












LLMOps para Servir Modelos e Inferência
.webp)
- Implante qualquer LLM de código aberto dentro do seu pipeline de LLMOps usando configurações pré-configuradas e otimizadas para desempenho
- Integre-se perfeitamente com Hugging Face, registros privados, ou qualquer hub de modelo — totalmente gerenciado dentro da sua plataforma LLMOps
- Aproveite servidores de modelo líderes do setor como vLLM e SGLang para inferência de baixa latência e alto throughput
- Habilite Autoescalonamento de GPU, desligamento automático e provisionamento inteligente de recursos em sua infraestrutura LLMOps.
.webp)
Sirva qualquer LLM com servidores de modelo de alto desempenho como vLLM e SGLang, impulsionados por autoescalonamento de GPU e infraestrutura LLMOps com custo-benefício.
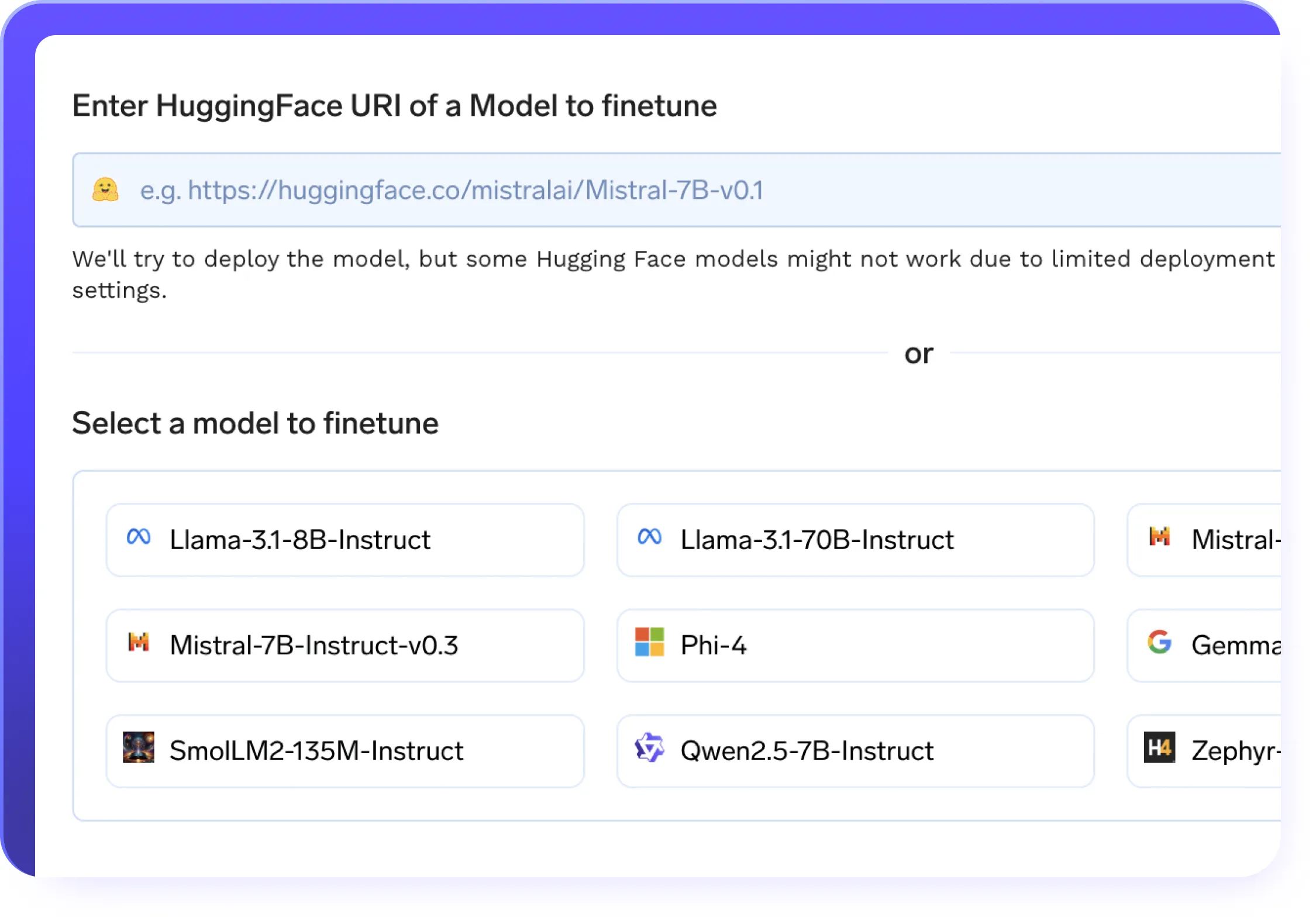
Fine-tuning Eficiente
- Suporte a fine-tuning no-code e full-code em conjuntos de dados personalizados
- LoRA e QLoRA para adaptação eficiente de baixo posto
- Retome o treinamento sem interrupções com checkpointing suporte em seus pipelines de LLMOps
- Com um clique implantação de modelos ajustados com servidores de modelo de ponta
- Pipelines de treinamento automatizados com rastreamento de experimentos incorporado aos seus fluxos de trabalho LLMops
- Suporte para treinamento distribuído para otimização de modelos mais rápida e em larga escala
Governe o uso de IA com um Gateway de IA que unifica o acesso a modelos, impõe cotas e garante observabilidade e segurança.
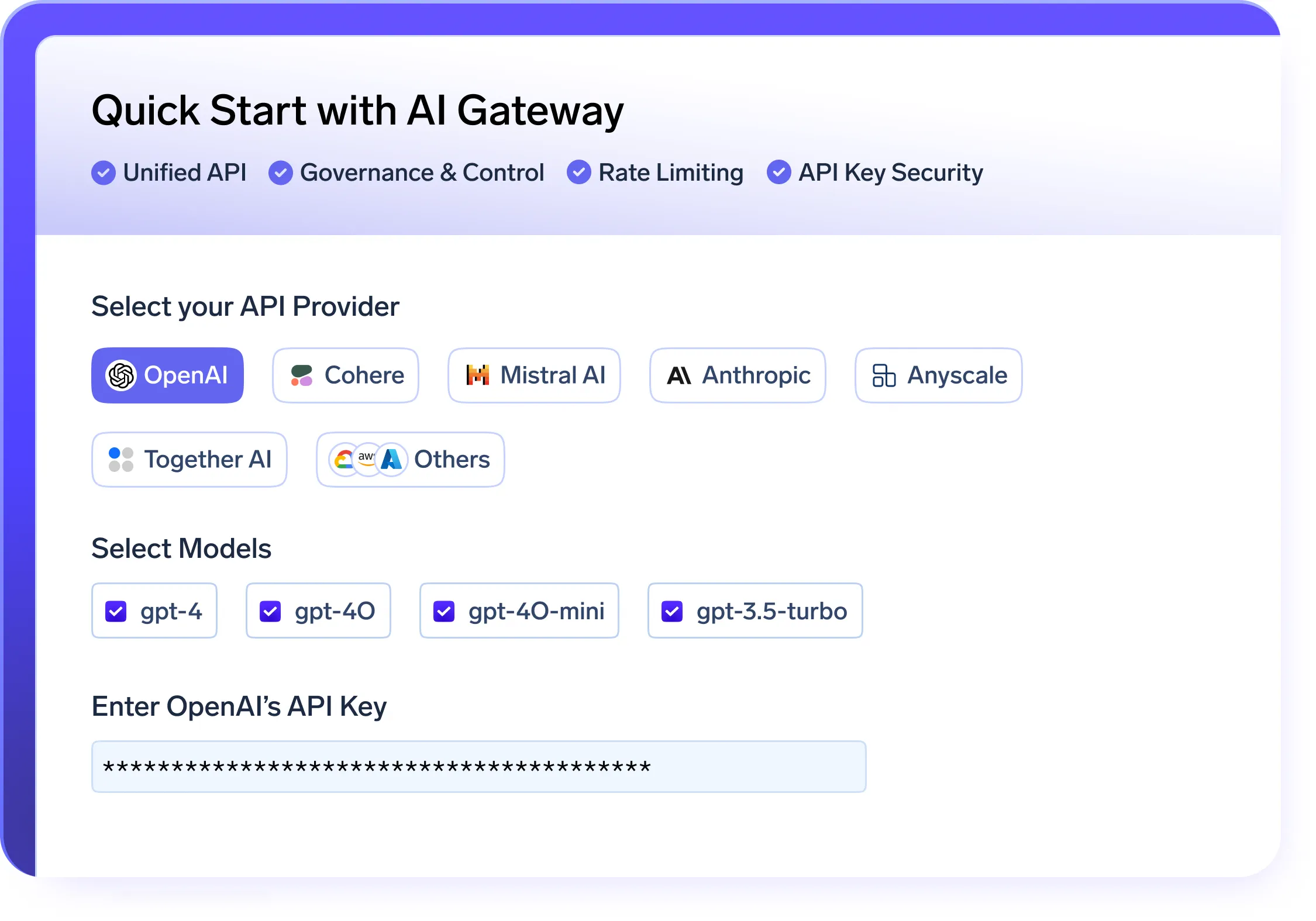
Gateway de IA Seguro e Escalável
- Um API unificada camada para servir e gerenciar modelos em OpenAI, LLaMA, Gemini e outros provedores
- Integrado gestão de cotas e controle de acesso para impor o uso seguro e governado de modelos dentro da sua plataforma LLMOps
- Métricas em tempo real para uso, custo e desempenho para melhorar a observabilidade de LLMOps
- Inteligente fallback e novas tentativas automáticas para garantir a confiabilidade em seus pipelines LLMOps
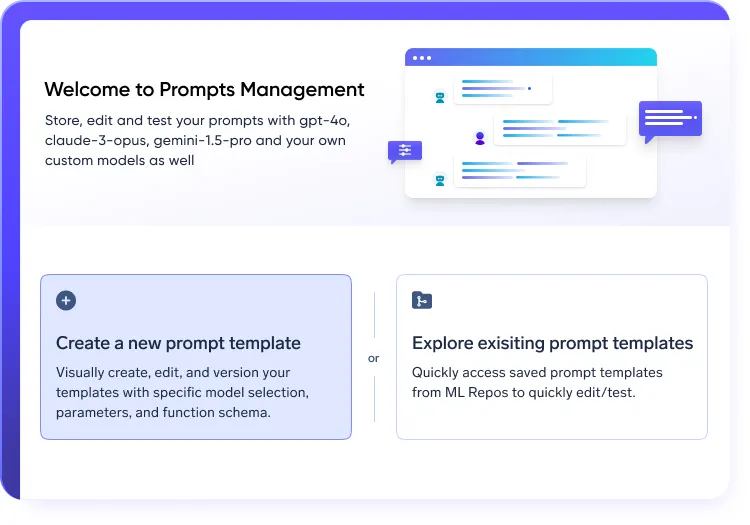
Fluxos de trabalho de prompt estruturados na pilha LLMOps
- Experimente e itere usando prompt com controle de versão engenharia
- Executar Testes A/B entre modelos para otimizar o desempenho
- Manter rastreabilidade completa das alterações de prompt dentro da sua plataforma LLMOps
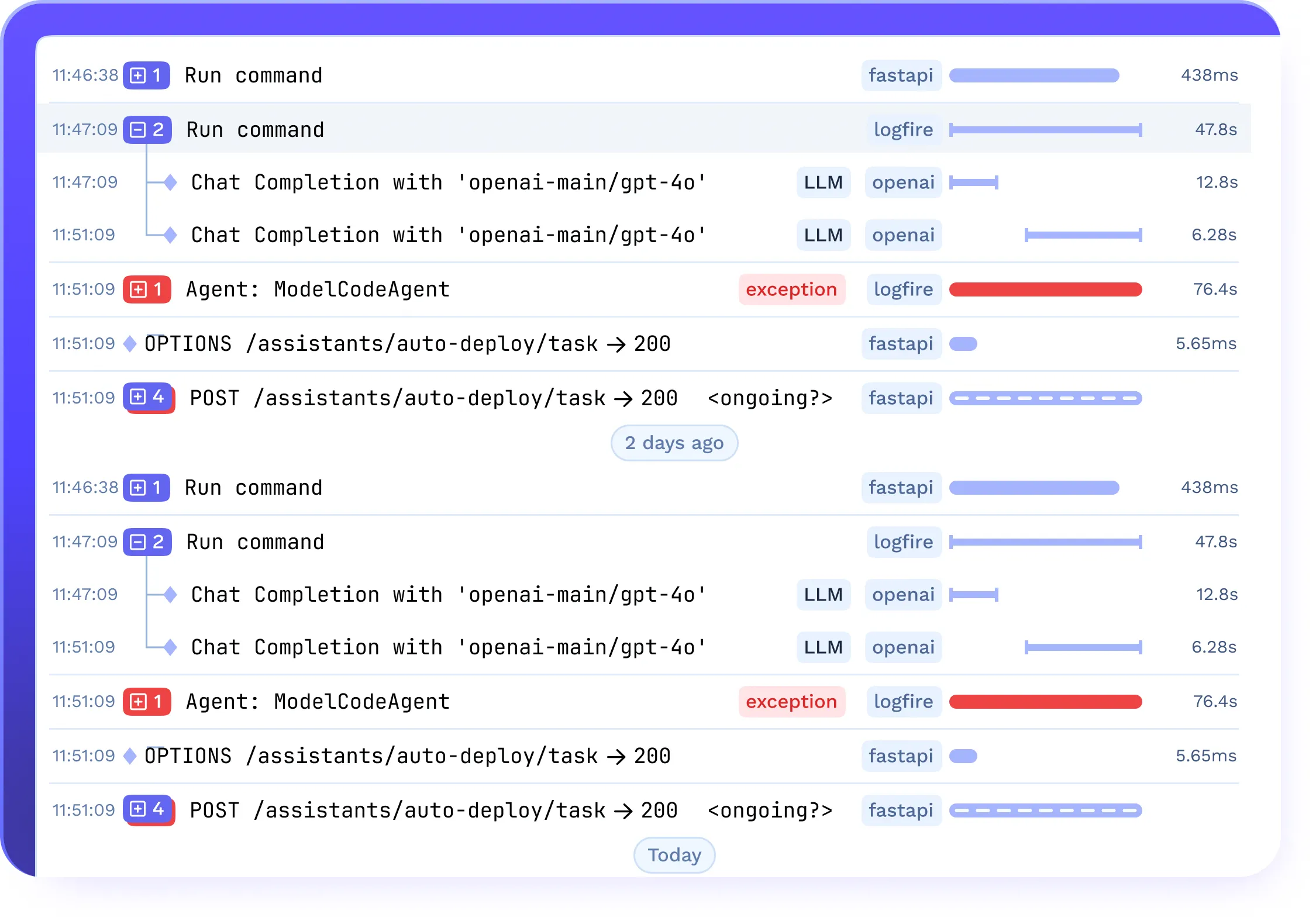
Rastreamento e Barreiras de Segurança para Fluxos de Trabalho LLMOps
- Capturar rastreamentos completos de prompts, respostas, uso de tokens e latência
- Monitorar desempenho, taxas de conclusão e anomalias
- Integrar com Barreiras de segurança para detecção de PII e moderação de conteúdo em pipelines LLMOps
Implantação RAG com um clique
- Implanta todos os componentes RAG com um único clique, incluindo VectorDB, modelos de embedding, frontend e backend
- Infraestrutura configurável para otimizar o armazenamento, a recuperação e o processamento de consultas
- Gerencie bases de documentos em crescimento com escalabilidade LLMOps nativa da nuvem
Gerencie os ciclos de vida dos agentes - da implantação à observabilidade - em qualquer framework, impulsionado pela sua plataforma LLMOps.
LLMOps para Gestão do Ciclo de Vida de Agentes de IA
- Execute e escale agentes em qualquer framework usando sua infraestrutura LLMOps
- Suporte para LangChain, AutoGen, CrewAI e agentes personalizados
- Orquestração de agentes agnóstica a frameworks com monitoramento LLMOps integrado
- Suporte para orquestração multiagente, permitindo que os agentes interajam, compartilhem contexto e executem tarefas de forma autônoma
.webp)
Integração do Servidor MCP na Sua Pilha LLMOps
- Conecte LLMs com segurança a ferramentas como Slack, GitHub e Confluence usando o protocolo MCP
- Implementar Servidores MCP em VPC, no local ou em configurações isoladas com controle total dos dados
- Ative o uso de ferramentas nativas de prompt sem wrappers — totalmente integrado na sua stack LLMOps
- Governe o acesso com RBAC, OAuth2, e rastreie cada chamada com observabilidade integrada
Pronto para Empresas
Implante um gateway de IA seguro que mantém seus dados e modelos dentro da sua infraestrutura em nuvem / on-premise.


Conformidade e Segurança
Padrões SOC 2, HIPAA e GDPR para garantir uma proteção de dados robustaGovernança e Controle de Acesso
SSO + Controle de Acesso Baseado em Função (RBAC) e Registro de AuditoriaSuporte Empresarial e Confiabilidade
Suporte 24/7 com garantia de SLA SLAs de resposta
Implemente a TrueFoundry em qualquer ambiente
VPC, on-premise, air-gapped ou em várias nuvens.
Nenhum dado sai do seu domínio. Desfrute de total soberania, isolamento e conformidade de nível empresarial onde quer que A TrueFoundry é executada

Perguntas frequentes
O que é LLMOps e por que é importante?
LLMOps (Large Language Model Operations) refere-se à prática de gerir todo o
ciclo de vida de grandes modelos de linguagem — desde o treino e ajuste fino até à implementação, inferência,
monitorização e governança. O LLMOps ajuda as organizações a trazer aplicações GenAI para
produção de forma fiável e em escala. A TrueFoundry oferece uma plataforma LLMOps de nível de produção
que simplifica e acelera todo este processo.
ciclo de vida de grandes modelos de linguagem — desde o treino e ajuste fino até à implementação, inferência,
monitorização e governança. O LLMOps ajuda as organizações a trazer aplicações GenAI para
produção de forma fiável e em escala. A TrueFoundry oferece uma plataforma LLMOps de nível de produção
que simplifica e acelera todo este processo.
Qual a diferença entre LLMOps e MLOps tradicional?
Enquanto o MLOps suporta uma vasta gama de modelos de ML, o LLMOps é construído especificamente para GenAI e
grandes modelos de linguagem. Inclui capacidades como orquestração de servidores de modelos, prompt
gerenciamento, observabilidade em nível de token, frameworks de agente e acesso seguro à API.
A plataforma LLMOps da TrueFoundry lida nativamente com esses fluxos de trabalho específicos de GenAI — ao contrário das
ferramentas MLOps genéricas.
grandes modelos de linguagem. Inclui capacidades como orquestração de servidores de modelos, prompt
gerenciamento, observabilidade em nível de token, frameworks de agente e acesso seguro à API.
A plataforma LLMOps da TrueFoundry lida nativamente com esses fluxos de trabalho específicos de GenAI — ao contrário das
ferramentas MLOps genéricas.
Por que devo investir em uma plataforma LLMOps dedicada como a TrueFoundry?
Uma plataforma LLMOps dedicada elimina a necessidade de juntar ferramentas de infraestrutura, monitoramento e avaliação. A TrueFoundry permite implantação segura, experimentação de prompts, observabilidade e otimização de custos em uma única plataforma. Isso permite que as equipes passem do protótipo para a produção mais rapidamente, mantendo a governança e a confiabilidade empresariais.
Quais são os principais recursos da plataforma LLMOps da TrueFoundry?
A plataforma LLMOps da TrueFoundry integra controle de versão, teste A/B e ajuste de prompts para cada modelo de base. Os principais componentes do LLMOps incluem ajuste automatizado de hiperparâmetros e monitoramento da qualidade dos dados. Esses recursos suportam aplicações complexas de IA, otimizando recursos computacionais e garantindo desempenho consistente de LLM em todos os conjuntos de dados.
Posso implantar a plataforma LLMOps da TrueFoundry na minha infraestrutura?
Sim. A TrueFoundry suporta a implantação em sua VPC, nuvem privada ou ambiente on-premise. Isso garante controle total sobre dados sensíveis, conformidade com políticas de segurança internas e integração perfeita com a infraestrutura existente, mantendo escalabilidade e desempenho de nível empresarial.
Como o LLMOps melhora a observabilidade e a depuração?
Esta plataforma LLMOps aprimora o desempenho do modelo por meio de métricas de desempenho e análise de dados em tempo real. Engenheiros usam avaliação de gisting e métricas BLEU de avaliação bilíngue para depurar modelos de ML. Ao acompanhar o feedback humano e as operações do modelo, você obtém visibilidade aprofundada sobre como a inteligência artificial se comporta em ambientes de produção em tempo real.
A plataforma LLMOps da TrueFoundry é segura e em conformidade?
Nossa plataforma LLMOps empresarial prioriza a segurança de IA empresarial através de RBAC e conformidade SOC 2. Garantimos a qualidade dos dados e protegemos dados sensíveis usando isolamento multi-tenant. Ao integrar integração contínua e protocolos rigorosos de preparação de dados, a plataforma mantém um ambiente seguro para a implantação de quaisquer modelos de linguagem grandes.
Quais modelos e frameworks são suportados na plataforma LLMOps da TrueFoundry?
A plataforma LLMOps da TrueFoundry suporta modelos de linguagem como Mistral e LLaMA, juntamente com modelos de ML tradicionais. É agnóstica a frameworks, integrando-se com transformers da Hugging Face e ferramentas de ciência de dados. Quer você esteja usando um modelo de base ou sistemas de IA personalizados, nossa plataforma facilita a implantação e o escalonamento contínuos de modelos.
Posso usar a plataforma LLMOps da TrueFoundry para gerenciar múltiplas equipes e projetos?
Sim, a plataforma LLMOps empresarial da TrueFoundry foi projetada para multi-tenancy, permitindo que equipes de engenharia de dados gerenciem projetos distintos. Você pode monitorar recursos computacionais, rastrear custos e organizar a coleta de dados para tarefas específicas. Essa estrutura melhora a experiência do usuário para grandes organizações que estão escalando suas iniciativas de IA generativa e ciência de dados.
Com que rapidez posso começar a usar o TrueFoundry para LLMOps?
Você pode lançar nossa plataforma LLMOps em minutos usando modelos de prompt pré-construídos e fluxos de trabalho de desenvolvimento de IA. A plataforma acelera a preparação de dados e a automação do suporte ao cliente. Com operações de modelo automatizadas, sua equipe pode passar rapidamente da coleta inicial de dados para ambientes de produção de alto desempenho com atrito mínimo.

Infraestrutura de GenAI - simples, mais rápida, mais barata
Confiado por mais de 30 empresas e companhias da Fortune 500








