



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Oracle Cloud Infrastructure (OCI) adota uma abordagem diferente para a computação de IA do que os hiperescaladores que priorizam VMs. A camada diferenciada é bare metal: as instâncias de GPU do OCI — como BM.GPU.H100.8 — executam com zero sobrecarga de hipervisor e conectam-se através de SmartNICs NVIDIA ConnectX por meio de uma rede personalizada RDMA over Converged Ethernet (RoCE v2) de cluster.
Esse limite de desempenho tem um custo operacional. Bare metal significa que você agora é responsável pela camada que as VMs geralmente abstraem: drivers de GPU e a pilha OFED, agendamento dentro das restrições de topologia da rede do cluster, federação de identidade através do OCI IAM e a escolha entre vários caminhos de armazenamento para os pesos do modelo. Nada disso é exótico, mas é um trabalho substancial de Kubernetes que não aparece nas ofertas de VMs gerenciadas.
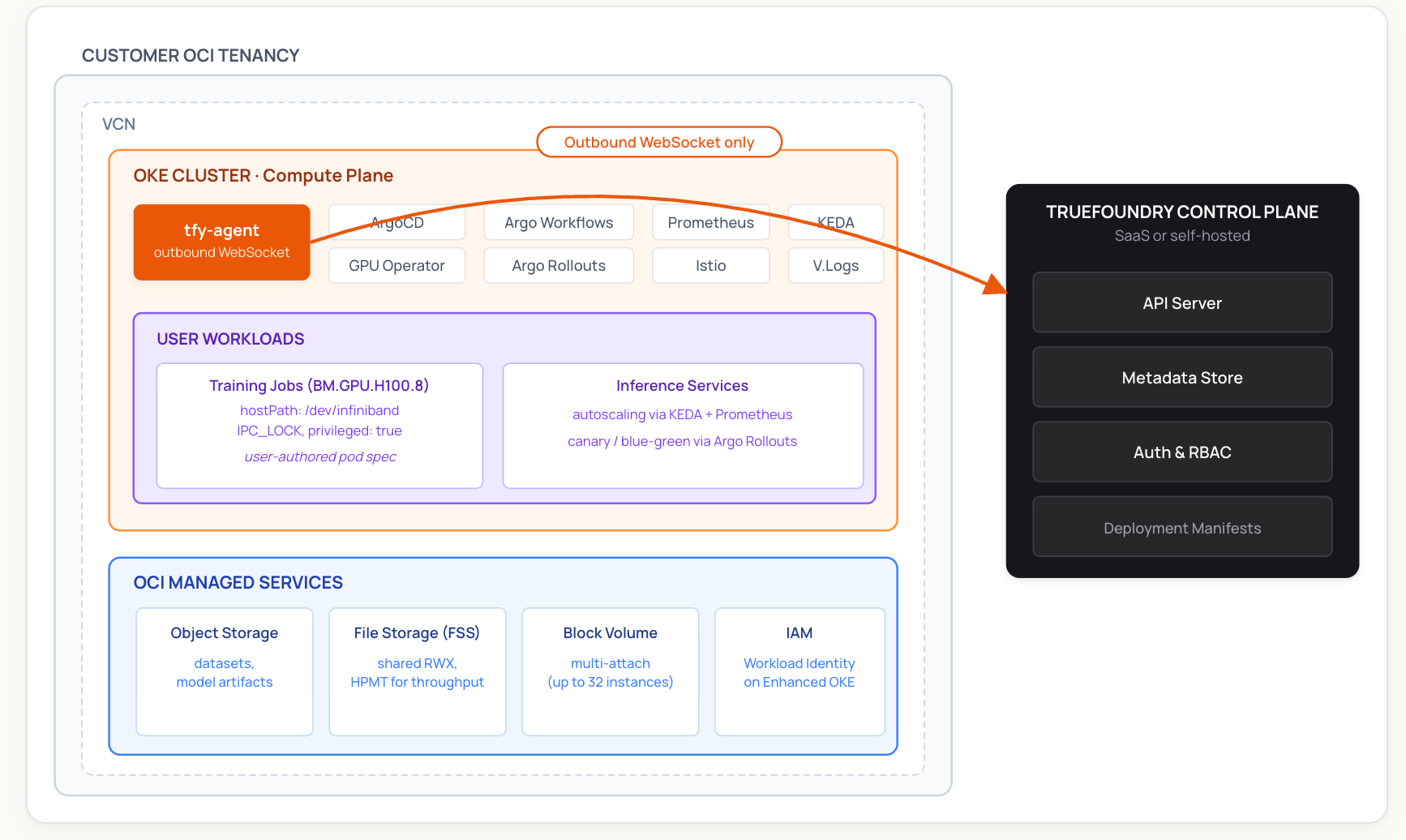
O papel do TrueFoundry nesta pilha é a camada operacional nativa do Kubernetes. O Plano de Computação é o seu próprio Oracle Cloud Infrastructure Kubernetes Engine (OKE) cluster executando em bare metal do OCI. A plataforma empacota um conjunto de componentes de código aberto e afiliados à CNCF (ArgoCD, Argo Workflows, NVIDIA GPU Operator, Prometheus, KEDA, Istio e outros) em uma implantação gerenciada, adiciona uma UI unificada e um fluxo de trabalho GitOps, e fornece observabilidade em serviços, trabalhos e utilização de GPU. Não substitui as primitivas do OCI — ele se posiciona sobre elas.
Esta publicação detalha a arquitetura que você obtém ao executar o TrueFoundry em bare metal do OCI: a divisão entre plano de controle e plano de computação, como o treinamento RDMA se encaixa no Kubernetes, como funciona a identidade da carga de trabalho e os padrões práticos para carregar pesos de modelo em escala.
TrueFoundry utiliza uma arquitetura de plano dividido. O Plano de Controle (gerenciado pelo TrueFoundry ou auto-hospedado) armazena metadados, RBAC, o servidor de API e o repositório de manifestos de implantação. O Plano de Computação é um ou mais clusters Kubernetes em seu próprio ambiente de nuvem — neste caso, um cluster OKE em bare metal do OCI. Cargas de trabalho, pesos de modelo e dados do cliente permanecem em sua tenancy.
O elo entre eles é o tfy-agent, que é executado no cluster do Plano de Computação e abre uma conexão WebSocket somente de saída para o Plano de Controle. O agente puxa manifestos de implantação e envia atualizações de recursos do Kubernetes. Como a conexão é de saída, você não precisa abrir portas de entrada em sua VCN ou expor o servidor de API do cluster à internet pública.
Quando o TrueFoundry configura um Plano de Computação, o agente instala e gerencia um conjunto de complementos de código aberto via ArgoCD:
Você também pode trazer suas próprias instâncias existentes de qualquer um desses — o TrueFoundry documenta a configuração necessária para coexistir com uma instalação existente do ArgoCD, Prometheus ou Istio.
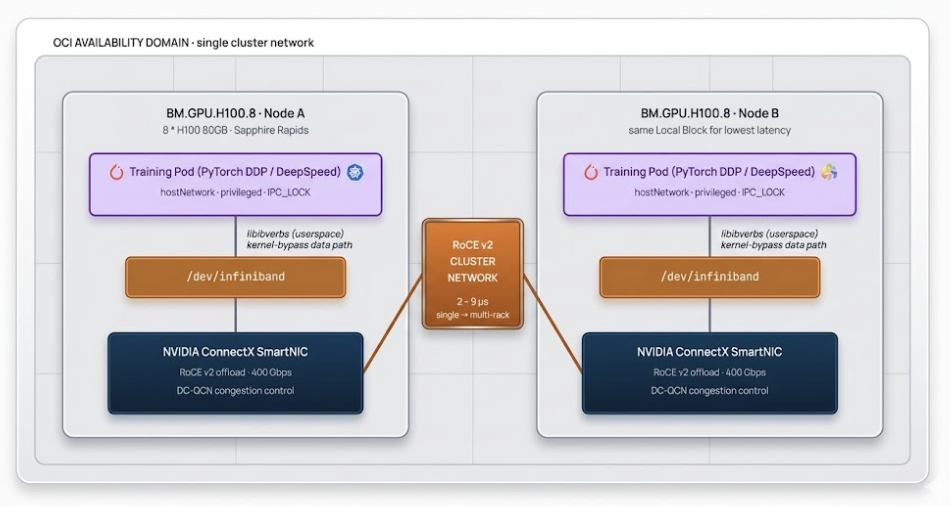
A rede de cluster do OCI é a camada de rede diferenciada que torna o treinamento distribuído em larga escala viável. A Oracle publicou medições internas mostrando latência de microssegundos de um único dígito nesta malha — tão baixa quanto 2 microssegundos para clusters de rack único, e tipicamente de 2,5 a 9 microssegundos em superclusters de múltiplos racks — usando RoCE v2 sobre SmartNICs NVIDIA ConnectX. Os números reais em produção dependem da topologia do cluster, tamanho da mensagem e contenção; Documento sobre os Primeiros Princípios da Oracle aborda o projeto subjacente.
Para usar o RDMA de forma eficaz, duas condições precisam ser atendidas:
oci.oraclecloud.com/rdma.local_block_id, network_block_id, e hpc_island_id — e o guia de início rápido oci-hpc-oke da Oracle mostra como usá-los com o agendamento com reconhecimento de topologia do Kueue para o melhor desempenho do NCCL. Para treinamento fortemente acoplado, prefira co-localizar pods dentro do mesmo Bloco Local./dev/infiniband/ (a nomenclatura do caminho reflete a API subjacente de verbos IB, mesmo que o transporte seja RoCE v2 sobre Ethernet).O padrão de pod do guia de início rápido da Oracle é o seguinte:
spec:
hostNetwork: true
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: trainer
securityContext:
privileged: true
capabilities:
add: ["IPC_LOCK"]
volumeMounts:
- { mountPath: /dev/infiniband, name: devinf }
- { mountPath: /dev/shm, name: shm }
volumes:
- { name: devinf, hostPath: { path: /dev/infiniband }}
- { name: shm, emptyDir: { medium: Memory, sizeLimit: 32Gi }}Esses privilégios elevados — privileged: true, IPC_LOCK, rede de host — são específicos para cargas de trabalho HPC/RDMA. Em produção, isole esses pods em namespaces de GPU dedicados com políticas de admissão (por exemplo, Pod Security Admission definido como privileged no namespace, restricted em outros lugares; ou uma política OPA/Kyverno que restringe por rótulo) para que cargas de trabalho não relacionadas não herdem o mesmo contexto.
O papel da TrueFoundry aqui é fazer com que a execução desses pods de treinamento faça parte de um fluxo de trabalho de implantação normal — você cria a carga de trabalho, a plataforma a envia através do Argo Workflows, o Prometheus coleta métricas de GPU do DCGM Exporter fornecido com o GPU Operator, e o ArgoCD versiona os manifestos. Sinais de nível de carga de trabalho, como contadores NCCL, são coletados apenas quando a aplicação os expõe. As partes específicas do RDMA (montagens hostPath, IPC_LOCK, afinidade de topologia) são configuradas na sua especificação de job seguindo o padrão padrão acima; a plataforma não substitui esses campos, ela implanta o que você especificar.
Para treinamento distribuído multi-nó especificamente, você normalmente instalará um operador no cluster através do seu helm chart — MPI Operator para execuções baseadas em MPIJob (PyTorch DDP, DeepSpeed, NCCL), Kubeflow Training Operator para PyTorchJob/TFJob, ou KubeRay para treinamento baseado em Ray. A TrueFoundry não os inclui por padrão. Uma vez instalado, a plataforma implanta recursos MPIJob/PyTorchJob/RayJob como qualquer outra carga de trabalho Kubernetes, com a mesma abordagem de GitOps e observabilidade. O treinamento distribuído com RDMA no OCI não é um recurso de primeira classe da TrueFoundry hoje — é um padrão de implementação baseado nos manifestos de referência publicados pela Oracle, com a plataforma lidando com a pilha operacional circundante em vez da orquestração específica do RDMA.
Para tipos de cluster suportados, a OCI agora recomenda Identidade de Carga de Trabalho OKE em vez de distribuir chaves de API de longa duração para pods. O mecanismo funciona de forma semelhante ao AWS IRSA ou GKE Workload Identity: uma ServiceAccount do Kubernetes é mapeada para uma política IAM do OCI, e o SDK do OCI troca o token de ServiceAccount projetado do pod por um token de acesso OCI de curta duração no momento da chamada. Não há credencial estática no pod.
Duas restrições importantes dos documentos da Oracle:
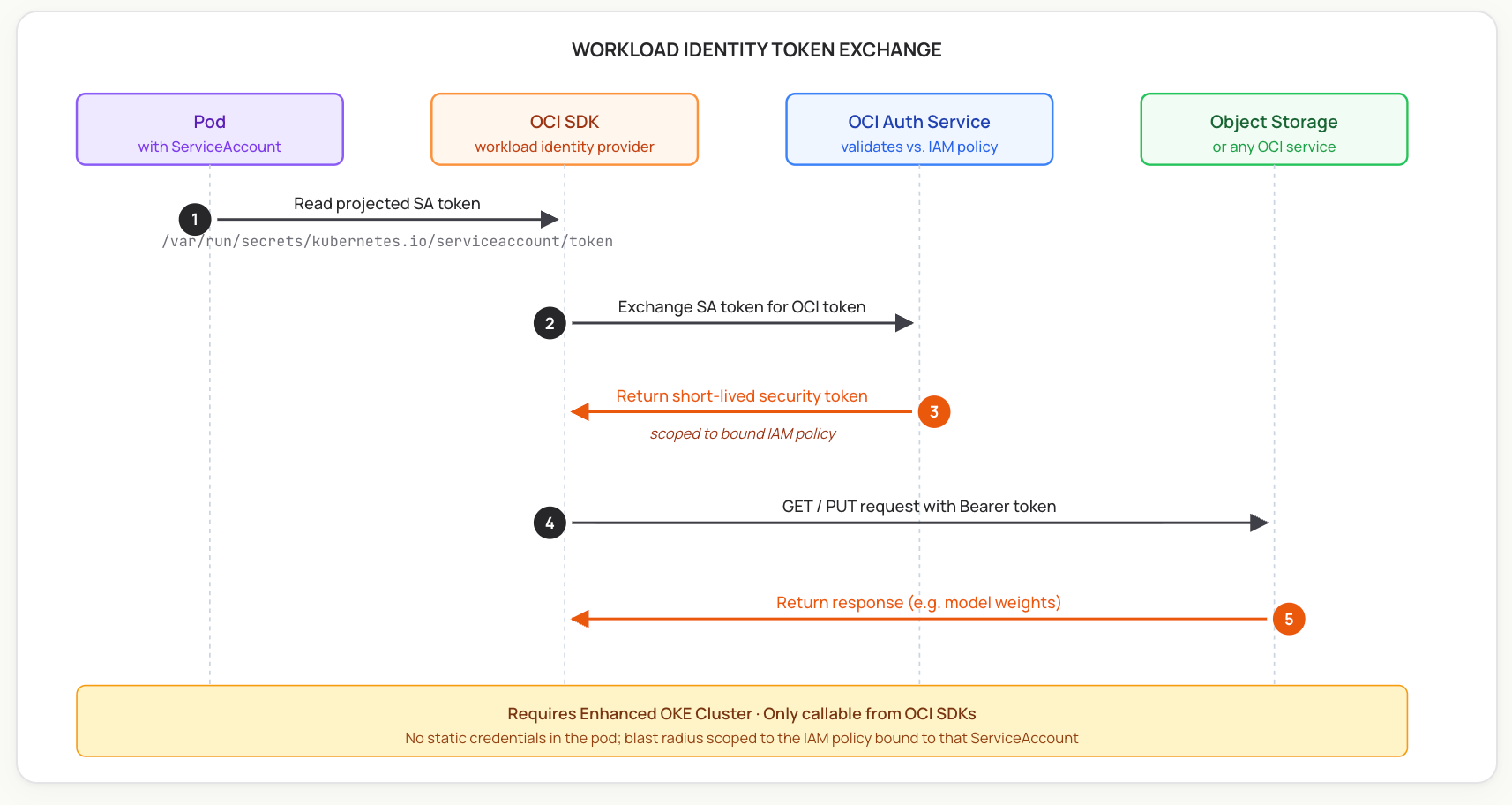
No lado do Kubernetes, as cargas de trabalho são vinculadas a ServiceAccounts com escopo de namespace, e a plataforma pode automatizar sua criação como parte do fluxo de implantação. O lado do OCI — a política IAM com a request.principal.type='workload' regra e os seletores de cluster/namespace/serviceaccount — é configurado de acordo com a configuração padrão de Identidade de Carga de Trabalho da Oracle. Uma vez que ambos os lados estejam configurados, as implantações que precisam de acesso ao OCI obtêm tokens de curta duração de forma transparente através do SDK.
O OCI bare metal oferece várias opções de armazenamento para carregar pesos de modelos na VRAM. Cada uma tem suas vantagens e desvantagens, e as abstrações de volume da TrueFoundry (PVCs, montagens de volume, contêineres de inicialização) funcionam com todas elas — o padrão certo depende da sua carga de trabalho:
O padrão correto depende da carga de trabalho. Para a maioria das execuções de treinamento, NVMe local (para dados quentes efêmeros) mais FSS (para checkpoints e pesos compartilhados) é a configuração de produção. O multi-anexo de Volume de Bloco é uma opção para casos específicos onde um único artefato imutável precisa parecer um disco local para muitos leitores.
Executar cargas de trabalho de GPU bare-metal em primitivas OCI brutas é viável — a Oracle fornece uma pilha HPC baseada em Terraform e o quickstart oci-hpc-oke — mas isso deixa você responsável por uma camada operacional substancial do Kubernetes. A tabela abaixo descreve o que o TrueFoundry adiciona.
O padrão é consistente: o OCI fornece as primitivas de computação e rede bare-metal; o TrueFoundry fornece a camada operacional do Kubernetes por cima.
TrueFoundry no OCI é uma plataforma nativa do Kubernetes executada na pilha bare-metal da Oracle. O Plano de Computação é o seu cluster OKE, as cargas de trabalho usam a rede de cluster RoCE v2 do OCI e a Identidade de Carga de Trabalho através de padrões Kubernetes padrão, e a plataforma empacota a camada operacional de código aberto e afiliada à CNCF — GitOps, observabilidade, autoescalonamento, operador de GPU — em uma implantação gerenciada. O resultado é menos sobrecarga de engenharia de plataforma para operar cargas de trabalho de GPU bare-metal, com a configuração específica do OCI mantida transparente em vez de oculta.
Um caminho de avaliação prático é uma implantação de referência em um pequeno cluster OKE — tipicamente uma ou duas formas BM.GPU mais um pool de CPU para os complementos da plataforma — para validar a arquitetura antes de escalar para um Supercluster completo.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




