











LLMs
Implemente e sirva LLMs de código aberto ou proprietários com aceleração de GPU e confiabilidade de nível de produção.
Agentes
Execute agentes de IA de longa duração com memória, execução de ferramentas e integração perfeita com o AI Gateway e servidores MCP.
Servidores MCP
Implemente servidores MCP para expor com segurança ferramentas, APIs e sistemas empresariais a agentes de IA.
Fluxos de Trabalho
Orquestrar fluxos de trabalho de IA de várias etapas entre modelos, agentes e serviços a partir de um único plano de controle.
Trabalhos
Executar trabalhos em lote, cargas de trabalho de treinamento e tarefas de IA agendadas sob demanda.
Modelos Clássicos de ML
Implementar e disponibilizar modelos tradicionais de machine learning juntamente com LLMs usando a mesma plataforma.
.webp)
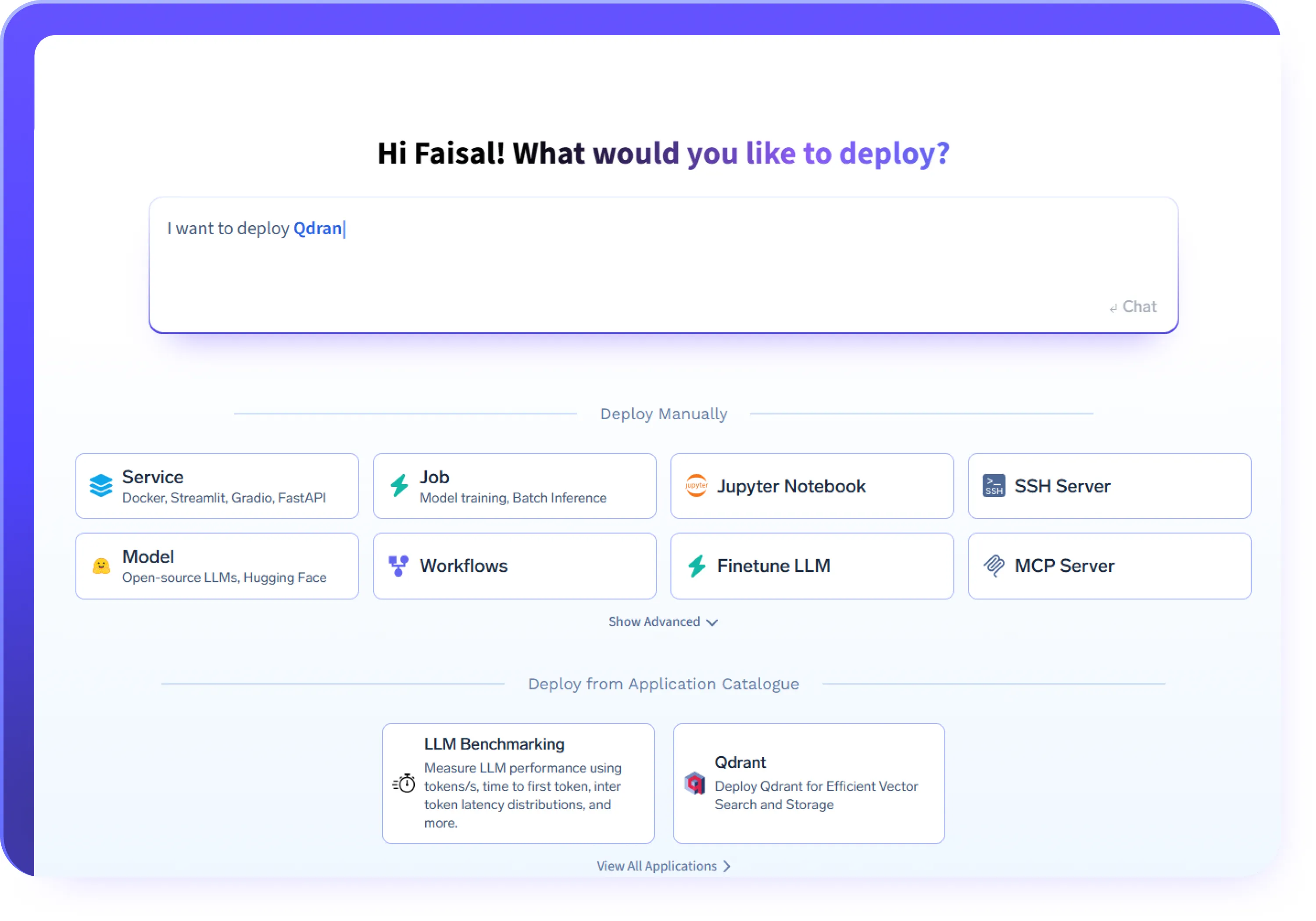
Implementar Qualquer Carga de Trabalho de IA
- Implementar LLMs e cargas de trabalho de inferência baseadas em GPU usando frameworks como vLLM, Triton, KServe ou contêineres personalizados
- Implementar agentes de IA e serviços de agente com tempo de execução e rede consistentes
- Implementar servidores MCP para expor com segurança ferramentas e sistemas internos
- Executar trabalhos em lote, APIs e serviços de IA de longa duração na mesma plataforma
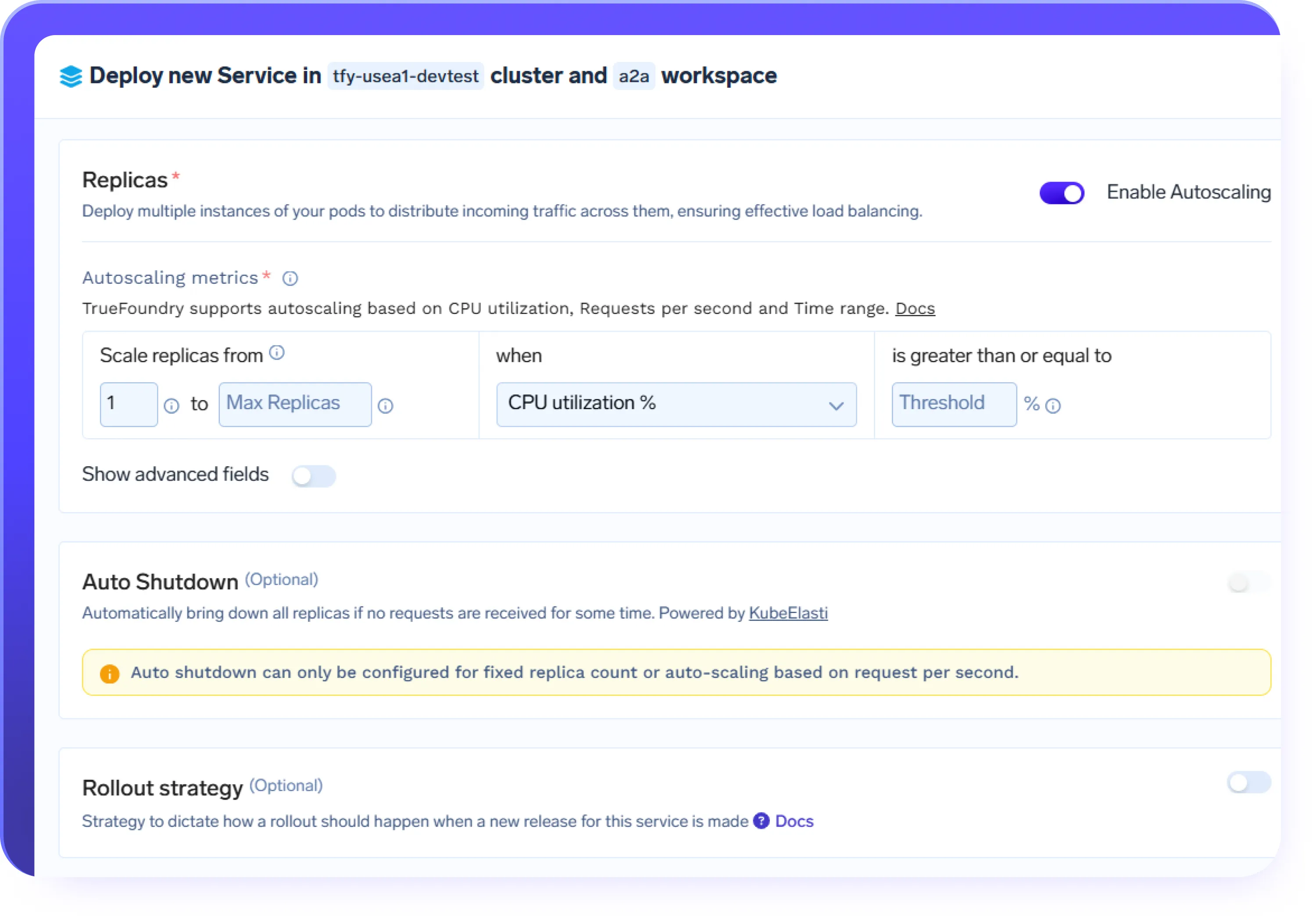
Dimensionamento automático para cargas de trabalho de IA
demanda.
- Dimensionar automaticamente endpoints de inferência e serviços de agente com base no volume de solicitações
- Aumentar a escala das cargas de trabalho de GPU durante a demanda de pico e reduzi-la quando o tráfego diminui
- Suportar cargas de trabalho com picos, como chat, RAG e fluxos de trabalho orientados por agentes
- Manter um desempenho previsível durante picos de tráfego
Desligamento Automático para Controlar Custos
- Desligue automaticamente endpoints, agentes ou serviços após períodos de inatividade configuráveis
- Reduza o desperdício de GPU fora do horário de pico ou durante experimentação
- Reinicie cargas de trabalho sob demanda sem intervenção manual
- Imponha disciplina de custos entre equipes e
ambientes
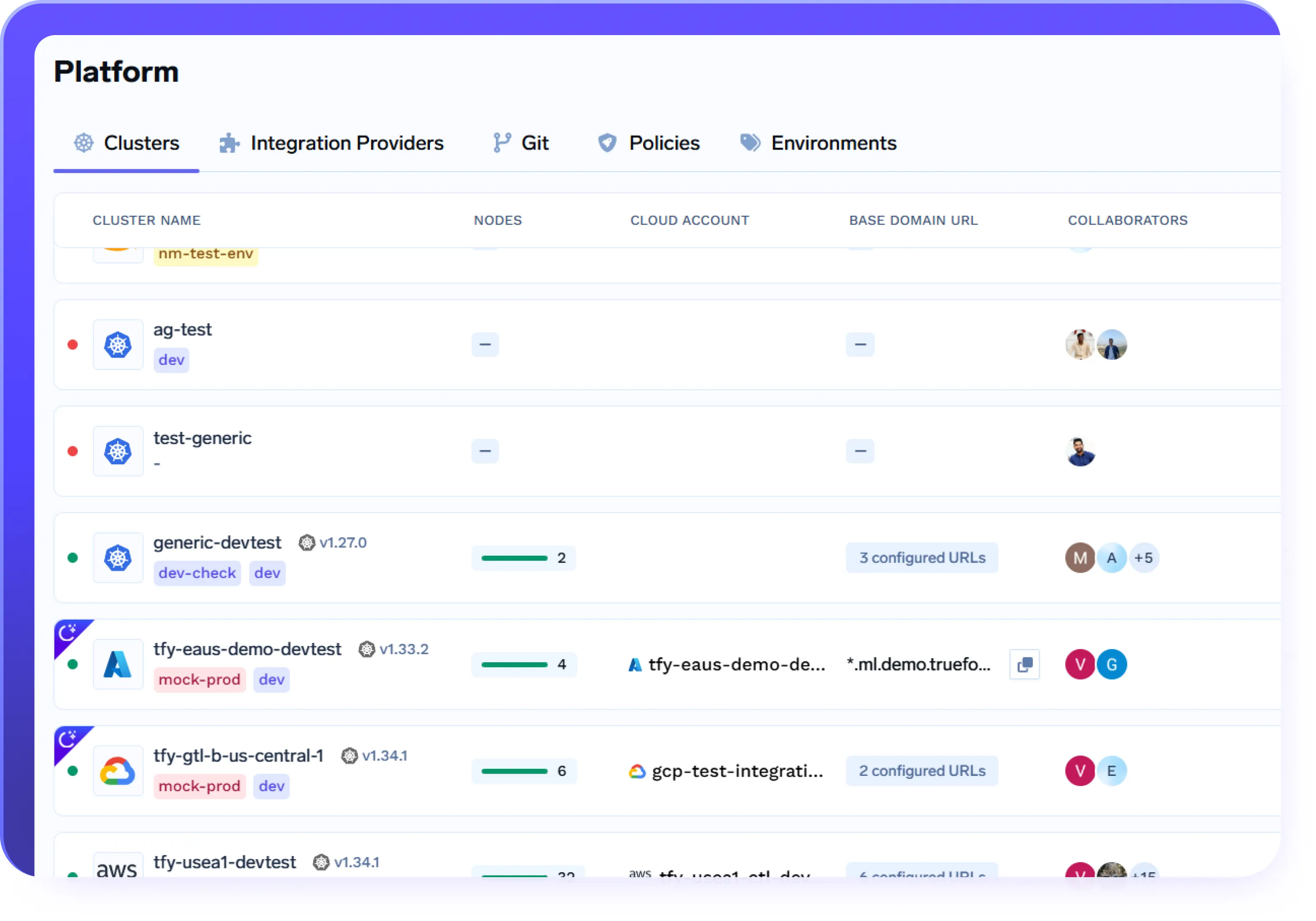
Experiência de Implantação Unificada Entre Nuvem/On-premise
- Conecte e gerencie clusters AWS, Azure, GCP e on-premise a partir de um único plano de controle
- Implante a mesma carga de trabalho em diferentes ambientes usando fluxos de trabalho e APIs idênticos
- Abstraia a complexidade específica da nuvem, mantendo total controle e isolamento
- Utilize a mesma experiência de implantação em desenvolvimento, staging e produção, independentemente da infraestrutura
Construído para uma Experiência do Desenvolvedor de Primeira Classe
- Logs, métricas e eventos integrados para cada implantação
- Monitoramento e alertas nativos para detectar e resolver problemas rapidamente
- Recursos de implantação prontos para produção, como verificações de saúde e estratégias de lançamento
- Gerenciamento seguro de segredos e integrações CI/CD contínuas
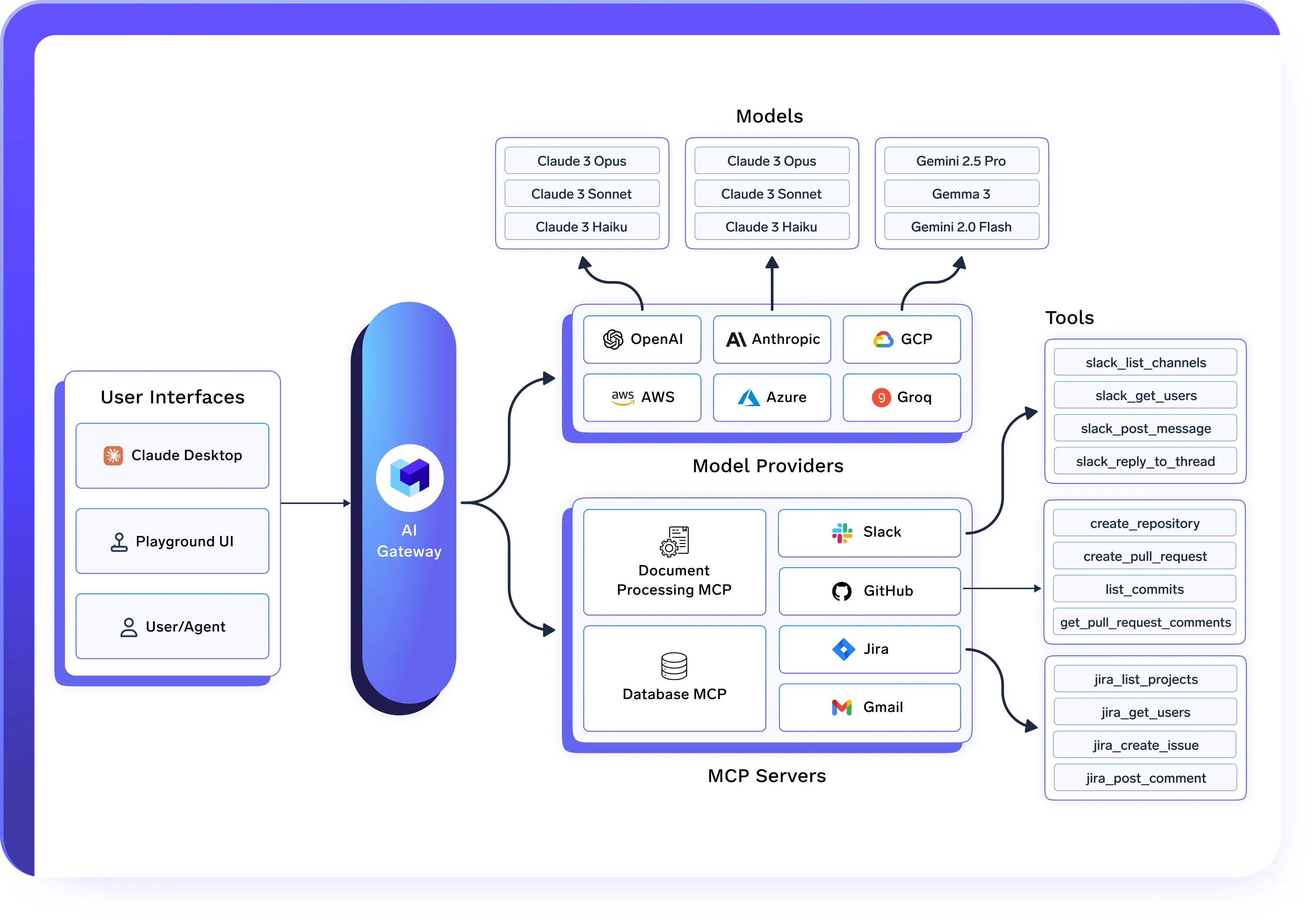
Funciona Perfeitamente com AI Gateway e Agent Gateway
acima dela.
- O AI Gateway governa o acesso a modelos, o roteamento e os controles de custo
- O MCP Gateway governa o acesso e a execução de ferramentas
- O Agent Gateway orquestra e governa os fluxos de trabalho de agentes
- Implantações Unificadas de IA impulsionam a execução e a infraestrutura reais
Feito para IA do Mundo Real em Escala
Pronto para Empresas
Implante um gateway de IA seguro que mantém seus dados e modelos dentro da sua infraestrutura em nuvem / on-premise.


Conformidade e Segurança
Padrões SOC 2, HIPAA e GDPR para garantir uma proteção de dados robustaGovernança e Controle de Acesso
SSO + Controle de Acesso Baseado em Função (RBAC) e Registro de AuditoriaSuporte Empresarial e Confiabilidade
Suporte 24/7 com garantia de SLA SLAs de resposta
VPC, on-premise, isolado (air-gapped), ou em várias nuvens.
Nenhum dado sai do seu domínio. Desfrute de soberania, isolamento e conformidade de nível empresarial completos onde quer que a TrueFoundry seja executada.

.avif)
Resultados Reais na TrueFoundry
Por que as Empresas Escolhem a TrueFoundry






3x
tempo de valorização mais rápido com agentes LLM autônomos
80%
maior utilização do cluster de GPU após otimização automatizada de agentes

Aaron Erickson
Fundador, Laboratório de IA Aplicada
A TrueFoundry transformou nossa frota de GPUs em um motor autônomo e auto-otimizável - impulsionando 80 % mais utilização e nos poupando milhões em computação ociosa.
5x
tempo mais rápido para colocar em produção a plataforma interna de IA/ML
50%
menor gasto com a nuvem após migrar cargas de trabalho para a TrueFoundry

Pratik Agrawal
Diretor Sênior de Ciência de Dados e Inovação em IA
A TrueFoundry nos ajudou a passar da experimentação para a produção em tempo recorde. O que levaria mais de um ano foi feito em meses - com melhor adoção pelos desenvolvedores.
80%
redução no tempo de colocação em produção para modelos
35%
economia de custos na nuvem em comparação com a configuração anterior do SageMaker
.webp)
Vibhas Gejji
Engenheiro de ML Sênior
Reduzimos a carga de DevOps e simplificamos as implementações em produção entre as equipes. A TrueFoundry acelerou a entrega de ML com uma infraestrutura que escala de experimentos a serviços robustos.
50%
implantação mais rápida da stack RAG/Agente
60%
redução na sobrecarga de manutenção para pipelines RAG/agente
.webp)
Indroneel G.
Líder de Processos Inteligentes
A TrueFoundry nos ajudou a implantar uma pilha RAG completa — incluindo pipelines, DBs vetoriais, APIs e UI — duas vezes mais rápido, com controle total sobre a infraestrutura auto-hospedada.
60%
implantações de IA mais rápidas
~40-50%
Redução eficaz de custos em todos os ambientes de desenvolvimento
.webp)
Nilav Ghosh
Diretor Sênior de IA
Com a TrueFoundry, reduzimos os prazos de implantação em mais da metade e diminuímos a sobrecarga de infraestrutura por meio de uma interface MLOps unificada — acelerando a entrega de valor.
<2
semanas para migrar todos os modelos de produção
75%
redução no tempo de coordenação da ciência de dados, acelerando as atualizações de modelos e lançamentos de recursos
.webp)
Rajat Bansal
CTO
Economizamos muito nos custos de infraestrutura e reduzimos o tempo de coordenação de DS em 75%. A TrueFoundry impulsionou a velocidade de implantação de nossos modelos em todas as equipes.
Perguntas frequentes
Que tipos de cargas de trabalho de IA posso implantar com o Unified AI Deployments?
O Unified AI Deployments suporta escalonamento automático?
Como funciona o desligamento automático para cargas de trabalho de IA?
Posso implantar cargas de trabalho de IA no meu próprio ambiente?
Como as Implantações Unificadas de IA se integram com o AI Gateway?

Infraestrutura de GenAI – simples, mais rápida, mais barata
Confiado por mais de 30 empresas e companhias da Fortune 500








