











Faça Fine-Tuning de Qualquer Modelo
Faça fine-tuning de LLMs e modelos de ML clássicos usando integrações Hugging Face e modelos prontos para produção.
Fine-Tuning Sem Código ou Com Código Completo
Comece rapidamente com uma UI sem código ou traga seus próprios scripts de treinamento para controle total e flexibilidade.
PEFT e Fine-Tuning Completo
Suporte a LoRA, QLoRA e fine-tuning completo para equilibrar custo, uso de memória e desempenho do modelo.
Criação de Checkpoints e Versionamento
Crie checkpoints de execuções automaticamente, retome o treinamento e crie versões de modelos e conjuntos de dados para reprodutibilidade.
Rastreamento de Experimentos Integrado
Acompanhe hiperparâmetros, métricas, conjuntos de dados e saídas em todas as execuções de fine-tuning.
Gerenciamento de Adaptadores
Treine, reutilize, mescle e alterne adaptadores LoRA para acelerar o ajuste fino e reduzir custos.
.webp)
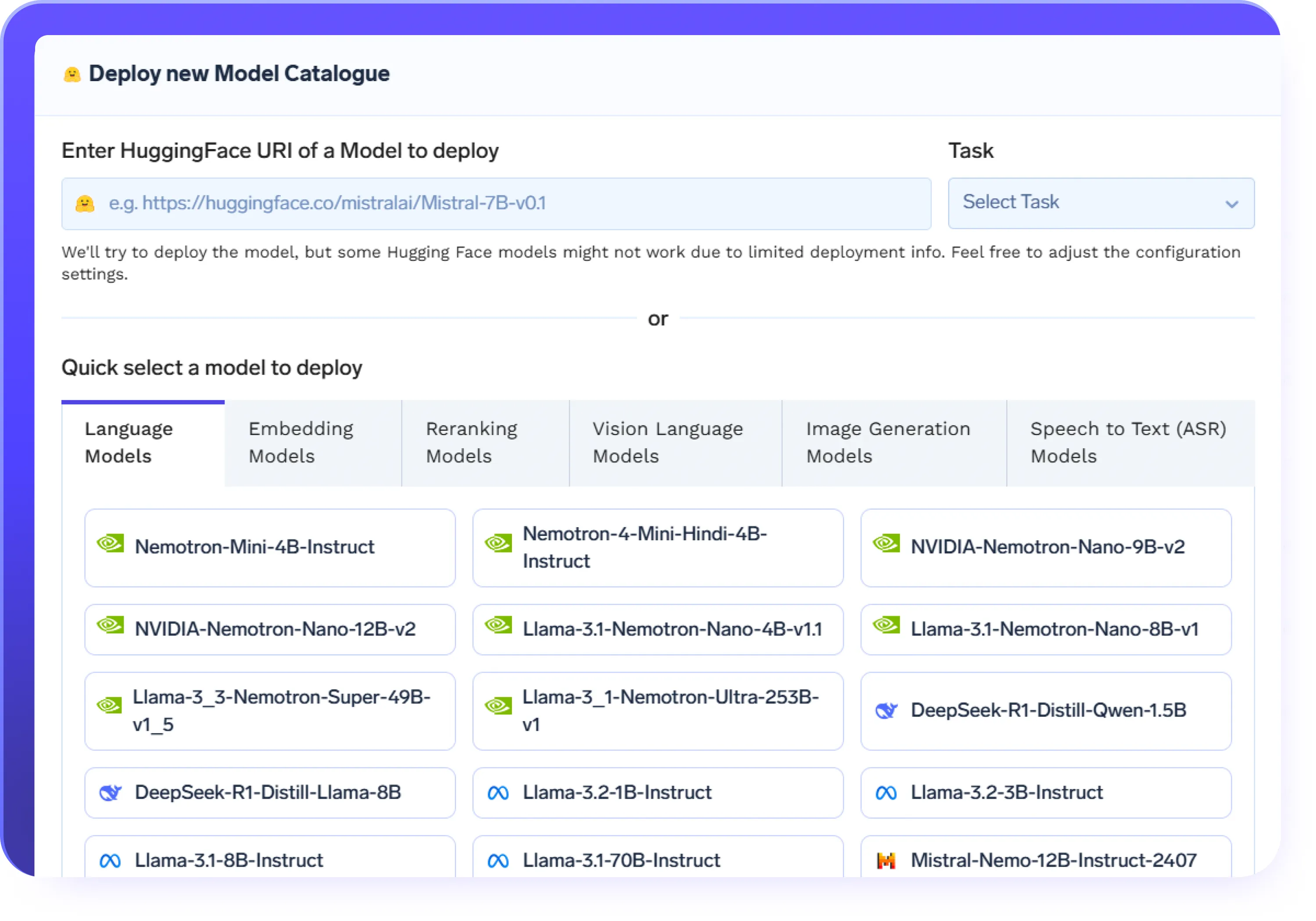
Ajuste Fino de Qualquer Modelo Hugging Face / Modelo de ML Clássico
- Suporta o ajuste fino de LLMs como LLaMA, Mistral, BERT, Falcon e GPT-J
- Comece a fazer o ajuste fino de LLMs em minutos usando o hub de modelos Hugging Face integrado
- Modelos pré-configurados simplificam o processo de ajuste fino de grandes modelos de linguagem
- Infraestrutura escalável gerencia tudo, desde pequenos experimentos até o ajuste fino de LLMs de nível de produção
Sem Código ou Código Completo - Sua Escolha
- Ajuste fino de LLMs usando uma interface de usuário sem código para configuração rápida e iteração ágil
- Traga seus próprios scripts de treinamento com controle total no modo de código
- Gerencie automaticamente a infraestrutura e o dimensionamento de recursos
- Obtenha total transparência em cada execução de ajuste fino, com logs, métricas e controle de versão integrados.
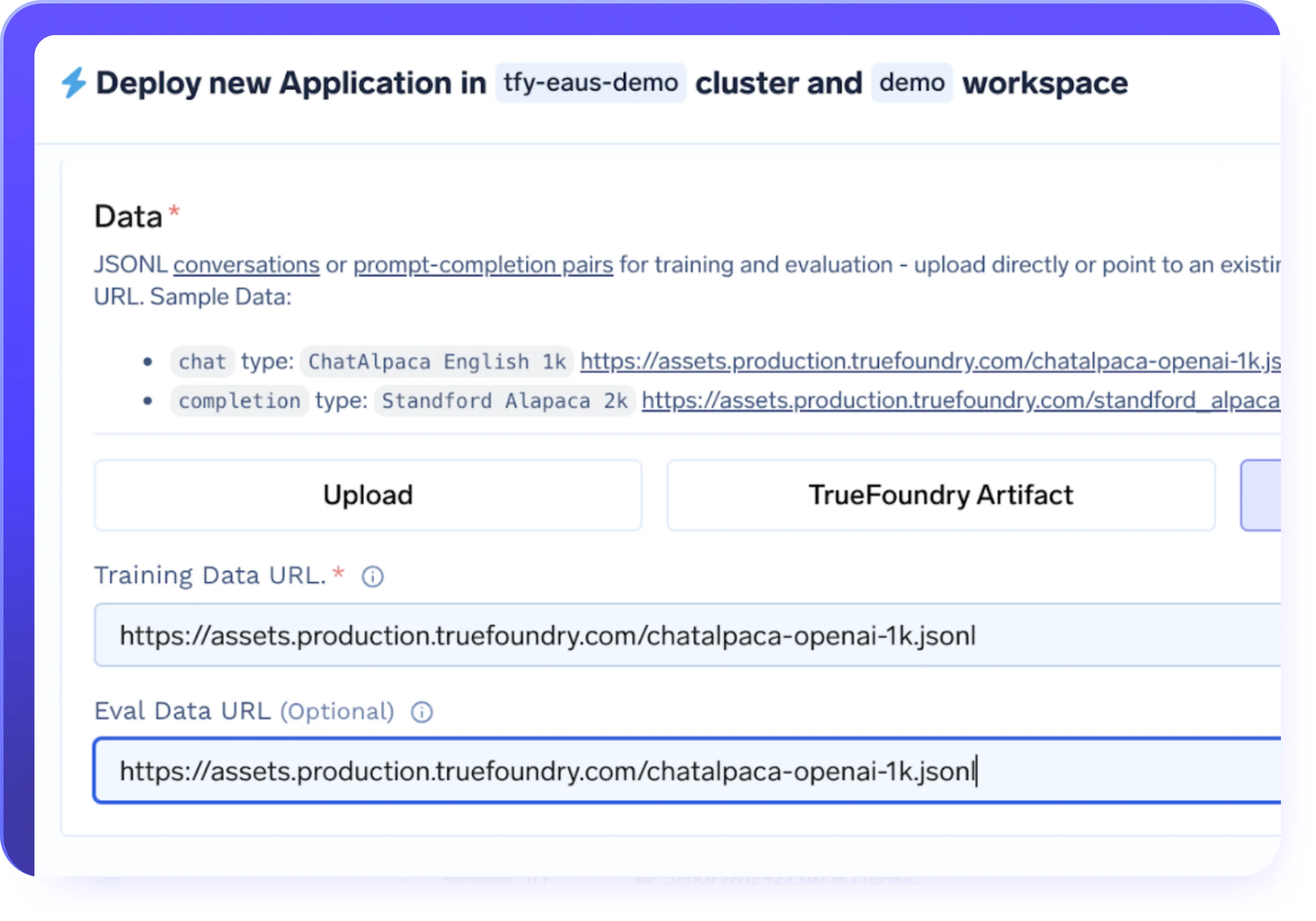
PEFT (LoRA / QLoRA) e Suporte Completo para Ajuste Fino
- Suporte para ajuste fino eficiente em parâmetros (LoRA, QLoRA), bem como ajuste fino de modelo completo
- Escolha LoRA ou QLoRA para um ajuste fino mais rápido e econômico de grandes LLMs
- Reduzir o uso de memória da GPU, mantendo a qualidade e o desempenho do modelo
- Selecione a abordagem de ajuste fino correta com base no tamanho do modelo, custo e necessidades da carga de trabalho
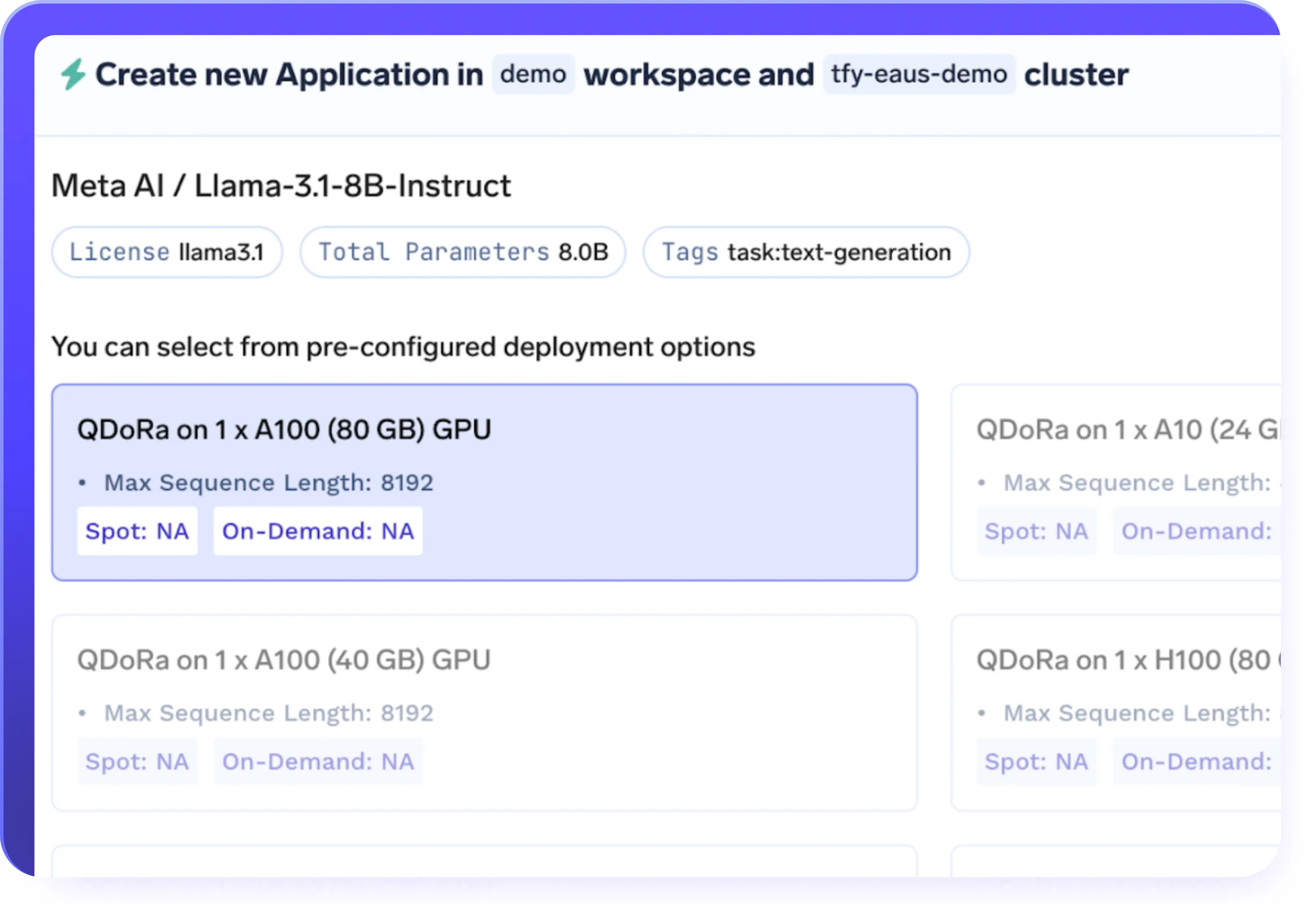
Checkpoints e Versionamento
- Salve checkpoints automaticamente durante o ajuste fino para evitar a perda do progresso do treinamento
- Retome trabalhos de ajuste fino interrompidos ou pausados a partir de qualquer checkpoint
- Versionamento de modelos, conjuntos de dados e execuções de treinamento para total reprodutibilidade
- Reverta para checkpoints anteriores e compare o desempenho entre as versões
Rastreamento de Experimentos Integrado
- Registre automaticamente todos os metadados de treinamento: hiperparâmetros, métricas, conjuntos de dados e saídas
- Compare múltiplas execuções para ajustar LLMs de forma mais eficaz
- Integre-se com sua pilha de LLMops ou use nossa interface visual nativa
- O controle de versão integrado garante reprodutibilidade e auditabilidade
Gerenciamento de Adaptadores para Ajuste Fino Eficiente de LLMs
- Aproveite os adaptadores LoRA para ajustar modelos atualizando apenas um pequeno conjunto de parâmetros.
- Reutilize adaptadores pré-treinados em projetos e domínios
- Mescle ou troque adaptadores entre diferentes tarefas, permitindo experimentação rápida e design de modelo modular
- Acelere o treinamento e reduza os custos treinando módulos adaptadores compactos em vez de pesos completos de LLM
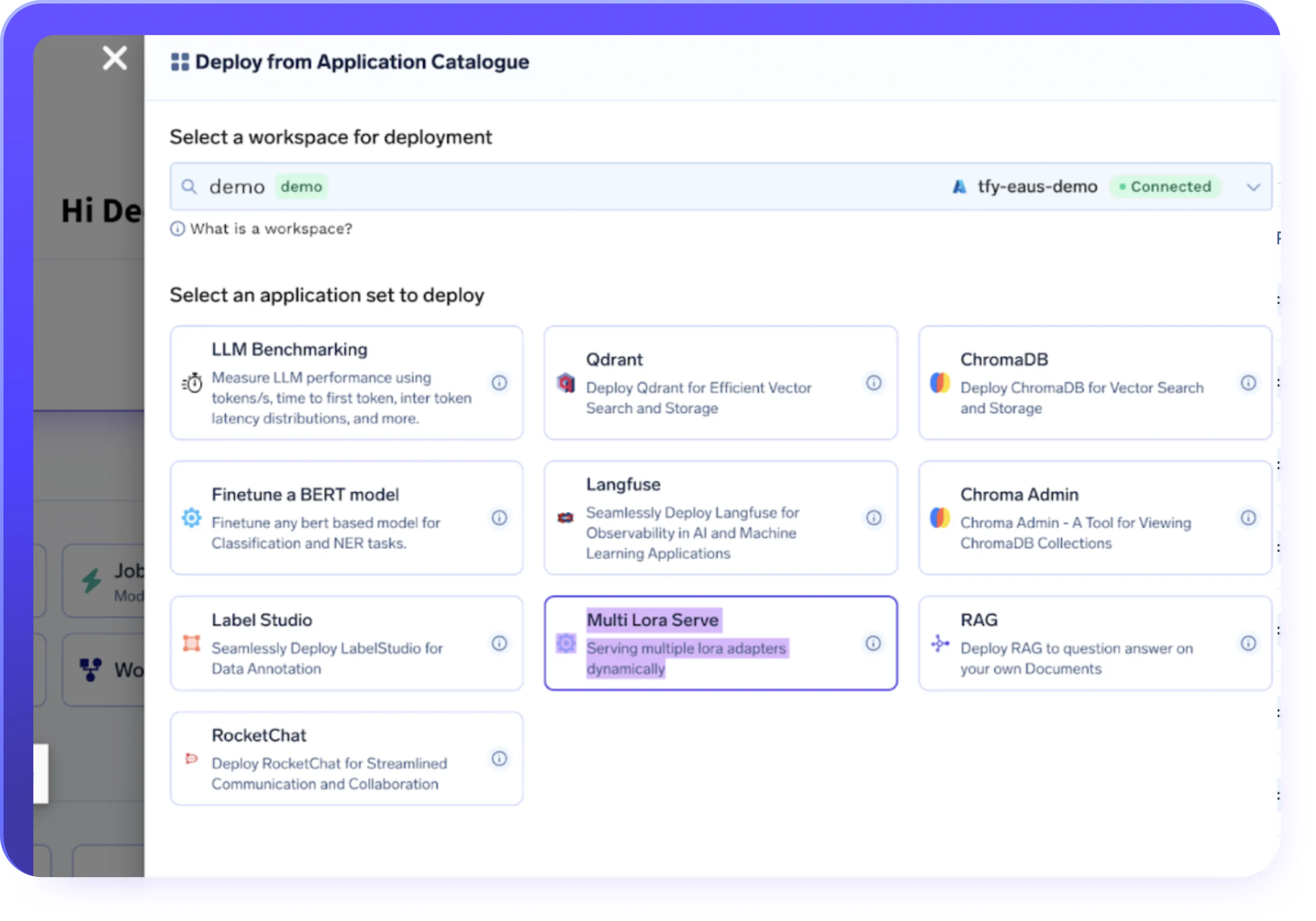
Integrações de Dados e Infraestrutura
- Importe conjuntos de dados do S3, GCS, Azure Blob ou Hugging Face Datasets
- Execute trabalhos de ajuste fino em infraestrutura totalmente gerenciada ou em seus próprios clusters
- Implante cargas de trabalho em ambientes de nuvem, híbridos ou locais
- Use autoescalonamento de GPU, fatiamento de tempo e provisionamento com consciência de custo por padrão
Feito para IA do Mundo Real em Escala
Pronto para Empresas
Implante um gateway de IA seguro que mantém seus dados e modelos dentro da sua infraestrutura em nuvem / on-premise.


Conformidade e Segurança
Padrões SOC 2, HIPAA e GDPR para garantir uma proteção de dados robustaGovernança e Controle de Acesso
SSO + Controle de Acesso Baseado em Função (RBAC) e Registro de AuditoriaSuporte Empresarial e Confiabilidade
Suporte 24/7 com garantia de SLA SLAs de resposta
VPC, on-premise, air-gapped, ou em várias nuvens.
Nenhum dado sai do seu domínio. Desfrute de soberania completa, isolamento e conformidade de nível empresarial onde quer que a TrueFoundry seja executada.


Resultados Reais com a TrueFoundry
Por que as Empresas Escolhem a TrueFoundry






3x
tempo mais rápido para obter valor com agentes LLM autônomos
80%
maior utilização do cluster de GPUs após otimização automatizada de agentes

Aaron Erickson
Fundador, Applied AI Lab
A TrueFoundry transformou nossa frota de GPUs em um motor autônomo e auto-otimizável, impulsionando 80% mais utilização e economizando milhões em computação ociosa.
5x
tempo mais rápido para colocar em produção a plataforma interna de IA/ML
50%
menores gastos com a nuvem após migrar cargas de trabalho para a TrueFoundry

Pratik Agrawal
Diretor Sênior de Ciência de Dados e Inovação em IA
A TrueFoundry nos ajudou a passar da experimentação para a produção em tempo recorde. O que levaria mais de um ano foi feito em meses - com melhor adoção pelos desenvolvedores.
80%
redução no tempo de colocação em produção para modelos
35%
economia de custos na nuvem em comparação com a configuração anterior do SageMaker
.webp)
Vibhas Gejji
Engenheiro de ML Sênior
Reduzimos a carga de DevOps e simplificamos as implantações em produção entre as equipes. A TrueFoundry acelerou a entrega de ML com uma infraestrutura que escala de experimentos a serviços robustos.
50%
implantação mais rápida da pilha RAG/Agente
60%
redução na sobrecarga de manutenção para pipelines RAG/de agente
.webp)
Indroneel G.
Líder de Processos Inteligentes
A TrueFoundry nos ajudou a implantar uma pilha RAG completa - incluindo pipelines, bancos de dados vetoriais, APIs e UI - duas vezes mais rápido, com controle total sobre a infraestrutura auto-hospedada.
60%
implantações de IA mais rápidas
~40-50%
Redução eficaz de custos em todos os ambientes de desenvolvimento
.webp)
Nilav Ghosh
Diretor Sênior de IA
Com a TrueFoundry, reduzimos os prazos de implantação em mais da metade e diminuímos a sobrecarga de infraestrutura por meio de uma interface MLOps unificada — acelerando a entrega de valor.
<2
semanas para migrar todos os modelos de produção
75%
redução no tempo de coordenação de ciência de dados, acelerando atualizações de modelos e lançamentos de recursos
.webp)
Rajat Bansal
CTO
Economizamos muito nos custos de infraestrutura e reduzimos o tempo de coordenação de DS em 75%. A TrueFoundry impulsionou a velocidade de implantação de nossos modelos em todas as equipes.
Perguntas frequentes
O que é ajuste fino de LLMs e por que é importante?
Como a TrueFoundry simplifica o ajuste fino de LLMs?
- Fluxos de trabalho sem código e com código completo: Use uma interface de usuário intuitiva ou scripts de treinamento personalizados
- Rastreamento de experimentos integrado: Registre automaticamente hiperparâmetros, métricas e versões de modelos
- Orquestração de infraestrutura: Execute tarefas na infraestrutura gerenciada pela TrueFoundry ou na sua própria nuvem/VPC
- Suporte para métodos PEFT: Suporte nativo para ajuste fino baseado em LoRA e QLoRA
- Checkpointing e versionamento: Retome o treinamento sem interrupções e mantenha a reprodutibilidade
- Gerenciamento de adaptadores: Reutilize, mescle ou implante adaptadores em várias tarefas/modelos
Que tipos de modelos posso ajustar finamente no TrueFoundry?
- LLMs baseados em decodificador (por exemplo, LLaMA, GPT-J, Falcon, Mistral)
- Modelos codificadores (por exemplo, BERT, RoBERTa, DistilBERT)
- Modelos codificador-decodificador (por exemplo, T5, FLAN-T5)
Posso trazer meu próprio conjunto de dados e código de treinamento?
- Traga seus próprios conjuntos de dados do S3, GCS, Azure, Hugging Face Hub ou arquivos locais
- Traga seu próprio código através de scripts de treinamento personalizados (PyTorch, Transformers, PEFT, etc.)
- Ou use modelos prontos para fluxos de trabalho comuns de ajuste fino
Como o TrueFoundry oferece suporte ao ajuste fino de LoRA e QLoRA?
- Use nossa UI para configurar camadas LoRA e hiperparâmetros
- Salve e implante adaptadores LoRA independentemente dos modelos base
- Mesclar adaptadores com modelos base para implantação ou inferência offline
- Reduza drasticamente o uso de memória da GPU — ideal para empresas que otimizam os gastos com infraestrutura
Posso implantar modelos ajustados da TrueFoundry em produção?
- Implante modelos com vLLM, SGLang ou outros servidores de inferência
- Exponha seu modelo como uma API com limitação de taxa integrada e RBAC
- Monitore a latência em tempo real, o uso de tokens e o desempenho
- Use adaptadores para implantação rápida ou mescle com o modelo base para inferência autônoma

Infra GenAI - simples, mais rápida, mais barata
Confiado por mais de 30 empresas e companhias da Fortune 500








