




October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
Nos últimos meses, tivemos a oportunidade de trabalhar com uma equipe enxuta. Eles desenvolveram um modelo de deep learning de ponta e criaram parcerias para disponibilizá-lo a mais de 10 milhões de usuários.
A última peça que faltava em sua história de impacto era lidar com a engenharia para realizar isso. O modelo era intensivo em computação e, na escala em que queriam servi-lo aos usuários finais, eles precisavam de uma pilha de infraestrutura confiável e de alto desempenho que os dois pudessem gerenciar (1 Engenheiro DevOps e 1 Engenheiro de ML).
O modelo foi construído para processar entradas de áudio de tamanhos variados. Como o modelo tinha um alto tempo de processamento (com média de ~5 segundos), ele precisava de uma inferência assíncrona para cada solicitação, a fim de processar e responder a essas solicitações.
A equipe construiu sua pilha inicial para servir o modelo no Sagemaker. No entanto, quando realizaram seu primeiro piloto usando este design, perceberam que servir o modelo de forma confiável na escala desejada seria difícil com esta pilha.
Mesmo após usar a configuração assíncrona, como as instâncias demoravam para escalar (8-10 minutos por máquina), a experiência do usuário final foi comprometida quando eles tiveram que suportar esse atraso.
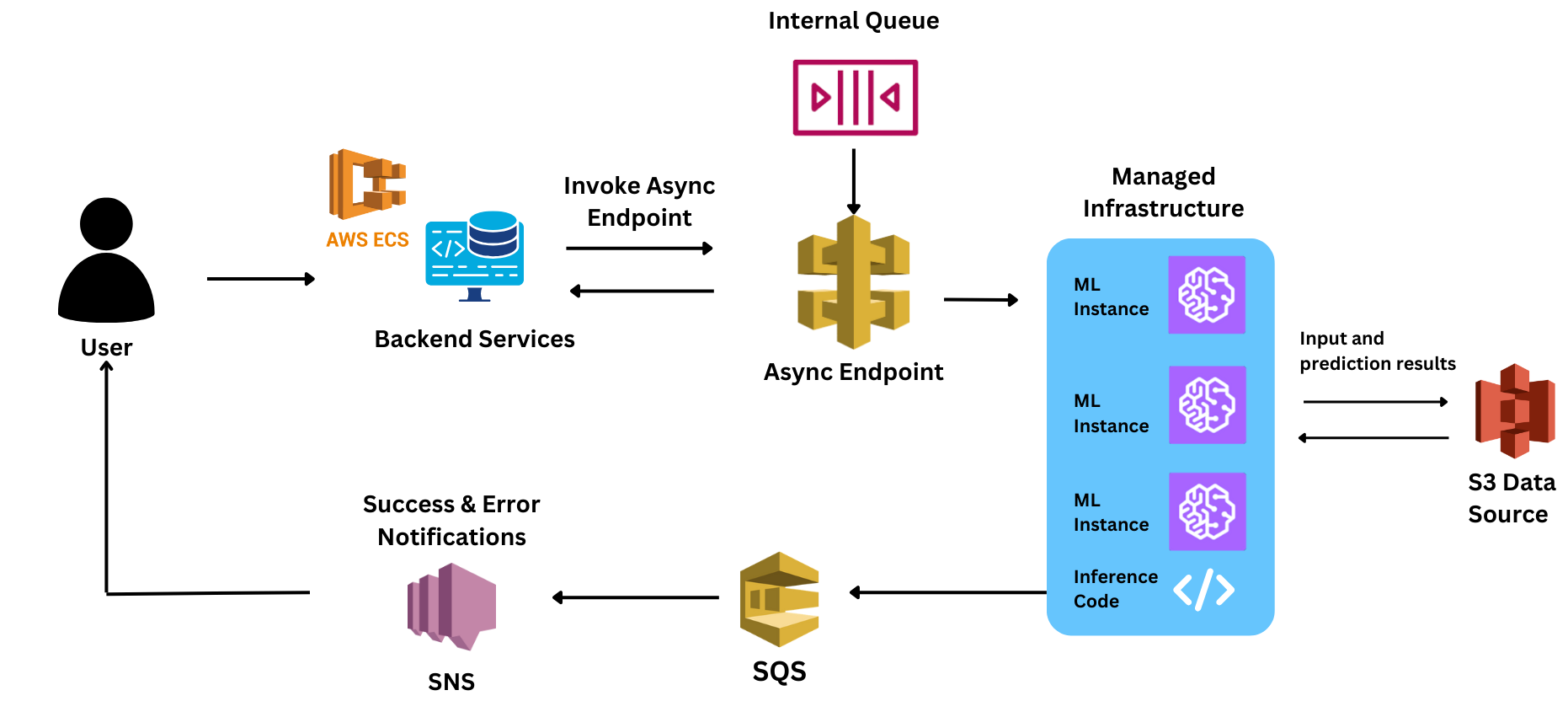
No entanto, durante a PoC, eles enfrentaram grandes atrasos nos tempos de resposta. Como eram novos em muitos dos controles relacionados ao Sagemaker, perderam tempo crucial para encontrar a razão dos atrasos. Alguns dos desafios que enfrentaram foram:
Depois da PoC, a equipe perdeu a confiança no Sagemaker e decidiu que precisava de uma solução que os dois (um Engenheiro de ML e um Engenheiro de DevOps) pudessem atender ao seu público-alvo de mais de 10 milhões de usuários.
Quando começamos a interagir com a equipe, o piloto deles estava a cerca de 7 dias. Garantimos à equipe que poderíamos ajudá-los a migrar toda a pilha e reconstruí-la usando os módulos do TrueFoundry em menos de 2 dias, para que tivessem tempo suficiente para testar antes que o piloto deles fosse para produção.
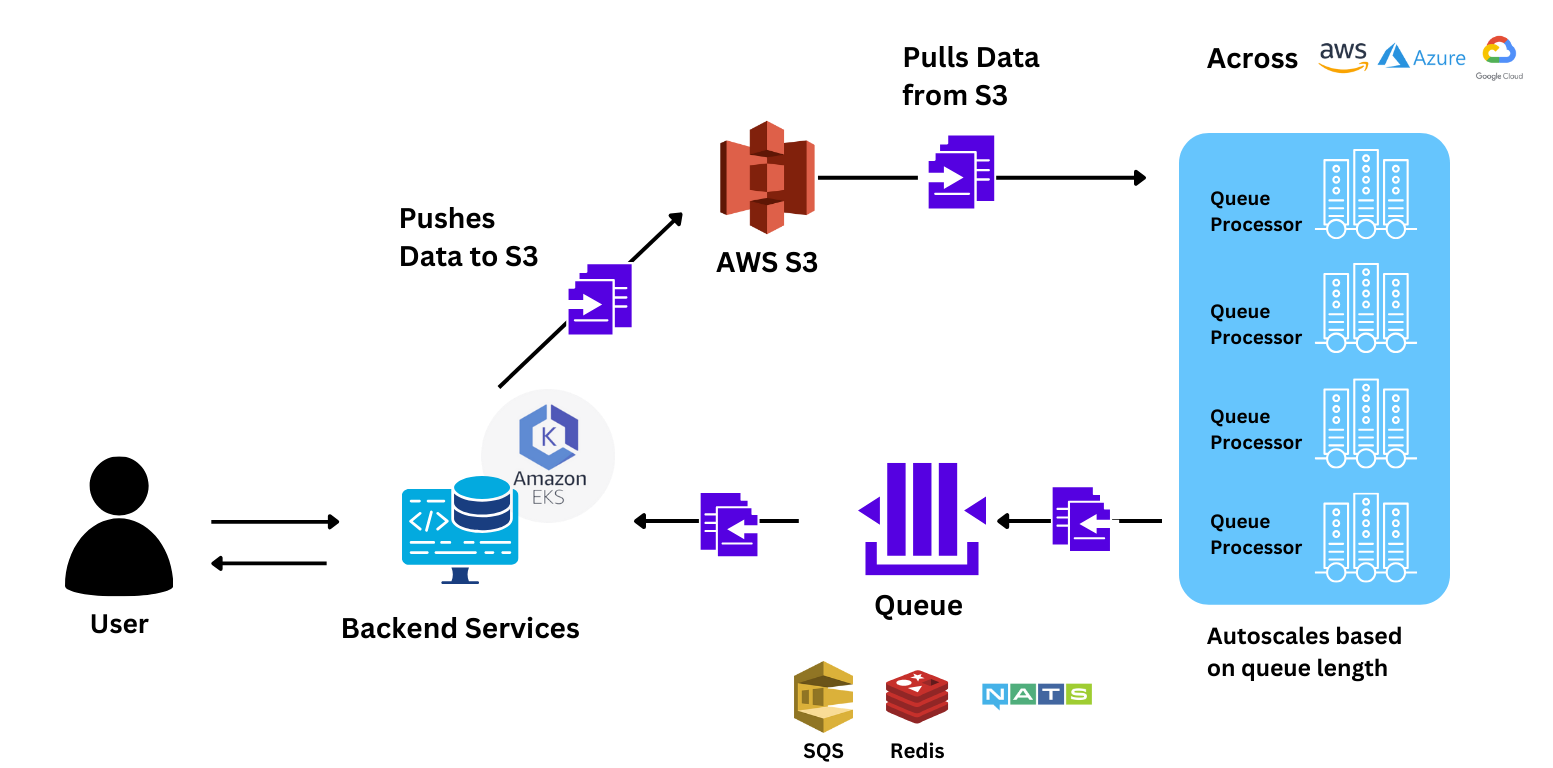
A equipe realizou benchmarks enviando um pico de 88 requisições ao modelo para comparar o desempenho com o Sagemaker. TrueFoundry escalou 78% mais rápido do que o Sagemaker, proporcionando ao usuário respostas muito mais rápidas. O tempo de ponta a ponta para responder à consulta foi 40% mais rápido com o TrueFoundry.
A equipe simplesmente conseguiu escalar a aplicação para mais de 150 nós de GPU porque:
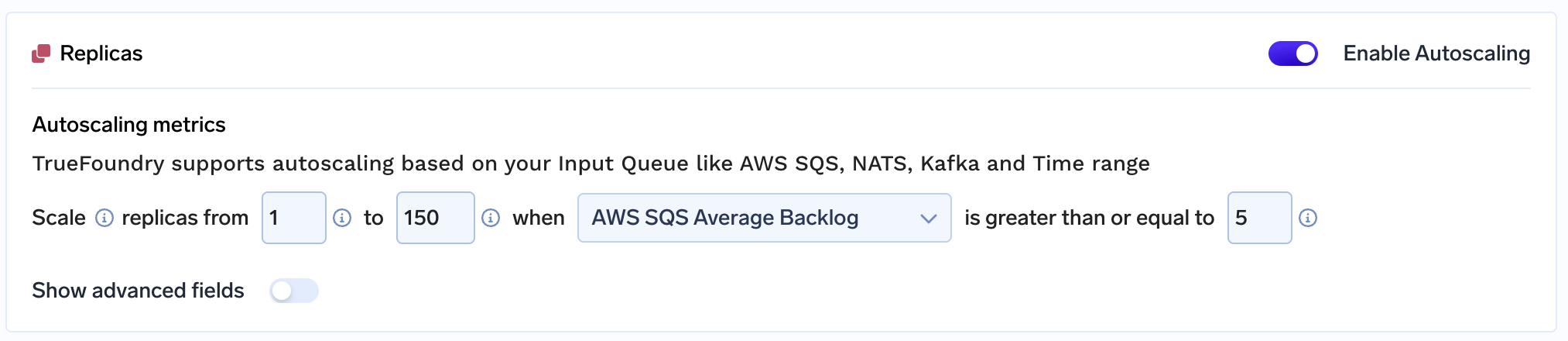

Usando TrueFoundry, a equipe de 2 membros consegue gerenciar toda a sua carga de trabalho, que muitas vezes escala para mais de 150 nós de GPU!! por conta própria. Ao trabalhar conosco, o que mais se destacou para a equipe foi o nosso suporte ao cliente e os baixos tempos de resposta. O TrueFoundry está empenhado no sucesso de seus clientes e espera que todos os nossos clientes possam escalar e gerar impacto em proporções semelhantes a este projeto!
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




