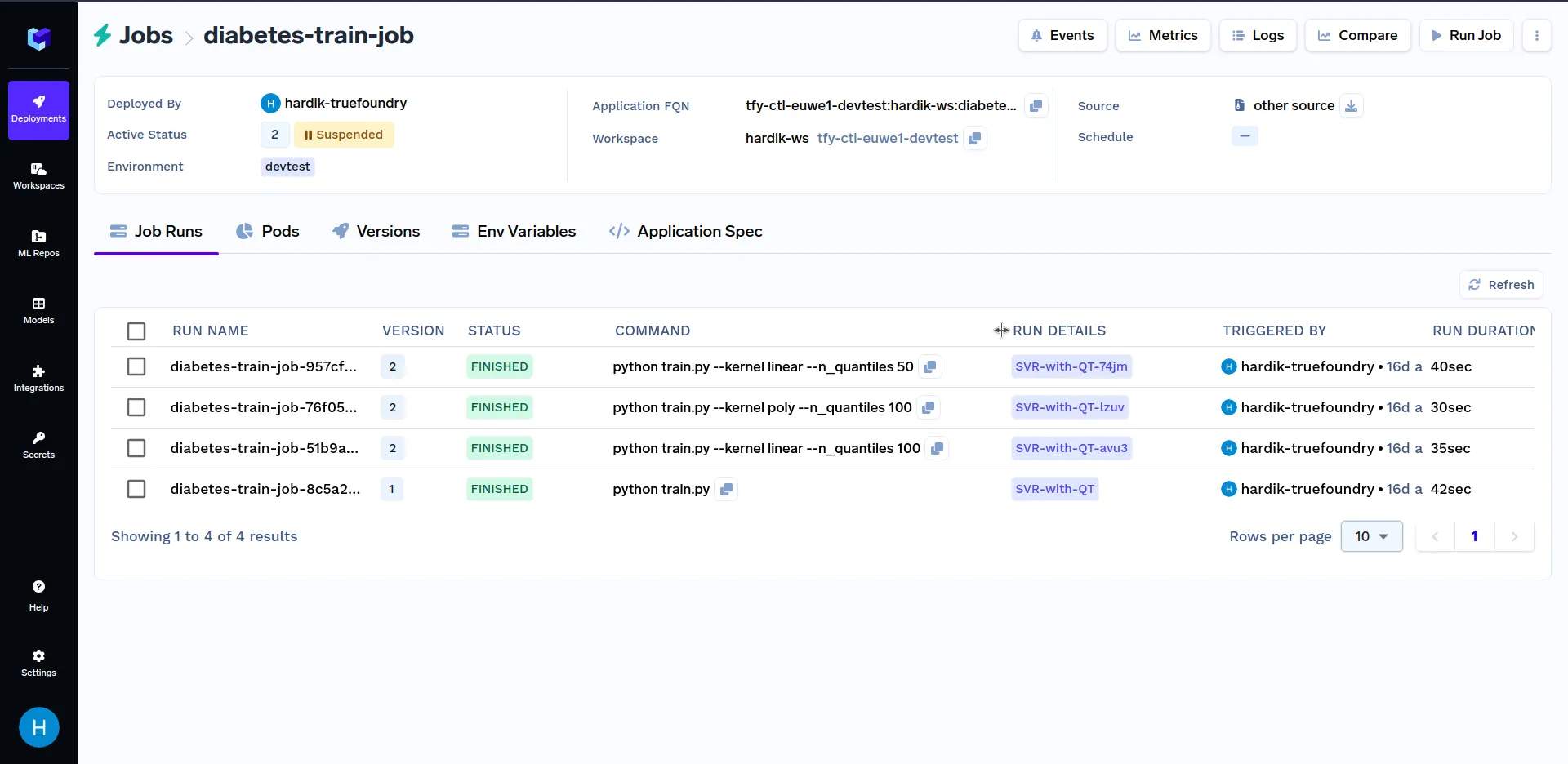
Você pode comparar as métricas de diferentes execuções de job no painel clicando no botão de comparação na seção superior direita do painel, conforme mostrado abaixo:
Você pode ler mais sobre Implantação de Job Parametrizado aqui:
Até agora, vimos apenas o acionamento de execuções de job a partir do TrueFoundry Dashboard. Agora é possível que acionar um trabalho não seja sempre desejável via UI, então vamos agora abordar como acionar um trabalho programaticamente via Python SDK.
Você pode acionar seu trabalho programaticamente usando o trigger_job função, conforme mostrado abaixo:
from servicefoundry import Job, trigger_job
# Configurar uma Implantação de Trabalho
job = Job(...)
# Implantar um Trabalho
job_deployment = job.deploy(workspace_fqn="YOUR WORKSPACE FQN")
# Acionar/Executar um Trabalho
trigger_job(
application_fqn=job_deployment.application_fqn,
params={"n_quantiles":"80"}
)
Também é possível obter o application_fqn facilmente do painel de controle, indo para Implantações --> Tarefas --> Procure o nome da sua tarefa no seu espaço de trabalho (aqui diabetes-train-job).
Abaixo está outro exemplo de como acionar uma tarefa programaticamente. Primeiramente, substitua YOUR_APPLICATION_FQN pelo Application FQN da tarefa implantada acima no código mostrado abaixo. O Application FQN para uma aplicação é destacado abaixo:
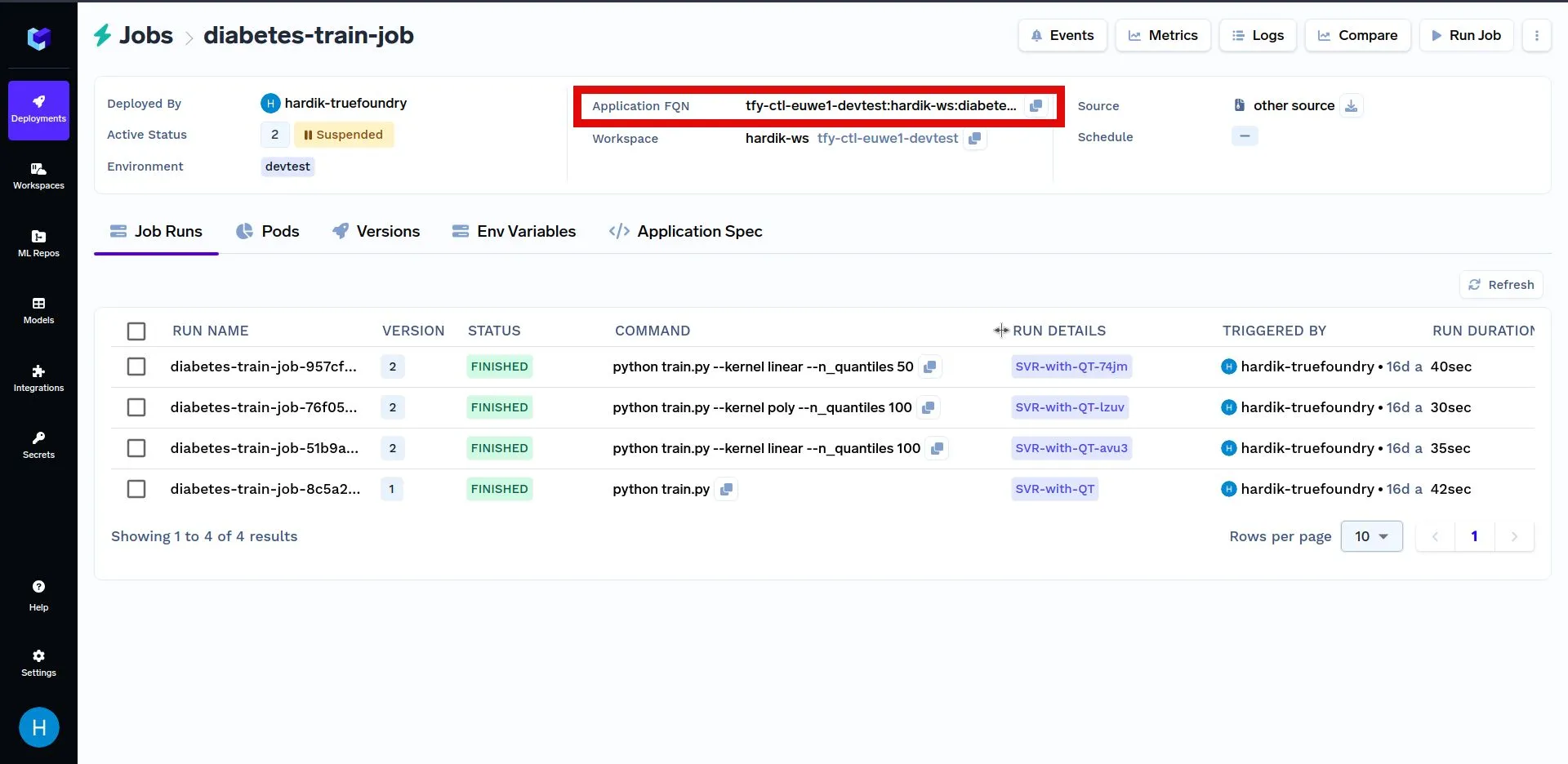
No código mostrado abaixo, estamos escolhendo aleatoriamente um valor para os parâmetros do modelo e acionando uma execução de tarefa usando esses parâmetros. Depois disso, procuramos nas execuções de tarefa para encontrar a execução com a pontuação máxima pontuação. A execução da tarefa com a pontuação máxima indica uma escolha mais otimizada dos parâmetros do modelo.
import random
import mlfoundry as mlf
from servicefoundry import trigger_job
# Encontre o job implantado, substitua pelo fqn do aplicativo do seu job
application_fqn = "YOUR_APPLICATION_FQN"
# Gerar parâmetros aleatoriamente
n_quantiles = random.randint(50, 100)
kernel_values = ['linear', 'sigmoid', 'poly', 'rbf']
kernel = kernel_values[random.randrange(0, len(kernel_values))]
# Acionar/Executar um Job
triggered_job = trigger_job(
application_fqn=application_fqn,
params={
"n_quantiles": str(n_quantiles),
"kernel": kernel
}
)
print(f'Job acionado com n_quantiles={n_quantiles} e kernel={kernel} e nome como', triggered_job.jobRunName)
client = mlf.get_client()
ml_repo_name = "YOUR ML REPO NAME HERE"
runs = client.search_runs(ml_repo=ml_repo_name)
max_score = 0
for run in runs:
metrics = run.get_metrics()
print(f'All Metrics for run with name as {run.run_name}":', metrics)
if 'score' in metrics:
max_score = max(max_score, metrics['score'][0].value)
print("Model Max Score: ", max_score)
NOTA: Certifique-se de substituir "YOUR ML REPO NAME HERE" pelo nome do seu Repositório ML e "YOUR WORKSPACE FQN HERE" pelo FQN do seu workspace no comando abaixo.
Você pode ler mais sobre Acionamento de Jobs aqui:
Você pode comparar as métricas de diferentes execuções de jobs programaticamente utilizando a mlfoundry.search_runs função, conforme descrito no código a seguir:
import mlfoundry as mlf
client = mlf.get_client()
ml_repo_name = "YOUR-ML-REPO-NAME"
# Retorna todas as execuções
runs = client.search_runs(ml_repo=ml_repo_name)
# Pesquisar o subconjunto de execuções com métrica de precisão registrada > 0.7
filter_string = "metrics.score > 0.7"
runs = client.search_runs(ml_repo=ml_repo_name, filter_string=filter_string)
Saiba mais sobre a search_runs função aqui:
Imagine lidar com modelos em larga escala que possuem milhões ou bilhões de parâmetros. Treinar tais modelos usando CPUs tradicionais seria muito demorado e pode até ser inviável devido a restrições de memória.
Por exemplo, treinar um modelo CNN baseado no conjunto de dados CIFAR-10 em um ambiente de CPU com 10 épocas leva 36 minutos e 31 segundos, mas o mesmo modelo, quando treinado em um ambiente de GPU (NVIDIA K80), levou apenas 4 minutos e 6 segundos. Isso representa uma melhoria de um fator de 9x (Consulte aqui)
GPUs desempenham um papel vital no treinamento de modelos em larga escala. Elas fornecem a largura de banda de memória necessária e capacidades de processamento paralelo para lidar com modelos de grande porte e arquiteturas complexas de forma eficiente. Agora, vamos abordar como usar uma GPU em uma Tarefa.
Usar uma GPU no exemplo acima requer pequenas modificações na forma como uma tarefa é configurada no deploy.py arquivo. O código abaixo mostra a configuração atualizada de Job para utilização de GPU e alocação personalizada de recursos de CPU e Memória:
deploy.py
from servicefoundry import Job, NodeSelector, GPUType, Resources
job = Job(
resources=
# Configurar GPU
gpu_count=1,
node=NodeSelector(gpu_type=GPUType.T4)
# (Opcional) Configurar Recursos de CPU e Memória
cpu_request=0.2,
cpu_limit=0.5,
memory_request=128,
memory_limit=512,
),
...
)
Nota: O restante do código permanece inalterado
Até agora, vimos várias opções de implantação de tarefas, como imagem, parâmetros, e ambiente. Existem várias maneiras de personalizar sua tarefa com opções avançadas. Algumas delas são as seguintes:
Agora que discutimos as Tarefas que podem ser acionadas manualmente, seja através do Painel TrueFoundry ou do SDK Python. Mas e se quisermos que uma Tarefa seja executada em um agendamento (como um cron job)?
Um cron job executa a tarefa definida em um agendamento repetitivo. Isso pode ser útil para retreinar um modelo periodicamente, gerar relatórios e muito mais. Podemos implementar tais tarefas alterando seu gatilho tipo da seguinte forma:
from servicefoundry import Job, Schedule
job = Job(
trigger=Schedule(
schedule="0 8 1 * *",
concurrency_policy="Forbid" # Valores: ["Forbid","Allow", "Replace"]
),
concurrency_limit=3,
...
)
Para cron jobs, é possível que a execução anterior da tarefa não tenha sido concluída enquanto já é hora de a tarefa ser executada novamente devido ao horário agendado. Nesses casos, podemos definir concurrency_policy da seguinte forma:
Proibir: Este é o padrão. Não permitir execuções simultâneas.Permitir: Permitir que os trabalhos sejam executados simultaneamente. Opcionalmente, o número máximo de trabalhos a serem executados simultaneamente pode ser alterado definindo concurrency_limit para o valor desejado. Substituir: Substituir o trabalho atual pelo novo.A concorrência não se aplica a trabalhos acionados manualmente. Nesse caso, é sempre criada uma nova execução de trabalho.
O estado do trabalho pode ser de 3 tipos: FINALIZADO, TERMINADO, e FALHADO. Um trabalho pode ser configurado para tentar novamente várias vezes em caso de falha.
Uma Tarefa é marcada como FALHA se não terminar com sucesso mesmo após o número configurado de tentativas. Tentativas podem ser configuradas para uma tarefa da seguinte forma:
from servicefoundry import Job
job = Job(
retries=6, # default = 1
...
)
Em alguns casos de uso, pode ser necessário especificar o tempo máximo que você deseja que uma tarefa continue a ser executada.
Usando timeout, você pode especificar (em segundos) o tempo máximo para uma tarefa ser executada, independentemente de ter falhado ou não. Isso terá precedência sobre o retries Limite. Por padrão, isso é definido como 1000 segundos.
Por exemplo, se você definir otentativas para 6 e um tempo limite de 480 segundos, o trabalho será encerrado após 480 segundos, independentemente de quantas vezes ele tentou ser executado.
from servicefoundry import Job
job = Job(
timeout=480,
...
)
Além das Opções de Implantação de Trabalho discutidas neste blog, ainda existem algumas que não abordaremos neste blog, como:
.... e mais alguns. Pode consultar a nossa Documentação disponível abaixo para saber as respostas às perguntas acima :)
O nosso repositório público truefoundry-examples contém o código-fonte do job deste blog e também inclui vários exemplos, incluindo Finetuning de LLM, Introdução aos Notebooks, Exemplos de Ponta a Ponta oferecendo uma visão mais abrangente das funcionalidades oferecidas pela Plataforma TrueFoundry.
Em resumo, o Job da TrueFoundry oferece uma estrutura poderosa para gerir e executar tarefas de treino de forma escalável, tolerante a falhas e eficiente em termos de recursos.
Eles permitem distribuir e controlar a execução de cargas de trabalho de machine learning, monitorar o progresso delas e garantir que seus modelos de treinamento sejam treinados de forma eficaz e confiável, o que os torna ideais para executar tarefas únicas ou sob demanda.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




