Custom Metadata
You can tag requests with custom metadata using theX-TFY-METADATA header. Metadata is a JSON object where both keys and values must be strings, with a maximum value length of 128 characters.
Sending Metadata
Automatic Metadata Injection
In addition to sending metadata explicitly via theX-TFY-METADATA header, TrueFoundry can automatically inject metadata into requests based on your access configuration. This ensures consistent tagging without requiring changes to client code.
Virtual account tags
Virtual account tags
Team tags via PATs
Team tags via PATs
Use Cases
Filter request logs and build custom metrics dashboards grouped by metadata keys
Filter request logs and build custom metrics dashboards grouped by metadata keys
Tag every request with attributes like 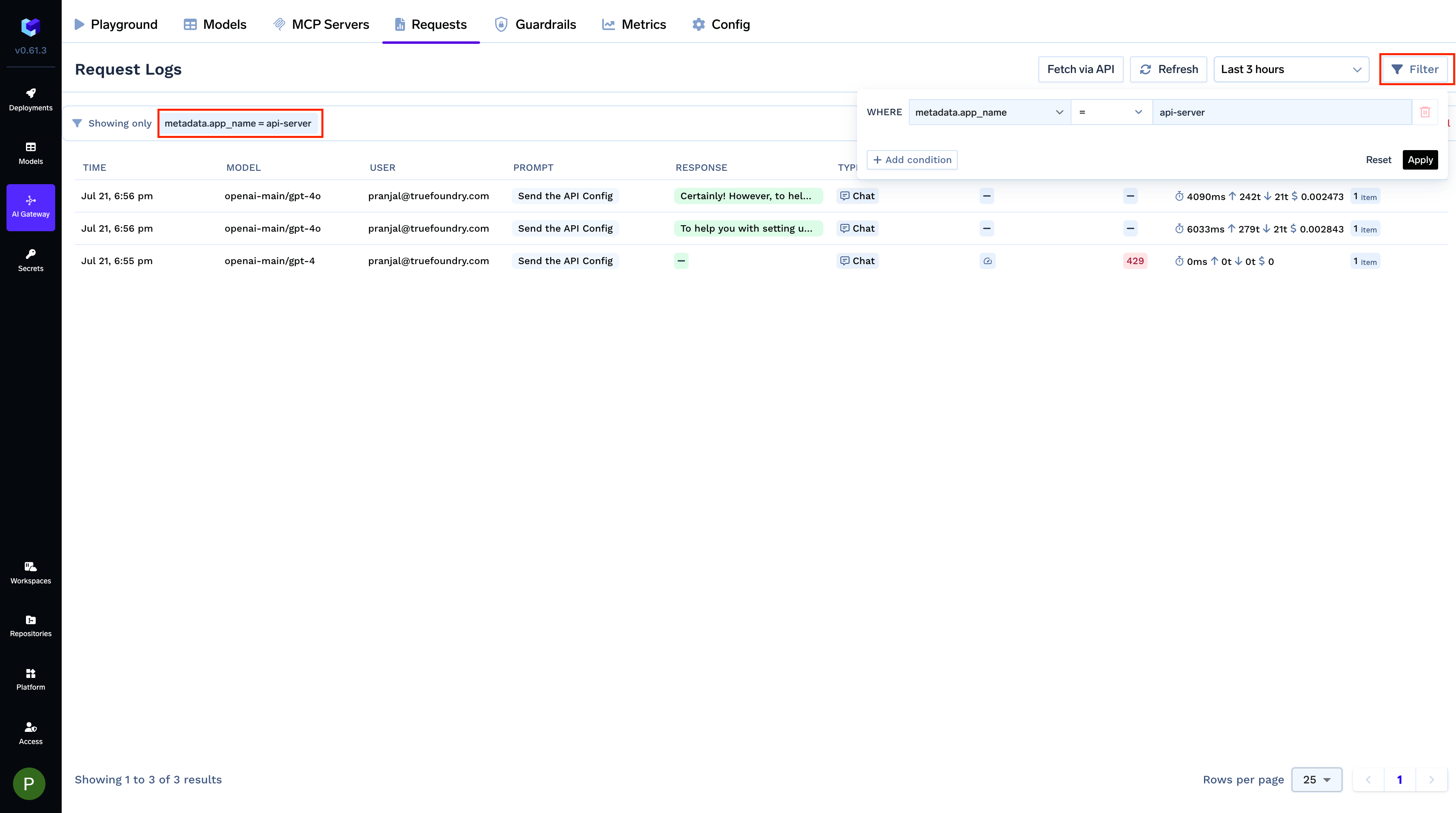
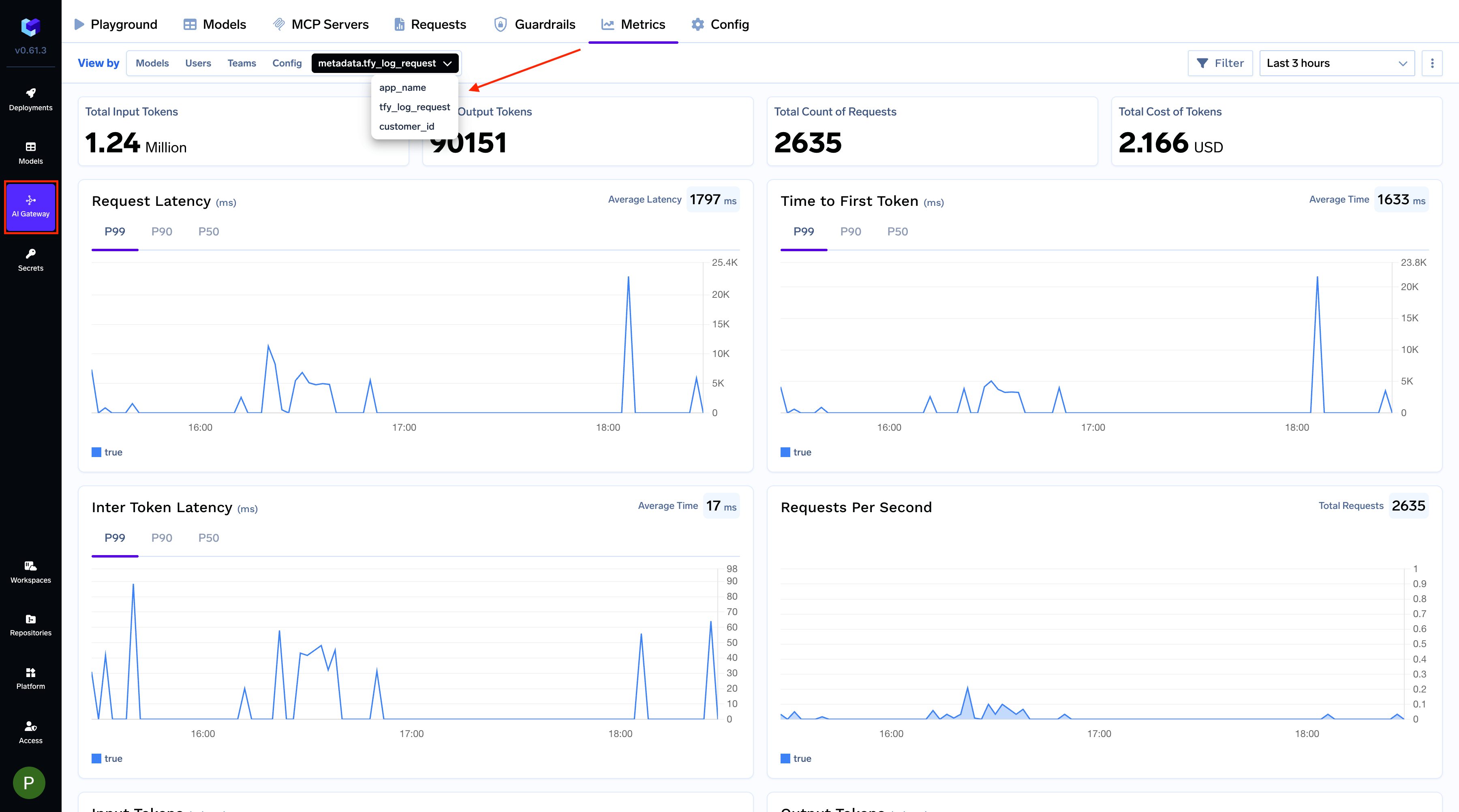
application, environment, or customer_id and slice your observability data by them.Filter LogsFilter your request logs using one or more metadata keys to isolate specific requests. This is useful for debugging or analyzing usage patterns for a particular feature, environment, or user.customer_id key.Selectively apply rate limits, fallbacks, and load balancing per metadata value
Selectively apply rate limits, fallbacks, and load balancing per metadata value
Use metadata in the You can also use metadata to configure Load Balancing and Fallbacks. Learn more in Virtual Models and Routing Config.
when block of gateway configurations to target specific applications, environments, or customers — without changing client code. For example, to rate limit requests from the dev environment:Request Headers
| Name | Description | Example |
|---|---|---|
Authorization | Your TrueFoundry API key (PAT or VAT) as a bearer token. See Authentication. | Authorization: Bearer TFY_API_KEY |
x-tfy-metadata | Stringified JSON where both keys and values must be strings. Used for request routing and metrics filtering. See Custom Metadata above. | x-tfy-metadata: {"custom_field":"value"} |
x-tfy-provider-name | Routes requests to the correct provider account. Required for Responses API, File API, and Batch API. | x-tfy-provider-name: openai |
x-tfy-strict-openai | Boolean flag to enable strict OpenAI compatibility. Set to false to access Claude thinking/reasoning tokens — see Reasoning Models. | x-tfy-strict-openai: true |
x-tfy-request-timeout | Number in milliseconds specifying the maximum time to wait for a response from a single model. If fallbacks or retries are configured, the timeout is applied per model request (i.e., each attempt, including fallbacks, will have its own timeout). See Virtual Models — Retries and fallbacks. | x-tfy-request-timeout: 60000 |
x-tfy-ttft-timeout-ms | Number in milliseconds specifying the maximum time to wait for the first token in a streaming response (time-to-first-token). If no token is received within this window, the request is considered timed out and the gateway returns 408. For virtual models or routing config, the gateway falls back to the next model on 408 even if 408 is not included in the fallback status codes. | x-tfy-ttft-timeout-ms: 30000 |
x-tfy-logging-config | Enable or disable logging for a specific request. See Request Logging for details. | x-tfy-logging-config: {"enabled": true} |
x-tfy-mcp-headers | Stringified JSON to pass custom headers to MCP servers. Format varies by API — see MCP Gateway and Agent API docs. Agent API only supports registered servers. | x-tfy-mcp-headers: {"truefoundry:...":{"Authorization":"Bearer TOKEN"}} |
Response Headers
| Name | Description |
|---|---|
x-tfy-resolved-model | The final TrueFoundry model ID used to process the request (may differ from the requested model due to load balancing or fallbacks). See Virtual Models. |
x-tfy-applied-configurations | Dictionary of applied configurations including load balancing, fallback, model config, applied guardrails, and rate limiting |
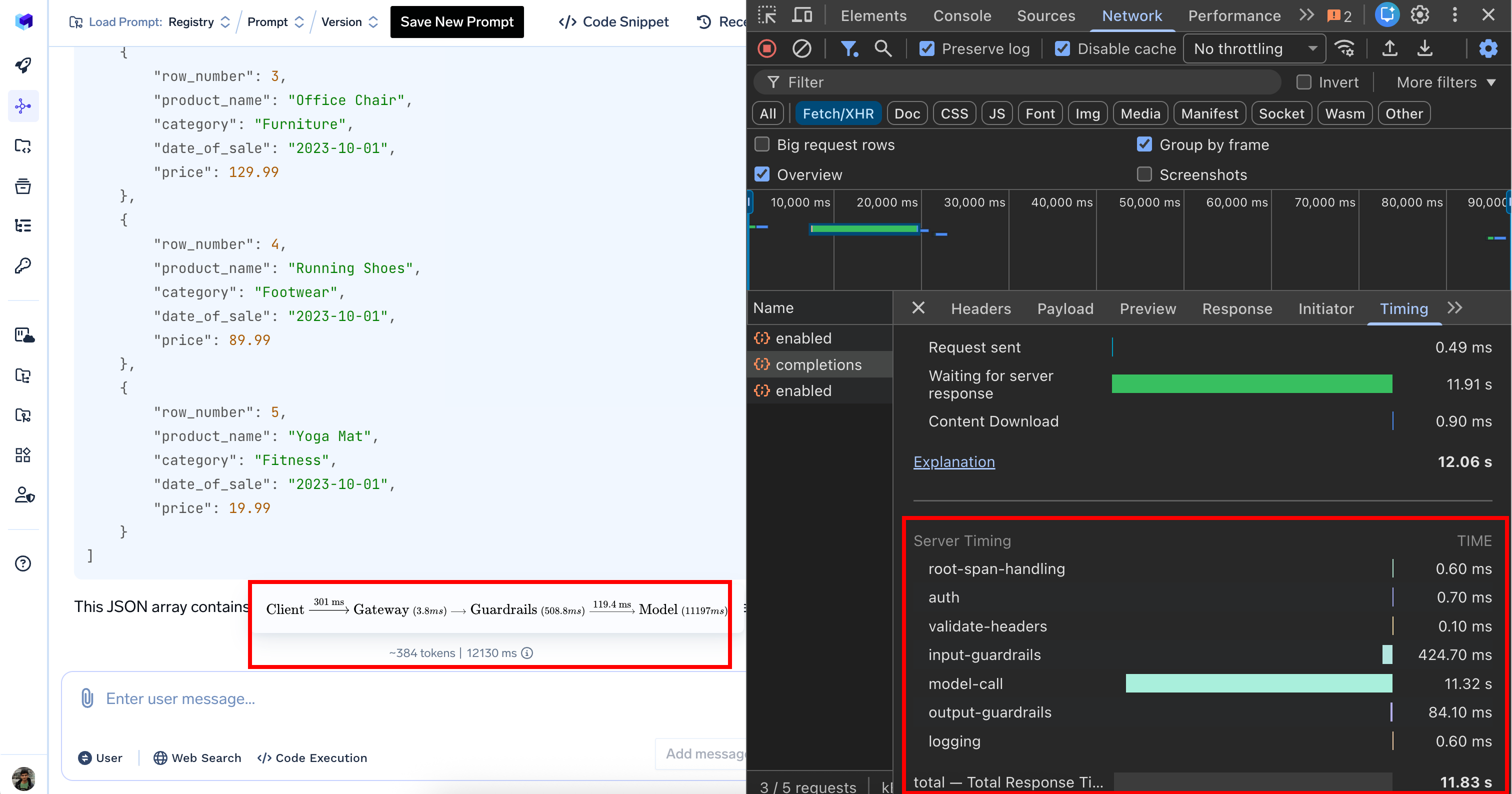
server-timing | For non-streaming requests only. Contains timing information for different processing stages including middlewares, guardrails, and model calls. See Server-Timing Breakdown below. |
Server-Timing Breakdown
When inspecting network requests in your browser’s developer tools, theserver-timing header provides a detailed performance breakdown:
| Processing Stage | Duration | Description |
|---|---|---|
| Authentication | 0.9 ms | Authenticating User |
| Input guardrails | 0.7 ms | Input validation and content filtering |
| Model call | 1350 ms | AI model response generation (bulk of the time) |
| Output guardrails | 722.3 ms | Output validation and filtering |
| Logging | 1.1 ms | Logging request |
| Total | 2080 ms | Complete request processing time (2.08 seconds) |
load balancing (0 ms), rate limiting (0 ms), and cost budget (0 ms) show zero duration because these configs weren’t triggered for this particular request.