



.webp)
July 3, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 25, 2026

Blazingly fast way to build, track and deploy your models!
CI/CD tornou-se silenciosamente uma das maiores linhas de custo de LLM em organizações de engenharia modernas. Um único agente de revisão de segurança acionado em cada pull request pode gastar três vezes mais do que toda a carga de trabalho de IA voltada para o cliente da equipe de engenharia. A fatura do provedor informa o total. Ela não informa qual pipeline, qual repositório ou qual etapa do agente o causou. Sem essa atribuição, a única resposta disponível é uma proibição geral, e a perda de produtividade excede o estouro de orçamento original.
O AI Gateway da TrueFoundry preenche essa lacuna com três primitivos — marcação de metadados obrigatória em cada solicitação, orçamentos hierárquicos por centro de custo com limites flexíveis, restritos e rígidos, e uma previsão P95 contínua que revela estouros de orçamento antes que cheguem à fatura. As configurações neste post são reais, podem ser copiadas e coladas, e são baseadas no oficial da TrueFoundry Limitação de Orçamento e Limitação de Taxa esquemas.
Aplicações LLM em produção rodam com tráfego de usuário, que é limitado pelo número de usuários e frequência de solicitações. Pipelines de CI/CD rodam com tráfego de máquina — agentes automatizados, jobs agendados, regressões periódicas, revisões de cada PR. O perfil de custo é fundamentalmente diferente. Uma equipe de 50 engenheiros, cada um abrindo 15 pull requests por semana, gera 750 invocações de LLM impulsionadas por PR por semana antes que qualquer pessoa toque em um recurso voltado para o usuário. Cada invocação pode encadear quatro ou cinco etapas de agente. Cada etapa pode fazer múltiplas chamadas de modelo com contextos de milhares de tokens. O multiplicador de throughput entre IA voltada para o usuário e IA de CI/CD é rotineiramente de 10x a 100x.
A primeira vez que a liderança de engenharia percebe é quando o financeiro encaminha uma fatura com um número que não corresponde ao modelo mental de ninguém. A história se repete em toda organização que implementa CI/CD com agentes sem observabilidade: Outubro é uma conta pequena, novembro é média, dezembro é o mês que leva a uma reunião executiva. O padrão é consistente o suficiente para que as equipes de plataforma o tratem como a expectativa operacional, e não como uma surpresa.
A fatura do provedor — Anthropic, OpenAI, Bedrock ou qualquer outro — detalha por modelo e tipo de token. Ela não pode detalhar por repositório, por pipeline ou por etapa do agente, porque o provedor não sabe o que esses conceitos significam dentro da sua organização de engenharia. Essa informação reside nos metadados da sua solicitação, que o provedor nunca vê. Da perspectiva do provedor, todos os 847 milhões de tokens de entrada Sonnet do mês passado parecem idênticos; da sua perspectiva, 80% deles vieram de um pipeline descontrolado que você teria limitado na primeira semana se soubesse.
A incompatibilidade entre o que o financeiro recebe e o que a engenharia precisa para depurar é a razão estrutural pela qual os projetos de governança de custos estagnam. O financeiro recebe uma conta. A engenharia recebe a mesma conta sem detalhamento. Sem um registro por carga de trabalho, a resposta se resume a "pare de gastar com IA por duas semanas enquanto resolvemos isso", o que anula o ganho de produtividade que a IA estava gerando.
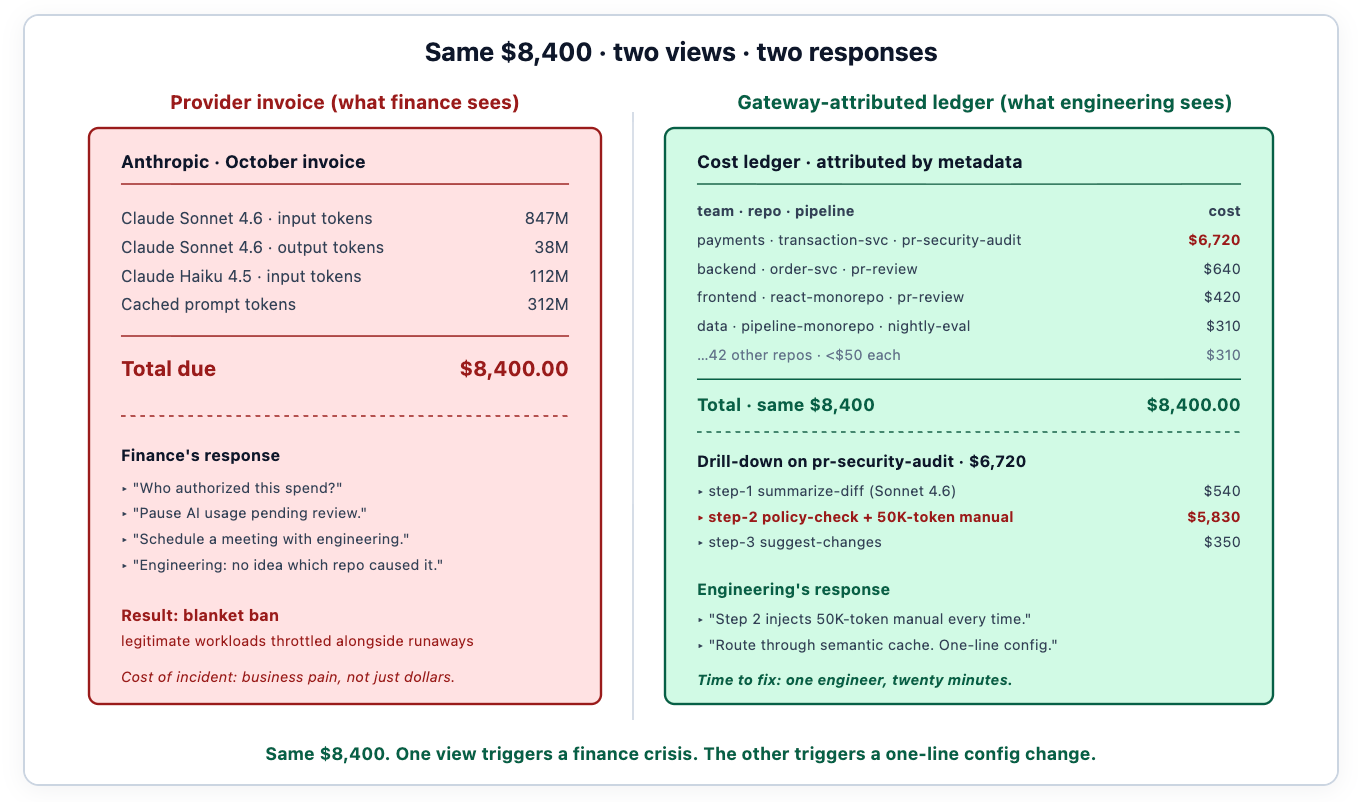
O mesmo valor monetário produz respostas opostas dependendo se a equipe tem atribuição. Sem ela, a resposta é estrutural: proibir o gasto, escalar para a liderança, agendar uma reunião que será desagradável para todos. Com ela, a resposta é um engenheiro lendo o registro de custos, identificando que a etapa 2 de um pipeline específico está injetando um manual de política de 50.000 tokens em cada prompt, e escrevendo uma alteração de configuração de uma linha para rotear a etapa 2 através do cache semântico. Mesma fatura. Resultado diferente.
A base da atribuição de custos é a marcação obrigatória no gateway. Pipelines de CI/CD precisam injetar identidade em cada solicitação — identificando a equipe, o repositório, o pipeline, a etapa do agente e o centro de custo responsável. De acordo com o da TrueFoundry documentação de cabeçalhos de requisição, essa identidade viaja em um único cabeçalho — x-tfy-metadata — cujo valor é um objeto JSON serializado com chaves e valores de string, limitado a 128 caracteres por valor. Os campos dentro do JSON são convenções escolhidas pela equipe da plataforma; eles não são cabeçalhos HTTP por si só.
Uma requisição corretamente formada de um pipeline de CI/CD se parece com isto na rede:
POST /api/llm/api/inference/openai/chat/completions HTTP/1.1
Host: gateway.truefoundry.ai
Authorization: Bearer {TFY_API_KEY}
Content-Type: application/json
x-tfy-metadata: {"team":"payments-platform","repo":"transaction-service","pipeline":"pr-security-audit","agent_step":"step-2-policy-check","cost_center":"eng-backend","run_id":"gh-run-882134"}A documentação do gateway enumera exatamente nove cabeçalhos de requisição personalizados aceitos: Authorization, x-tfy-metadata, x-tfy-provider-name, x-tfy-strict-openai, x-tfy-retry-config, x-tfy-request-timeout, x-tfy-ttft-timeout-ms, x-tfy-logging-config, e x-tfy-mcp-headers. A identidade personalizada — equipe, repositório, pipeline, centro_de_custo, run_id, ou qualquer outra coisa que a equipe da plataforma defina — reside estritamente dentro do valor JSON de x-tfy-metadata, não como cabeçalhos separados. Este é o único contrato que o gateway reconhece. Equipes que inventam cabeçalhos adicionais x-tfy-* descobrem que são ignorados silenciosamente — os metadados nunca chegam às camadas de rastreamento de custos ou de políticas, os painéis perdem a atribuição e os logs de auditoria contêm apenas o token de portador. Um cabeçalho, JSON dentro, é a regra.
Visibilidade sem aplicação é um painel que ninguém usa. O gateway atribui orçamentos hierárquicos e matematicamente impostos a cada centro de custo que a marcação produz. A equipe da plataforma de pagamentos recebe, por exemplo, US$ 500 por semana para fluxos de trabalho agentivos de CI/CD; esse orçamento é aplicado no gateway, no caminho da solicitação, com três limites que disparam respostas diferentes.
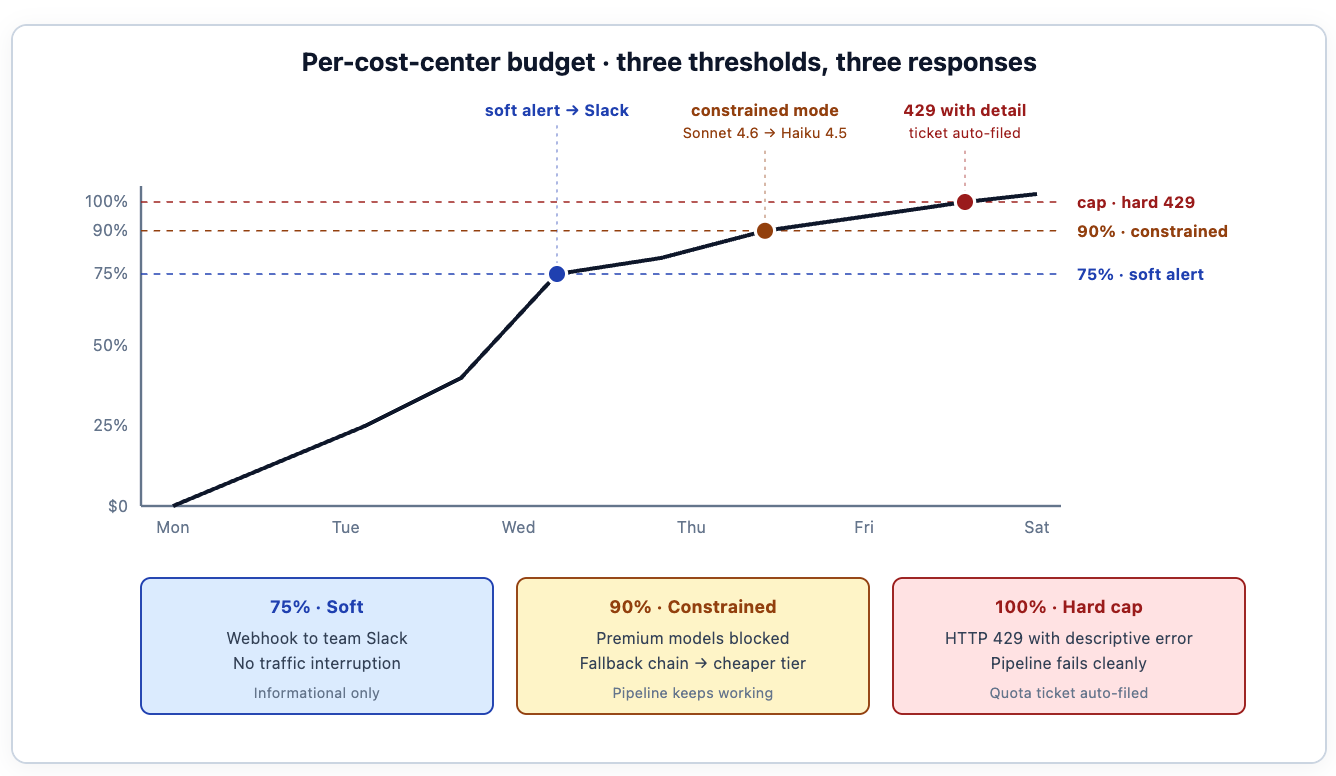
75% do limite — alerta suave. Um webhook publica no canal Slack da equipe: "Você já usou três quartos do orçamento de IA desta semana." Nenhuma interrupção de tráfego. O proprietário da carga de trabalho vê o alerta durante o horário de trabalho normal e pode decidir se ajusta o comportamento do agente, solicita um aumento de cota ou não faz nada porque o gasto é legítimo.
90% — modo restrito. Modelos premium (Sonnet 4.6, Opus 4.7, GPT-4o) são bloqueados; o gateway roteia transparentemente as solicitações para alternativas mais baratas (Haiku 4.5, GPT-4o-mini) através da configuração de fallback de modelo virtual, para que os pipelines continuem funcionando enquanto os custos se estabilizam. A cadeia de fallback é definida em uma configuração de roteamento separada — a configuração de orçamento aciona a restrição, a configuração de roteamento executa a troca. A aplicação vê um cabeçalho indicando qual modelo realmente atendeu à solicitação, e a qualidade pode diferir para cargas de trabalho específicas.
100% — limite máximo. O gateway rejeita solicitações adicionais com HTTP 429. Abaixo está o formato que as equipes de plataforma tipicamente projetam para o corpo do erro — a resposta padrão do gateway é concisa, e a equipe a enriquece através de sua camada de encapsulamento com o contexto do centro de custo, o ponteiro do painel e o fluxo de solicitação de cota:
{
"error": "Budget Exceeded",
"detail": "Cost center 'eng-backend' has exhausted its weekly $500 AI budget.",
"context": {
"spent_to_date": "$501.23",
"cap": "$500.00",
"resets_at": "2026-05-19T00:00:00Z",
"top_consumer": "pipeline=pr-security-audit · 87% of spend"
},
"mitigation": "Review pipeline logs for runaway loops, or request a quota increase at /governance/quota."
}O corpo do erro faz parte do design. Um pipeline que atinge seu orçamento deve saber o que fazer em seguida — ler os logs, registrar uma solicitação de cota — sem que o desenvolvedor precise procurar a equipe da plataforma para obter contexto. Os executores de CI interpretam 429 como um sinal de backoff padrão; a compilação falha de forma limpa com uma mensagem acionável, em vez de travar de maneiras confusas. O mesmo padrão 429 se compõe com as camadas de limite de taxa e detecção de fuga, de modo que uma carga de trabalho que excede múltiplos controles recebe um caminho de falha coerente, em vez de uma cascata de erros não relacionados.
Dados marcados fluindo para o Grafana permitem que a equipe da plataforma construa painéis que respondem a perguntas de propriedade em vez de gerar mais ruído agregado. Em vez de olhar para um pico e perguntar "quem fez isso?", o painel já informa que às 02:00 UTC a equipe de frontend implantou um novo agente em react-monorepo que alucinou uma dependência ausente e entrou em um loop de resolução de 400 etapas. Os campos de metadados aparecem como rótulos do Prometheus; consultas PromQL padrão produzem detalhamentos por equipe, por repositório, por pipeline; dashboards Grafana padrão os visualizam.
Esse tipo de contexto operacional transforma o custo de um problema financeiro em um problema de engenharia. Uma vez que a equipe consegue ver que a mudança da etapa inicial de sumarização de código do Sonnet 4.6 para o Haiku 4.5 reduz o custo dessa etapa em 80% sem afetar a qualidade da revisão de PR, eles fazem a alteração. A discussão sobre limites orçamentários não precisa acontecer em um comitê de direção — os dados são o argumento, e a mudança é a resposta.
Um dashboard útil tem três visualizações: um custo agregado por centro de custo ao longo do tempo, um detalhamento por pipeline e etapa, e uma visualização de anomalias que identifica automaticamente os valores atípicos de custo. As duas primeiras são as visualizações operacionais; a terceira é a visualização de alerta precoce que encontra os desvios antes que o limite orçamentário seja atingido. Os rastreamentos OpenTelemetry emitidos pelo gateway incluem o modelo, a contagem de tokens, os campos de metadados e o valor em dólar por chamada — as ferramentas existentes do Grafana cuidam do resto.
Dados de marcação agregados também tornam a previsão viável. Cargas de trabalho agentivas são intermitentes — trabalhos pesados e periódicos de CI dominam a fatura — e é por isso que médias móveis simples subestimam sistematicamente os gastos. Uma equipe que teve uma média de US$ 40/dia por três semanas e US$ 400 em uma única execução de release-train de quarta-feira tem uma média móvel de US$ 51/dia; seus gastos reais no final do mês, se eles lançarem mais dois release-trains, ultrapassam os US$ 2.000.
O gateway executa uma previsão móvel P95 de 7 dias por repositório e por centro de custo. O P95 captura o risco de picos que uma média suaviza, projetando os gastos do final do mês com tempo suficiente para ajustar orçamentos, aumentar cotas ou desativar um pipeline problemático antes que o financeiro perceba a surpresa. "Surpresa" é a palavra-chave: esta é uma previsão projetada para não produzi-las. Quando a previsão indica que uma equipe está a caminho de exceder seu orçamento mensal em 30%, a equipe tem duas ou três semanas de margem para agir antes que o limite máximo seja acionado.
A previsão aparece no mesmo dashboard Grafana que os gastos em tempo real, com a projeção desenhada ao lado da curva histórica. Equipes de plataforma que revisam a previsão semanalmente identificam o padrão que produz a crise orçamentária do próximo trimestre; equipes que não revisam a previsão ficam sabendo do problema da mesma forma que sempre souberam — pelo financeiro.
O que se segue é um exemplo composto ilustrativo, extraído de padrões que esta equipe observou em implementações reais de clientes — os números são estilizados para deixar a mecânica clara, mas o modo de falha e a correção são ambos comuns.
Uma organização com 50 engenheiros construiu um agente de revisão de código Claude de três etapas que era executado em cada pull request: (1) resumir o diff, (2) revisar o diff em relação às políticas de segurança via um servidor de documentação MCP, (3) sugerir alterações de código. Arquitetura sensata, fluxo de trabalho útil, sem bandeiras vermelhas óbvias. O agente entrou em produção no início de setembro.
Com aproximadamente 15 PRs por engenheiro por semana, considerando as tentativas e o custo da janela de contexto de injetar arquivos inteiros nos prompts, o agente teve uma média de cerca de 400.000 tokens de entrada por PR. Fatura do primeiro mês para automação CI/CD: US$ 8.400. A fatura chegou em 5 de outubro. A mensagem do Slack do financeiro chegou em 6 de outubro. A conversa que gerou esta publicação chegou em 7 de outubro.
A atribuição revelou a causa real minutos depois de a equipe fazer login no dashboard de custos. A Etapa 2 estava injetando um manual de segurança de 50.000 tokens em cada prompt, em cada PR, independentemente de o diff realmente tocar em código relevante para a política. O modelo estava lendo o manual inteiro para avaliar se deveria aplicá-lo; a resposta era "não, esta é uma mudança de CSS" 80% das vezes; o custo era pago todas as vezes. Encaminhando a etapa 2 através do gateway da cache semântica — indexado pela extensão do arquivo e assinatura de conteúdo do diff — reduziu a sobrecarga de tokens em 92%. Mesma cobertura. Mesmas sugestões. Fatura mensal abaixo de US$ 800.
Sem atribuição, a resposta teria sido uma proibição geral do Sonnet para fluxos de trabalho de CI. A engenharia teria absorvido o impacto na produtividade; o financeiro teria absorvido a vitória política; ninguém teria aprendido qual era o problema real. Com atribuição, a resposta foi uma alteração de configuração de uma linha. Essa é a diferença que os dados fazem.
Duas configurações de política do TrueFoundry sustentam todo o padrão: uma configuração de orçamento que impõe limites de dólar com modos de auditoria e alertas, e uma configuração de limite de taxa que impõe cotas de tokens e requisições. Ambos são esquemas reais — copie-os diretamente para o AI Gateway Políticas guia. A referência do esquema está na documentação oficial para Limitação de Orçamento e Limitação de Taxa. Dois pontos semânticos a internalizar antes de implantá-los:
Primeiro, sobre ordem das regras e rastreamento em camadas: de acordo com a documentação de orçamento da TrueFoundry, quando uma solicitação corresponde a várias regras, o custo é rastreado em relação a cada regra correspondente, mas apenas a primeira regra correspondente controla a decisão de permitir/bloquear. A ordem das regras no YAML determina a prioridade — não há um campo de prioridade separado. Na configuração abaixo, uma solicitação da plataforma de pagamentos corresponde tanto à regra específica payments-platform-weekly (primeira correspondência, controla a decisão de bloqueio) quanto à regra ampla per-user-daily-default (também rastreia o custo, útil para visibilidade por desenvolvedor). Isso é intencional: o painel mostra tanto o uso em nível de centro de custo quanto em nível de usuário na mesma solicitação.
Segundo, sobre nomenclatura da conta do provedor: identificadores de modelo como anthropic-main/claude-opus-4-7 seguem o formato <provider-account-name>/<model-id>, onde o nome da conta do provedor é o que o administrador do espaço de trabalho nomeou a conta Anthropic em Gateway de IA → Modelos. A parte do ID do modelo é fixa pela Anthropic. Verifique o nome da conta do provedor na sua instância específica do TrueFoundry antes de copiar e colar.
Configuração de orçamento — aplicação de limites em dólares por centro de custo, com modo de auditoria para implementação segura:
name: cicd-budget-config
type: gateway-budget-config
rules:
# Priority 1 (first in list = first match): payments-platform — higher cap
- id: 'payments-platform-weekly'
when:
metadata:
cost_center: 'eng-backend-payments'
limit_to: 800
unit: cost_per_week
audit_mode: false # enforce: block on exceed
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: slack-bot
notification_channel: 'eng-alerts-channel'
channels: ['#eng-backend-ai']
# Priority 2: data team — lighter cap, longer period
- id: 'data-team-monthly'
when:
metadata:
cost_center: 'eng-data'
limit_to: 2000
unit: cost_per_month
audit_mode: false
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: email
notification_channel: 'data-alerts'
to_emails: ['data-platform-lead@example.com']
# Priority 3: intern sandbox — hard cap, no exceptions
- id: 'intern-sandbox-weekly'
when:
metadata:
cost_center: 'intern-sandbox'
limit_to: 50
unit: cost_per_week
audit_mode: false
alerts:
thresholds: [100]
notification_target:
- type: slack-bot
notification_channel: 'platform-alerts'
channels: ['#platform-budgets']
# Default per-user safety net — $20/day per individual developer.
# Tracks against every request (layered), controls block only for requests
# that don't match a higher-priority rule above.
- id: 'per-user-daily-default'
when: {}
limit_to: 20
unit: cost_per_day
budget_applies_per: ['user']
audit_mode: true # audit-only during initial rollout
alerts:
thresholds: [90, 100]
notification_target:
- type: slack-bot
notification_channel: 'platform-alerts'
channels: ['#platform-budgets']Configuração de limite de taxa — cotas de requisições e tokens, a segunda linha de defesa:
name: cicd-ratelimiting-config
type: gateway-rate-limiting-config
rules:
# Per-pipeline token ceiling: prevents runaway agents.
# metadata.pipeline accesses the 'pipeline' field inside x-tfy-metadata JSON.
- id: 'pipeline-hourly-token-cap'
when: {}
limit_to: 500000
unit: tokens_per_hour
rate_limit_applies_per: ['metadata.pipeline']
# Per-user request floor: stops developer mistakes from going viral
- id: 'per-user-daily-requests'
when: {}
limit_to: 5000
unit: requests_per_day
rate_limit_applies_per: ['user']
# Premium-model brake: caps Opus consumption per cost center.
# Replace 'anthropic-main' below with your workspace's Anthropic
# provider-account name (see AI Gateway → Models in the dashboard).
- id: 'opus-per-cost-center-daily'
when:
models: ['anthropic-main/claude-opus-4-7']
limit_to: 200000
unit: tokens_per_day
rate_limit_applies_per: ['metadata.cost_center']Ambas as configurações são controladas por versão, revisadas em pull requests e aplicadas através do mesmo fluxo GitOps que a equipe da plataforma usa para o restante do gateway. Os esquemas acima correspondem exatamente à documentação oficial — cada campo, cada valor, cada rate_limit_applies_per entrada é documentada e suportada. As equipes de workload propõem alterações em suas próprias entradas de centro de custo através de pull requests; a equipe da plataforma aprova; o gateway capta a alteração em seu próximo ciclo de reconciliação.
A audit_mode: true configuração na regra padrão por usuário é o primitivo de segurança que vale a pena destacar. Durante a implementação, o modo de auditoria permite que a regra rastreie gastos reais e dispare alertas sem bloquear qualquer tráfego. Após uma ou duas semanas de observação, a equipe muda audit_mode para false para aplicar. Este é o caminho de menor risco para um sistema de aplicação de orçamento de nível de produção: observe primeiro, aplique depois, e nunca aplique um número que você ainda não viu o tráfego real produzir.
O caso de organização única, onde cada centro de custo pertence a uma empresa, é o mais fácil. Muitas implantações de IA em produção são multi-inquilino: um produto SaaS B2B oferece recursos de IA aos seus próprios clientes, e a fatura de IA precisa ser alocada por inquilino antes que a empresa saiba quais clientes são lucrativos e quais são subsidiados. A camada de atribuição de custos é o que torna essa pergunta respondível.
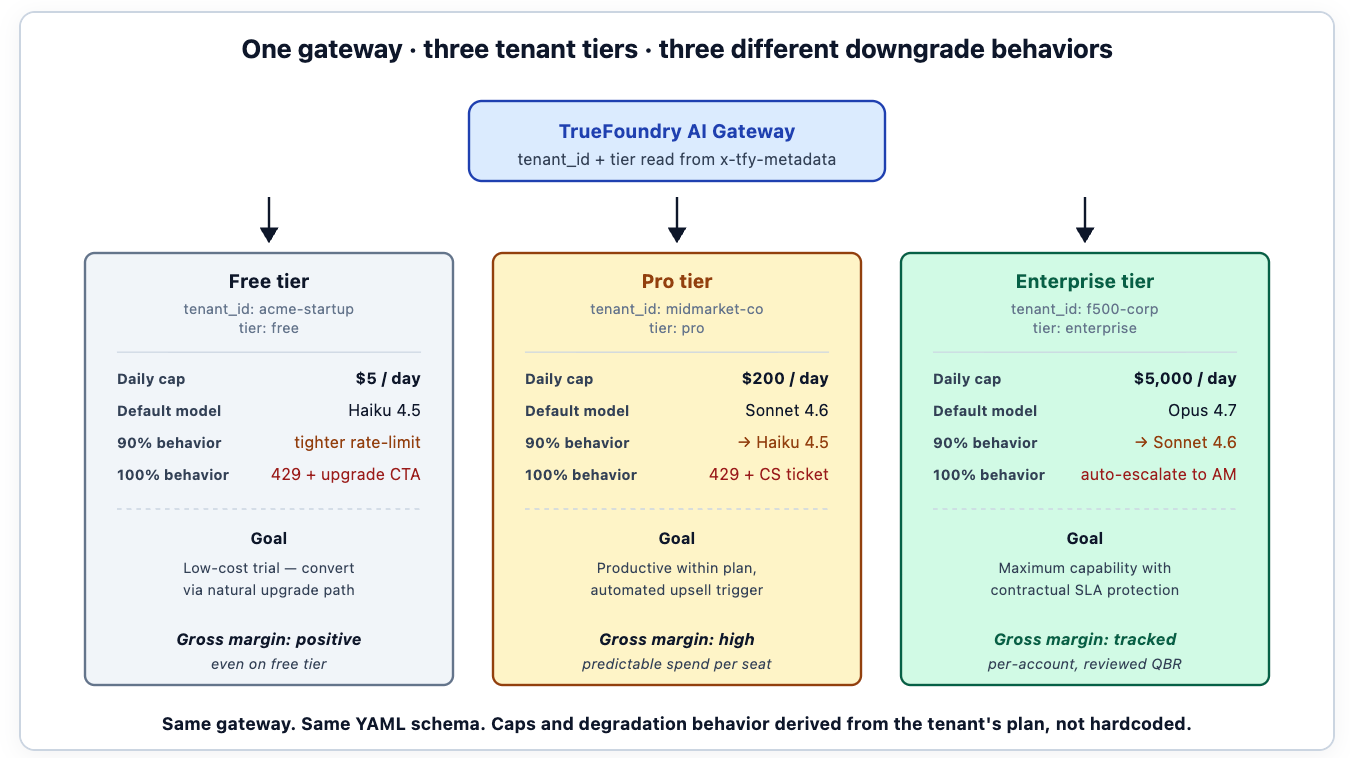
O padrão que funciona adiciona tenant_id como outro campo no envelope de metadados. A chave do bucket para orçamentação torna-se a combinação de tenant_id e carga de trabalho; o painel suporta uma visualização por inquilino ao lado da visualização por centro de custo; o relatório FinOps associa dados do gateway ao sistema de faturamento da empresa para produzir a margem bruta por inquilino. Um inquilino cujo consumo de IA excede o seu nível de plano aparece no painel antes que o sucesso do cliente precise iniciar a conversa.
Limites orçamentários sensíveis ao nível são o segundo padrão. O inquilino do nível gratuito recebe um limite mais apertado do que o inquilino do nível empresarial; os limites são derivados do plano do inquilino, em vez de serem codificados. Quando um inquilino faz um upgrade, o limite é atualizado sem alterações no código — o plano é metadados na identidade do inquilino, o limite é uma função do plano. Equipes que codificam limites acabam reescrevendo-os toda vez que os preços mudam; equipes que os derivam dos dados do inquilino herdam o comportamento correto automaticamente.
O terceiro padrão: modos degradados, mas funcionais, por nível. O modo restrito do inquilino de nível empresarial pode mantê-los em um modelo de fronteira com limitação de taxa mais rigorosa; o modo restrito do inquilino de nível gratuito pode direcioná-los para um modelo pequeno auto-hospedado. Mesmo gateway, diferentes cadeias de downgrade, expressas como configuração. A estrutura de preços da empresa B2B SaaS aparece diretamente na configuração do gateway — que é o lugar certo para isso.
Quatro erros de configuração aparecem regularmente nas primeiras tentativas das equipes de atribuição de custos. Cada um produz um modo de falha diferente que vale a pena conhecer.
Marcação opcional. A equipe configura o gateway para registrar solicitações não marcadas, mas as permite passar, com a intenção de aplicar a regra mais tarde. O "mais tarde" não chega, e o painel acumula um bucket "desconhecido" que cresce mês a mês. Quando a aplicação da regra é ativada, metade do tráfego está no bucket desconhecido e quebrá-lo é politicamente caro. A solução é aplicar a rejeição a partir da segunda semana, quando o tráfego visível ainda é pequeno.
Criar cabeçalhos adicionais. As equipes às vezes tentam distribuir a identidade por vários cabeçalhos — cabeçalhos separados para equipe, repositório, centro de custo e assim por diante. O gateway reconhece exatamente nove cabeçalhos personalizados, listados anteriormente nesta publicação; os restantes são ignorados silenciosamente. Toda a identidade personalizada pertence ao valor JSON de x-tfy-metadata. Um cabeçalho. JSON dentro. O contrato é documentado e o gateway o aplica.
Centros de custo que abrangem equipes. Um centro de custo como shared-infra parece uma abstração limpa, mas não gera responsabilidade de engenharia quando excede o orçamento — não há equipe para acionar. Os centros de custo devem mapear para a área de responsabilidade de uma equipe; o trabalho compartilhado pertence a um centro de custo de "plataforma" de propriedade da equipe de plataforma, e não a um bucket compartilhado vago.
Limites rígidos sem erros descritivos. Um 429 com corpo {"error": "rate_limited"} não informa nada acionável ao desenvolvedor. Um 429 com o centro de custo, o limite, o principal consumidor e um link para o fluxo de solicitação de cota diz a eles exatamente o que fazer. O esquema do corpo do erro é uma das partes mais ajustadas da configuração em qualquer implantação madura.
A atribuição de custos é uma das implementações mais seguras no espaço de plataformas de IA, porque o modo de falha de "orçamento mal calibrado" é limitado (alguns pipelines atingem o modo restrito inesperadamente) e o modo de falha de "nenhuma atribuição" é catastrófico (a conta descontrolada). A sequência correta é observar primeiro, aplicar depois.

Semana 1 — Marcação em modo de auditoria. Atualize os modelos de CI para injetar x-tfy-metadata em cada solicitação. Configure o gateway para registrar solicitações não marcadas como avisos, mas as deixe passar. O painel no final da semana informa à equipe o padrão natural de seus gastos: quais pipelines dominam, quais centros de custo são os usuários mais intensivos, quais modelos as cargas de trabalho realmente preferem. Estes são os dados que informam a calibração do orçamento.
Semana 2 — Rejeitar solicitações não marcadas. Altere o gateway para retornar 400 para solicitações não marcadas. Os modelos de CI atualizados na semana 1 são os únicos clientes legítimos; qualquer resposta 400 indica um modelo não atualizado ou um chamador fora de banda que precisa ser tratado. Até o final da semana 2, cada solicitação em produção está marcada.
Semanas 3-4 — Configurar orçamentos em modo de auditoria. Implante a configuração de orçamento com audit_mode: true em todas as regras. Defina os limites flexíveis (75%) em relação ao P95 observado de gastos legítimos mais margem. Alertas são disparados para os canais do Slack da equipe; nenhuma ação de aplicação é acionada ainda. A equipe observa quais limites são razoáveis e quais precisam de ajuste. Algumas cargas de trabalho parecerão estar em uma trajetória descontrolada; uma ou duas realmente estarão, e a equipe pode intervir antes que a aplicação comece.
Semana 5 — Habilitar aplicação. Altere audit_mode para false sobre as regras orçamentárias. Ative a cadeia de degradação de 90% (configuração de fallback de modelo virtual emparelhado) e o limite máximo de 100%. A cadeia de degradação é a mudança mais controversa para os proprietários de cargas de trabalho — algumas equipes preferem fortemente "falhar rapidamente" a "degradado, mas funcionando" para seus pipelines. Torne a cadeia configurável por centro de custo desde o início, para que cada equipe possa escolher seu comportamento preferido.
Semana 6+ — Previsão e cadência de revisão. Ative a previsão P95 de 7 dias. Configure uma revisão semanal da previsão pela equipe da plataforma em relação aos orçamentos. Novos centros de custo são padronizados com limites iniciais razoáveis com base no uso inicial observado; as alterações de cota são feitas por meio de pull requests na configuração. O sistema funciona como infraestrutura, não como um projeto.
A camada de atribuição de custos precisa de um limite de propriedade claro porque os dados que ela produz chegam a vários stakeholders ao mesmo tempo. A divisão correta é: a equipe da plataforma é proprietária da camada, as equipes de carga de trabalho são proprietárias de seus orçamentos, o financeiro é proprietário da visão estratégica, a liderança de engenharia é proprietária da política.
A equipe da plataforma opera o gateway, a disciplina de marcação, o motor de orçamento e a previsão. Eles revisam e aprovam solicitações de cota, ajustam as cadeias de degradação com base no feedback de qualidade dos proprietários de cargas de trabalho e triam os alertas que disparam fora do horário comercial. O trabalho deles é fazer o sistema funcionar; eles não decidem quanto cada carga de trabalho deve custar.
As equipes de carga de trabalho são proprietárias de sua própria entrada de centro de custo na configuração. Eles propõem alterações orçamentárias por meio de pull requests; ajustam seus pipelines quando atingem alertas suaves; escolhem entre o comportamento degradado-mas-funcional e o fail-fast para sua resposta de limite máximo. A equipe da plataforma aprova; a equipe de carga de trabalho executa.
A liderança financeira e de engenharia consome as visões agregadas. As chamadas de fechamento mensais citam centros de custo específicos e pipelines específicos, em vez de números agregados. O planejamento trimestral usa a previsão para projetar os gastos com infraestrutura de IA; os ciclos orçamentários tornam-se previsíveis em vez de reativos. Esta é a propriedade que torna o gasto com IA um item orçamentário planejado, em vez de uma surpresa recorrente.
A marcação obrigatória não substitui a engenharia de prompts. Uma carga de trabalho que injeta um manual de 50.000 tokens em cada prompt verá a tag dizer exatamente qual carga de trabalho é cara; ela não dirá como corrigi-la. A correção — um manual menor, um cache, uma recuperação mais focada, um modelo mais adequado à tarefa — é o trabalho de engenharia que segue a atribuição. O painel é o diagnóstico; a correção é o tratamento.
Orçamentos hierárquicos não são garantia de controle de custos. Uma equipe que tem seu orçamento aumentado toda vez que atinge o limite eventualmente chega à conclusão de que "o limite não existe". A disciplina está na cadência de revisão orçamentária, não no mecanismo técnico. Equipes de plataforma que aprovam todas as solicitações de cota perdem a alavancagem que o orçamento deveria proporcionar.
E a atribuição de custos no gateway não é a resposta certa para todas as organizações. Equipes cujo gasto total com IA é pequeno o suficiente para que o investimento em engenharia exceda as economias devem escolher um problema diferente para resolver primeiro; equipes cujas ferramentas FinOps existentes já produzem atribuição por carga de trabalho a partir de dados do provedor de nuvem não precisam de um sistema paralelo no gateway. O padrão se encaixa em organizações cujo gasto com IA cresceu mais rápido do que sua visibilidade sobre ele — tipicamente acima de US$ 5 mil/mês de gasto com provedor, onde o custo de um incidente descontrolado excede o custo de construção da camada. Abaixo desse limite, a matemática de um gateway pronto para uso como o da TrueFoundry nem sempre compensa; a equipe se beneficia mais mantendo o gasto em uma ou duas aplicações bem monitoradas e aplicando a camada quando o crescimento justificar.
Ambos, concomitantemente. Dólares se alinham com o planejamento financeiro e operacional. Tokens são a métrica de engenharia que permite à equipe depurar a eficiência do prompt — uma carga de trabalho cujo consumo de tokens dobra enquanto seu custo em dólares permanece estável (porque o modelo ficou mais barato) vale a pena investigar do ponto de vista da engenharia, mesmo que o financeiro não perceba. O gateway rastreia ambos; o financeiro é proprietário dos painéis de dólares, a engenharia é proprietária dos painéis de tokens, e o gateway é a fonte da verdade para ambos.
O pipeline recebe um 429 com o corpo de erro descritivo mostrado acima e um link para o painel de orçamento. Os runners de CI interpretam 429 como um sinal de backoff padrão; a compilação falha de forma limpa com uma mensagem acionável, em vez de travar de maneiras confusas. Aumentos de cota são registrados como tickets padrão para a equipe da plataforma através do link no corpo do erro. A última etapa bem-sucedida do pipeline é preservada; retomar após o aumento da cota não refaz o trabalho já pago.
Na prática, não. A TrueFoundry fornece wrappers de SDK que injetam o envelope de metadados automaticamente a partir de variáveis de ambiente já definidas pelos runners de CI, para que desenvolvedores individuais nunca editem cabeçalhos. O custo único é a atualização dos modelos de pipeline da equipe; o custo recorrente é zero. O benefício recorrente é cada painel que se segue.
Utilize um estável workflow_id campo dentro do x-tfy-metadata JSON — o mesmo valor para cada requisição pertencente ao mesmo fluxo de trabalho lógico. O gateway agrupa as requisições por workflow_id para aplicação de orçamento por fluxo de trabalho. Um fluxo de trabalho com um limite de $5 pode abranger centenas de requisições; o gateway rastreia o total acumulado em relação ao identificador do fluxo de trabalho, e não à requisição individual.
Corresponde à fatura do provedor com uma margem de aproximadamente 1% para custos de tokens de entrada e saída; a pequena variação provém de arredondamentos e de sobretaxas do lado do provedor (descontos por volume, diferenciais regionais) que o gateway não consegue ver no momento da requisição. Para a maioria dos propósitos de planejamento, os números do gateway são suficientemente precisos; para reconciliação de nível contábil, a fatura do provedor permanece a fonte da verdade, com o gateway fornecendo o detalhamento por carga de trabalho. A TrueFoundry's documentação de rastreamento de custos descreve os modos de precificação pública (tarifas publicadas pelo provedor) e precificação privada (contratos personalizados).
Os orçamentos são definidos por centro de custo; o descontrole de uma equipe consome apenas o seu próprio orçamento. O limite máximo impede o descontrole antes que ele possa afetar outras equipes. A regra de limite de nível de modelo na configuração de limite de taxa (o opus-per-cost-center-daily exemplo) é uma salvaguarda para o caso em que várias equipes se comportam mal simultaneamente ou onde a própria atribuição está incorreta; ele opera acima da camada por centro de custo.
O trabalho entre equipes é incomum, mas real. O padrão mais limpo é definir um centro de custo de "iniciativa compartilhada" de propriedade da equipe de plataforma, com regras explícitas de estorno documentadas no README do gateway. A marcação permanece de valor único — a requisição pertence a exatamente um centro de custo em tempo de execução — mas a equipe de plataforma pode registrar os gastos para as equipes participantes no final de cada período de faturamento por meio dos dados de custo exportados descritos na documentação de rastreamento de custos.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




