












Gateway de IA e Plataforma de Implantação Agente Prontos para Empresas — Seguros, Escaláveis, Governados.
No local, VPC, híbrido ou nuvem pública


Governe, Implante, Escale e Rastreie a IA Agente em Uma Plataforma Unificada
.svg)
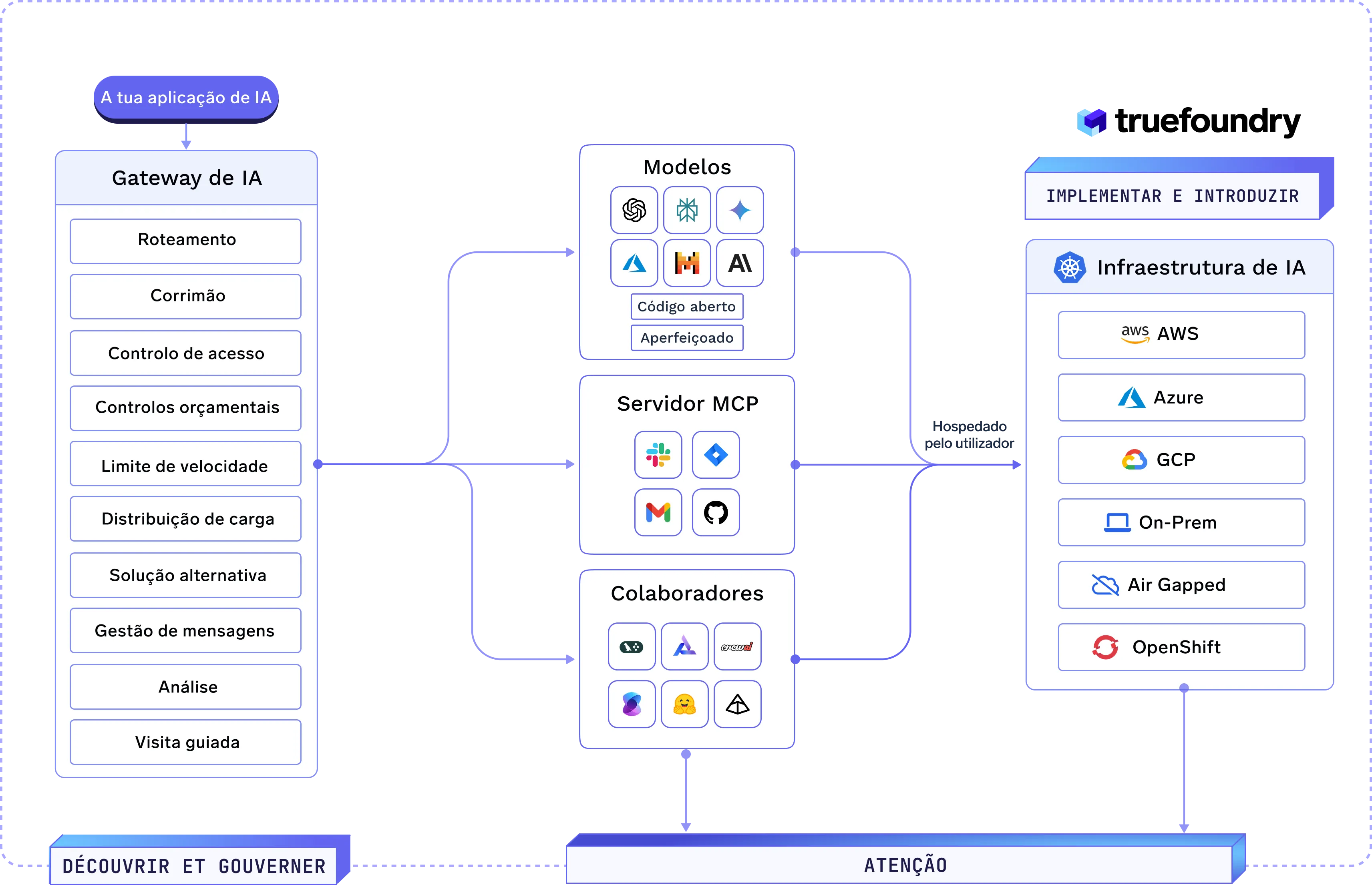
Orquestre a IA Agente com o Gateway de IA
Habilite o raciocínio inteligente em várias etapas, o uso de ferramentas e a memória com controle total e visibilidade em todos os seus agentes de IA e fluxos de trabalho.
Gateway de IA
Gerencie a memória do agente, a orquestração de ferramentas e o planejamento de ações através de um protocolo centralizado que suporta fluxos de trabalho complexos e sensíveis ao contexto.

MCP & Registro de Agentes
Mantenha um registro estruturado e detectável de ferramentas e APIs acessíveis a agentes, completo com validação de esquema e controle de acesso.
.webp)
Gestão do Ciclo de Vida de Prompts
Controle a versão, gerencie e monitore prompts para garantir um comportamento repetível e de alta qualidade em todos os agentes e casos de uso.

Implante e Escale Qualquer Carga de Trabalho de IA Agente
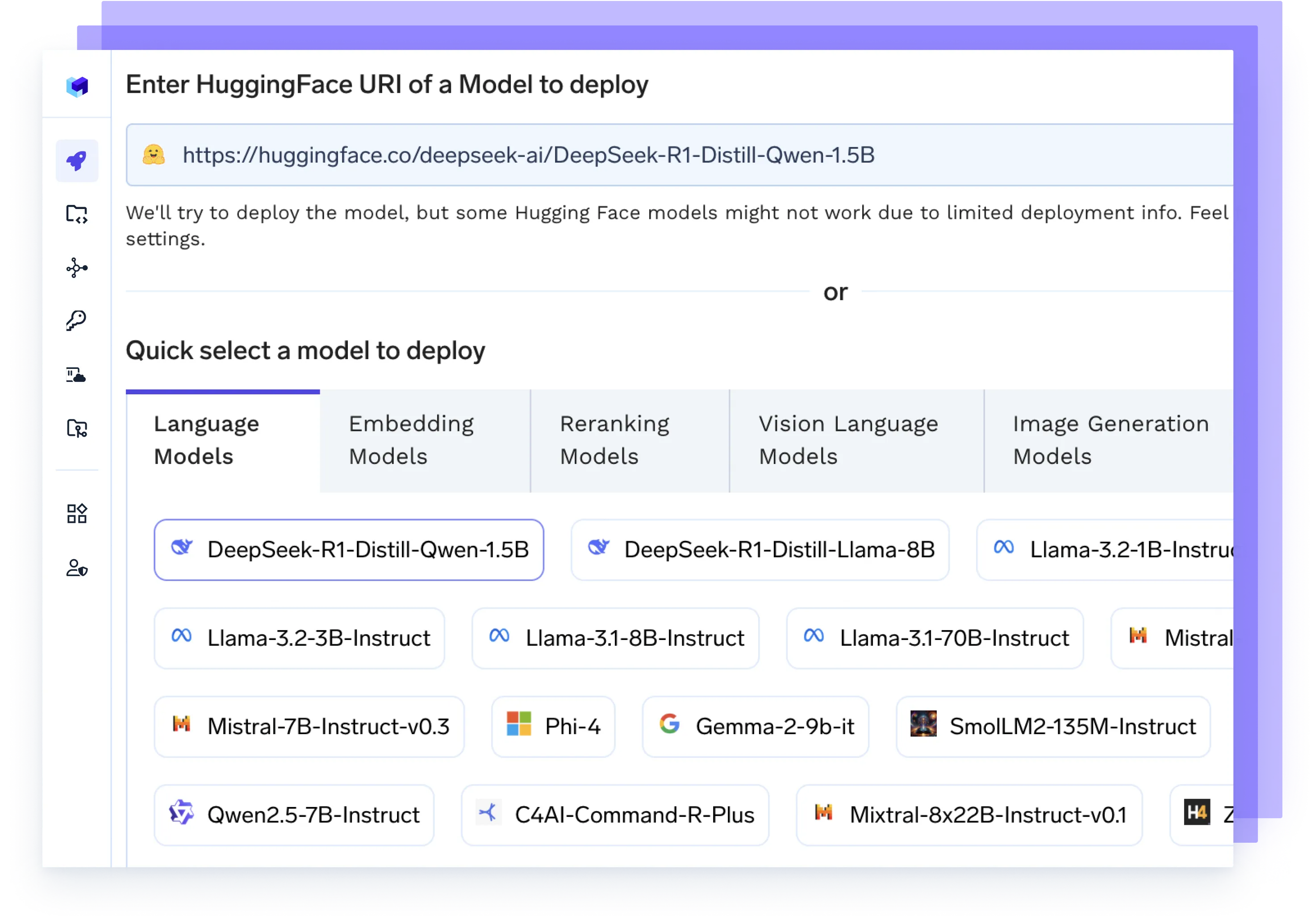
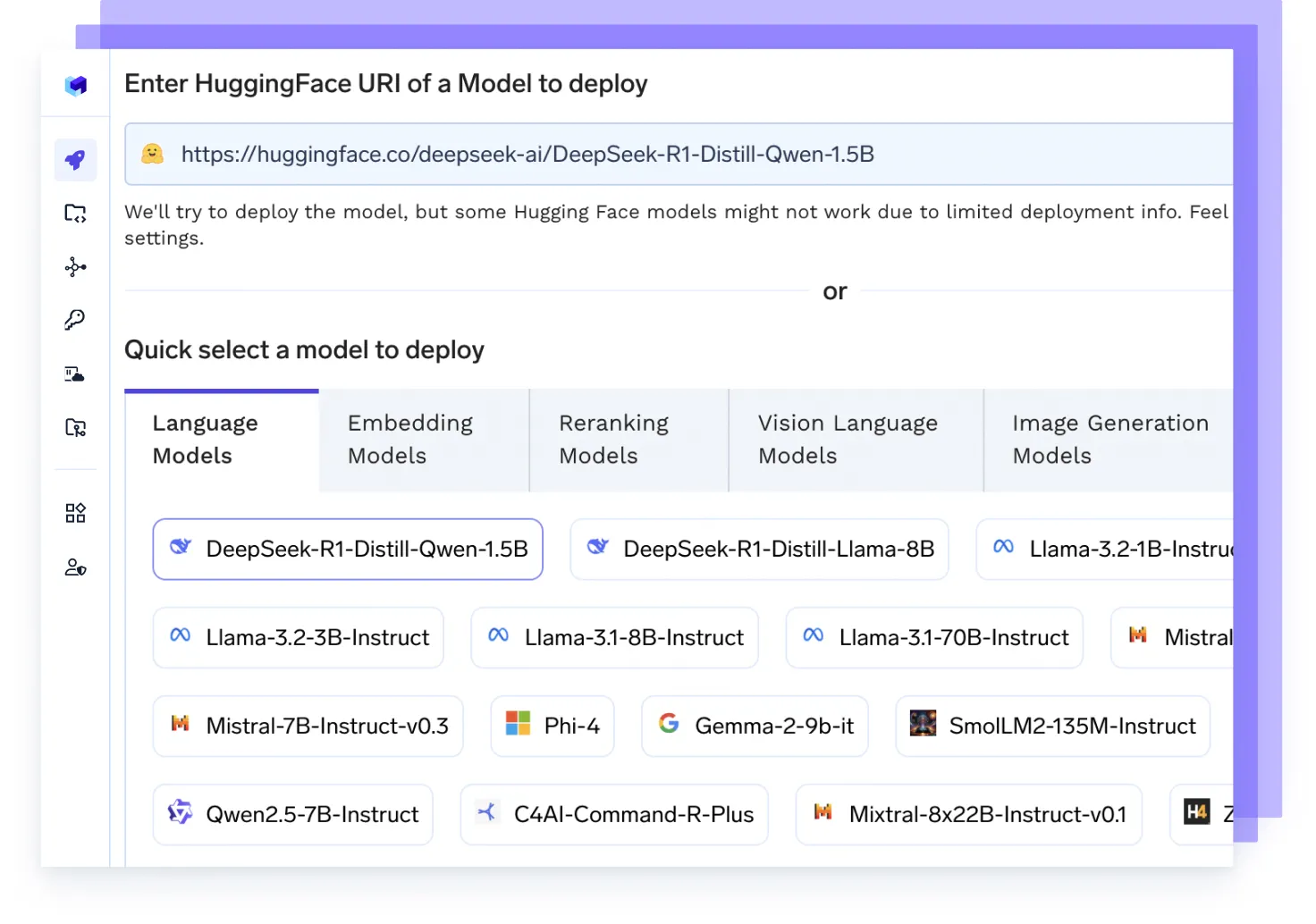
Hospede qualquer Modelo de IA
Execute qualquer LLM, modelo de embedding ou modelos personalizados usando backends de alto desempenho como vLLM, TGI ou Triton — otimizados para velocidade e escala.
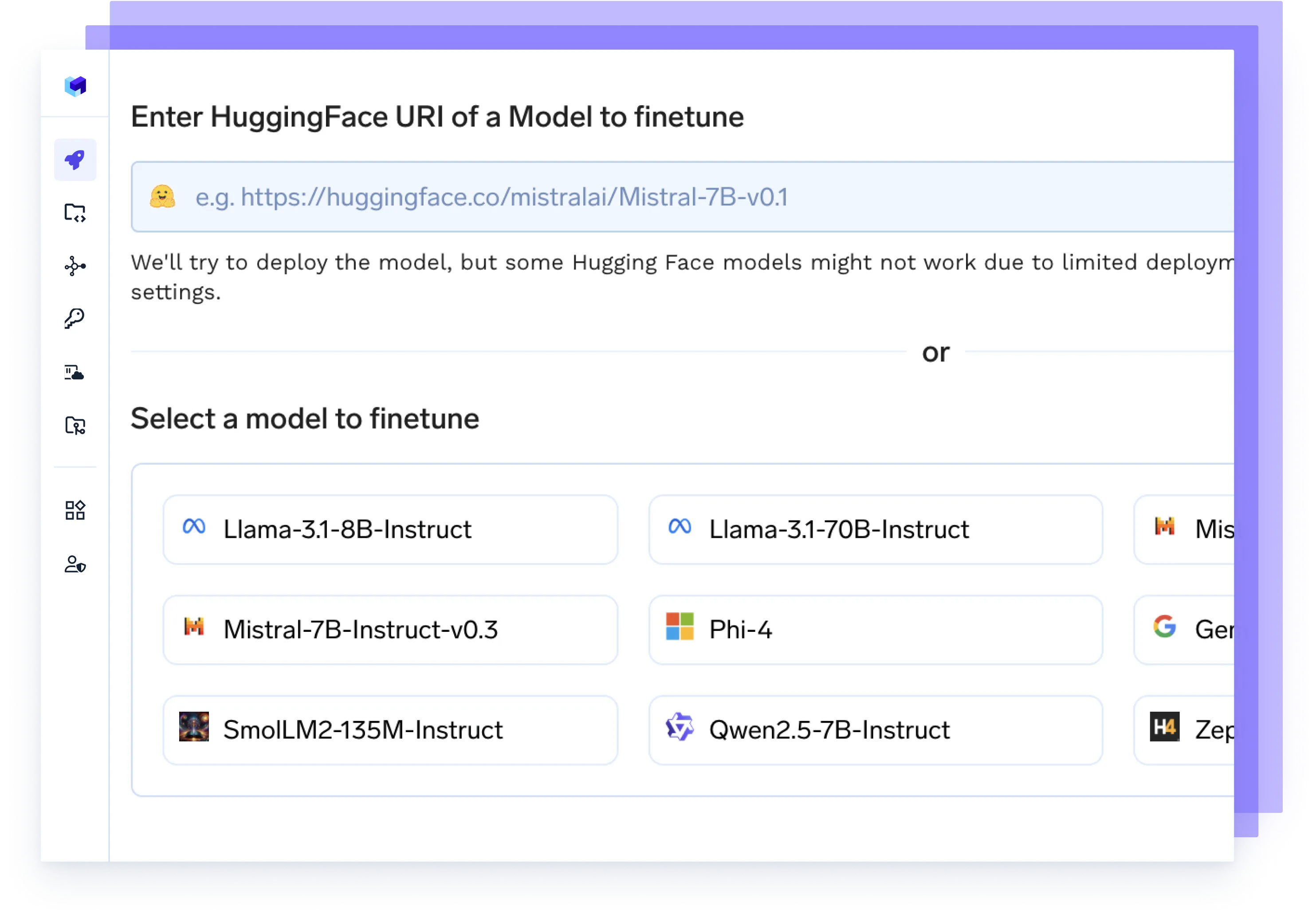
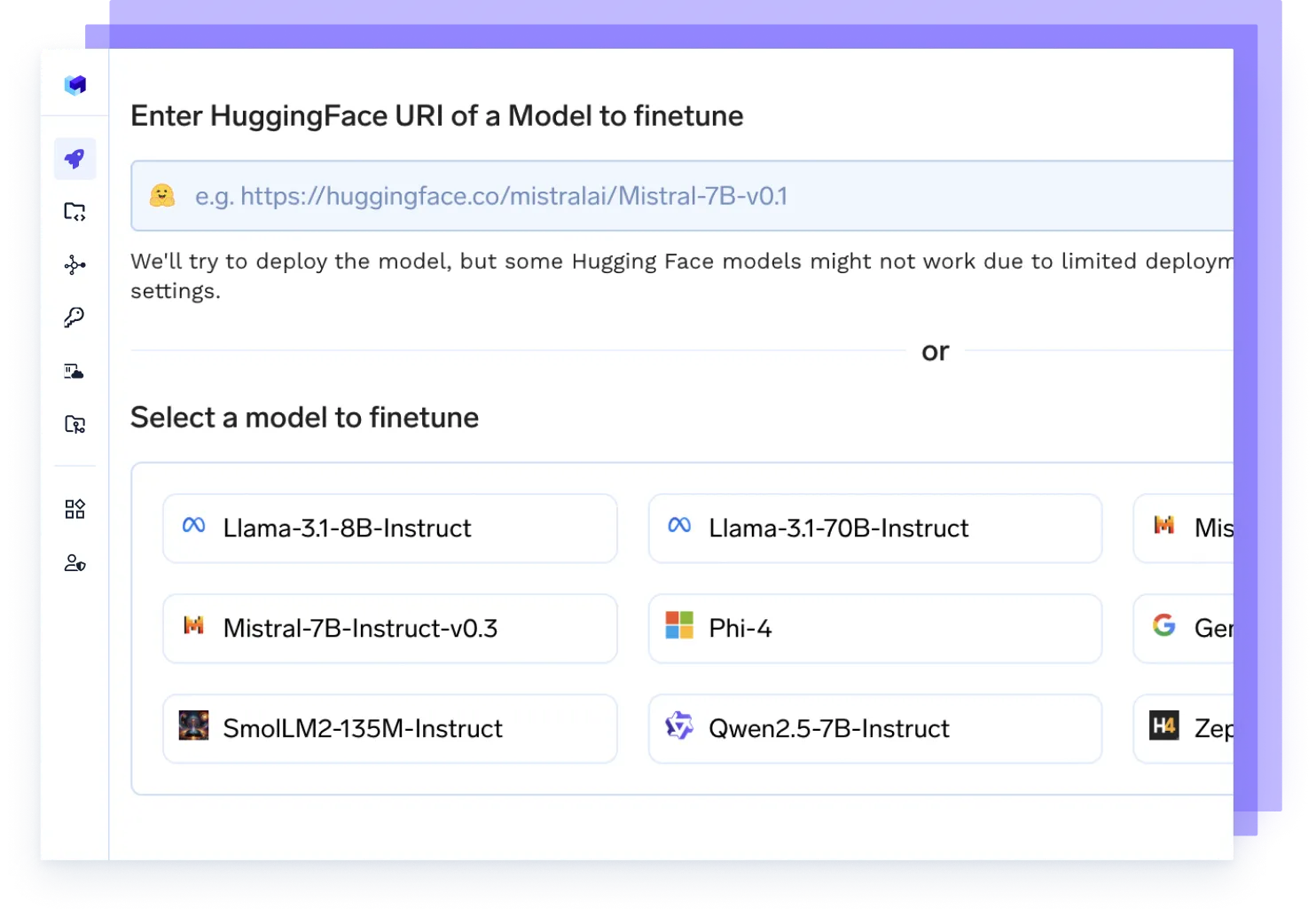
Faça o Fine-tuning de Qualquer Modelo
Inicie trabalhos de fine-tuning nos seus dados, acompanhe experimentos e implante checkpoints atualizados diretamente em produção — tudo em um único fluxo.
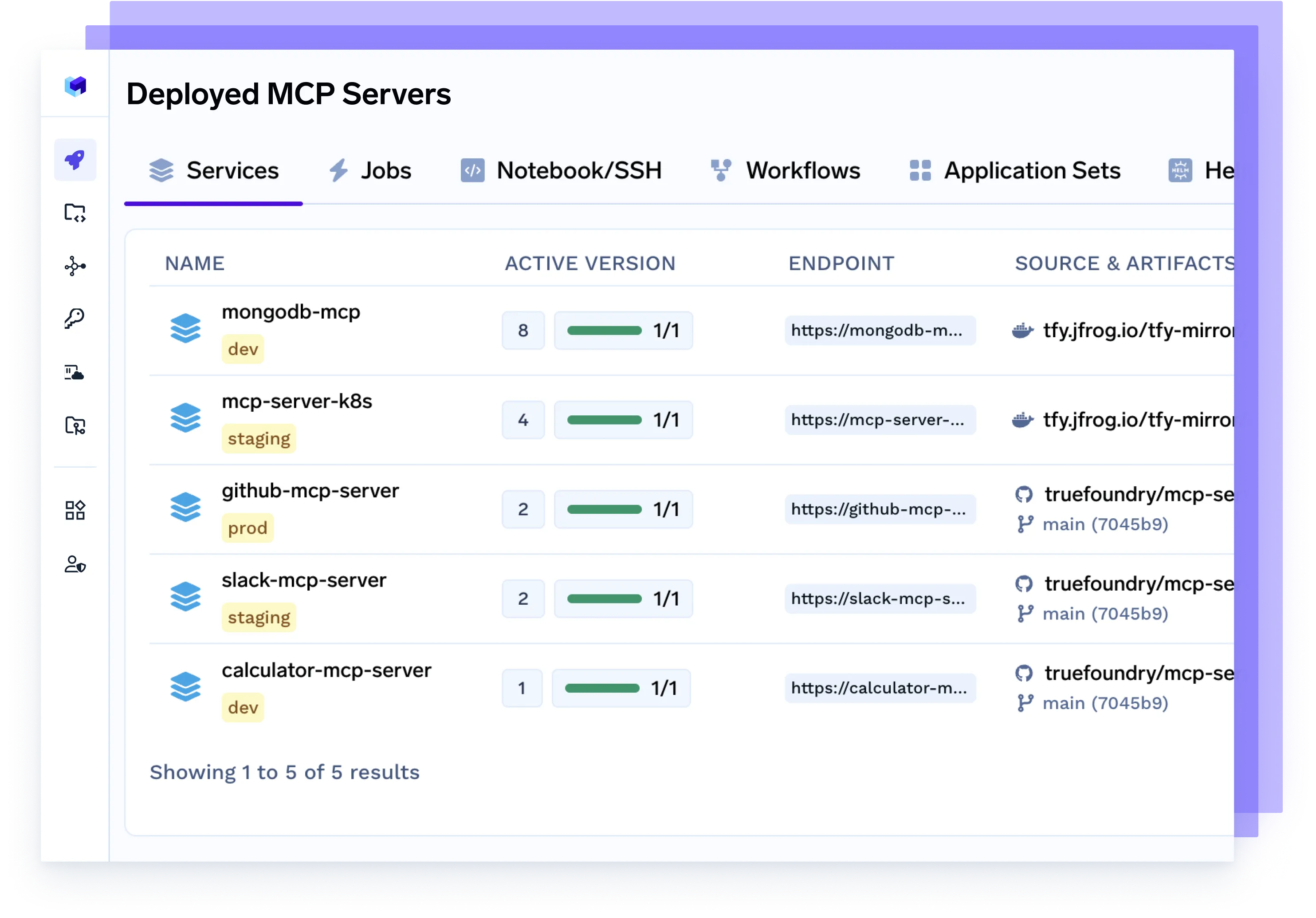
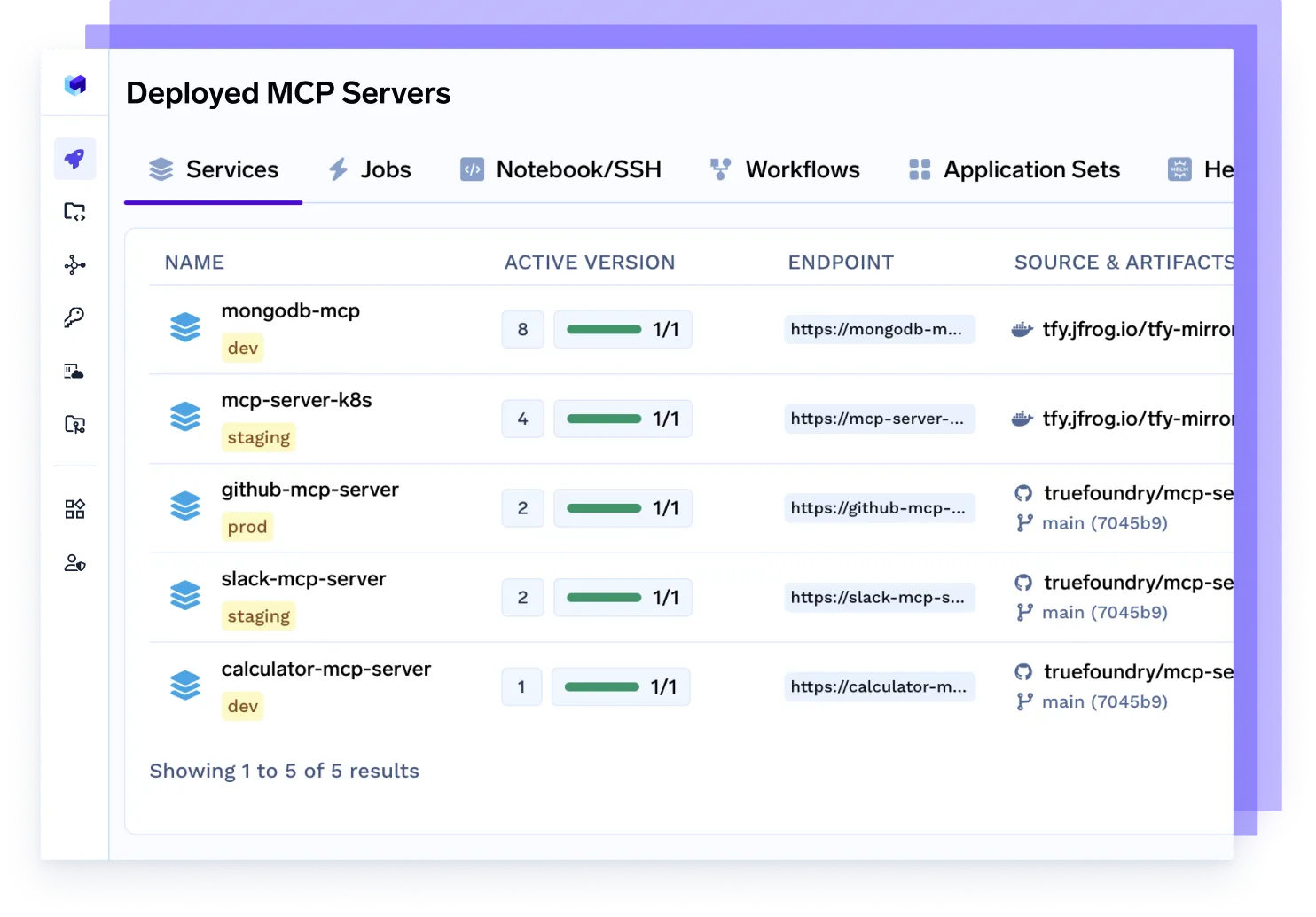
Implante o Servidor MCP
Provisione servidores dedicados do Protocolo de Controle de Modelo (MCP) para gerenciar o tráfego de agentes, escalar o acesso a modelos, impor limites de taxa e isolar cargas de trabalho por equipe ou projeto.
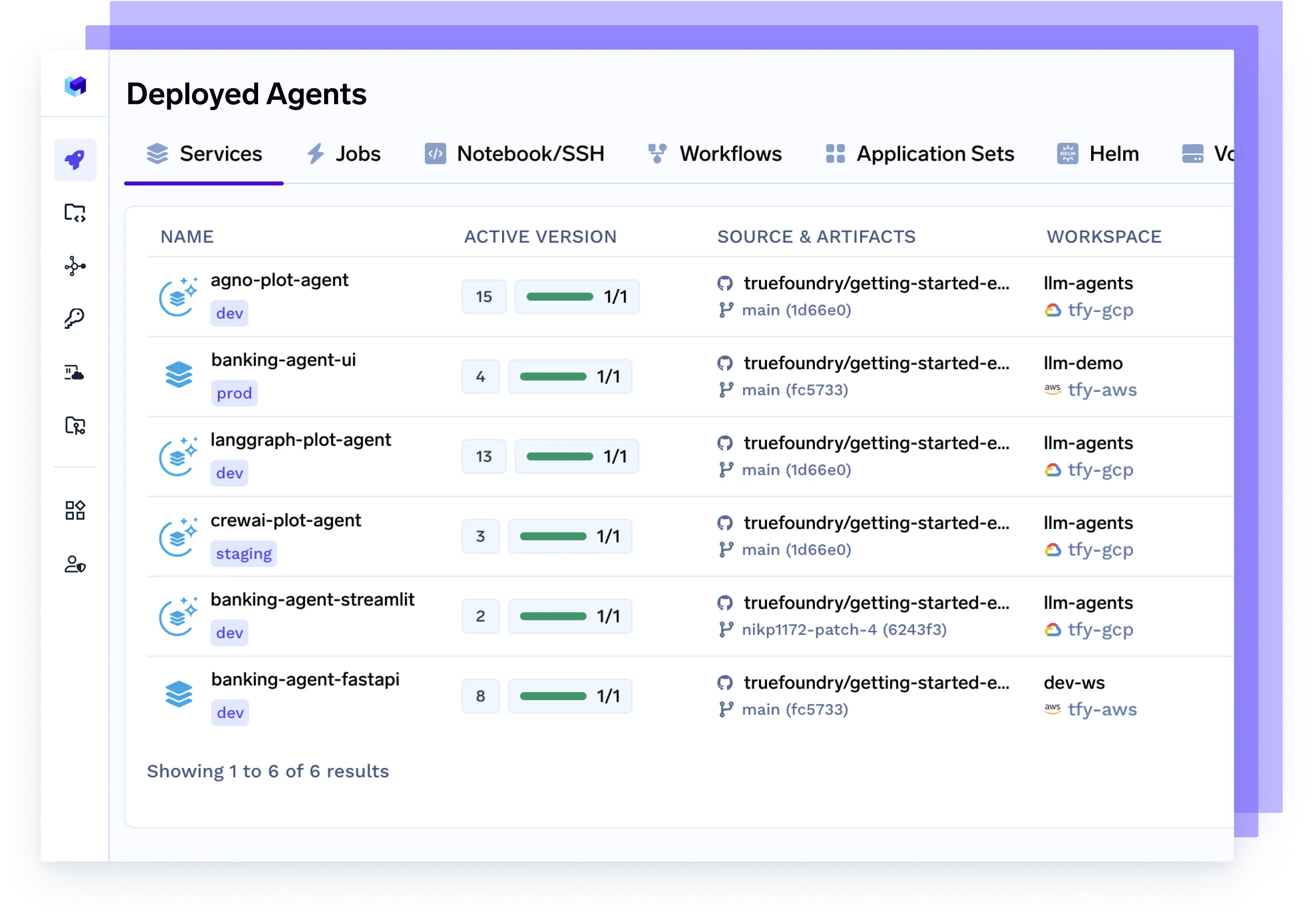
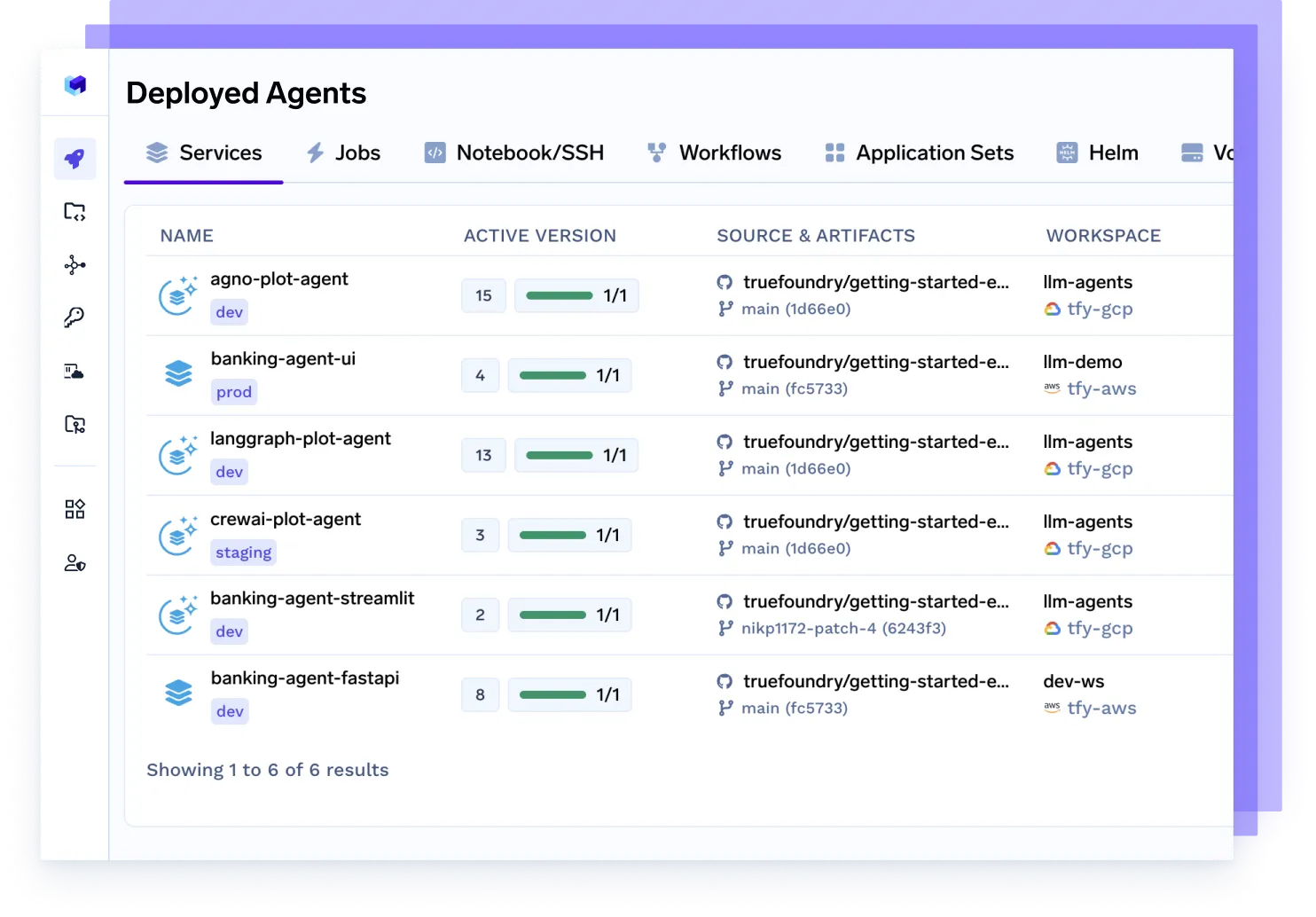
Implante Qualquer Agente, Qualquer Framework
Sirva agentes construídos com Langgraph, CrewAI, AutoGen ou sua própria orquestração de forma contínua — totalmente conteinerizados, observáveis e prontos para produção.
VPC, on-premise, com isolamento de rede (air-gapped) ou em várias nuvens.
Nenhum dado sai do seu domínio. Desfrute de soberania completa, isolamento e conformidade de nível empresarial onde quer que o TrueFoundry seja executado.


.avif)
Pronto para Empresas
Implante um gateway de IA seguro que mantém seus dados e modelos dentro da sua infraestrutura em nuvem / on-premise.


Conformidade e Segurança
Padrões SOC 2, HIPAA e GDPR para garantir uma proteção de dados robustaGovernança e Controle de Acesso
SSO + Controle de Acesso Baseado em Função (RBAC) e Registro de AuditoriaSuporte Empresarial e Confiabilidade
Suporte 24/7 com garantia de SLA SLAs de resposta
Observe Agentes e a Infraestrutura Subjacente
Rastreamento agnóstico de framework para tudo, desde a execução de prompts até o desempenho da GPU.
Observabilidade Completa do Agente
Rastreie cada etapa do prompt à execução da ferramenta/modelo com métricas, latência e resultados.
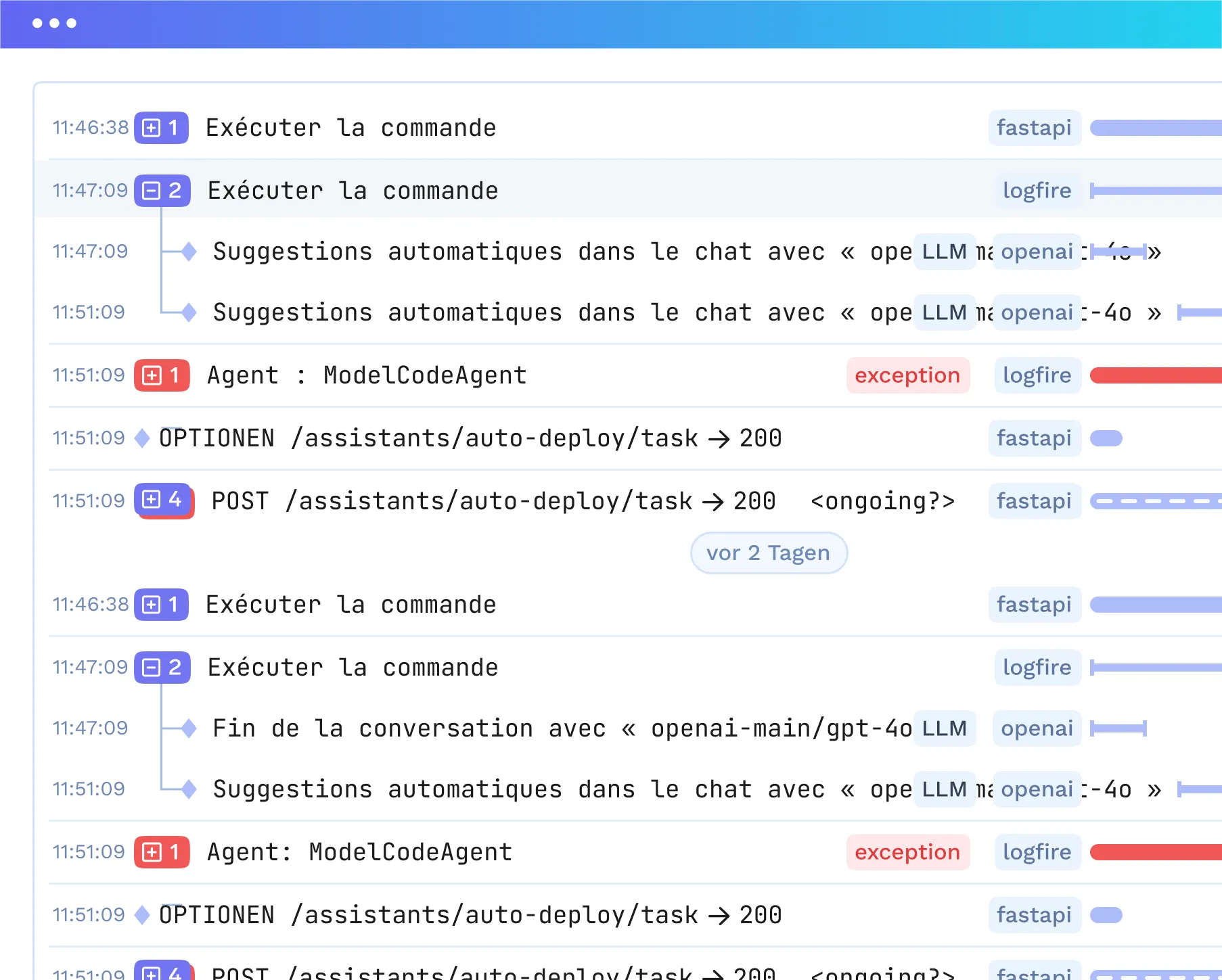
Integração Perfeita com Ferramentas Internas
Compatível com OpenTelemetry; integre-se com Grafana, Datadog, Prometheus ou sua pilha de observabilidade preferida.




Observabilidade da Infraestrutura (GPU, CPU, Cluster)
Monitore o uso de recursos em nuvem/on-premise — incluindo memória da GPU, saúde do nó e comportamento de escalonamento.
Governe e Garanta a Conformidade em toda a IA de Nível Empresarial
Estabeleça confiança e disciplina operacional com controles de acesso robustos, aplicação de políticas e observabilidade full-stack — integrados nativamente desde o primeiro dia.
.webp)
Controle de Acesso Baseado em Função (RBAC) Granular
Controle com precisão quem pode acessar modelos, ambientes ou APIs com base em equipes, funções e atribuições.
.webp)
Registro de Auditoria Imutável
Registre todas as atividades, incluindo uso do modelo, acesso do usuário e alterações de configuração, para garantir total prontidão para auditoria.

Arquitetura Pronta para Conformidade
Construído para atender aos mais altos padrões de segurança e conformidade, incluindo SOC 2, HIPAA e GDPR.
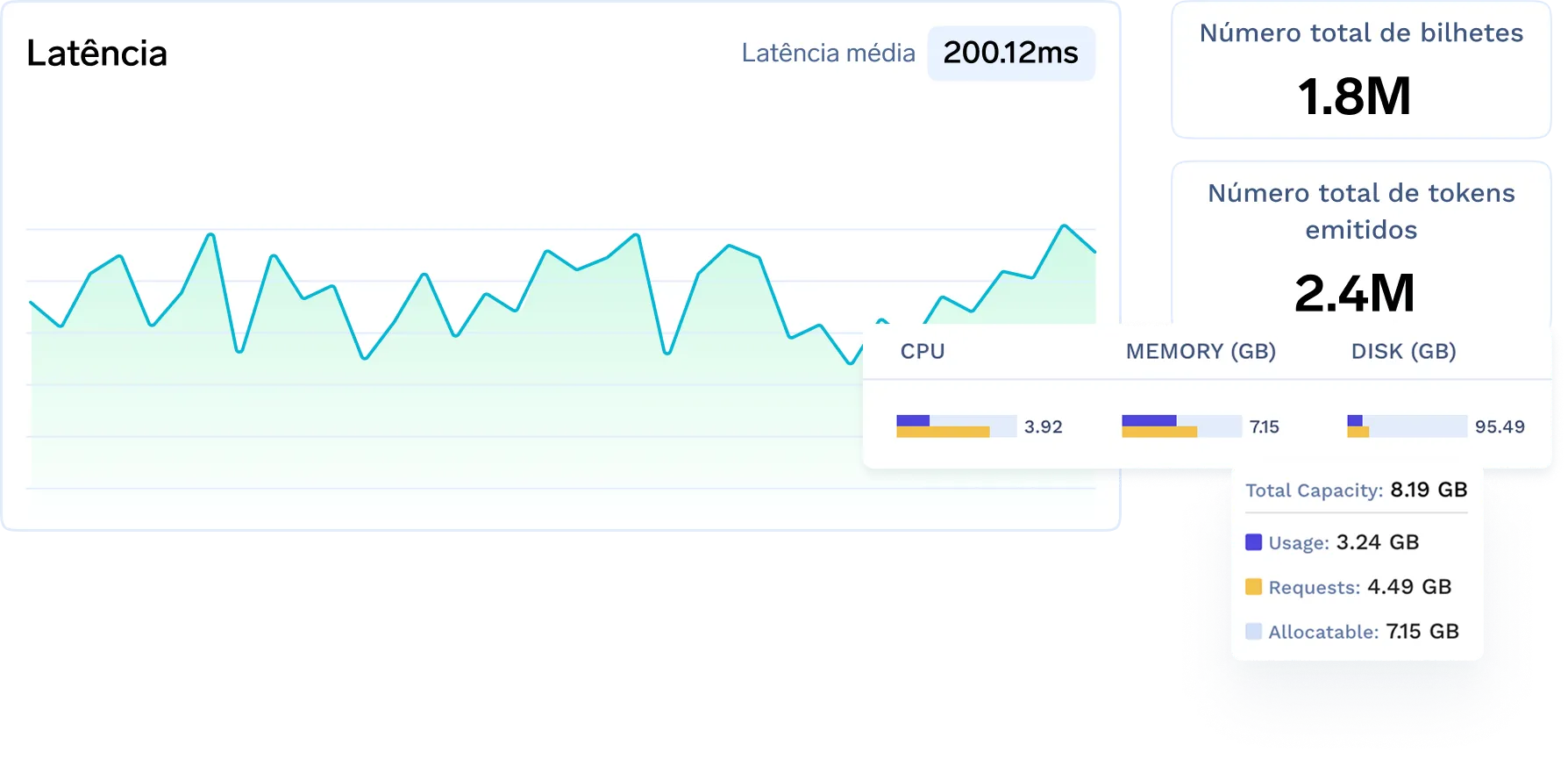
Monitoramento e Alerta Unificados
Acompanhe a latência, o throughput, o uso de tokens, os custos e a utilização da GPU em toda a sua pilha de IA através de painéis centralizados e alertas.

Aplicação de Políticas em Tempo Real
Aplique políticas relacionadas à residência de dados, cotas de uso, limites de taxa e controle de custos dinamicamente enquanto as cargas de trabalho são executadas.
Visionamos uma Infraestrutura de IA Otimizada por IA e Livre de Gerenciamento
Otimização Automatizada de Recursos Sem Sobrecarga Operacional

Orquestração e Autoescalonamento de GPU
Agende e dimensione automaticamente as cargas de trabalho de GPU para atender à demanda, otimizando o desempenho sem superprovisionamento.
Suporte a GPU Fracionária
(MIG e Fatiamento de Tempo)
Permita o compartilhamento econômico de recursos de GPU entre múltiplas cargas de trabalho usando NVIDIA MIG e fatiamento de tempo.
Recurso em Tempo Real
Otimização
Ajuste continuamente as alocações de CPU e memória com base no tráfego real e nas necessidades de computação.
Dimensionamento Automático de Infraestrutura
Detete e corrija infraestruturas superprovisionadas para reduzir o desperdício na nuvem, mantendo os SLAs e o desempenho do modelo.
Resultados Reais na TrueFoundry
Por que as Empresas Escolhem a TrueFoundry






3x
tempo mais rápido para gerar valor com agentes LLM autônomos
80%
maior utilização do cluster de GPUs após otimização automatizada de agentes

Aaron Erickson
Fundador, Laboratório de IA Aplicada
A TrueFoundry transformou nossa frota de GPUs em um motor autônomo e auto-otimizável – impulsionando 80% mais utilização e nos poupando milhões em computação ociosa.
5x
tempo mais rápido para colocar em produção a plataforma interna de IA/ML
50%
menor gasto na nuvem após migrar cargas de trabalho para a TrueFoundry

Pratik Agrawal
Diretor Sênior, Ciência de Dados e Inovação em IA
A TrueFoundry nos ajudou a passar da experimentação para a produção em tempo recorde. O que levaria mais de um ano foi feito em meses – com melhor adoção pelos desenvolvedores.
80%
redução no tempo de colocação em produção de modelos
35%
economia de custos na nuvem em comparação com a configuração anterior do SageMaker
.webp)
Vibhas Gejji
Engenheiro de ML da Equipe
Reduzimos a carga de DevOps e simplificamos as implantações em produção entre as equipes. O TrueFoundry acelerou a entrega de ML com uma infraestrutura que escala de experimentos a serviços robustos.
50%
implantação mais rápida da pilha RAG/Agente
60%
redução na sobrecarga de manutenção para pipelines RAG/agente
.webp)
Indroneel G.
Líder de Processos Inteligentes
O TrueFoundry nos ajudou a implantar uma pilha RAG completa — incluindo pipelines, DBs vetoriais, APIs e UI — duas vezes mais rápido, com controle total sobre a infraestrutura auto-hospedada.
60%
implantações de IA mais rápidas
~40-50%
Redução eficaz de custos em todos os ambientes de desenvolvimento
.webp)
Nilav Ghosh
Diretor Sênior de IA
Com o TrueFoundry, reduzimos os prazos de implantação em mais da metade e diminuímos a sobrecarga de infraestrutura por meio de uma interface MLOps unificada — acelerando a entrega de valor.
<2
semanas para migrar todos os modelos de produção
75%
redução no tempo de coordenação de ciência de dados, acelerando as atualizações de modelos e lançamentos de funcionalidades
.webp)
Rajat Bansal
CTO
Economizamos muito nos custos de infraestrutura e reduzimos o tempo de coordenação de DS em 75%. A TrueFoundry impulsionou a velocidade de implantação dos nossos modelos em todas as equipes.
Integrações
Integrações agnósticas de framework para tudo, desde construtores de agentes low-code até avaliação de desempenho em nível de GPU.
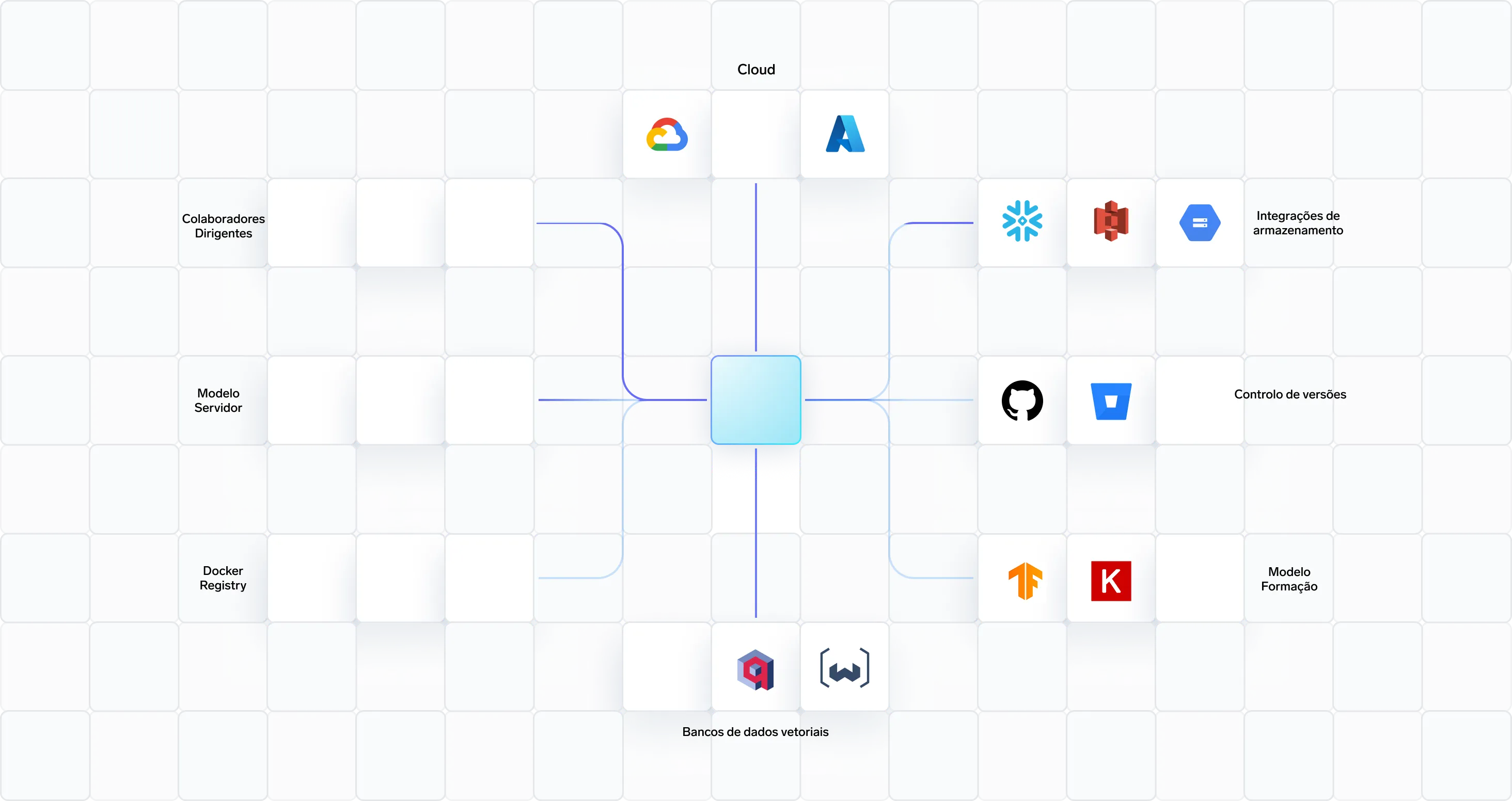

Infra GenAI - simples, mais rápida, mais barata
Confiado pelas Melhores Equipes para Escalar GenAI
- © 2022 ENSEMBLE Tecnologias






Assine nossa newsletter
As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.














