







October 5, 2023
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: May 21, 2026

Blazingly fast way to build, track and deploy your models!
A OpenAI e a Langchain tornaram muito fácil criar uma demonstração de perguntas e respostas sobre os seus documentos. Existem muitos artigos na internet que descrevem como fazer isso. Também temos um notebook funcional caso queira experimentar um sistema de ponta a ponta:
Neste artigo, falaremos sobre como colocar um bot de perguntas e respostas em produção nos seus documentos. Também o implementaremos no seu ambiente de nuvem e permitiremos o uso de LLMs de código aberto em vez da OpenAI, se a privacidade e a segurança dos dados forem um dos requisitos principais.
O fluxo de trabalho principal para construir o sistema de QA usando RAG (Geração Aumentada por Recuperação) é o seguinte:
Fluxo de Indexação de Documentos:
Obtendo a resposta à consulta do usuário:
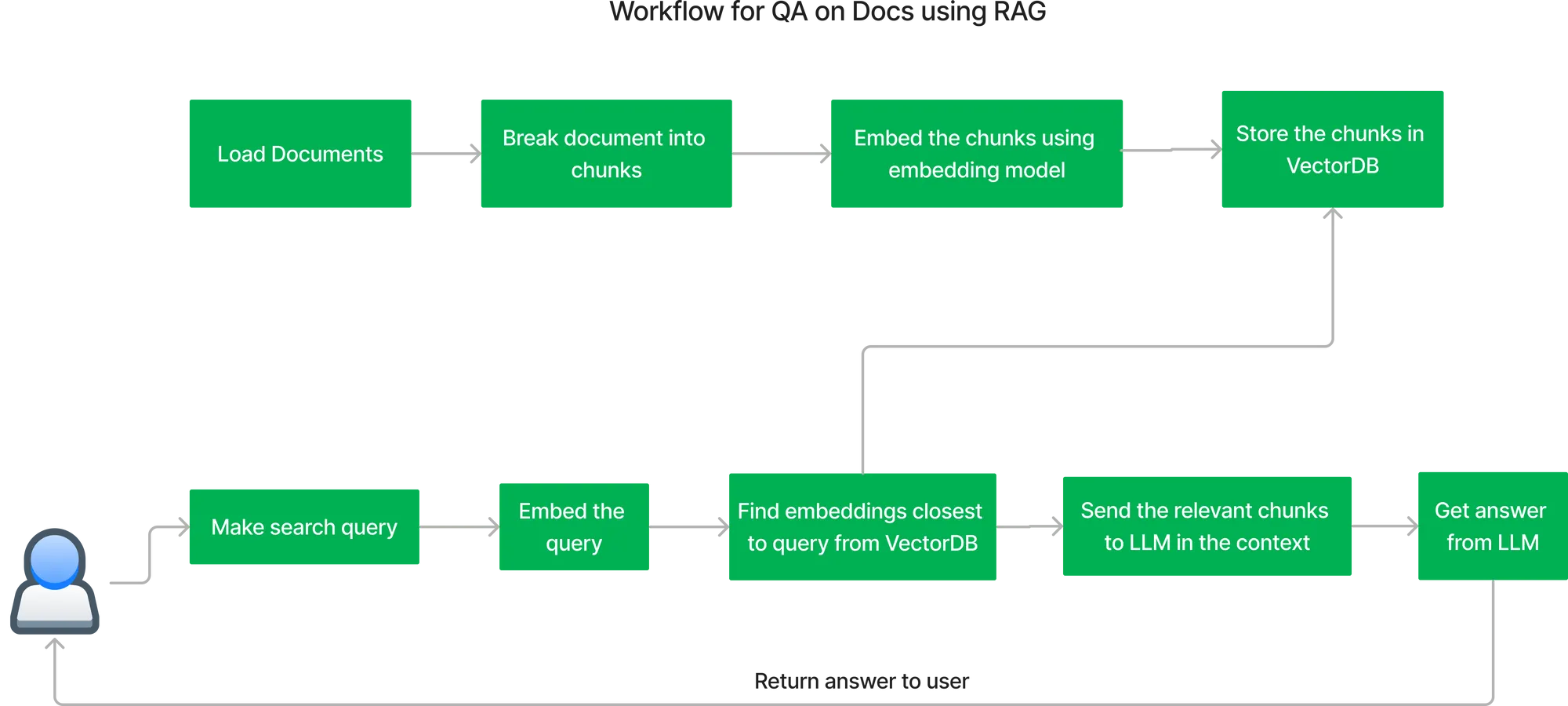
Para implantar todo o fluxo descrito acima, precisamos implantar vários componentes juntos. Aqui está o diagrama de arquitetura para implantar o RAG em sua própria nuvem.
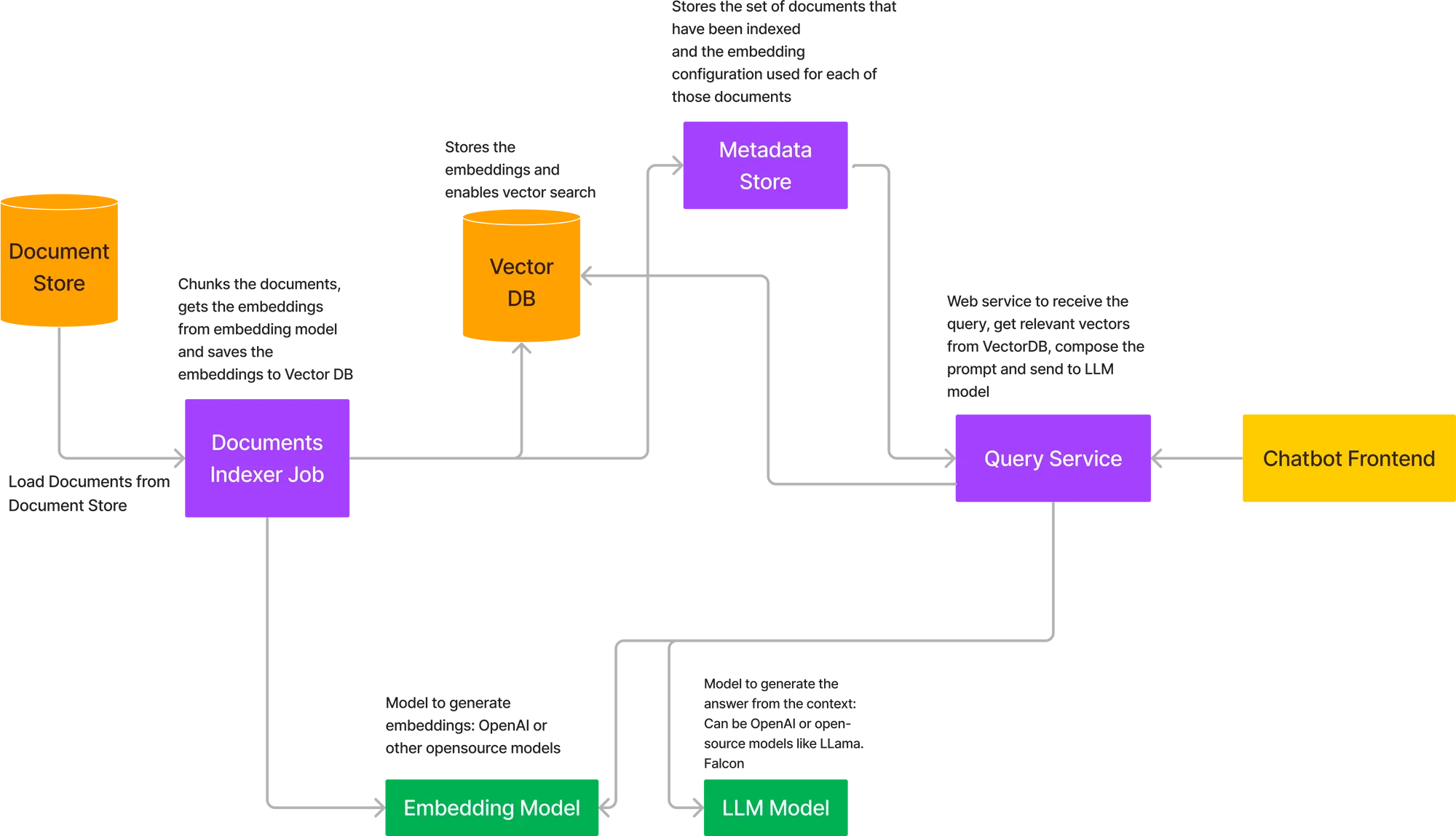
Os principais componentes na arquitetura acima são:
É aqui que os documentos serão armazenados. Em muitos casos, será AWS S3, Google Storage Buckets ou Azure Blob Storage. Em alguns casos, esses dados também podem vir de APIs se estivermos lidando com algo como documentos do Confluence.
Isso será modelado de forma semelhante a uma tarefa de treinamento em ML, que recebe os documentos como entrada, os divide em trechos, chama o modelo de incorporação para incorporar os trechos e armazena os vetores no banco de dados. O modelo de incorporação pode ser carregado na própria tarefa ou chamado como uma API. A rota da API é preferida, pois assim o modelo de incorporação pode ser escalado independentemente caso haja um grande número de documentos. As tarefas podem ser acionadas ad-hoc ou em um agendamento, se houver um fluxo de documentos de entrada. Assim que a tarefa for concluída, ela também deve armazenar o status como 'Bem-sucedida' em um armazenamento de metadados, juntamente com as configurações de incorporação.
Se estivermos usando OpenAI ou um modelo hospedado externamente, não precisamos hospedar um modelo neste caso. No entanto, se estivermos usando um modelo de código aberto, teremos que hospedá-lo em nosso ambiente de nuvem e, em seguida, obter as incorporações usando a API.
Se estivermos usando OpenAI ou APIs de modelos hospedados como Cohere e Anthropic, então não precisamos implantar nada; caso contrário, teremos que implantar LLMs de código aberto.
Este pode ser um serviço FastAPI que fornece a API para listar todas as coleções de documentos indexadas e permite ao usuário fazer consultas sobre as coleções de documentos. Haverá também uma API para acionar um novo trabalho de indexação para uma nova coleção de documentos.
Podemos usar uma solução hospedada aqui, como o PineCone, ou hospedar um dos VectorDBs de código aberto, como o Qdrant ou o Milvus.
Isso é necessário para armazenar os links para os documentos que foram indexados e qual foi a configuração utilizada para incorporar os blocos (chunks) nesses documentos. Isso ajuda o usuário a selecionar o conjunto de documentos a serem consultados e pode suportar múltiplos conjuntos de documentos em uma organização.
Truefoundry é uma plataforma em Kubernetes que torna muito fácil implantar trabalhos de treinamento de ML e serviços com o custo mais otimizado. Usando Truefoundry, podemos implantar todos os componentes da arquitetura acima — na sua própria conta de nuvem. A implantação final na sua nuvem terá esta aparência:
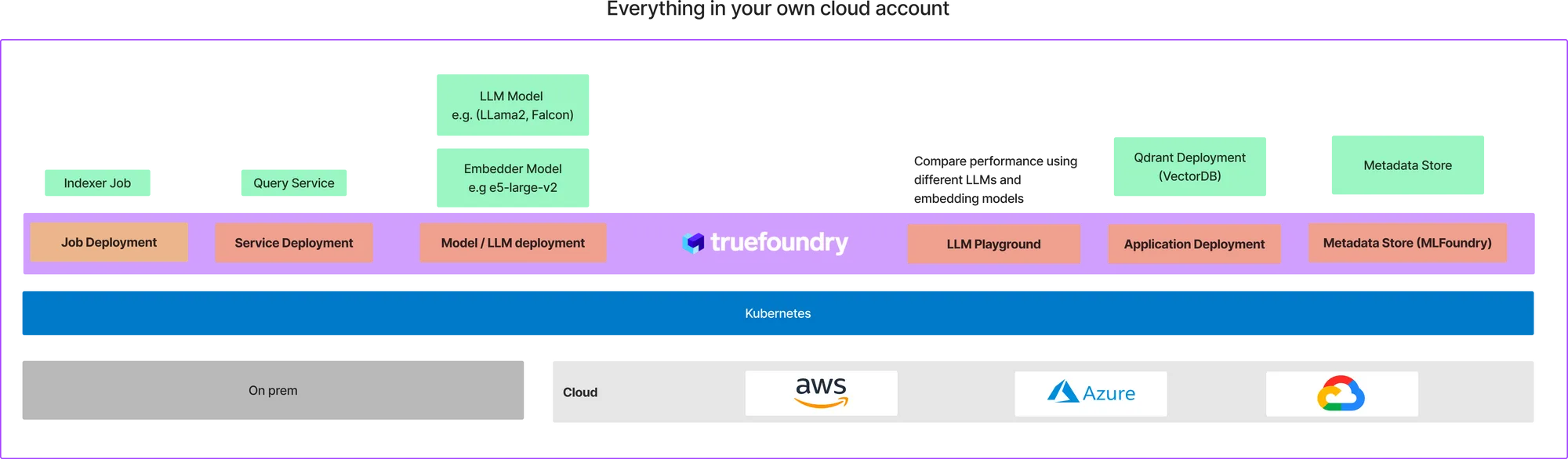
Isso pode parecer muita configuração, mas já criamos um modelo para você começar com isso em menos de 10 minutos. Assumimos que você já está integrado ao TrueFoundry. Se você ainda não está integrado, siga este guia para ser integrado. TrueFoundry funciona em todos os três principais provedores de nuvem: AWS, Azure e GCP — então você deve conseguir configurá-lo em qualquer um desses provedores de nuvem.
Criamos um bot de QA de exemplo para você, com o código para o trabalho do indexador, serviço de consulta e um frontend de chat usando streamlit neste repositório do Github:
Você pode implantar isso no TrueFoundry na sua própria nuvem em 15 minutos. Isso permitirá uma configuração de nível de produção e também lhe dará total flexibilidade para modificar o código de acordo com seus próprios casos de uso.
Implantaremos toda a arquitetura em um Cluster Kubernetes. Você pode encontrar todo o código e as instruções para implantar em este repositório do github.
TrueFoundry oferece uma abstração fácil de usar sobre o Kubernetes para implantar diferentes tipos de aplicações no Kubernetes. Vamos percorrer os diferentes passos para implantar RAG na sua nuvem.
Truefoundry vem com um armazenamento de metadados na forma de repositórios ML. Você pode armazenar artefatos, metadados e mlfoundry pip library fornece métodos para carregar e baixar os artefatos. Cada repositório ML é suportado pelo armazenamento de blobs na nuvem (AWS S3, GCS ou Azure Blob Storage). Começaremos criando um repositório ML e, em seguida, carregando nossos documentos para indexar como um artefato. Para criar um repositório ML, siga o guia aqui: https://www.truefoundry.com/docs/creating-a-ml-repo
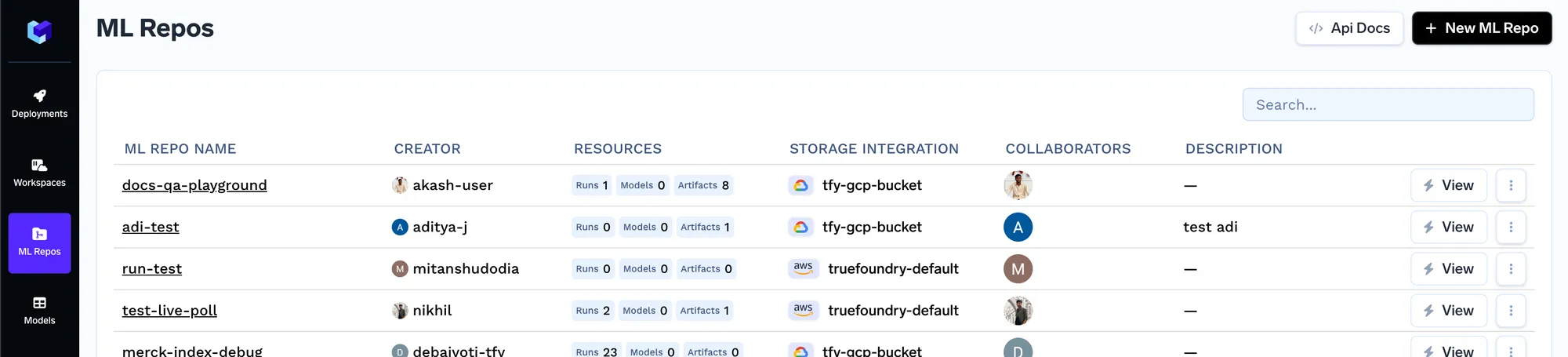
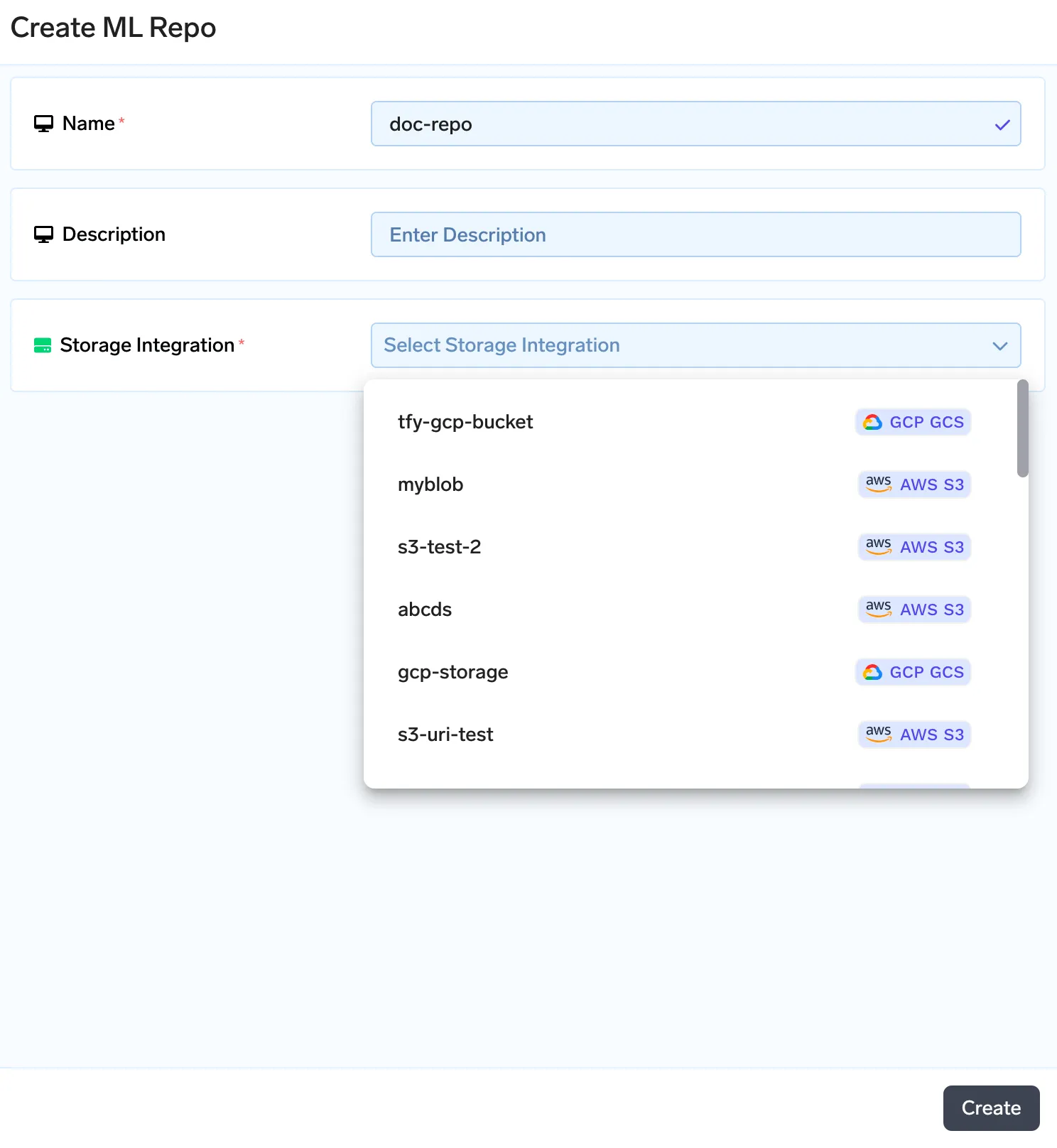
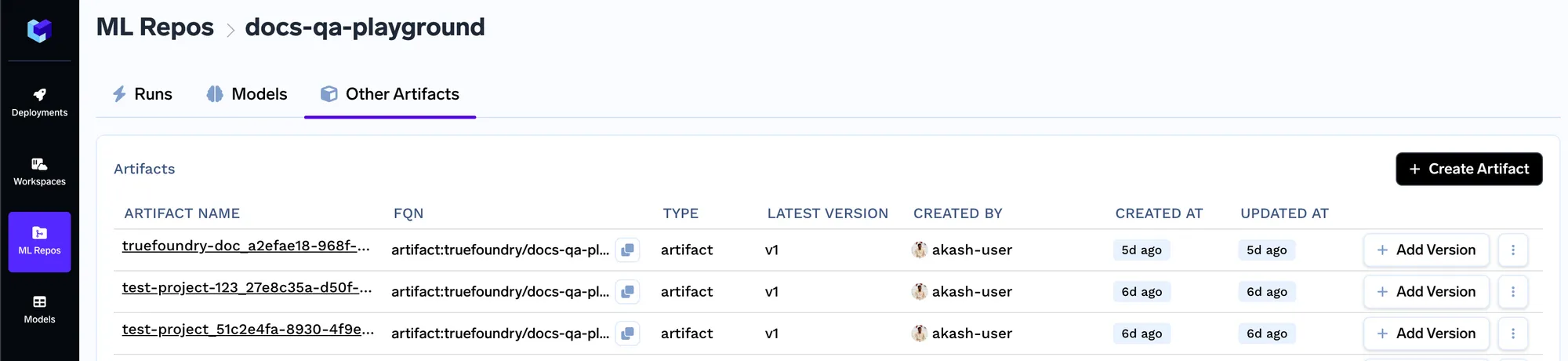
Assim que criarmos um artefato, estaremos criando uma nova versão do artefato. Dessa forma, sempre que o conjunto de documentos mudar, você pode carregar o novo conjunto de documentos como uma nova versão. Você pode carregar seus documentos na tela abaixo.
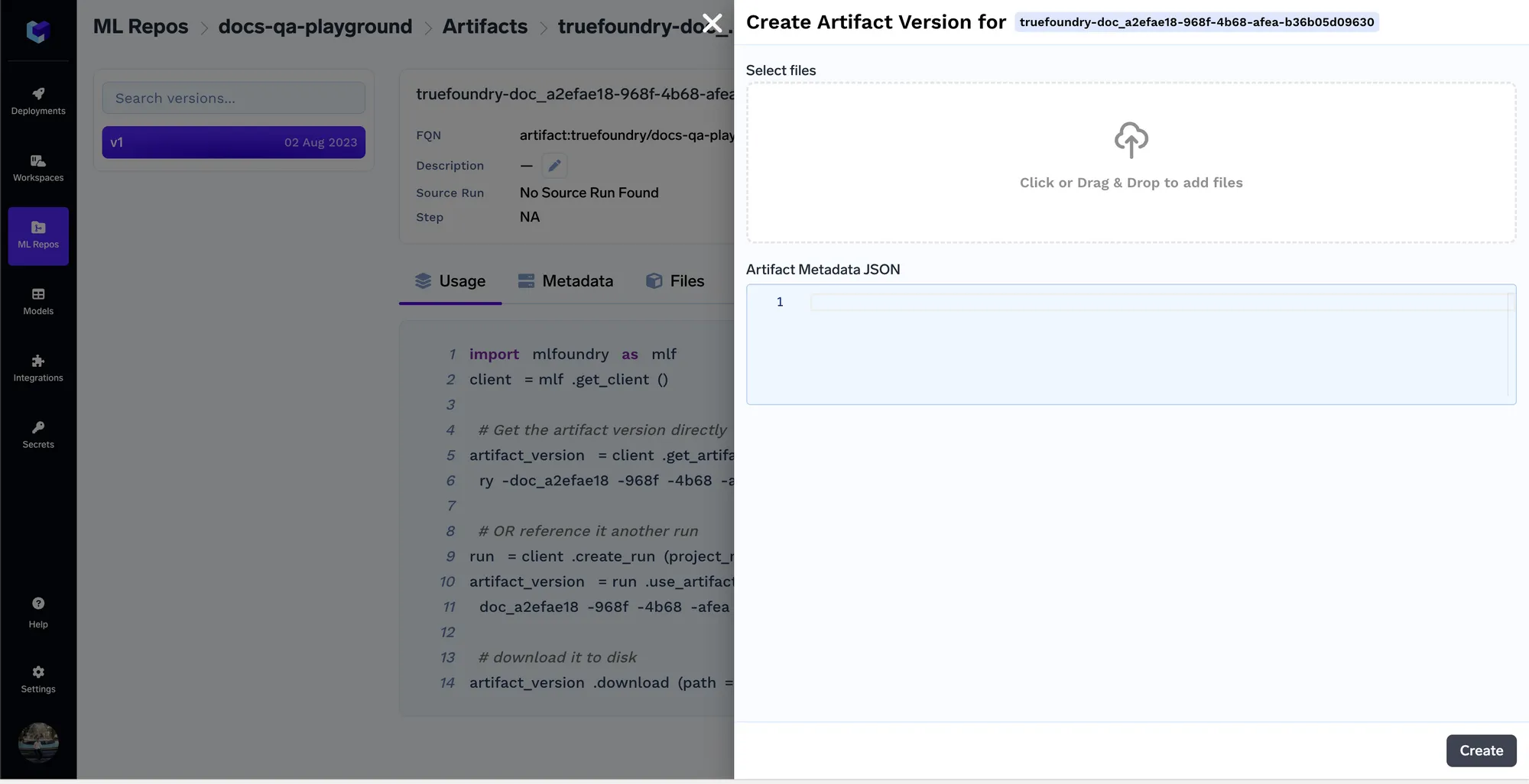
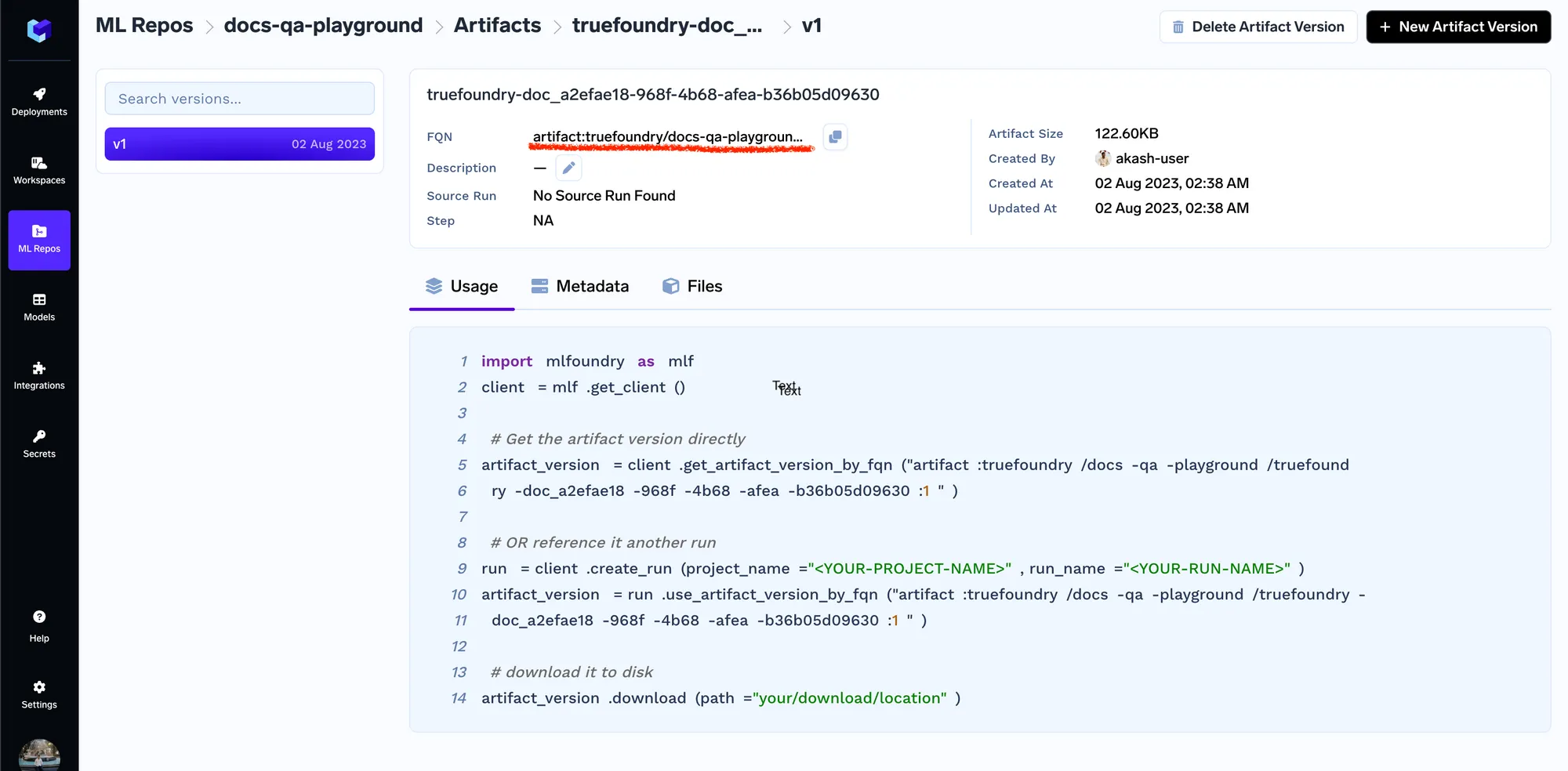
Assim que os documentos forem carregados, obteremos o FQN da versão do artefato, usando o qual poderemos então referenciar/baixar o artefato em código em qualquer lugar.
Precisaremos do modelo de embedding para incorporar os chunks – você pode pular esta etapa se estiver usando Embeddings da OpenAI. Você pode implantar qualquer um dos modelos de embedding do catálogo de modelos – em geral, descobrimos que o e5-large-v2 tem um desempenho muito bom.
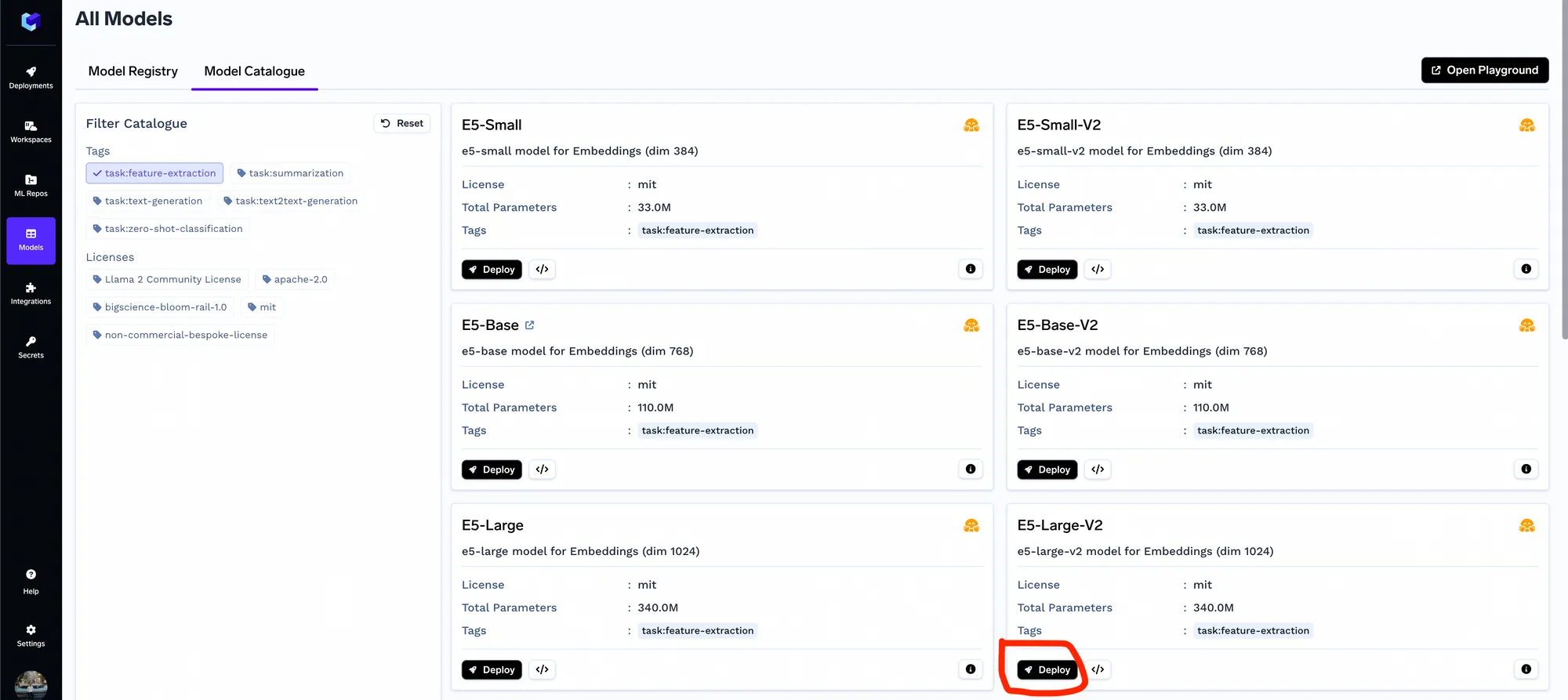
Assim que o modelo de embedding for implantado, você pode verificar as APIs usando o playground OpenAPI no painel do Truefoundry.
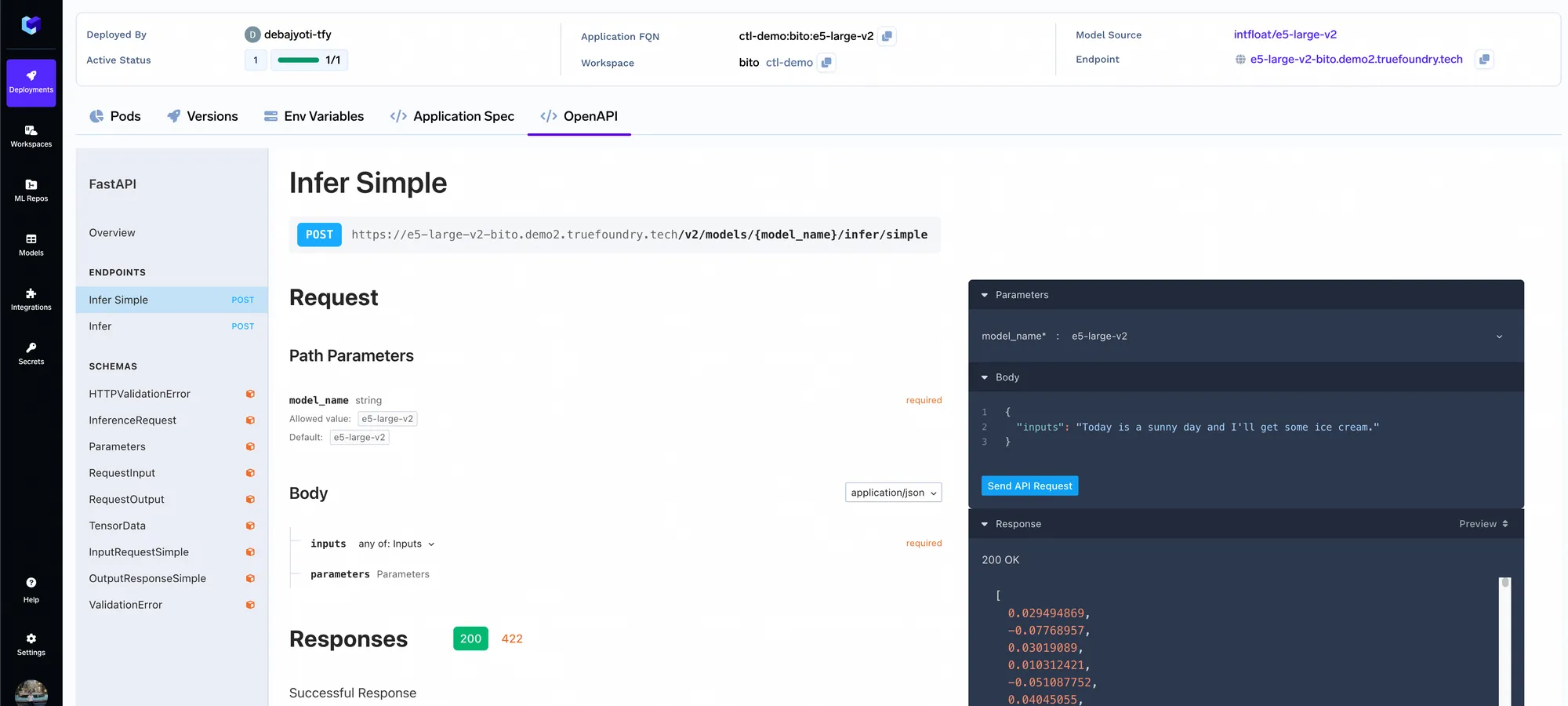
Estaremos implantando o VectorDB Qdrant.
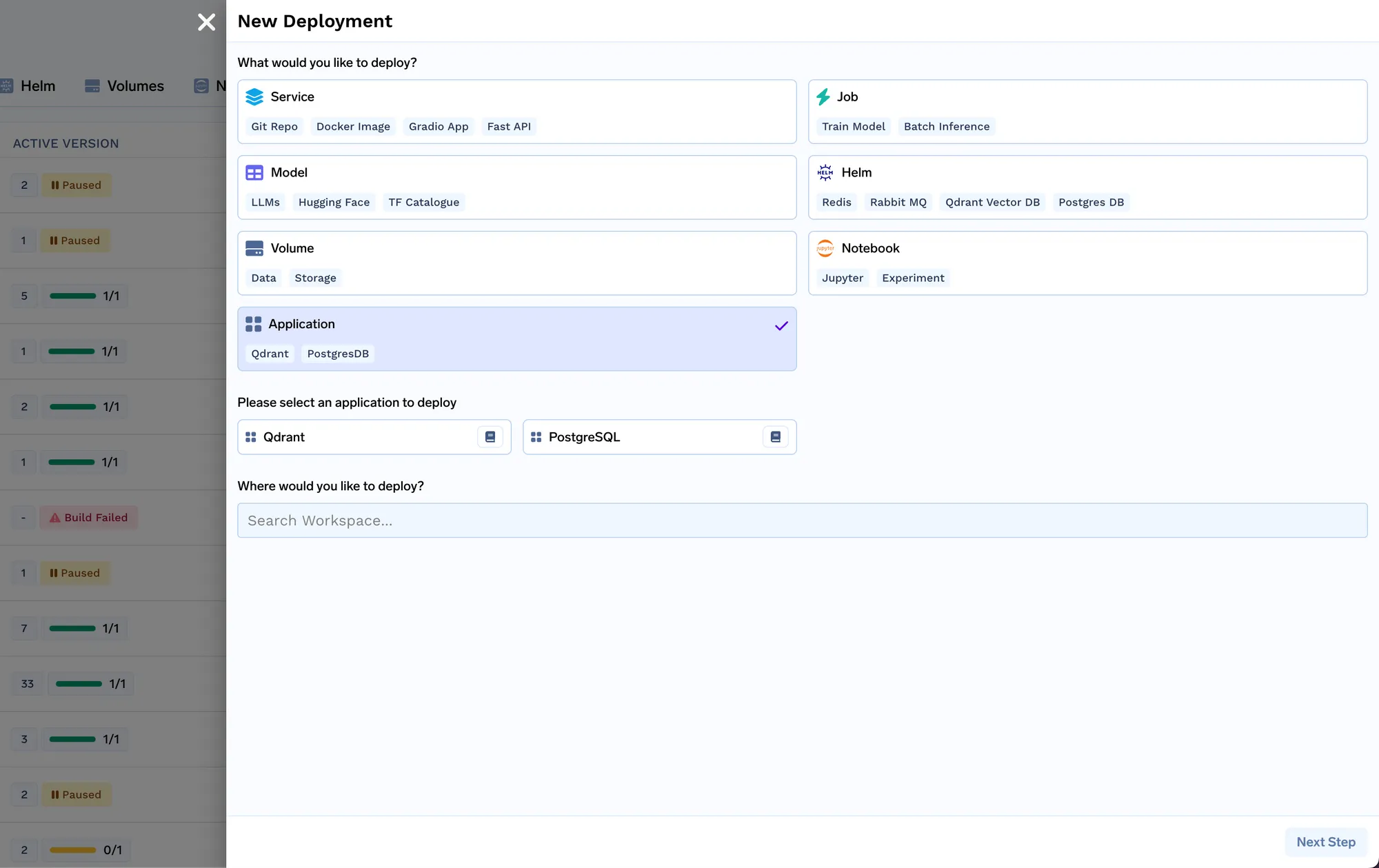
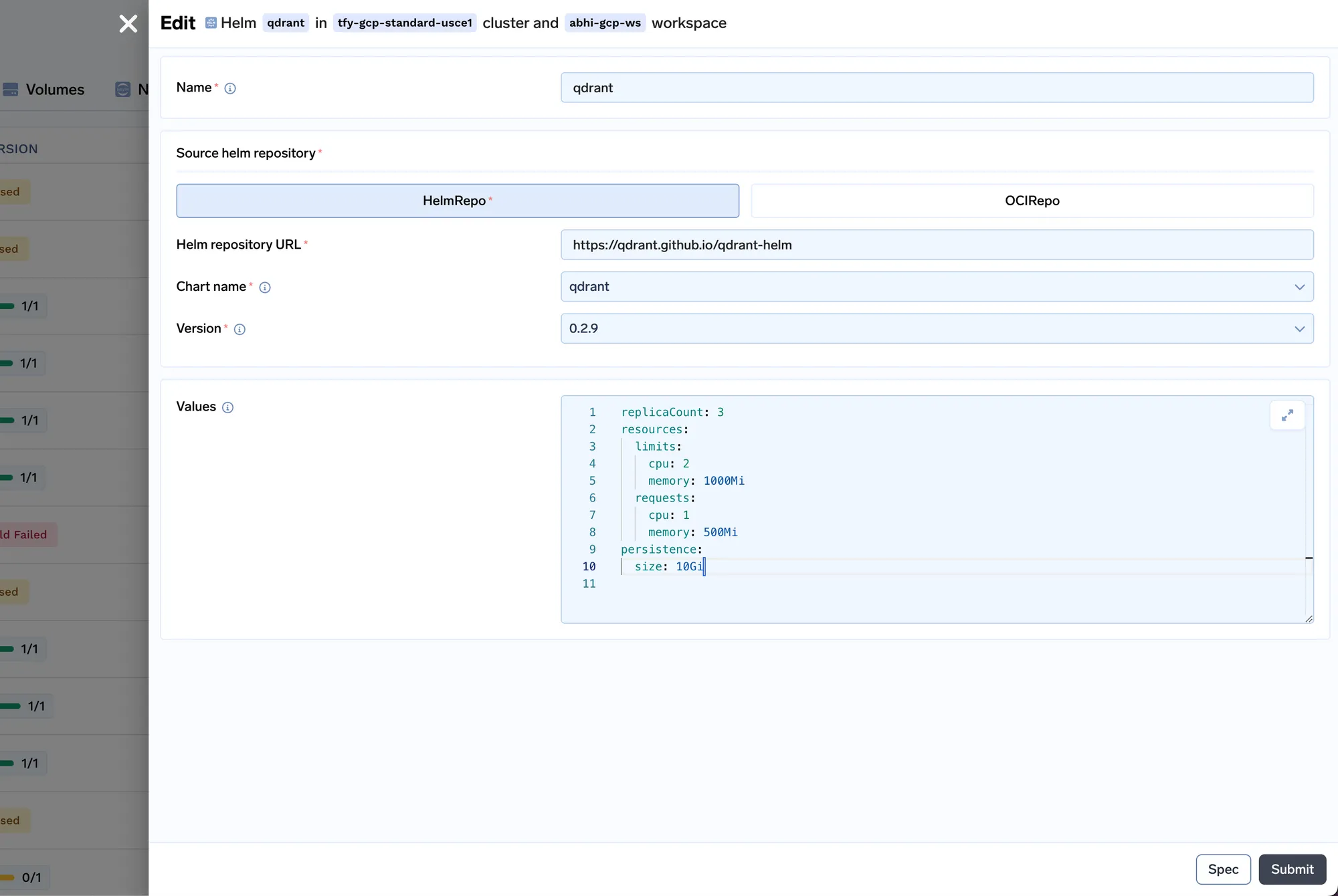
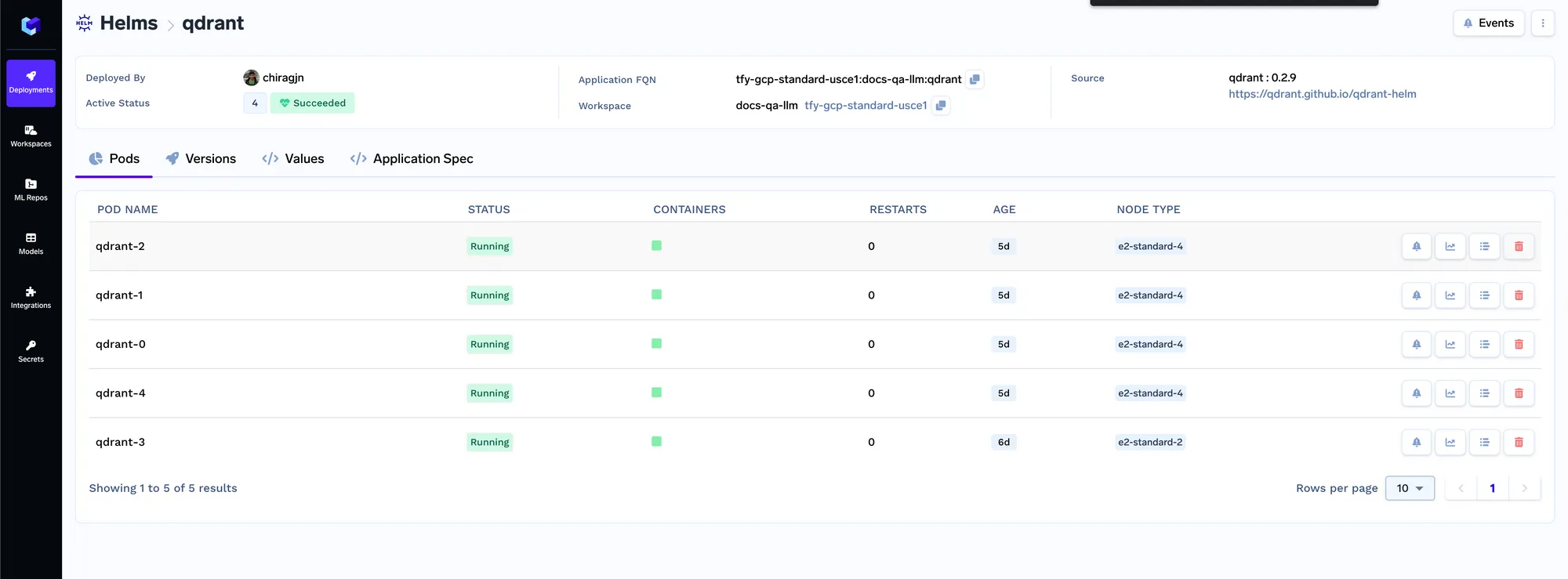
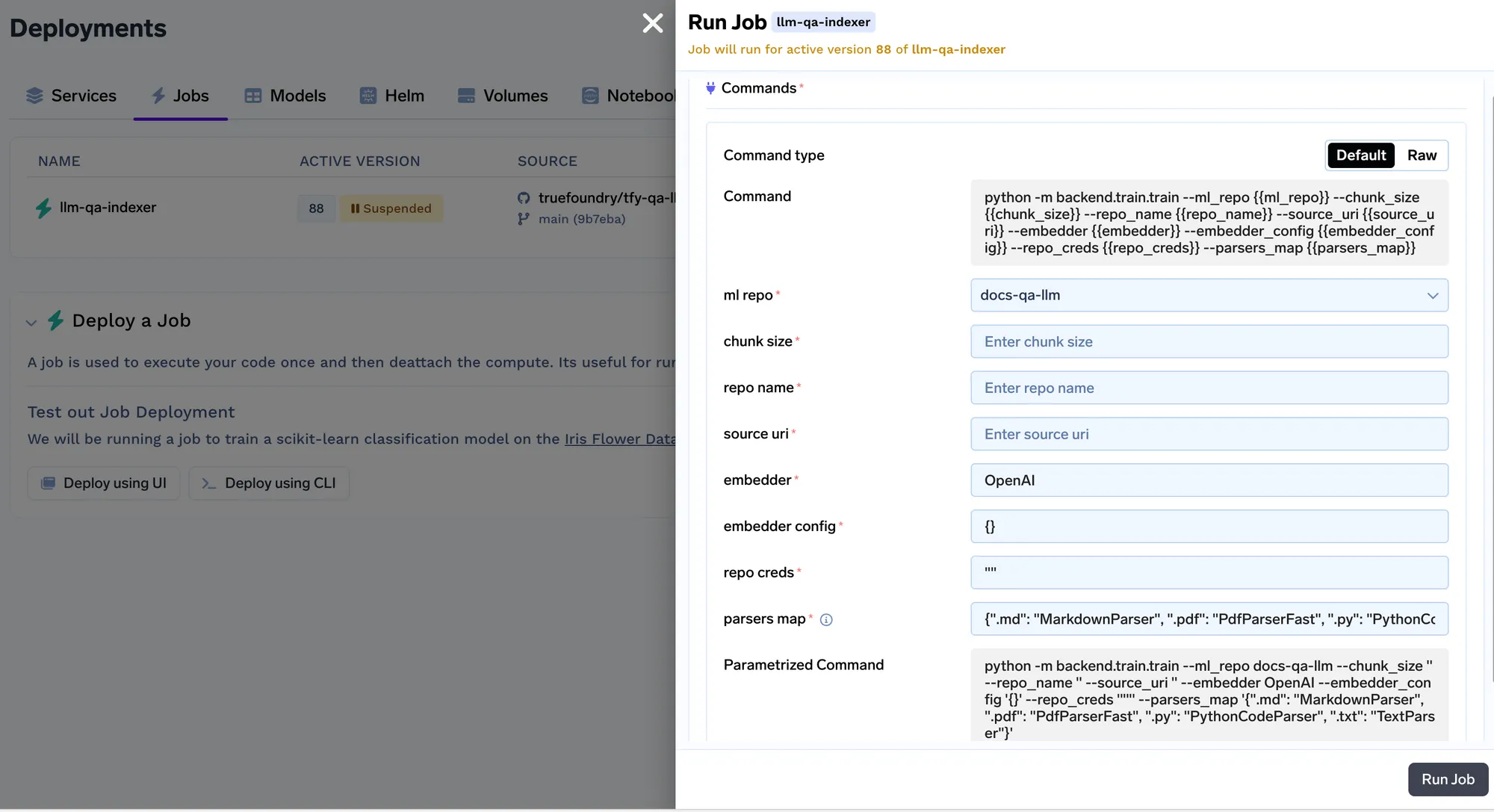
Vamos agora implantar o job de indexação. Um job no Truefoundry nos permite executar um script uma única vez ou em um agendamento, e então o recurso computacional é desligado após a conclusão do job. O código do job de indexação pode ser encontrado aqui: https://github.com/truefoundry/docs-qa-playground/tree/main/backend/train. O job de indexação suporta o carregamento de dados de arquivos locais ou de um artefato mlfoundry. Ele também renderiza automaticamente um formulário onde você pode fornecer argumentos para acionar o job. Você pode inserir o fqn do artefato que copiamos na etapa 1 e colá-lo no campo URI de origem como mlfoundry://<artifact_fqn>. O nome do repositório pode ser qualquer string aleatória que o ajude a identificar este job de indexação. Você também deve inserir o nome do repositório ML que criamos na etapa 1.
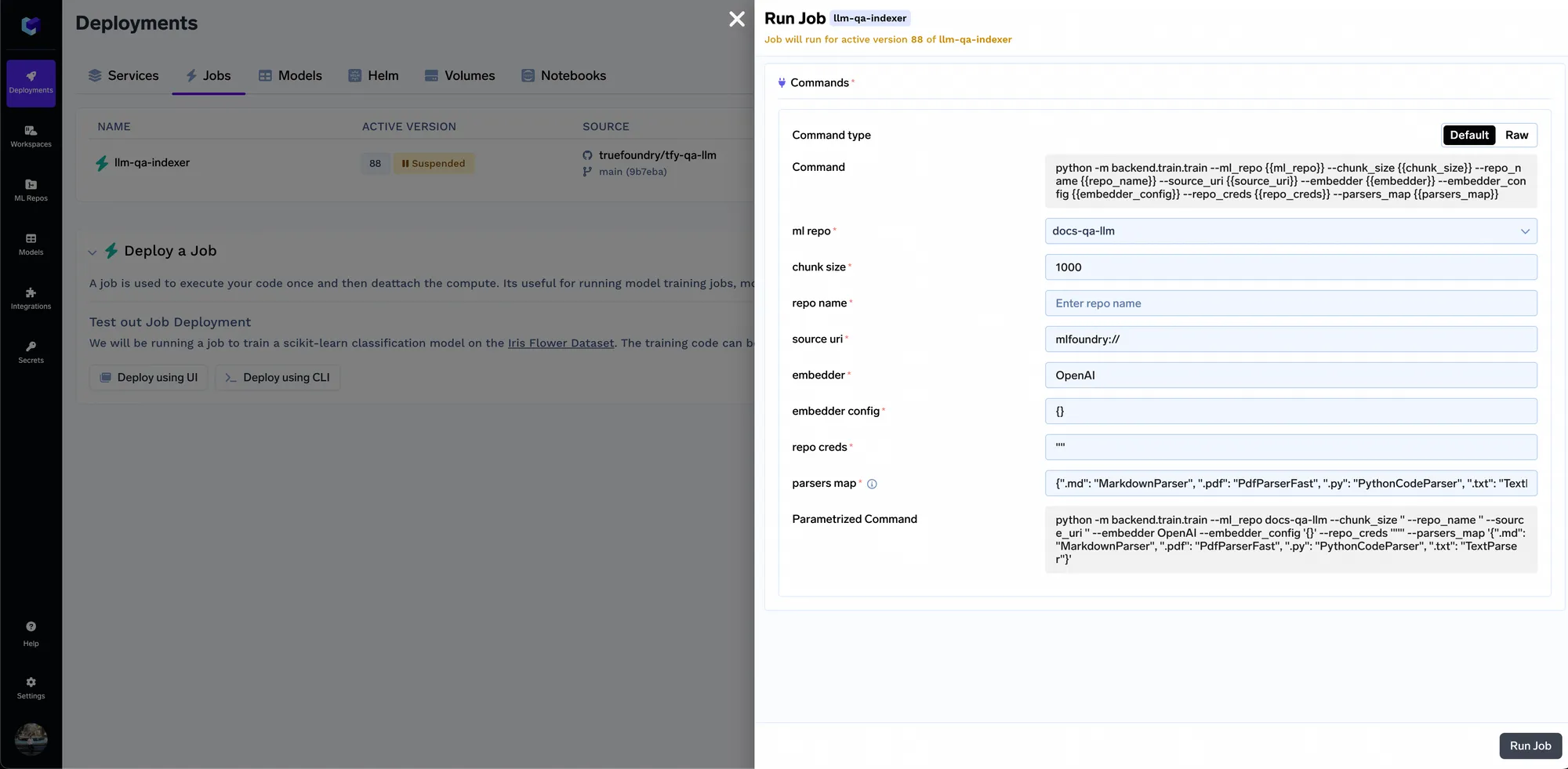
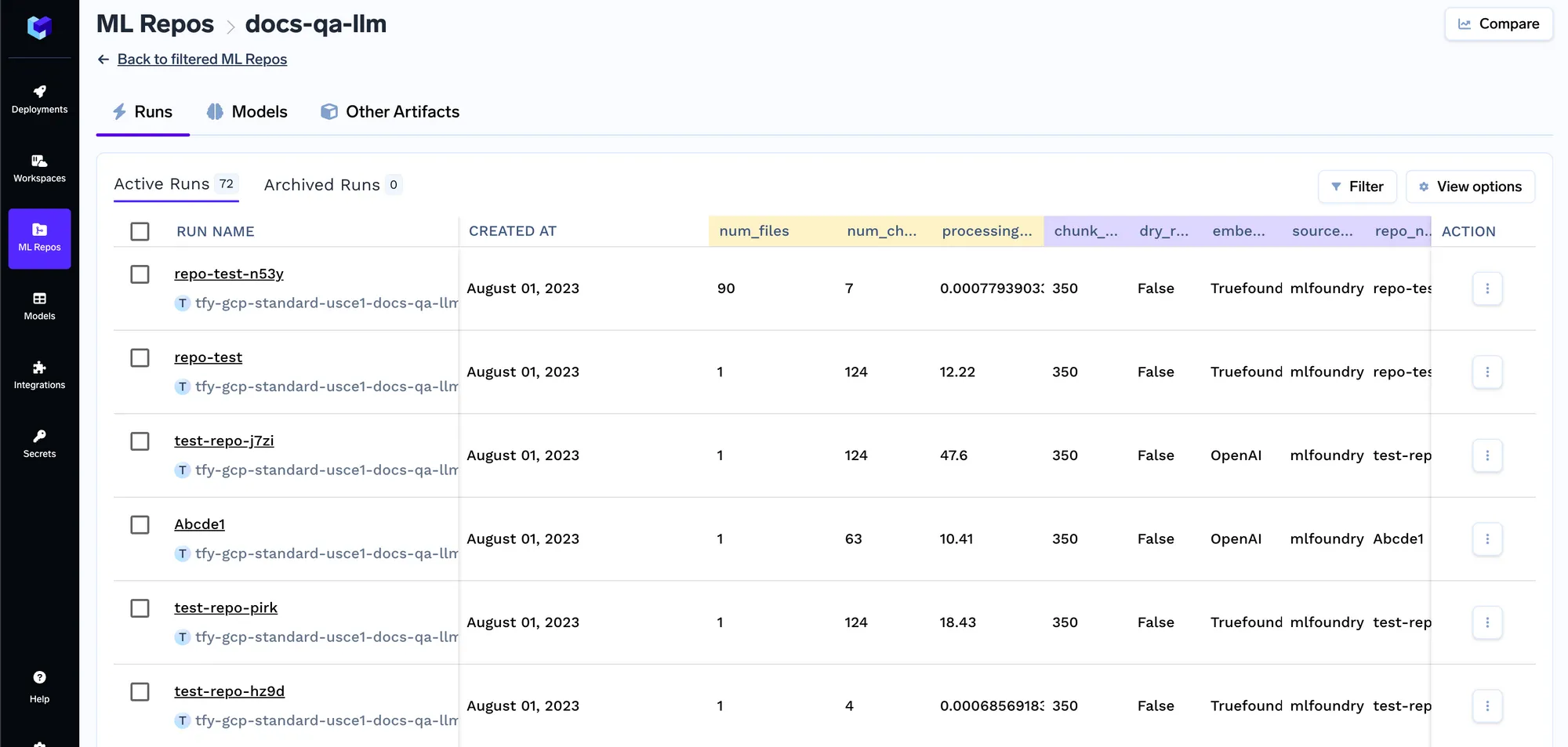
Assim que o job começar a ser executado, você pode acompanhar todas as execuções do job e seus logs:
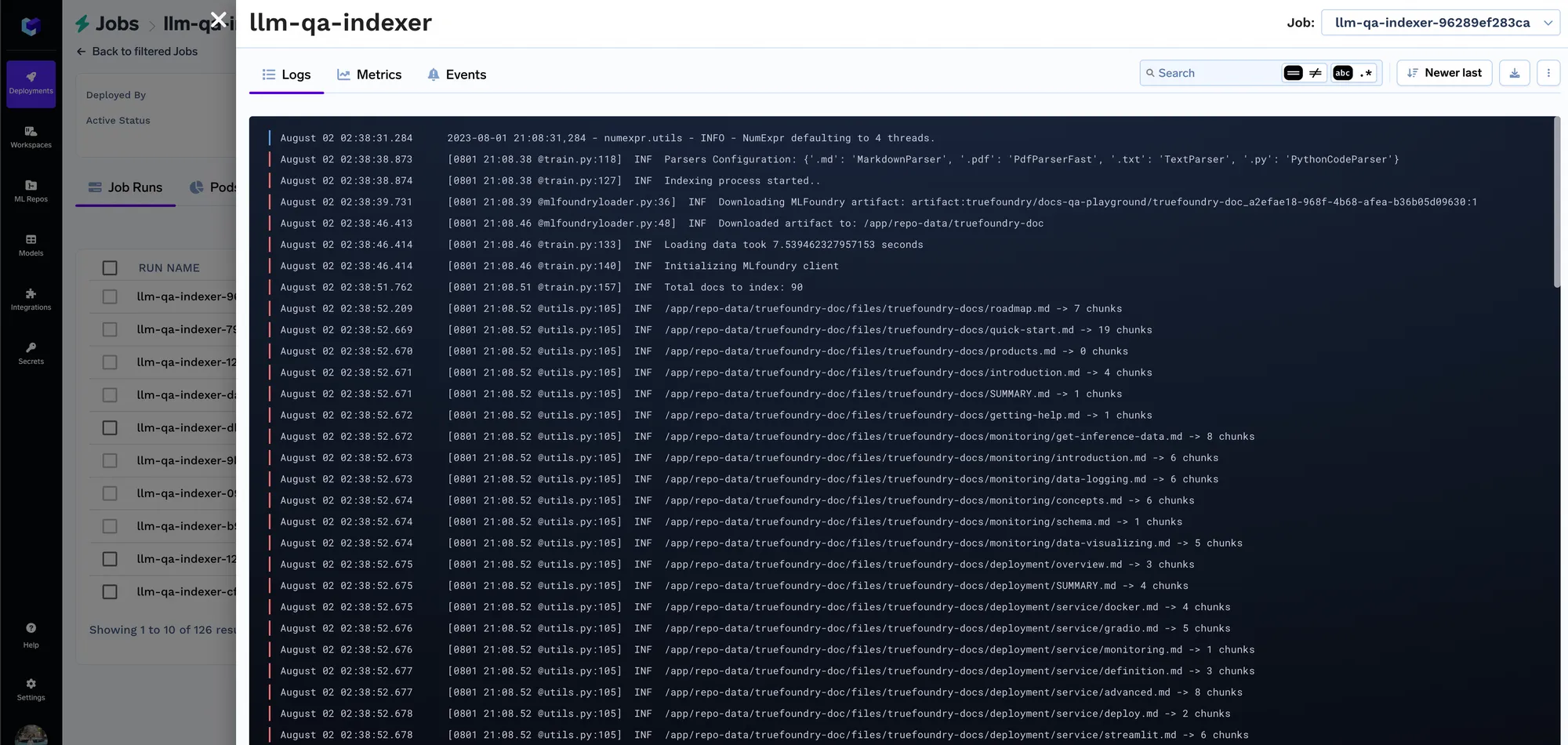
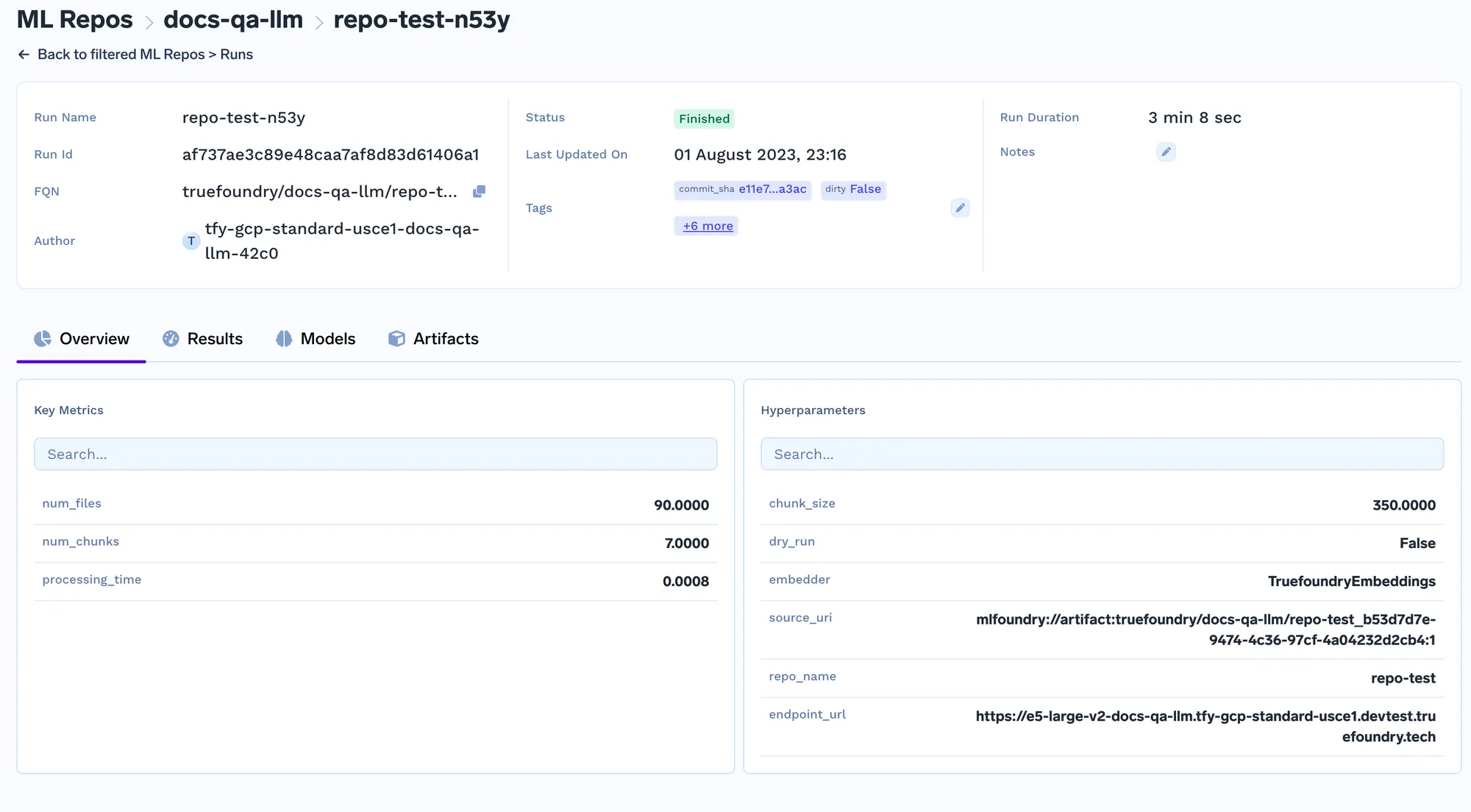
Cada vez que o job é executado, criamos uma execução no repositório ML que armazena todas as configurações de embedding e os parâmetros do job de indexação. Essas configurações são posteriormente usadas pelo serviço de consulta para determinar as configurações de embedding a serem utilizadas para o embedding da consulta. Você pode acompanhar os detalhes de todos os jobs de indexação na aba de execuções.
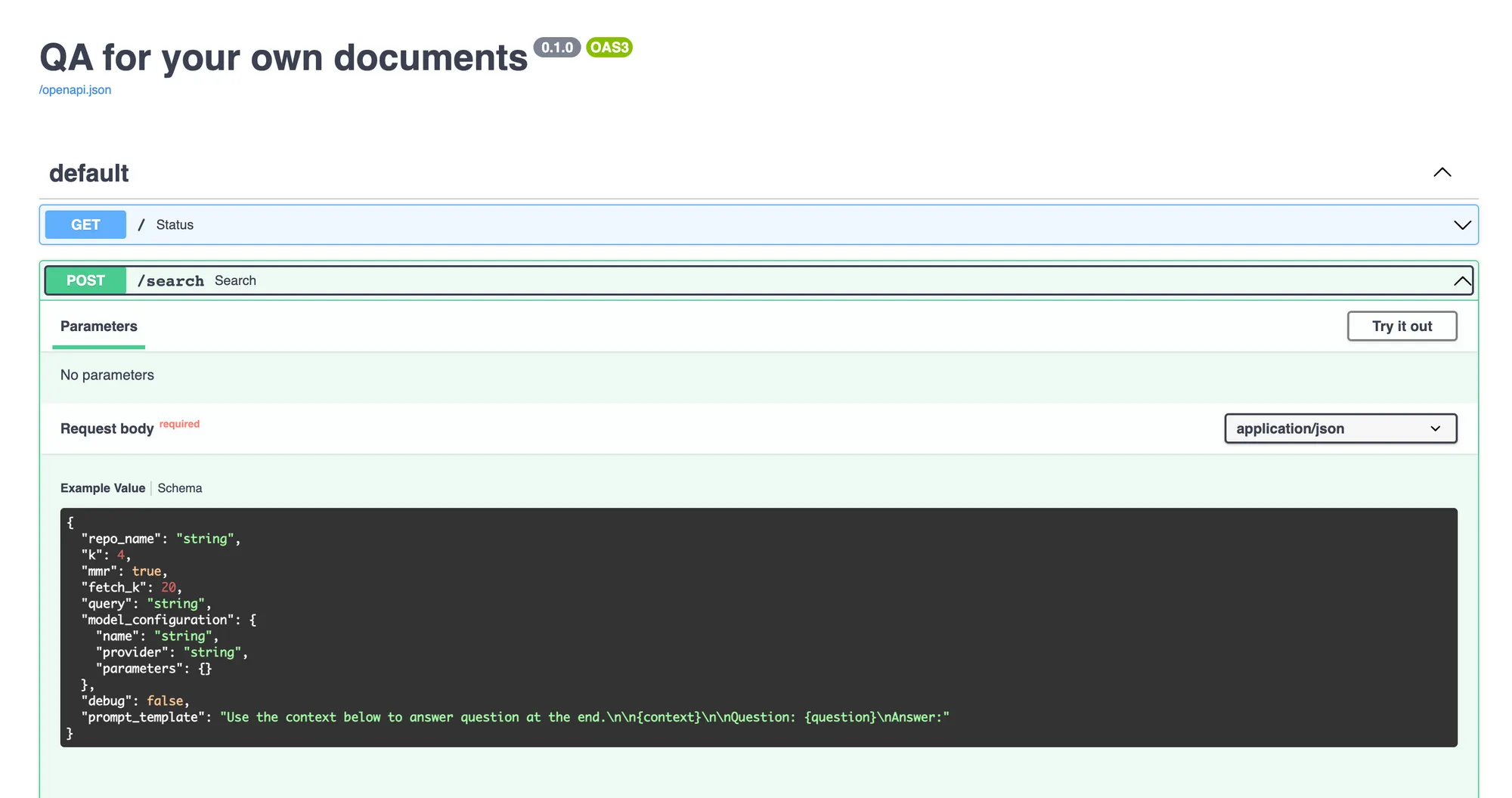
O serviço de consulta é um servidor FastAPI que possui uma API para receber a consulta e obter a resposta do LLM. Depois de implantá-lo, você pode fazer consultas usando a interface Swagger UI no FastAPI.
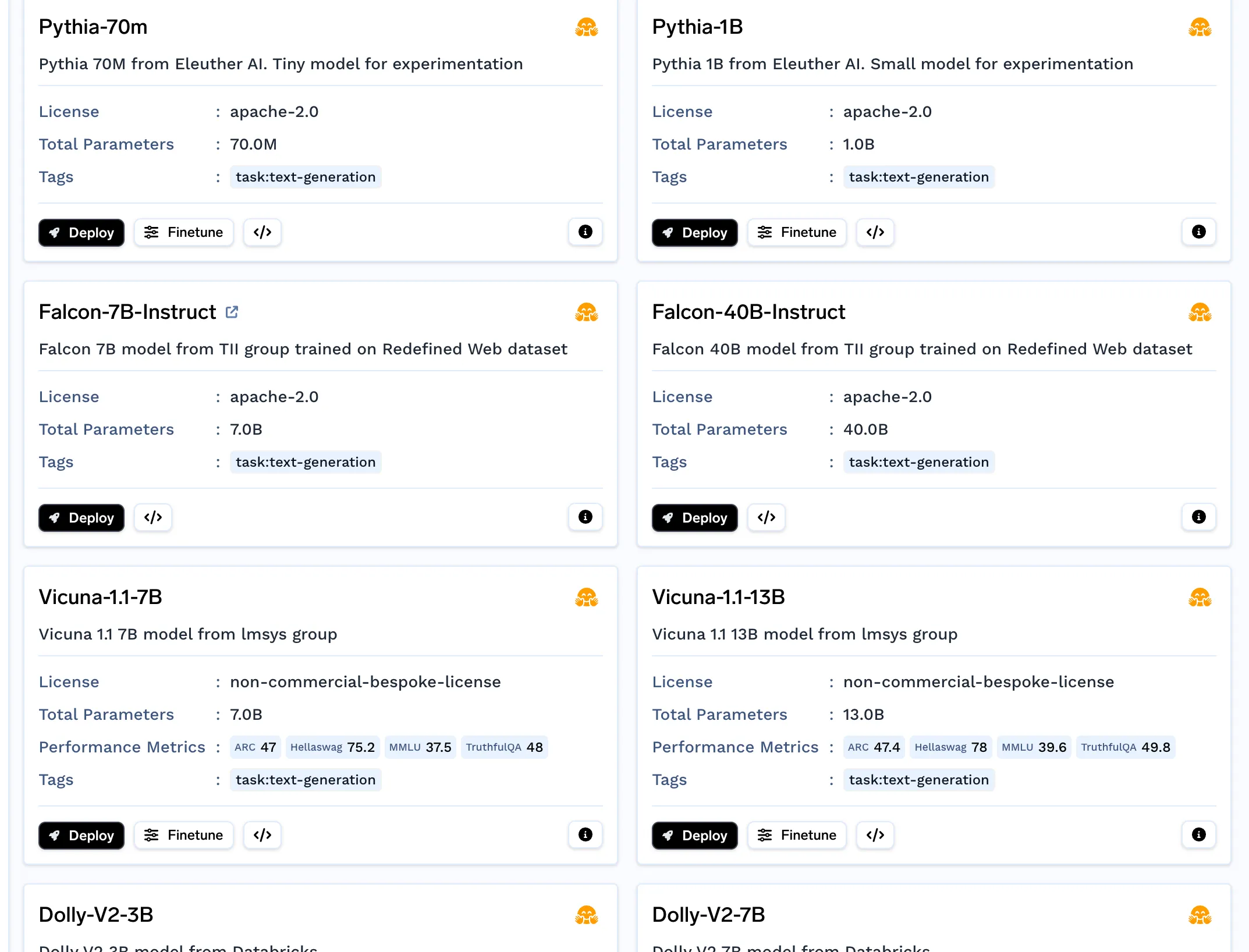
Isso é necessário se você planeja usar um LLM de código aberto e não o OpenAI. Você pode implantar o LLM a partir do catálogo de modelos.
Também fornecemos um aplicativo Streamlit que pode se conectar ao seu backend de indexação, serviço de consulta e armazenamento de metadados para listar todos os repositórios indexados e realizar consultas sobre eles. Uma demonstração de exemplo disso está hospedada em https://www.truefoundry.com/docs/create-and-setup-your-account. Você pode encontrar o código no repositório do GitHub aqui. Para fazer este frontend funcionar, você terá que vinculá-lo ao seu serviço de consulta e job usando variáveis de ambiente:
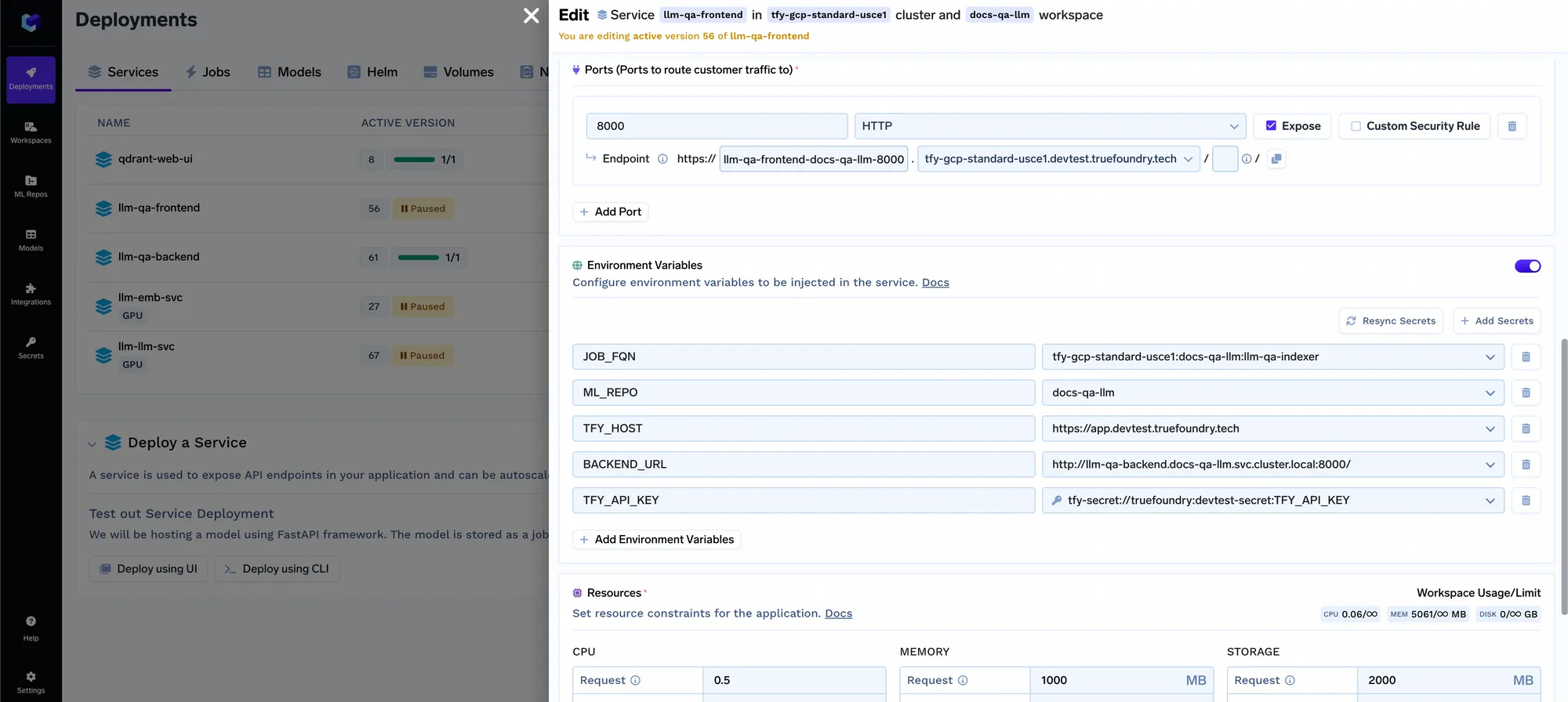
Agora temos um sistema ponta a ponta com um frontend que pode escalar para quantos casos de uso e conjuntos de documentos diferentes dentro da organização. Há algumas coisas que pretendemos incorporar no futuro:
Esta arquitetura também permite ter um serviço central de indexação de documentos em uma organização, que se baseia em uma biblioteca central de carregadores e analisadores de dados.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada
© 2026 Todos os direitos reservados.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




