













Confiado por mais de 1000 Marcas Globais
Sirva Qualquer Modelo, Qualquer Framework
IA Generativa
Sirva qualquer modelo Hugging Face em texto, imagem, multimodal e áudio, com suporte total para endpoints compatíveis com OpenAI
ML Tradicional
Implante e escale sem esforço modelos construídos com XGBoost, scikit-learn e LightGBM para previsões confiáveis e de alto desempenho.
Deep Learning
Execute modelos prontos para produção desenvolvidos usando PyTorch, TensorFlow ou Keras, otimizados para velocidade, escalabilidade e estabilidade.
Contêineres Personalizados
Implante pipelines de inferência totalmente personalizados usando seus próprios contêineres Docker para controle completo sobre o tempo de execução e as dependências.
RAG
Implante modelos de embedding, rerankers e bancos de dados vetoriais para construir aplicações de IA precisas e sensíveis ao contexto.
Modelos de Visão
Implante e escale qualquer modelo de visão computacional com facilidade, desde classificação de imagens até compreensão visual avançada.

Execute em qualquer lugar: Nuvem, On-Premise ou Edge
- Implantações totalmente nativas da nuvem baseadas em Kubernetes
- Implementar em AWS, GCP, Azure, on-premise, ou na edge
Autoescalonamento fácil em CPUs/GPUs
- Suporta modelos intensivos em CPU e GPU
- Escala para zero ou autoescalonamento sob demanda
.webp)

Acesso Seguro e Controlado
- Controle de Acesso Baseado em Função Granular
- Autenticação baseada em token e segurança de API
Inferência em Lote e por Streaming
- Forneça previsões em tempo real via REST ou gRPC
- Agende ou dispare inferência em lote
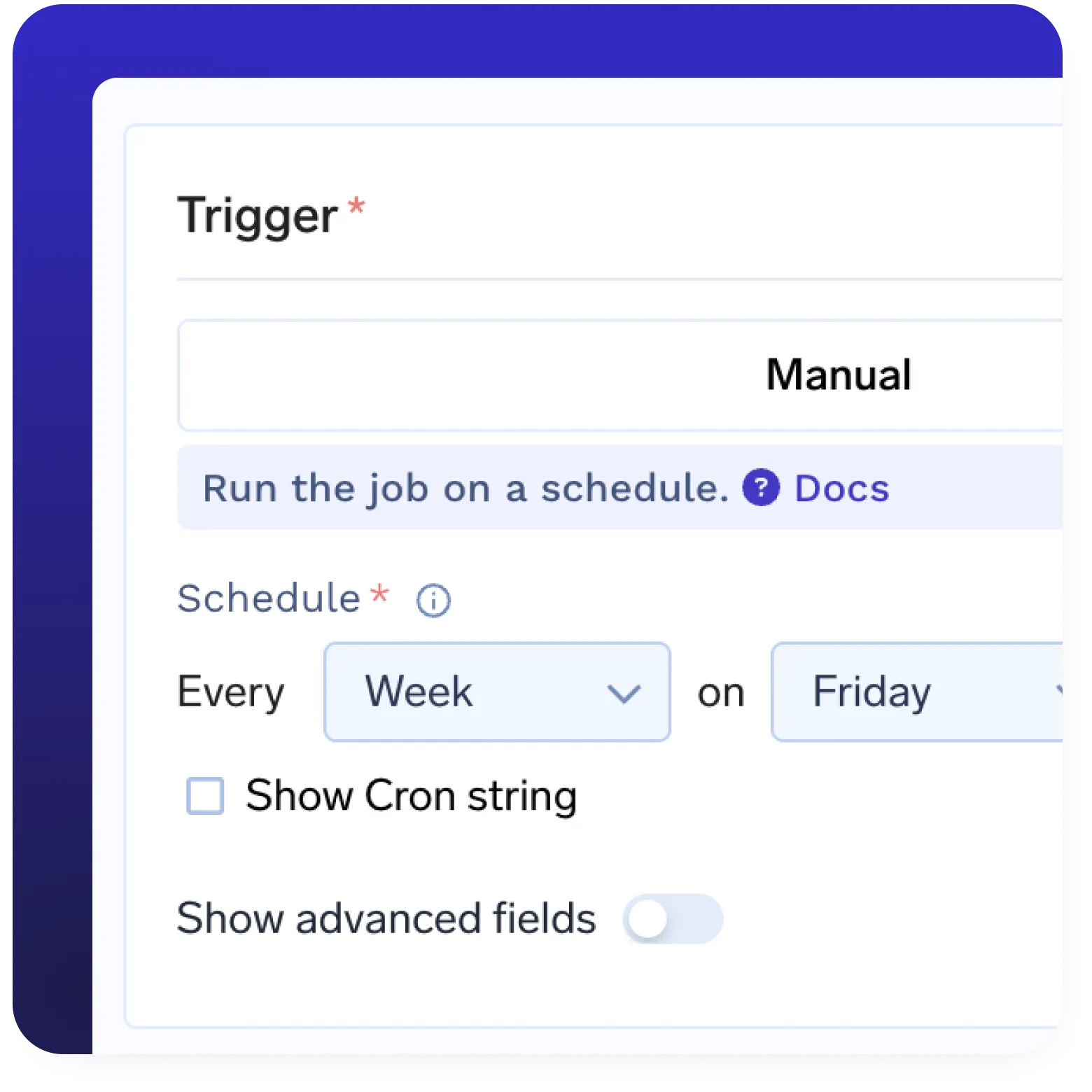

Registro de Modelos Integrado
- Registro de modelos abrangente integrado
- Implante modelos automaticamente a partir do registro
- Gerencie versões e metadados
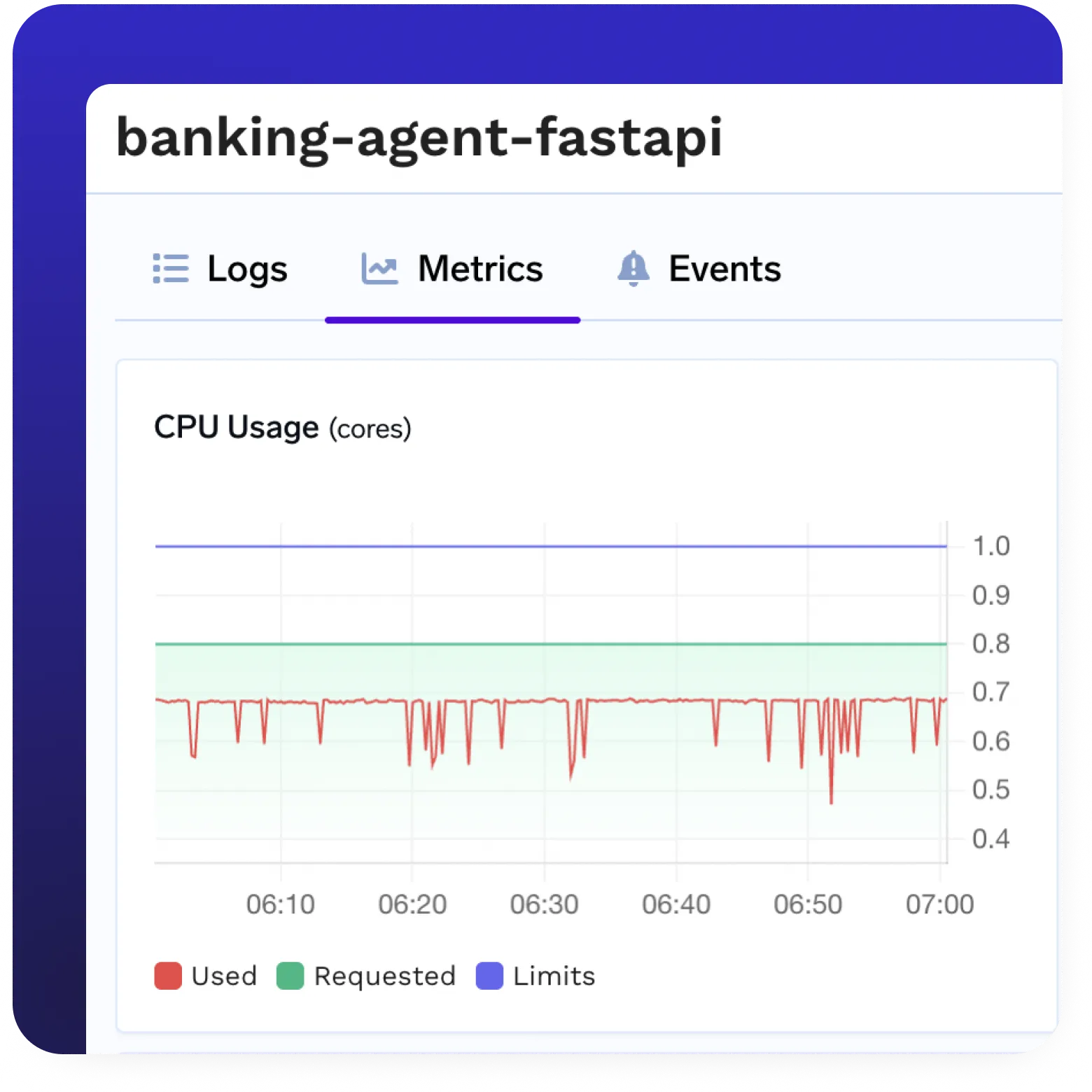
Observabilidade e Monitoramento Completos
- Suporte nativo para Prometheus, Grafana e OpenTelemetry
- Logs, traces e métricas em tempo real
- Visibilidade sobre implantação, uso e saúde do sistema

Experiência do Desenvolvedor Agradável
- UI, SDK e CLI intuitivos para gerenciar, testar e monitorar seus modelos.
- Design focado no desenvolvedor, do ambiente de desenvolvimento local à produção.
Custo-benefício
- Otimização inteligente de infraestrutura
- Utilização eficiente de GPU e suporte a instâncias spot
- Sem dependência de fornecedor

Pronto para Empresas
Seus dados e modelos são armazenados com segurança em sua infraestrutura na nuvem / local.

Sistemas Totalmente Modulares
Integra-se e complementa sua pilha existenteConformidade Genuína
Padrões SOC 2, HIPAA e GDPR para garantir proteção robusta de dadosSeguro por Design
Controle de acesso baseado em função flexível e trilhas de auditoriaAutenticação padrão da indústria
Integração SSO via OIDC ou SAML

Infraestrutura GenAI - simples, mais rápida, mais barata
Confiado por mais de 30 empresas e companhias da Fortune 500
Depoimentos A TrueFoundry torna sua equipe de ML 10 vezes mais rápida
.webp)
Deepanshi S
Cientista de Dados Líder



Matthieu Perrinel
Líder de ML


Soma Dhavala
Diretor de Machine Learning


Rajesh Chaganti
CTO


Sumit Rao
AVP de Ciência de Dados


Vivek Suyambu
Engenheiro de Software Sênior










