



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 26, 2026

Blazingly fast way to build, track and deploy your models!
O TrueFoundry AI Gateway é uma camada de execução unificada para infraestrutura de LLM. Ele lida com autenticação, roteamento entre provedores, limitação de taxa, aplicação de políticas, gerenciamento de chamadas de ferramentas MCP e — crucialmente para esta integração — rastreamento compatível com OpenTelemetry. Cada solicitação através do gateway gera um span contendo atributos padrão gen_ai.* (nome do modelo, contagens de tokens, motivo de conclusão) juntamente com atributos específicos do TrueFoundry, como tfy.input, tfy.output, e tfy.span_type. Esses spans são publicados assincronamente em uma fila de mensagens NATS após a conclusão da solicitação, o que significa que o caminho de exportação nunca atrasa uma solicitação em andamento. Um serviço de exportação OTEL dedicado lê dessa fila e encaminha os spans para qualquer endpoint OTLP configurado via HTTP ou gRPC.
Pydantic Logfire é uma plataforma de observabilidade construída pela equipe por trás do Pydantic — a camada de validação incorporada nos SDKs da OpenAI, da Anthropic e na maioria dos frameworks de IA em produção atualmente. O Logfire ingere dados OTLP padrão e aplica renderização nativa de IA sobre eles: quando detecta gen_ai.* em um span, o Painel LLM ativa automaticamente, exibindo o histórico completo da conversa, argumentos de chamadas de ferramentas, contagens de tokens por solicitação e custos calculados — sem qualquer integração de SDK no lado do envio. As consultas do Logfire são escritas em SQL compatível com PostgreSQL, para que os rastreamentos de produção sejam acessíveis tanto a humanos quanto a agentes de codificação. Está disponível como um serviço de nuvem gerenciado com endpoints regionais nos EUA e na UE.
A integração se conecta em um único ponto: na Configuração OTELdo TrueFoundry, que aceita um endpoint HTTP OTLP e um cabeçalho de autorização. Navegue até AI Gateway → Controles → Configurações → Configuração OTEL e clique no botão de edição para abrir o painel de configuração.

Seção de Configuração OTEL do TrueFoundry — o endpoint de traces está apontado para a URL de ingestão da Logfire na UE com o cabeçalho Authorization definido.
Defina o endpoint para a URL de ingestão regional da Logfire, selecione HTTP com codificação proto e adicione o token de escrita da Logfire como o Authorization valor do cabeçalho. O mesmo token de escrita cobre tanto os exportadores de traces quanto os de métricas.
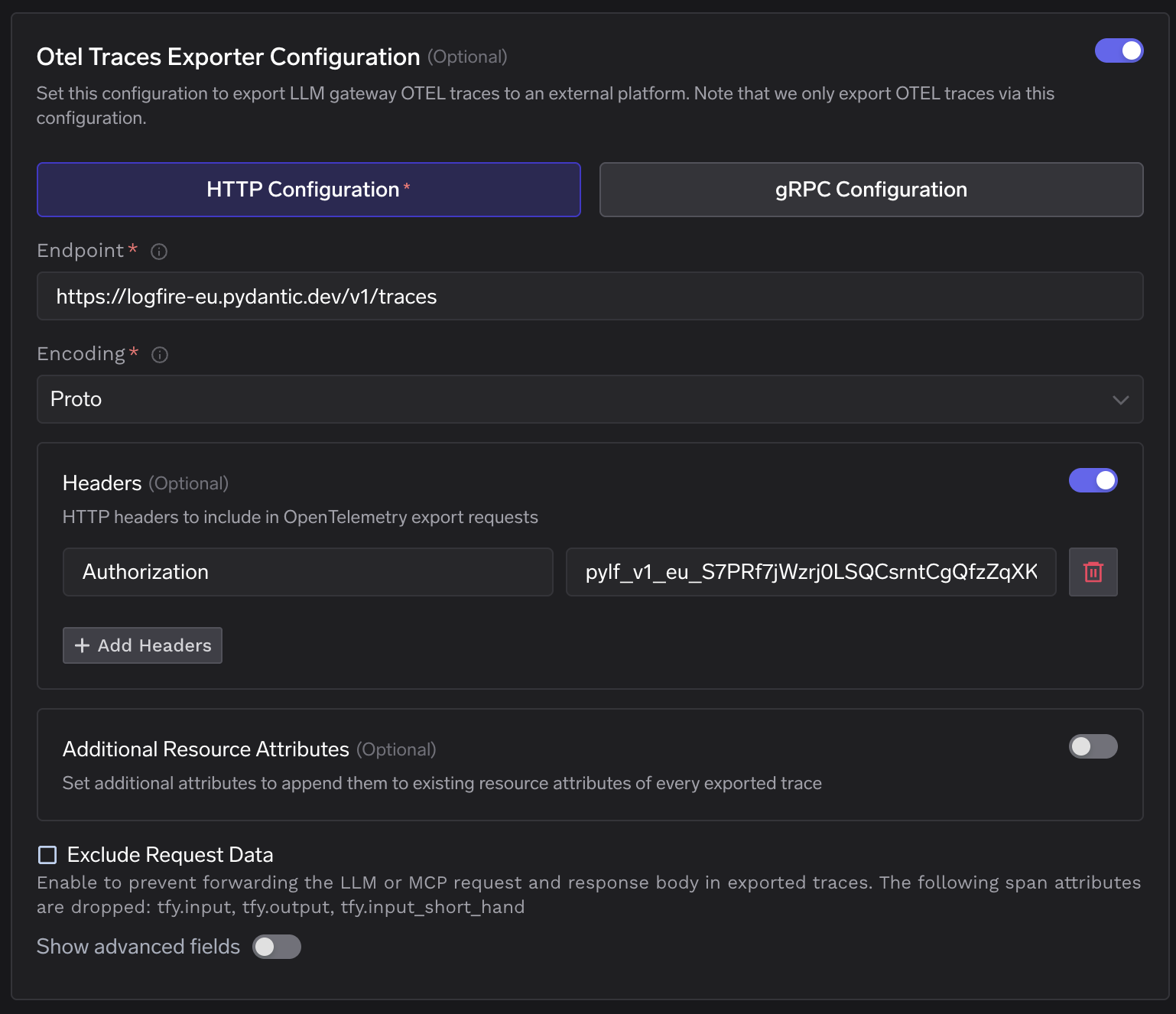
O formulário do Exportador de Traces preenchido — endpoint definido para https://logfire-eu.pydantic.dev/v1/traces, codificação Proto, e o token de escrita da Logfire no cabeçalho Authorization.
Nenhuma alteração de código é necessária nas aplicações que enviam requisições através do gateway. O pipeline de tracing opera inteiramente na camada de infraestrutura. Uma requisição de qualquer equipe, usando qualquer modelo, através de qualquer provedor, gera um span que flui para o Logfire, carregando o contexto completo do que aconteceu no gateway.
Quando uma requisição chega ao gateway, a sequência é:
Uma vez configurados, os spans do tfy-llm-gateway começam a aparecer na visualização ao vivo do Logfire em tempo real. O tfy.span_type atributo distingue ChatCompletion, AgentResponse, e MCPGateway spans — permitindo que as equipes filtrem por tipo de operação ou consultem-nos em SQL.

Visualização ao vivo do Logfire mostrando spans do tfy-llm-gateway — operações AgentResponse, ChatCompletion e MCPGateway aparecem com tempo completo, status e spans filhos aninhados.
Além dos rastreamentos individuais, o exportador de métricas exibe dados de uso agregados entre provedores, modelos e equipes. A visão geral de uso do Logfire agrupa-os por escopo e nome de span, fornecendo aos líderes de plataforma uma imagem de alto nível de para onde o tráfego está indo e em que volume.
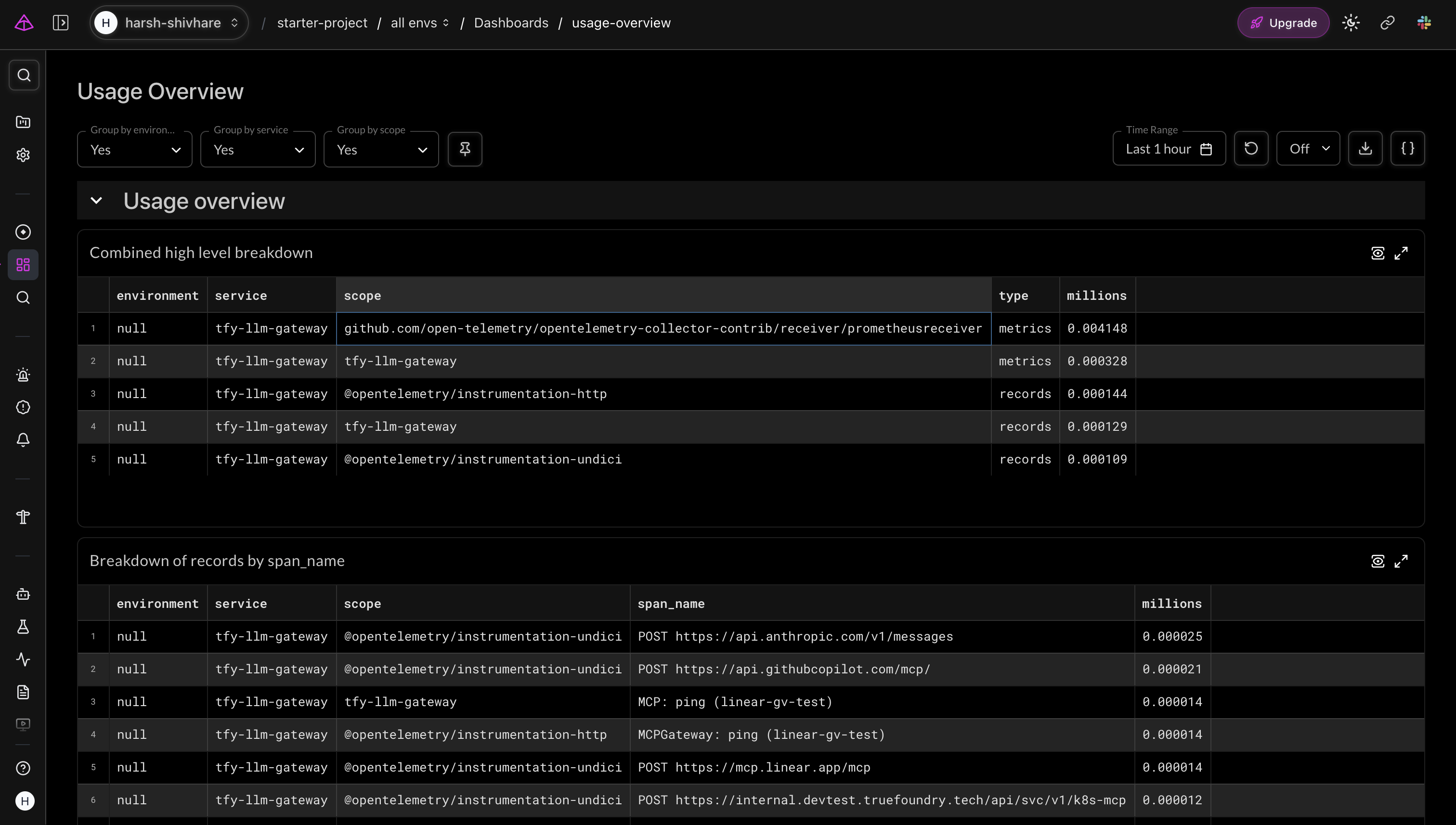
Visão geral de uso do Logfire — métricas do tfy-llm-gateway detalhadas por escopo de instrumentação, mostrando o tráfego de ChatCompletion e MCPGateway entre provedores.
Comece criando um token de escrita no Logfire. Navegue até seu projeto, abra Configurações do Projeto → Tokens de Escrita, e clique em Novo token de escrita. Copie o token imediatamente — o Logfire não exibirá o valor completo novamente.

A página de Tokens de Escrita do Logfire — crie um token dedicado para TrueFoundry e armazene-o com segurança antes de fechar a caixa de diálogo.
Em seguida, vá para AI Gateway → Controles → Configurações → Configuração OTEL no TrueFoundry e configure os exportadores de rastreamentos e métricas com o endpoint regional do Logfire e o token de escrita. A referência completa do endpoint e o guia de configuração estão disponíveis na documentação do TrueFoundry. O Logfire oferece um nível gratuito perpétuo, com uma opção empresarial auto-hospedada para equipes com requisitos de residência de dados.
A percepção valiosa a ser tirada desta integração é arquitetônica: TrueFoundry e Logfire nunca precisaram coordenar diretamente. O gateway emite spans OpenTelemetry padrão com atributos gen_ai.*; o Logfire lê esse mesmo padrão e ativa suas visualizações cientes de LLM automaticamente. OpenTelemetry é o contrato entre eles — o gateway governa a execução e gera telemetria, o Logfire registra e visualiza o comportamento, e o padrão os conecta sem que nenhum dos sistemas dependa dos internos do outro.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




